
Con el auge de la inteligencia artificial, las bases de datos vectoriales han ganado una atención significativa debido a su capacidad para almacenar, gestionar y recuperar eficientemente datos a gran escala y de alta dimensionalidad. Esta capacidad es crucial para aplicaciones de IA y generación de IA (GenAI) que tratan con datos no estructurados como texto, imágenes y videos.
La lógica principal detrás de una base de datos vectorial es proporcionar capacidades de búsqueda de similitud, en lugar de búsqueda por palabras clave como lo hacen las bases de datos tradicionales. Este concepto se ha adoptado ampliamente para mejorar el rendimiento de los modelos de lenguaje grandes (LLMs), especialmente después del lanzamiento de ChatGPT.
El mayor problema con los LLMs es que requieren recursos, tiempo y datos sustanciales para el ajuste fino, lo que dificulta mucho mantenerlos actualizados. Es por eso que cuando consultas a los LLMs sobre eventos recientes, a menudo proporcionan respuestas incorrectas, sin sentido o desconectadas de la entrada, lo que lleva a "alucinaciones".
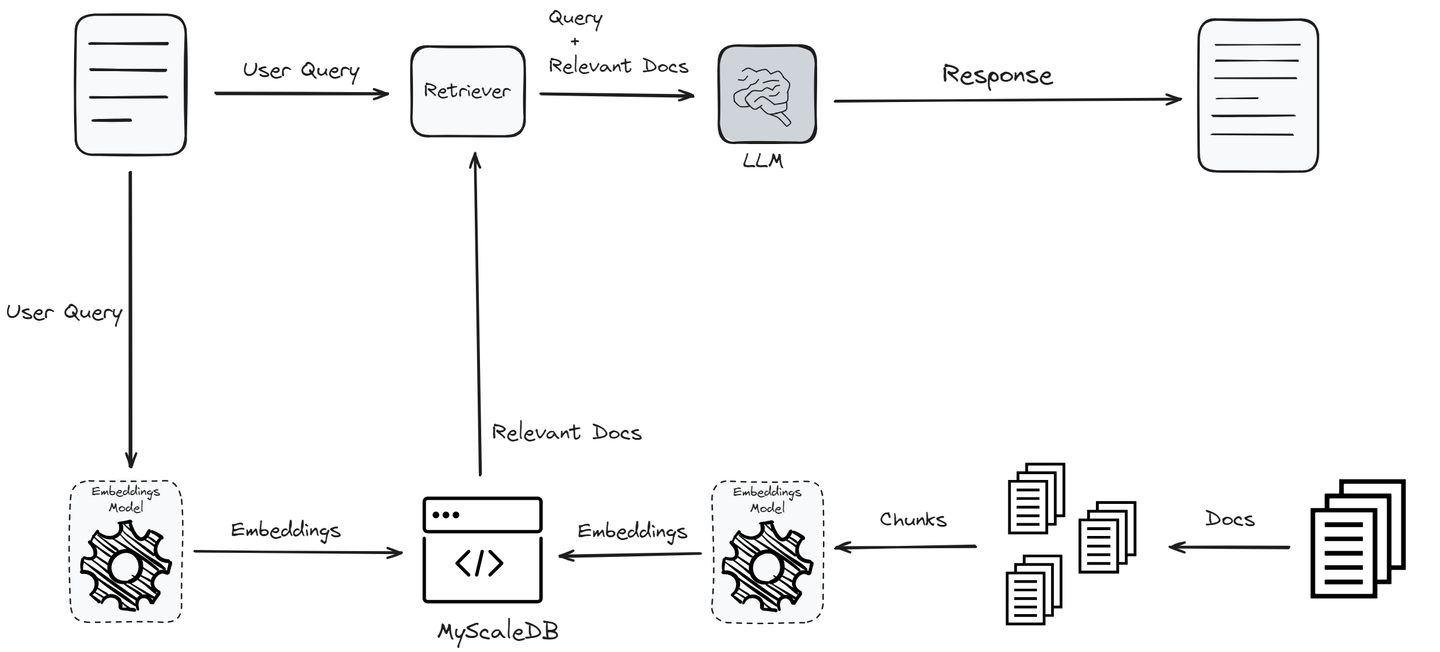
Una solución es la generación con recuperación aumentada (RAG) (opens new window), que mejora un LLM integrando información actualizada recuperada de una base de conocimientos externa. Las bases de datos vectoriales especializadas están diseñadas para manejar datos vectorizados de manera eficiente y proporcionar capacidades de búsqueda semántica sólidas. Estas bases de datos están optimizadas para almacenar y recuperar vectores de alta dimensionalidad, que son muy importantes para realizar búsquedas de similitud. La velocidad y eficiencia de las bases de datos vectoriales las han convertido en una parte integral de los sistemas RAG.
