
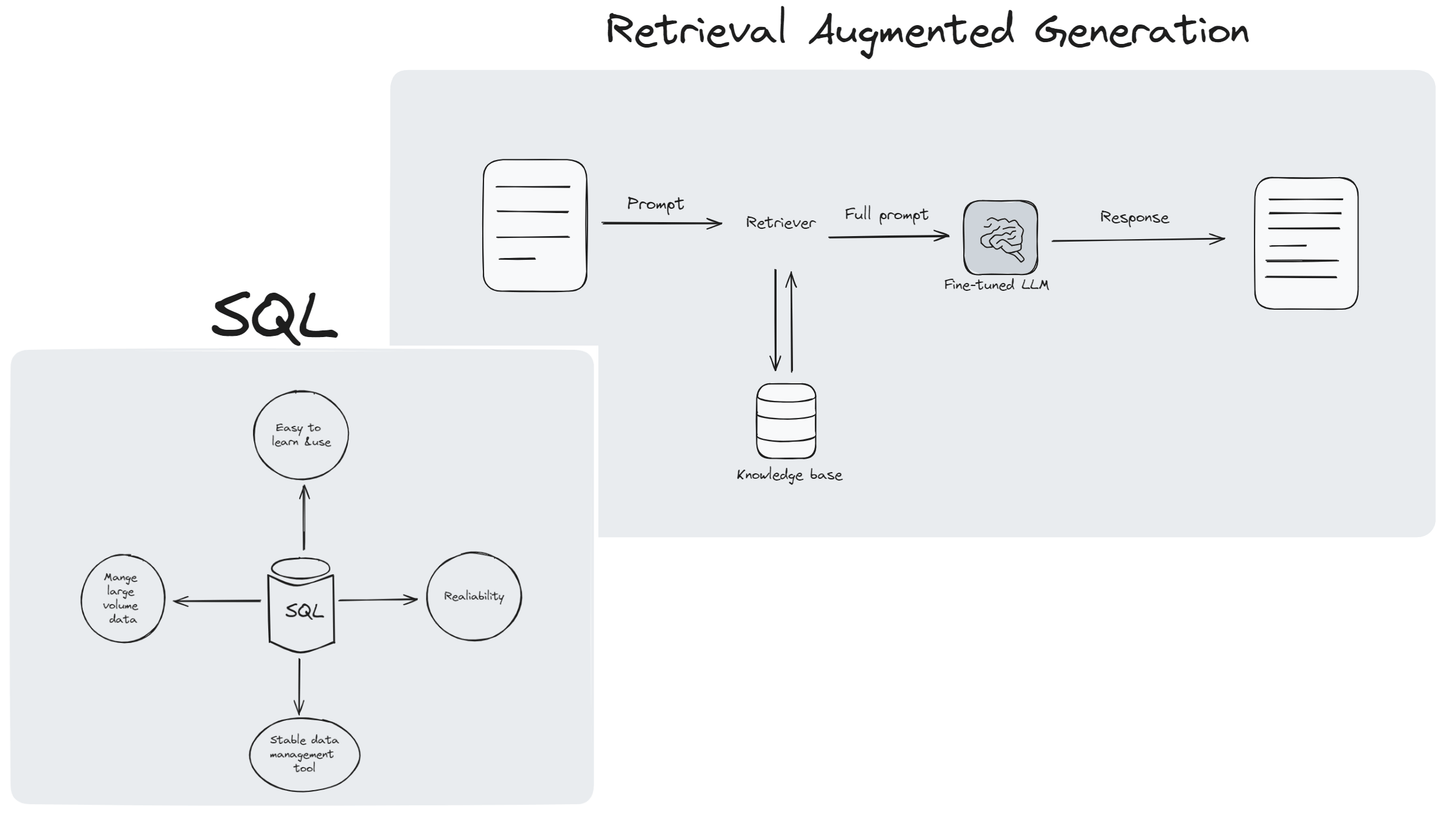
La generación con recuperación aumentada (RAG) (opens new window) ha demostrado ser una técnica revolucionaria en el campo del Procesamiento del Lenguaje Natural (NLP) y los Modelos de Lenguaje Amplios (LLMs, por sus siglas en inglés). Ha combinado los modelos de lenguaje tradicionales con un innovador mecanismo de recuperación, permitiendo que los modelos de lenguaje accedan a una vasta base de conocimientos (opens new window) para mejorar la calidad y relevancia de sus respuestas. RAG es particularmente beneficioso en escenarios donde se requiere información detallada y actualizada, como la investigación académica, el servicio al cliente y la creación de contenido.
