
大規模言語モデル (LLMs) は、情報へのアクセスと理解の方法を革命的に変えました。これらの高度な AI システムは膨大なデータで訓練されており、言語のパターンや意味を認識することができます。文脈の中で単語を理解することで、アイデアを探求し、新しいことを学び、迅速かつ効率的に答えを見つけることが容易になります。LLM は、日常生活における情報とのインタラクションの新しい時代を形作っています。
初期の従来型 LLM は、静的な訓練データから提供された知識のみに依存していました。この制限は、モデルが古いまたは不完全なデータのために不正確または虚偽の情報を生成する「幻覚」を引き起こすことがよくあります。これらの問題を認識し、リトリーバル拡張生成 (RAG) の概念が導入されました。
# リトリーバル拡張生成 (RAG)
リトリーバル拡張生成 (RAG) (opens new window) の背後にあるアイデアは、LLM の応答品質を向上させるために信頼できるデータベースを提供することでした。訓練中に学んだ情報のみに依存するのではなく、RAG は LLM が MyScale (opens new window) のような ベクターデータベース (opens new window) にアクセスしてリアルタイムデータを取得できるようにします。
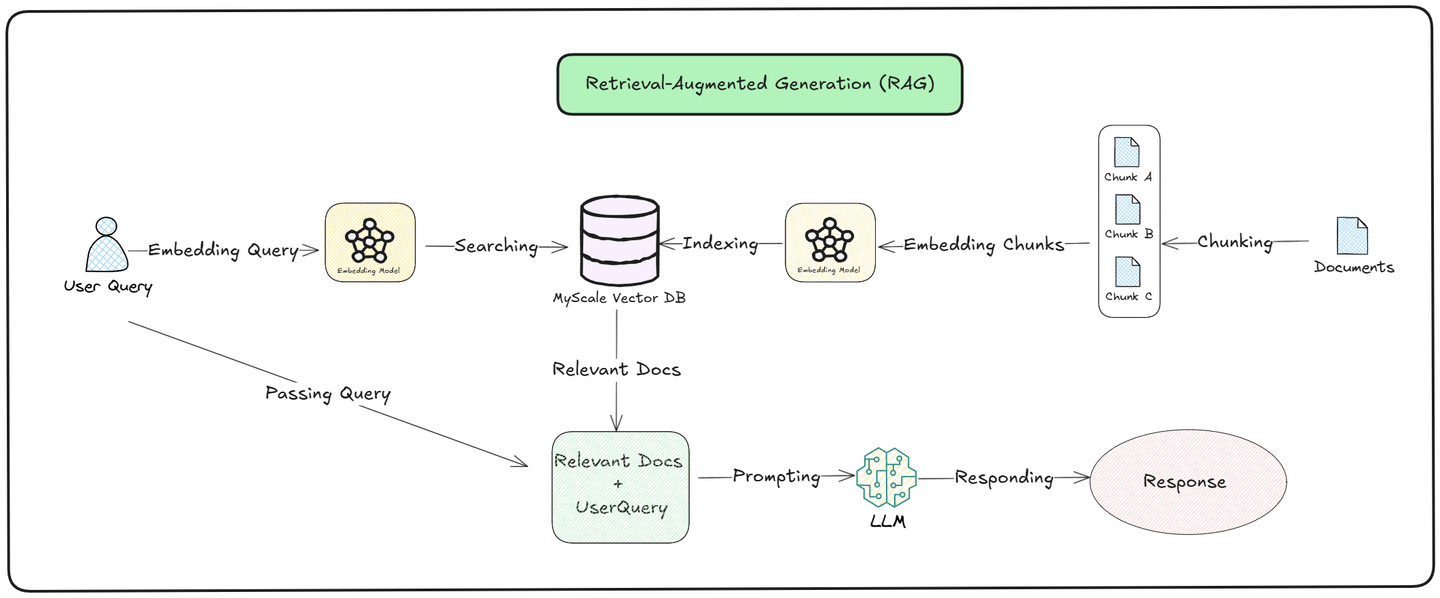
上の図に示すように、クエリプロセスは リトリーバル (opens new window) と 生成 (opens new window) の2つの部分に分かれています。
リトリーバル: モデルは外部の 知識ベース から関連する文書を検索します。ユーザーのクエリをベクターに変換し、保存されたデータと比較します。最も類似した文書が取得され、クエリへの関連性に基づいてランク付けされ、モデルが正確で最新の情報を引き出すことを保証します。
生成: 関連する文書を取得した後、モデルは取得した情報と事前に訓練された知識の両方を使用して応答を生成します。新たに見つかったデータと既に知っていることを組み合わせて、ユーザーの質問に対して文脈的に正確で関連性のある答えを生成します。
RAG は間違いなく応答の正確性と品質を向上させます。しかし、そのパイプラインは静的に動作します。ユーザーがクエリを行うたびに、同じプロセスが繰り返されます: ベクターデータベースから関連情報が取得され、LLM に渡されて応答が生成されます。この一貫性は信頼性を保証しますが、特定の文脈やシナリオに動的に適応する能力を制限します。
RAG の静的パイプラインの限界を克服するために、ReACT (推論と行動) (opens new window) や エージェント (opens new window) のような新しい手法が導入されました。これらのツールは、次の要素を追加することでシステムがユーザーのクエリにより良く応答できるようにします:
- 推論
- 意思決定
- タスク実行
これらは、論理的思考と単純な行動を組み合わせて、より正確で柔軟なものにするためのエージェンティック RAG のような高度なシステムの基盤です。
# ReACT とは
ReACT、つまり「推論と行動」は、LLM の動作における画期的な進展です。従来のモデルが迅速な回答を提供するのに対し、ReACT は AI が問題を段階的に考えるのを助けます。このアプローチは、チェーン・オブ・ソート (CoT) と呼ばれ、モデルが複雑なタスクをより効果的に解決できるようにします。