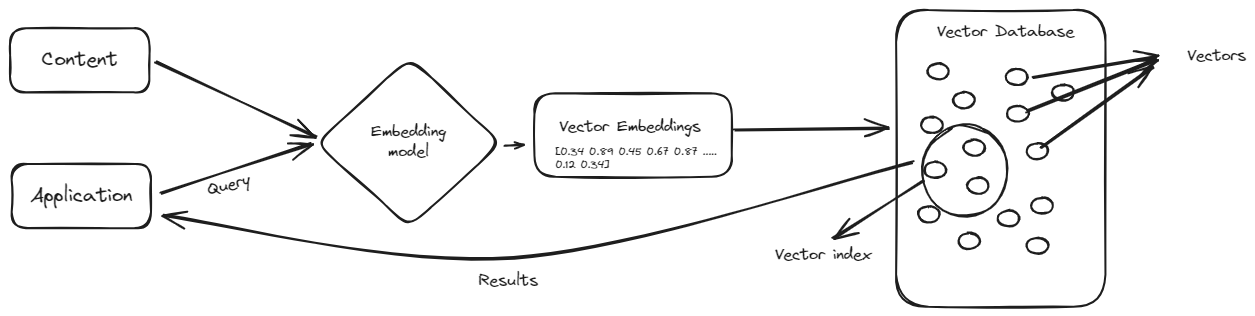
La emoción alrededor de las bases de datos vectoriales ha llevado a muchas personas a sugerir que las bases de datos tradicionales podrían ser reemplazadas por bases de datos vectoriales. ¿En lugar de almacenar datos en bases de datos tradicionales (SQL o NoSQL), podrías almacenar el conjunto de datos completo de una organización en una base de datos vectorial y recuperarlo utilizando lenguaje natural en lugar de escribir consultas manuales?
Pero las bases de datos vectoriales no funcionan como las bases de datos tradicionales. Como escribió el CTO de Qdrant, Andrey Vasnetsov, "la mayoría de las bases de datos vectoriales no son bases de datos en este sentido. Es más preciso llamarlas motores de búsqueda". Esto se debe a que su objetivo principal es proporcionar funcionalidades de búsqueda optimizadas y no están diseñadas para admitir características básicas como la búsqueda por palabras clave o consultas SQL.
# Limitaciones de las bases de datos vectoriales especializadas
A medida que los casos de uso crecieron y las personas se centraron en la escalabilidad de sus aplicaciones, las limitaciones de las bases de datos vectoriales se hicieron más visibles. Los desarrolladores pronto se dieron cuenta de que aún necesitan las características de un motor de búsqueda de texto completo junto con la búsqueda vectorial. Por ejemplo, filtrar los resultados de búsqueda en función de criterios específicos es muy difícil con las bases de datos vectoriales. Estas bases de datos también carecen de coincidencias directas para frases exactas, que son cruciales para muchas tareas.