RAG mejora cuando se utiliza a gran escala, pero esto también plantea algunos desafíos. A medida que la información crece rápidamente, RAG necesita clasificar grandes cantidades de datos desordenados rápidamente, el problema radica en mejorar el tamaño del sistema sin comprometer la velocidad o la precisión. RAG a menudo se implementa con algunas bases de datos vectoriales diseñadas específicamente para almacenar información como vectores. Sin embargo, estas bases de datos pueden tener problemas para manejar consultas complejas, lo que plantea un desafío para mantener la efectividad del sistema en medio de preguntas complejas.
# Desafíos enfrentados por las bases de datos vectoriales especializadas
No hay duda de que estas bases de datos vectoriales especializadas son buenas para manejar datos vectoriales, pero también tienen sus propios problemas.
- Las bases de datos vectoriales especializadas no son compatibles con el sistema de datos maduro
Un gran problema es integrar bases de datos vectoriales especializadas en sistemas de datos grandes existentes. La mayoría de las empresas utilizan bases de datos SQL para sus grandes colecciones de datos. La transición a bases de datos vectoriales especializadas puede plantear desafíos significativos de integración, lo que provoca la creación de silos de datos y dificulta el trabajo con otros sistemas.
- Las bases de datos vectoriales especializadas tienen dificultades para manejar escenarios de datos complejos
Es importante destacar que las bases de datos vectoriales especializadas están diseñadas principalmente para implementar búsquedas de vecinos más cercanos. Enfrentan desafíos cuando se enfrentan a consultas relacionadas con funciones basadas en el tiempo o funciones de agregación. Esta limitación puede plantear problemas en escenarios donde estas consultas son esenciales, complicando aún más su integración y utilización en entornos de datos diversos.
- Las bases de datos vectoriales especializadas no son amigables para los desarrolladores comunes
Además, debido a que estas bases de datos son tan especializadas, los científicos de datos e ingenieros que están acostumbrados a SQL pueden encontrarlas difíciles de aprender. Esto puede ralentizar la rapidez con la que se adoptan y limitar la utilización de estas bases de datos avanzadas. Además, si bien las bases de datos vectoriales son excelentes para manejar datos vectorizados, a menudo carecen de funciones completas para administrar datos estructurados y relacionales, que aún son predominantes en muchas aplicaciones industriales.
Artículo relacionado: Cómo funciona RAG (opens new window)
# ¿Por qué SQL es importante para la gestión y almacenamiento de datos?
SQL ha sido el sistema de gestión de bases de datos confiable y de referencia durante bastante tiempo. Es conocido por su eficiencia, seguridad y versatilidad en el manejo de grandes cantidades de datos en diversas industrias.
# SQL puede manejar grandes volúmenes de datos
SQL es conocido por su capacidad para consultar y gestionar eficientemente grandes cantidades de datos, manteniendo al mismo tiempo la velocidad y precisión. El poder de SQL radica en su motor de consulta optimizado y sus estructuras de almacenamiento de datos eficientes. Los sistemas de bases de datos SQL suelen emplear técnicas sofisticadas de indexación y estrategias de particionamiento de datos para garantizar un acceso y recuperación rápidos de la información, incluso al tratar con datos estructurados a gran escala, lo que ayuda a las empresas a expandirse sin problemas.
# SQL es confiable
La confiabilidad es otra característica clave de SQL. Esta confiabilidad se deriva de varios factores clave inherentes a las bases de datos SQL, como la consistencia de los datos, los mecanismos sólidos de recuperación de datos, el manejo de grandes volúmenes de datos y altos niveles de tráfico concurrente. La base de datos SQL utiliza técnicas de optimización como la indexación, la optimización de consultas y el almacenamiento en caché para garantizar una recuperación y procesamiento eficientes de datos, manteniendo la confiabilidad incluso a medida que la base de datos crece en tamaño y complejidad.
