
Retrieval Augmented Generation(RAG)は、外部の知識ベースと接続することでLLMのパフォーマンスを向上させます。これには、コスト/リソースの削減、特定のドメイン知識に基づいたLLMの最適化、データのセキュリティなど、多くの利点があります。RAGは、深層学習の文脈では比較的新しい技術です[1]が、その使用は非常に広範であり、日々増加しています。
RAGの使用が増えるにつれ、その性能も継続的に改善されています。RAGシステムの制約が発見されるにつれ、研究者はその性能を向上させる方法を特定してきました。今日は、クエリの改善について話しましょう。
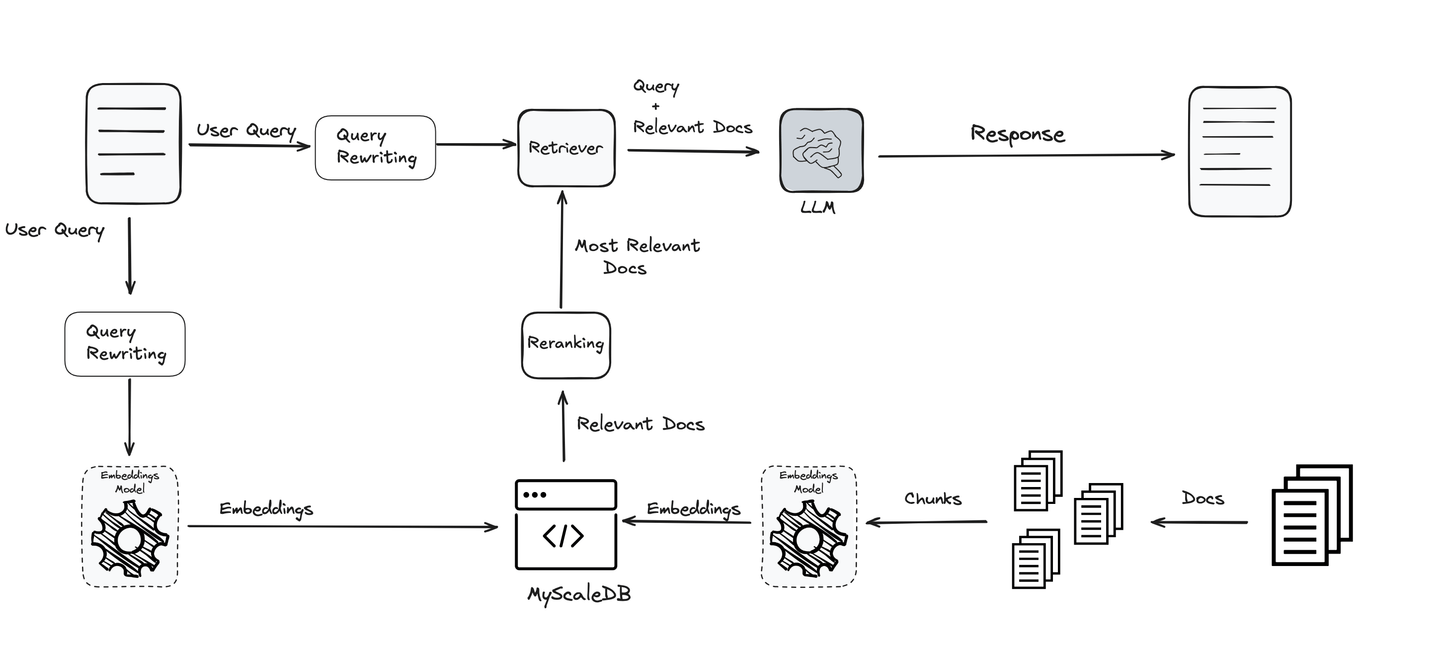
クエリの書き換えステップを追加
クエリは、RAGパイプライン全体で最も重要な部分の1つです。求める内容によって方向が決まり、LLMと他のツールがそれに基づいて情報を提供します。クエリが明確で最適化されていない場合、最高のシステムでも十分な結果を得ることができません。そのため、クエリの改善と洗練は、正確で意味のある結果を得るための鍵です。
この重要性を念頭に置いて、さまざまな技術が使用され、クエリを最適化し明確にするために使用されます。これらの技術により、システムはより効果的で信頼性のあるものになり、RAGパイプラインの各段階をサポートします。
# クエリの言い換え
(主に素人の)ユーザーが書いたクエリは、LLMの観点からはほとんど判断できず、経験からもわかるように、これらのクエリには改善の余地がたくさんあります。LLMや他の検索システムは特定の単語にも敏感に反応することがありますので、クエリの言い換えは、クエリをより理解しやすく最適化することができます。
例:
これをさらに説明するために、[2]から引用した例を挙げます。彼らが提供した元のクエリは次のようなものでした:
車の製造工場は、次の工場を建設する前に、コミュニティの計画者が最も関心を持つであろうものは次のうちどれですか?