# Soporte limitado para consultas complejas
Las consultas complejas a menudo involucran múltiples condiciones, uniones y agregaciones, lo que las hace desafiantes para las bases de datos vectoriales especializadas. Estas bases de datos brindan un soporte limitado para consultas complejas a través del filtrado de metadatos. Sin embargo, el almacenamiento de metadatos es muy limitado en las bases de datos vectoriales, lo que restringe la capacidad de los usuarios para realizar una amplia gama de consultas complejas.
En contraste, las bases de datos SQL están diseñadas para manejar un almacenamiento y procesamiento extensos, lo que permite la ejecución eficiente de consultas complejas que involucran múltiples condiciones, uniones y agregaciones. Esto hace que las bases de datos SQL sean mucho más versátiles y capaces cuando se trata de manejar tareas complejas de recuperación y manipulación de datos.
# Limitaciones de tipos de datos
Las bases de datos vectoriales especializadas también enfrentan limitaciones en cuanto a tipos de datos. Están diseñadas para almacenar vectores y metadatos mínimos, lo que restringe su flexibilidad. Este enfoque en los vectores significa que no pueden manejar la amplia variedad de tipos de datos que pueden manejar las bases de datos SQL, como enteros, cadenas y fechas, lo que permite operaciones de datos más complejas y variadas.
En general, las bases de datos vectoriales especializadas tienen un enfoque muy estrecho. Su arquitectura está optimizada principalmente para la búsqueda semántica en lugar de las necesidades más amplias de gestión de datos. Esto restringe su funcionalidad para realizar una amplia gama de tareas que son fácilmente manejadas por sistemas más versátiles como las bases de datos SQL. Además, su incapacidad para almacenar y gestionar diferentes tipos de datos más allá de los vectores los hace menos adecuados para tareas de bases de datos de propósito general. Las bases de datos vectoriales funcionan bien para aplicaciones RAG, pero no son lo suficientemente versátiles para casos de uso más amplios.
# Desafíos de integración
La integración de bases de datos vectoriales especializadas en infraestructuras de TI existentes presenta desafíos. A menudo surgen problemas de compatibilidad debido a las diferencias inherentes entre las bases de datos vectoriales especializadas y los sistemas existentes, lo que requiere una transformación significativa de datos y puede resultar en pérdida o corrupción de datos. Asegurar la interoperabilidad con sistemas heredados y mantener la consistencia e integridad de los datos también son tareas complejas. Además, el proceso de integración requiere conjuntos de habilidades especializadas, que pueden no estar fácilmente disponibles dentro de una organización, lo que lleva a altos costos de capacitación y una curva de aprendizaje pronunciada.
Además, las implicaciones financieras de la integración son sustanciales. Los costos incluyen licencias de software, actualizaciones de hardware, capacitación del personal y mantenimiento continuo. Además, es posible que las aplicaciones existentes deban modificarse o reescribirse para interactuar con la base de datos vectorial, lo que es un proceso costoso y arriesgado con el potencial de introducir nuevos errores o problemas de rendimiento. La necesidad de soporte y actualizaciones continuas para la base de datos vectorial especializada también puede generar compromisos financieros a largo plazo.
# El procesamiento de datos requiere un enfoque híbrido
Los cimientos de una base de datos vectorial especializada son el almacenamiento y la búsqueda de vectores, principalmente para aplicaciones RAG. Sin embargo, las bases de datos tradicionales también deberían poder manejar vectores, y la búsqueda vectorial es un enfoque de procesamiento de consultas, no un fundamento para una nueva forma de procesar datos.
RAG es una técnica de IA popular que se beneficia de las bases de datos vectoriales. Si bien las bases de datos vectoriales son excelentes para búsquedas semánticas y manejo de datos de alta dimensionalidad, sus capacidades enfocadas a menudo pasan por alto las necesidades operativas y funcionales de una organización. Esto puede limitar su uso en aplicaciones más amplias con diversos requisitos operativos y funcionales.