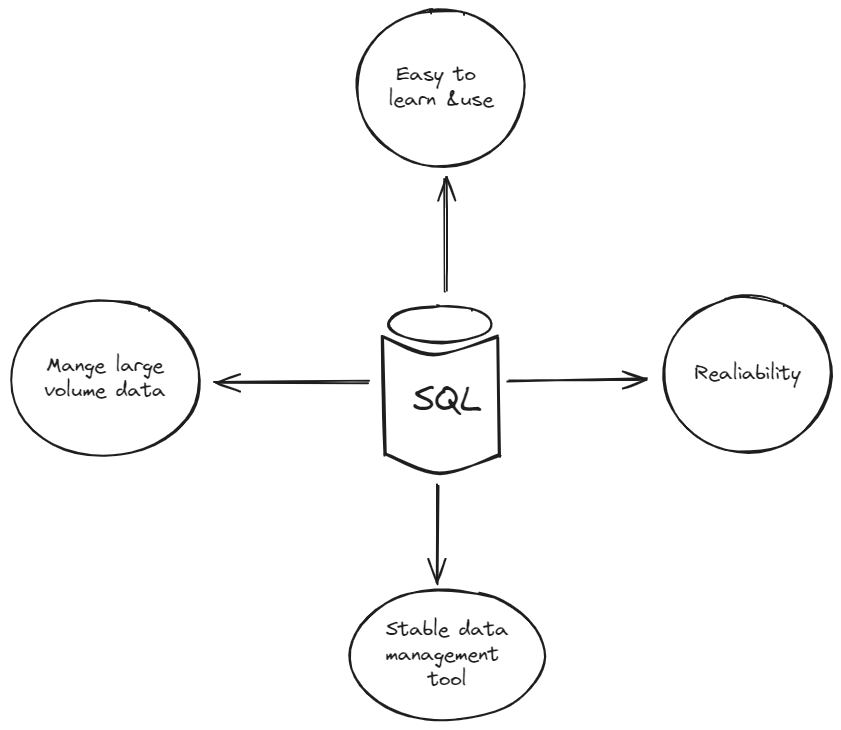
# SQL proporciona herramientas avanzadas de procesamiento de datos
SQL también tiene herramientas y características poderosas para mejorar la gestión de datos. Le brinda a los desarrolladores la capacidad de optimizar y mejorar el rendimiento de las consultas según las demandas y patrones únicos de la aplicación. A través de capacidades como la indexación, el particionamiento y la optimización de consultas, SQL mejora significativamente la eficiencia y velocidad de recuperación y procesamiento de datos. Esto puede hacer que las aplicaciones que dependen de los datos se ejecuten más rápido y brinden a los usuarios una mejor experiencia. Además, SQL tiene excelentes herramientas para encontrar y solucionar cualquier ralentización, asegurando que los sistemas de datos funcionen bien en diferentes situaciones.
Artículo relacionado: Cuando SQL WHERE se encuentra con la búsqueda vectorial (opens new window)
# ¿Por qué SQL es importante para RAG?
La construcción de un sistema de generación con recuperación aumentada (RAG) conlleva varios desafíos, pero SQL podría ayudar a abordarlos:
- SQL puede ayudar a recuperar datos complejos
Recuperar información relevante de conjuntos de datos vastos y diversos puede ser complejo, especialmente al tratar con fuentes de datos no estructurados o semi-estructurados como documentos de texto, imágenes o multimedia. Integrar mecanismos de recuperación eficientes que puedan manejar esta complejidad es un desafío importante. Las capacidades de consulta de SQL permiten la recuperación eficiente de información relevante de estas fuentes de datos. Al generar consultas SQL adaptadas a criterios específicos y utilizar funcionalidades de búsqueda avanzadas, SQL puede agilizar el proceso de recuperación de datos, abordando así la complejidad de acceder a conjuntos de datos diversos.
- SQL puede ayudar a recuperar datos de calidad
Garantizar la calidad y relevancia de los datos recuperados es crucial para generar respuestas precisas y significativas. Sin embargo, los datos ruidosos o desactualizados, así como la información irrelevante, pueden afectar negativamente el rendimiento del sistema RAG. Desarrollar algoritmos para filtrar y clasificar eficazmente los datos recuperados es un desafío. SQL proporciona mecanismos para filtrar y clasificar los datos recuperados en función de diversos criterios, como marcas de tiempo, categorías o puntuaciones de relevancia. Además, las funciones de agregación y análisis de SQL permiten a los desarrolladores preprocesar y limpiar los datos, asegurando su calidad antes de utilizarlos para la generación.
- SQL en conjunto con otras técnicas puede mejorar la interpretación de datos
Comprender el significado semántico y el contexto de los datos recuperados es importante para generar respuestas coherentes y relevantes. Sin embargo, interpretar los matices del lenguaje natural y el contexto es una tarea compleja, especialmente al tratar con información ambigua o subjetiva. Si bien SQL en sí mismo no proporciona capacidades inherentes de comprensión semántica, se puede utilizar en conjunto con otras técnicas de Procesamiento del Lenguaje Natural (NLP, por sus siglas en inglés) como los embeddings para mejorar la comprensión semántica de los datos. Por ejemplo, los desarrolladores pueden usar SQL para recuperar datos basados en palabras clave o información contextual y luego utilizar algoritmos de análisis semántico para interpretar aún más el significado de los datos recuperados.