このクエリはLLMによって正確に理解されるには複雑すぎて、それに答えることができませんでした。リライトを使用した後の言い換えられたクエリは次のようになります:
車の製造工場を建設する前に、コミュニティの計画者が最も関心を持つであろうものは何ですか?
これは完璧に機能し、正しい答えも返します。
クエリを書き換えるためのいくつかの技術があります。一部は同義語で置き換える方法、一部はメタデータを追加 (opens new window)する方法、一部は文法を改善することに焦点を当てる方法、一部はクエリをより意味のある形に展開する方法(一部の方法では元のクエリの順列を生成 (opens new window)することさえあります)、などです。興味深いことに、これらの方法のいくつかはLLMを含んでいます (opens new window)。そのため、LLMを使用して入力を別の(または同じ)LLMに改善するために、LLMを再帰的に使用することになります。
# クエリの正規化
クエリの正規化は、元のクエリの文法やスペルなどを修正するための簡単な方法を指します。同様に、小文字化やストップワードの削除などの前処理もクエリの正規化に使用できます。
例えば、「ブラザーズ・カラマゾフの著者は誰ですか?」は、「broter karamovを書いたのは誰ですか」と比べて理解しやすいです。後者のクエリのスペルミスに注目してください。
ここで注意すべきは、LLMは通常、正規化をあまり行わずに文を理解できる強力なトランスフォーマーモデルです。そのため、入力の正規化と過剰な正規化のバランスを取る必要があります。
# クエリの展開
ほとんどの場合、クエリがうまく機能するかどうかはわかりませんので、クエリの複数の順列を作成し、それぞれの結果を返すという一般的な方法があります。いくつかの古典的な言い換え方法もありますが、前述のように、LLM自体がそれに非常に適していることに気付いたことでしょう。
以下は、LangChainとOpenAIのGPT-4モデルを使用した例です(元の例はLangChain (opens new window)から取られています)。
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain.output_parsers import PydanticToolsParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
class ParaphrasedQuery(BaseModel):
"""You have performed query expansion to generate a paraphrasing of a question."""
paraphrased_query: str = Field(
...,
description="A unique paraphrasing of the original question.",
)
system = """You are an expert at converting user questions into database queries. \
You have access to a database of tutorial videos about a software library for building LLM-powered applications. \
Perform query expansion. If there are multiple common ways of phrasing a user question \
or common synonyms for key words in the question, make sure to return multiple versions \
of the query with the different phrasings.
If there are acronyms or words you are not familiar with, do not try to rephrase them.
Return at least 3 versions of the question."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.25)
llm_with_tools = llm.bind_tools([ParaphrasedQuery])
query_analyzer = prompt | llm_with_tools | PydanticToolsParser(tools=[ParaphrasedQuery])
クエリエキスパンダーを作成したので、それを使用することができます。例えば:

クエリの展開結果
見ての通り、それは素敵な順列を提供してくれます(さらに順列の数を増やすこともできます)。
# コンテキストの適応
コンテキストの適応プロセスは、特定の文脈に合わせてクエリをより適切に調整することを指します。これは、リインフォースメントラーニング(RL)を活用して達成されることが多く、リファレンス学習によってクエリのフレーズを最適化することができます。ある方法では、小さな言語モデル(LM)をクエリの言い換えツールとして使用し、インターネットデータなどの外部ソースを活用してクエリのコンテキストを豊かにします。RLコンポーネントは、この適応を微調整し、与えられたコンテキストでの言い換えクエリのパフォーマンスがどれだけ良いかに基づいて学習します。このアプローチは、[2]や[3]で参照されているようなさまざまな研究で探求され、クエリの関連性とパフォーマンスの向上においてその効果が示されています。
# クエリの分解
クエリにはしばしば2つ(またはそれ以上)の異なるクエリが含まれており、これによりLLMが理解するのが難しくなります。さらに、LLMは関係のない文脈にも敏感です[4]。例えば、ジェシカの年齢の古典的な例では、関係のない文(赤色の文)の導入はLLMを混乱させる可能性があります。

効率的なクエリ理解の例([4]から引用)は、クエリの分解の必要性を示しています。赤色で下線が引かれた文は、クエリを不必要に複雑にし、LLMの理解をさらに困難にします。
ここでのより良い解決策は、次のようにクエリを分解することです:
“ジェシカはクレアより6歳年上です。2年後、クレアは20歳になります。” “20年前、クレアの父の年齢はジェシカの年齢の3倍でした。” “ジェシカは今何歳ですか?”