Del mismo modo, las bases de datos tradicionales han intentado incorporar almacenamiento y búsqueda vectorial para ofrecer una solución eficiente para el procesamiento a gran escala de tipos de datos complejos. Por ejemplo, PostgreSQL y Elasticsearch han introducido capacidades de búsqueda vectorial. Sin embargo, su rendimiento de búsqueda vectorial no es tan bueno y queda rezagado en comparación con bases de datos vectoriales especializadas como Pinecone y Qdrant. Por ejemplo, Qdrant logra una latencia media de solo 45.23 ms con una tasa de precisión de 0.9822. En comparación, aunque robusto, OpenSearch registra una latencia más alta de 53.89 ms y una precisión ligeramente menor de 0.9823.
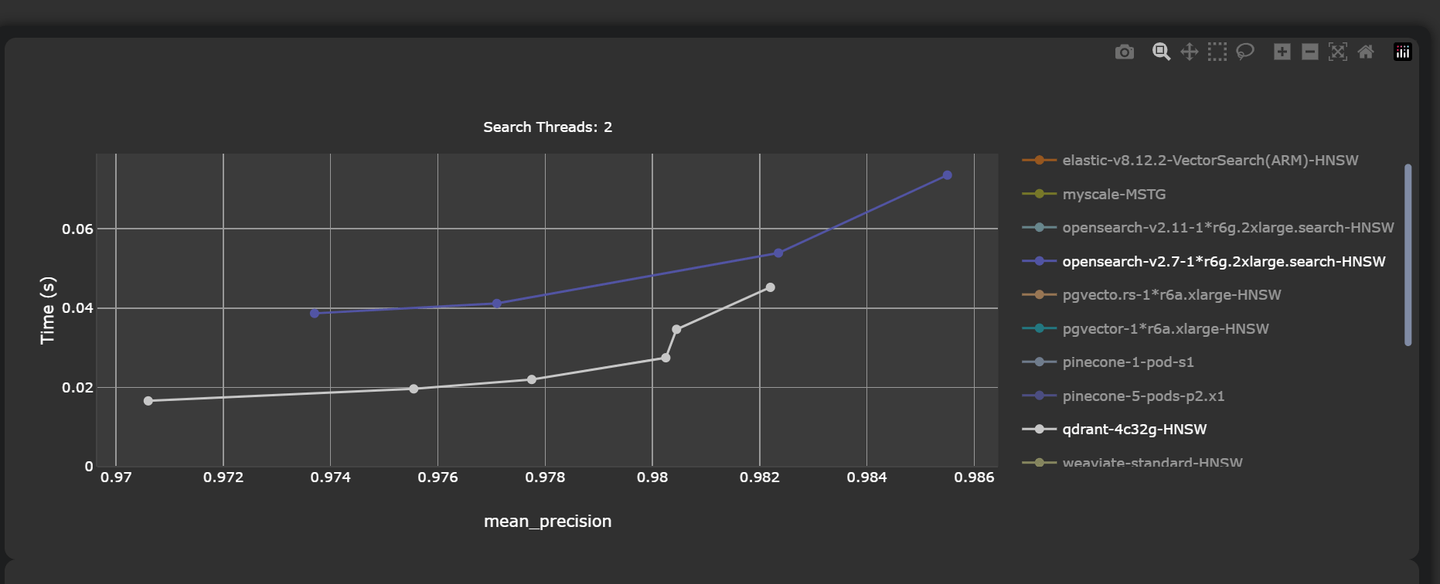
Nota:
Ver las mediciones de rendimiento (opens new window) completas aquí.
La arquitectura de las bases de datos vectoriales especializadas está diseñada específicamente para manejar datos vectoriales de alta dimensionalidad de manera eficiente, pero las bases de datos tradicionales están principalmente construidas para datos relacionales y no admiten naturalmente las necesidades específicas de la búsqueda vectorial.