- SQL proporciona escalabilidad y flexibilidad
A medida que los conjuntos de datos crecen en tamaño y complejidad, la escalabilidad se convierte en un desafío importante para los sistemas RAG. Asegurar que el sistema pueda manejar volúmenes crecientes de datos mientras mantiene el rendimiento y la capacidad de respuesta requiere un diseño de arquitectura eficiente y estrategias de optimización. Las bases de datos SQL están diseñadas para gestionar grandes cantidades de datos estructurados de manera eficiente. La integración de SQL con los sistemas RAG aborda uno de los desafíos clave en el campo de la Inteligencia Artificial: escalar el mecanismo de recuperación para manejar conjuntos de datos extensos sin comprometer el rendimiento. Además, la flexibilidad de SQL en la formulación de consultas permite que RAG realice una recuperación de información compleja, ajustando la amplitud y profundidad de los datos considerados durante el proceso de generación.
- SQL ayuda a recuperar datos en tiempo real
Proporcionar respuestas en tiempo real es crucial para muchas aplicaciones de los sistemas RAG, como chatbots o asistentes virtuales. Lograr tiempos de respuesta bajos en latencia mientras se mantiene la calidad del contenido generado plantea un desafío, especialmente en escenarios con requisitos estrictos de latencia. Las técnicas de optimización de SQL, como el almacenamiento en caché y la indexación de consultas, pueden reducir significativamente los tiempos de procesamiento de consultas, lo que permite que los sistemas RAG proporcionen respuestas en tiempo real.
Artículo relacionado: Una inmersión profunda en las bases de datos vectoriales SQL (opens new window)

# MyScaleDB: la mejor base de datos vectorial SQL para RAG
Teniendo en cuenta la rápida expansión de los volúmenes de datos y las limitaciones específicas que enfrentan las bases de datos vectoriales especializadas, hemos desarrollado MyScaleDB. MyScaleDB (opens new window) es una base de datos vectorial SQL basada en la nube, especialmente diseñada y optimizada para gestionar grandes volúmenes de datos para aplicaciones de inteligencia artificial. Está construida sobre ClickHouse (opens new window) (una base de datos SQL), combinando la capacidad de búsqueda de similitud vectorial con el soporte completo de SQL. Es una base de datos vectorial SQL, lo que significa que puedes almacenar tus vectores junto con datos estructurados.
A diferencia de las bases de datos vectoriales especializadas, MyScaleDB integra sin problemas algoritmos de búsqueda vectorial con bases de datos estructuradas, lo que permite gestionar tanto vectores como datos estructurados en la misma base de datos. Esta integración ofrece ventajas como una comunicación simplificada, filtrado flexible de metadatos, soporte para consultas conjuntas de SQL y vectores, y compatibilidad con herramientas establecidas que se utilizan típicamente con bases de datos versátiles de propósito general.