おそらく、2番目の文も省略できるでしょう。
# クエリの分解における課題
クエリの分解には、より明確さとLLMのステップバイステップの推論を支援するという利点があります。しかし、クエリの分解にはいくつかの課題もあります。
- 過度の分割:クエリを過度に分解すると、文脈が希薄になり、関連性の低い結果になる可能性があります。
- 結果の結合:サブクエリからの結果を集約することは難しい場合があります。特に、それらが矛盾しているか不完全な場合はさらに難しいです。
- クエリの依存関係:一部のクエリは、前のステップの結果に依存しており、反復的なプロセスが必要です。
- コストとレイテンシー:クエリを複数のパーツに分割すると、検索と計算のステップ数が増え、計算コストが高くなる可能性があります。
クエリの分解は有望ですが、課題があることがわかったように、まだ改善の余地がたくさんあります。使用するかどうかについて疑問がある場合は、特にコストを節約するために、安全側に立つことをお勧めします。
# 埋め込みの最適化
埋め込みは通常、BERT (opens new window)やTitan (opens new window)などの一般的なNLPモデルを使用して生成されます。これらの埋め込みは多くのアプリケーションには非常に優れていますが、より良い理解のために最適化する必要があることもしばしばあります。そのため、Massive Text Embedding Benchmark(MTEB) (opens new window)などのベンチマークも提案されており、これらの埋め込みが分類、クラスタリング、要約などの8つの異なるタスクでどれだけ優れたパフォーマンスを発揮するかをチェックすることができます。
“私たちは、異なるタスクにおいて異なるモデルが優れていることを発見しました。” - MTEB論文
MTEBが正しく発見したように、すべてのタスクにおいて単一の最適な解決策はありません。要約にはあるモデルが良く、分類には別のモデルが良いなど、タスクによってモデルの優れた性能が異なります。また、すべてのデータセットに対しても一概に言えるわけではありません。同じタスクでも、モデルは一部のデータセットで優れた結果を示す一方で、他のデータセットでは劣った結果を示すことがあります。
# 架空のドキュメント埋め込み(HyDE)
2022年、研究者たちは新しいゼロショットの手法を提案しました[6]。このユニークな手法は、架空のドキュメントを作成し、その埋め込みを使用して埋め込み空間で類似した(実際の)ドキュメントを見つけるという概念に基づいています。HyDEは、RAGにおけるクエリの最適化ツールとして人気を集めています。HyDEの方法論は次のように要約できます:
- 架空のドキュメントを生成する
- 埋め込みを計算する
- 埋め込みを使用してベクトルデータベースをクエリする
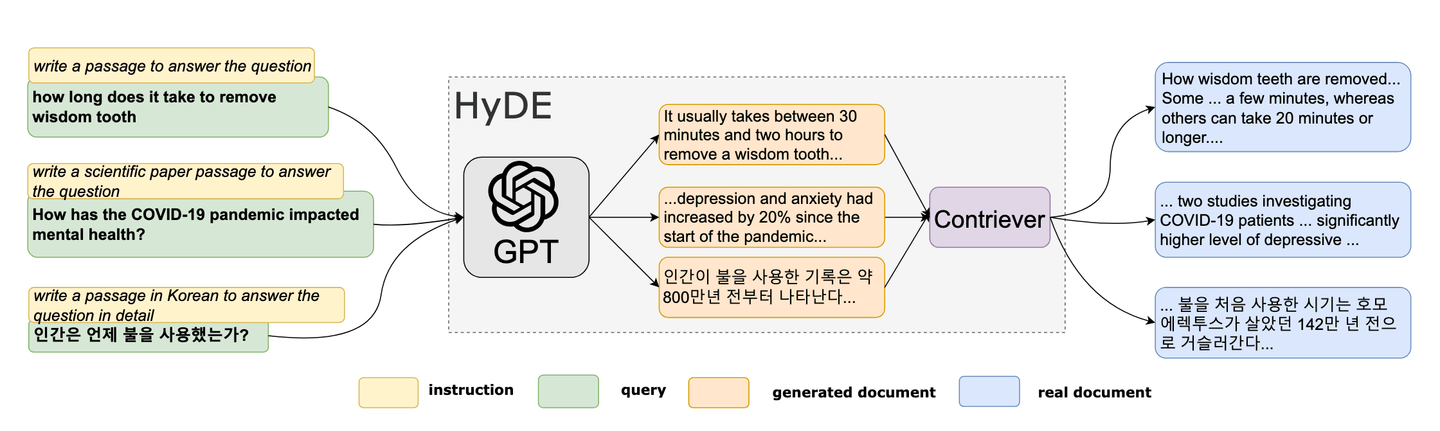
参考:HyDE論文 [6]
# 架空のドキュメントの作成
最初のステップとして、クエリを取り、それを使用して架空のドキュメントを生成します。例えば、後で示す例のように、LLMに「この質問に答えるドキュメントを作成してください」と促すだけで生成できます。
# 埋め込みの計算
計算には、任意のモデルやサービス(MyScaleも独自のEmbedText()メソッドを提供しています)を使用して、これらの埋め込みを計算することができます。これらの(架空のクエリ)埋め込みが利用可能になったら、ベクトルデータベースをクエリするために使用することができます。
最も類似したテキストを架空のクエリから取得したら、それらを(元の)クエリとともにLLMに渡して応答生成を行います。
# HyDEの例
例えば、いくつかの埋め込みがMyScaleのDocEmbeddingsテーブルに格納されているとします。次のようにCosine類似度を使用して、トップ10の類似したドキュメントをクエリできます。
ステップ1:架空のドキュメントの生成
最初のステップとして、クエリを取り、OpenAIのGPT-4(mini)モデルを使用して架空のドキュメントを生成します(ほとんどのタスクには、GPT4-miniが十分であり、コストを節約できます)。
from openai import OpenAI
openai_client = OpenAI(api_key='sk-xxxxx')
def Make_HyDoc(query):
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "system", "content": "Make a document that answers the question:"},
{"role": "user", "content": f"{query}"}],
max_tokens=100
)
return response.choices[0].message