Otra opción es agregar extensiones vectoriales a su base de datos o motor de búsqueda actual. Este enfoque admite directamente las necesidades comerciales al combinar las fortalezas y la flexibilidad de las bases de datos tradicionales con las características avanzadas de las búsquedas vectoriales modernas.
Un modelo híbrido puede alinearse más estrechamente con los diversos requisitos de manejo de datos de una empresa y optimizar su infraestructura de datos. Esto puede reducir los costos y la complejidad operativa, lo que finalmente conduce a una solución más escalable y eficiente que cumple con las necesidades integrales de procesamiento de datos de la organización.
# Las bases de datos vectoriales SQL acortan la brecha: presentando MyScaleDB
SQL ha sido el pilar de las aplicaciones escalables durante medio siglo, y su integración con características de búsqueda vectorial está lista para acortar la brecha entre las necesidades de procesamiento de datos tradicionales y modernas. Integrar SQL con vectores mejorará la flexibilidad del modelado de datos y facilitará el desarrollo. Esto permitirá que el sistema maneje consultas complejas que involucren datos estructurados, datos vectoriales, búsquedas por palabras clave y consultas unidas en múltiples tablas.
Si bien las bases de datos vectoriales especializadas sobresalen en el manejo de datos de alta dimensionalidad con precisión y velocidad, la integración de la búsqueda vectorial en las bases de datos SQL presenta una alternativa convincente. Ofrece un equilibrio entre la eficiencia requerida para el procesamiento de tipos de datos complejos a gran escala y la comodidad de trabajar dentro de un marco familiar y ampliamente adoptado. Esta integración resuelve muchos desafíos que enfrentan las bases de datos vectoriales especializadas, como la iteración lenta, las consultas ineficientes y los altos costos de administrar una base de datos separada. Al adoptar las bases de datos vectoriales SQL, las empresas pueden aprovechar la escalabilidad y confiabilidad probadas de SQL, al tiempo que obtienen capacidades avanzadas necesarias para abordar los desafíos multifacéticos del procesamiento de datos moderno.