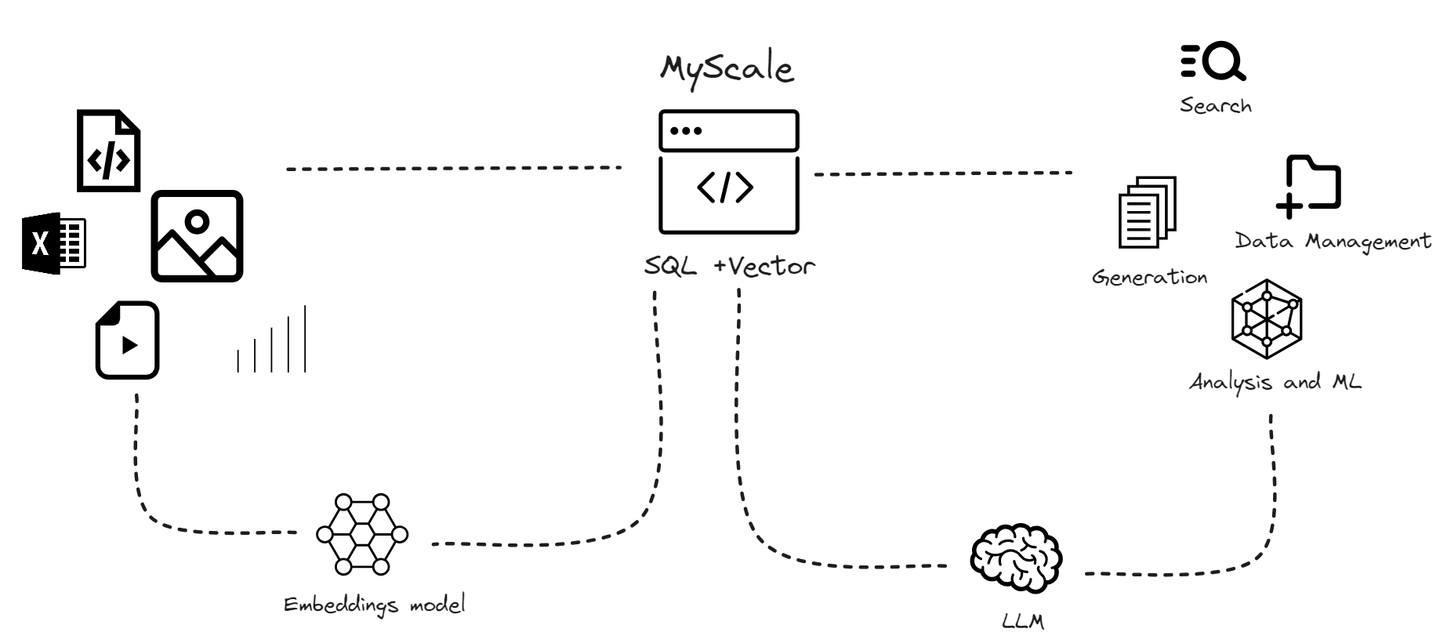
MyScaleDB se destaca por la integración de SQL con sistemas RAG. A diferencia de las bases de datos vectoriales tradicionales que tienen dificultades con consultas complejas y compatibilidad, MyScaleDB está diseñada para satisfacer las necesidades específicas de los sistemas RAG de manera fluida.
- En primer lugar, el soporte avanzado de MyScaleDB para consultas SQL complejas permite que los sistemas RAG realicen operaciones sofisticadas de recuperación de datos que antes no eran factibles. Esta característica permite respuestas más relevantes y contextualmente apropiadas, mejorando así la experiencia del usuario.
- MyScaleDB está diseñada específicamente para aplicaciones de inteligencia artificial a gran escala, asegurando un alto rendimiento y rentabilidad. Mantiene constantemente una alta velocidad y precisión incluso en conjuntos de datos muy grandes con soporte completo de SQL. Un solo pod c1x1 admite hasta 10 millones de vectores de 768D, mientras que el pod s1x1 alcanza más de 150 QPS con 5 millones de vectores.
- Además, MyScaleDB se destaca por sus métricas de rendimiento, gestionando sin esfuerzo conjuntos de datos grandes y complejos y proporcionando tiempos de respuesta más rápidos que las bases de datos vectoriales tradicionales.
Este beneficio de rendimiento hace que MyScaleDB sea particularmente adecuada para aplicaciones en tiempo real donde la velocidad es fundamental. MyScale ofrece almacenamiento gratuito para hasta 5 millones de vectores para cada nuevo usuario. Puedes desarrollar fácilmente una versión MVP de cualquier aplicación de mediana o gran escala. Puedes visitar la página de inicio de MyScaleDB (opens new window) para crear una cuenta gratuita y configurar un pod gratuito en 2 minutos.
Artículo relacionado: Primeros pasos con MyScale (opens new window)
# Conclusión
A medida que aumenta la demanda de aplicaciones sofisticadas basadas en conocimientos, la integración de SQL con los sistemas de generación con recuperación aumentada marca un gran avance. Esta combinación no solo aborda los problemas de escalabilidad y eficiencia de las bases de datos vectoriales especializadas, sino que también aprovecha la fortaleza y familiaridad de SQL, lo que hace que los sistemas RAG avanzados sean más amigables y prácticos para los desarrolladores.
MyScaleDB está a la vanguardia de esta integración, ofreciendo un rendimiento, compatibilidad y facilidad de uso incomparables. Al optar por MyScaleDB, los desarrolladores y las organizaciones pueden aprovechar al máximo el potencial de sus aplicaciones de inteligencia artificial. Si estás planeando construir una aplicación a gran escala o tu plan implica desarrollar una aplicación en una base de datos grande existente, MyScaleDB podría ser una base de datos vectorial ideal para ti.
Si tienes alguna sugerencia, puedes comunicarte con nosotros a través de Twitter (opens new window) y Discord (opens new window).