これで、この関数を使用してクエリに基づいて架空のドキュメントを生成することができます。
ステップ2:埋め込みの計算
埋め込みを計算するために、MyScaleの組み込みのEmbedText()を使用して、埋め込みを直接計算します。
service_provider = 'OpenAI'
hypoDoc = Make_HyDoc("What was the solution proposed to farmers problem by Levin?")
parameters = {'sampleString': hypoDoc, 'serviceProvider': service_provider}
x = client.query("""
SELECT EmbedText({sampleString:String}, {serviceProvider:String}, '', 'sk-*****', '{"model":"text-embedding-3-small", "batch_size":"50"}')
""", parameters=parameters)
input_embedding = x.result_rows[0][0]
ステップ3:埋め込みを使用してベクトルDBをクエリ
これで、input_embeddingに埋め込みがありますので、単純なSQLクエリを使用して、すでにテーブル(この場合はDocEmbeddings)に格納されているベクトルと比較することができます。
SELECT
id,
title,
content,
cosineDistance(embedding, input_embedding) AS similarity
FROM
DocEmbeddings
ORDER BY
similarity ASC
LIMIT
10;
Pythonで実行し、データフレームとして表示することができます。
import pandas as pd
query = f"""
SELECT
id,
sentences,
cosineDistance(embeddings, {input_embedding}) AS similarity
FROM
DocEmbeddings
LIMIT
10
"""
df = pd.DataFrame(client.query(query).result_rows)
最も関連性の高いドキュメントが返されます:

HyDEの結果

# 結論
RAGは、LLMの機能を向上させる強力で費用効果の高いツールですが、制約もあります。このブログ記事では、RAGプロセスの一環としてクエリの改善に焦点を当てました。言い換え(しばしばLLMを使用)、クエリの分解、埋め込みの品質の最適化、HyDEなど、さまざまな技術を探求しました。これらの方法は価値がありますが、RAGパイプライン全体を向上させるためのさまざまな方法もあります。次の記事では、チャンキング戦略について詳しく説明し、データを異なるタイプにチャンク分けする方法について議論します。
# 参考文献
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS. https://arxiv.org/abs/2005.11401
- Ma, X., Gong, Y., He, P., Zhao, H., & Duan, N. (2023). Query Rewriting for Retrieval-Augmented Large Language Models. EMNLP. https://arxiv.org/abs/2305.14283
- Anand, A., V, V., Setty, V., & Anand, A. (2023). Context Aware Query Rewriting for Text Rankers using LLM. ArXiv. https://arxiv.org/abs/2308.16753
- Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H. Chi, Nathanael Schärli, and Denny Zhou. Large language models can be easily distracted by irrelevant context. ICML, 2023.
- Muennighoff, N., Tazi, N., Magne, L., & Reimers, N. (2022). MTEB: Massive Text Embedding Benchmark. ArXiv. https://arxiv.org/abs/2210.07316
- Gao, L., Ma, X., Lin, J., & Callan, J. (2022). Precise Zero-Shot Dense Retrieval without Relevance Labels. ArXiv. https://arxiv.org/abs/2212.10496