MyScaleDB es una base de datos vectorial SQL de código abierto construida sobre ClickHouse. Combina las fortalezas de las bases de datos SQL tradicionales con las capacidades de las bases de datos vectoriales, almacenando y gestionando eficientemente vectores de alta dimensionalidad utilizando SQL para aplicaciones GenAI. Ofrece una recuperación de datos integral a través de filtrado avanzado y consultas vectoriales SQL complejas, respaldadas por texto a SQL para facilitar su uso.
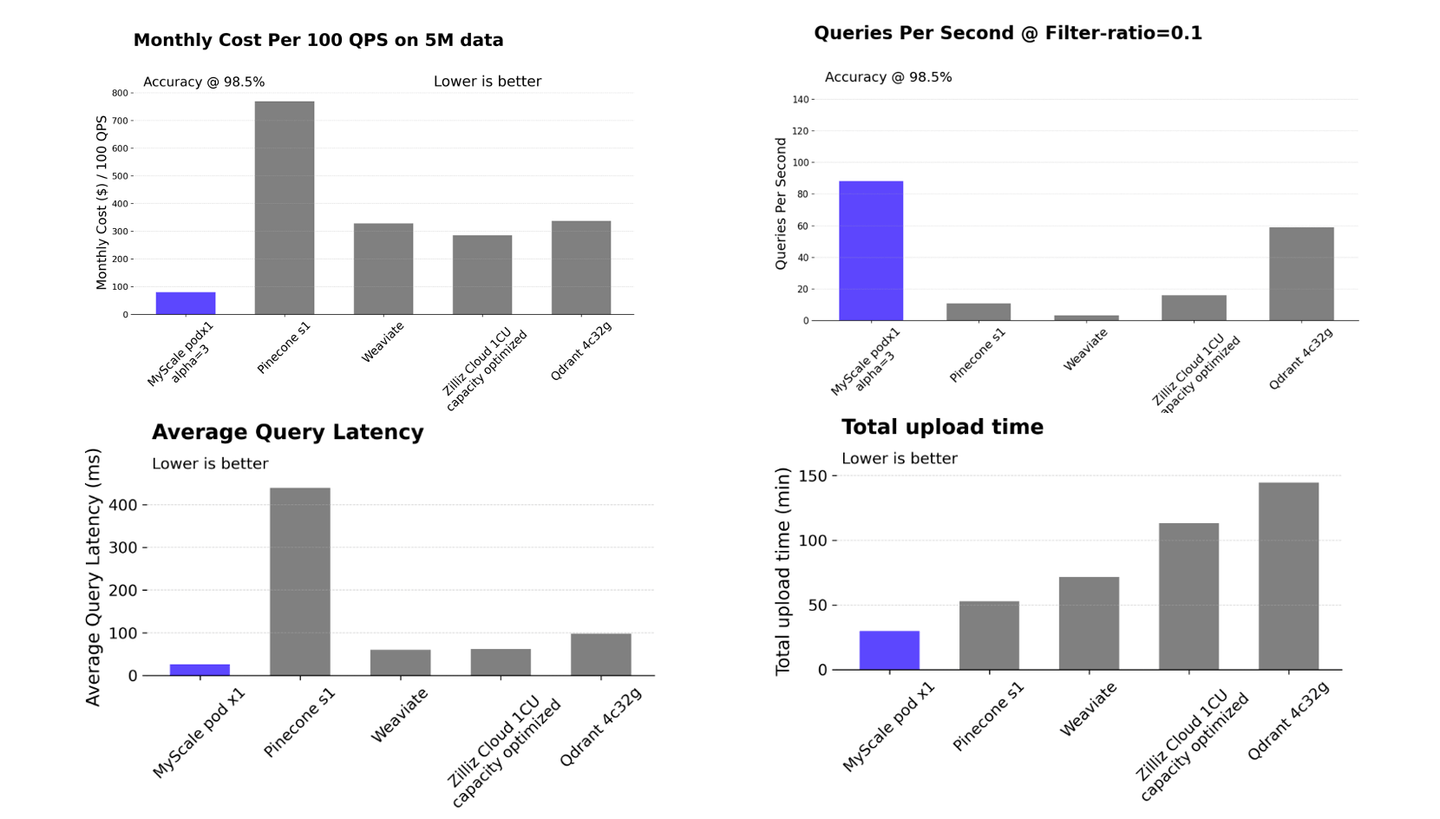
MyScaleDB (opens new window) es más rápido y rentable que las bases de datos vectoriales especializadas, con su algoritmo de indexación MSTG propietario optimizando la recuperación de datos vectoriales para una mayor eficiencia del sistema. Además, MyScaleDB se destaca entre las bases de datos SQL/NoSQL mejoradas con vectores por su rendimiento y escalabilidad superiores, especialmente cuando se manejan diversas relaciones de filtro.

# En conclusión
Confiar completamente en una base de datos vectorial especializada que solo procesa vectores limita la flexibilidad de tu estrategia de gestión de datos. Una base de datos vectorial multifuncional o integrada proporciona una solución más prometedora. MyScaleDB no solo gestiona eficientemente vectores, sino que también funciona como una base de datos general, lo que la convierte en una solución versátil y potente para aplicaciones de IA modernas.
Tener una base de datos que pueda gestionar tanto datos estructurados como vectores es crucial en el mundo tecnológico de IA actual. Este enfoque garantiza la escalabilidad, flexibilidad y rentabilidad, eliminando la necesidad de gestionar múltiples sistemas. Al optar por una base de datos versátil, puedes preparar tu infraestructura de datos para el futuro y satisfacer los crecientes requisitos de las aplicaciones modernas.