2022 年の研究論文で、Yao とそのチームは、推論と行動を組み合わせることで AI をより賢くできることを示しました。従来のモデルは複雑な問題に苦しむことが多いですが、ReACT はそれを変えます。AI が一時停止し、批判的に考え、より良い解決策を開発するのを助けます。
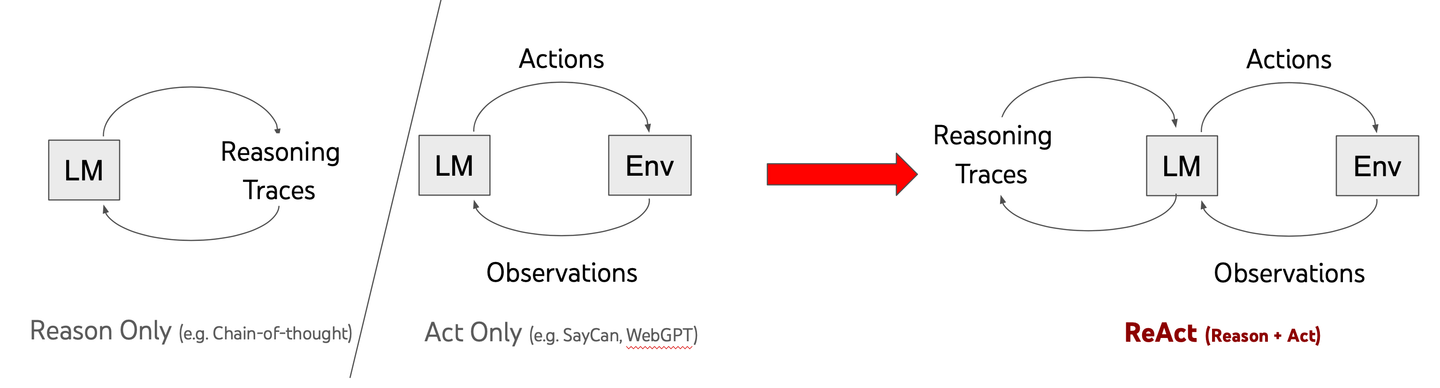
重要な違いは、問題解決のアプローチにあります。答えを急いで出すのではなく、ReACT を搭載したモデルは課題を体系的に分解します。これにより、実世界の問題に取り組む際に、より適応性があり信頼性の高いものになります。
AI に行動する前に推論することを教えることで、ReACT は人工知能の可能性の限界を押し広げています。情報を持つだけではなく、その情報を賢く使うことが重要です。
# ReACT の仕組み
ReACT は、体系的な推論プロセスと実行可能なステップを統合することで LLM の能力を強化します。このフレームワークは、次の段階を通じて機能します:

クエリ分析: モデルはユーザーのクエリを管理可能なコンポーネントに分解します。
チェーン・オブ・ソート推論: LLM は段階的に推論し、各コンポーネントを分析し、必要なアクションを決定します。たとえば、情報を取得したり、データをクロスチェックしたり、複数のソースを論理的に組み合わせたりすることがあります。
アクション実行: 推論に基づいて、モデルは外部ツールと対話したり、特定のデータを取得したり、新しい情報が利用可能になるとクエリを再評価したりします。
反復的改善: ReACT は、ステップを進めるにつれて推論を洗練させることができ、中間結果に基づいて動的に調整します。
この段階的な推論は、人間が複雑な問題を解決する方法に似ており、最終的な応答が十分に考慮され、文脈的に関連性があることを保証します。たとえば、「ReACT とエージェントの主な違いは何ですか?」というクエリがある場合、モデルは最初にコンポーネントを特定し(たとえば、ReACT の定義、エージェントの定義)、次にそれらを順次推論して完全な答えを合成します。
# エージェントの紹介
ReACT が LLM 内での推論に焦点を当てる一方で、エージェント はモデルの外で特定のタスクを実行する役割を担います。エージェントは、LLM によって提供された指示に基づいて行動する自律的な存在であり、システムが外部ツール、API、データベースと対話したり、複雑なマルチステップのワークフローを実行したりすることを可能にします。
# エージェントの仕組み
- タスクの特定: LLM は、しばしば ReACT の推論に導かれて、特定のタスクに必要なエージェントを決定します。たとえば、最近の天候条件に関するクエリは、リアルタイムの天気更新を取得するために データ取得エージェント を起動するかもしれません。
- 実行: 選択されたエージェントがタスクを実行します。これには、データベースへのクエリ、ウェブコンテンツのスクレイピング、API の呼び出し、計算の実行が含まれる可能性があります。
- フィードバックループ: タスクが完了すると、エージェントは結果を LLM に返し、さらなる推論や応答生成を行います。
- 複数エージェントの連携: より複雑なシナリオでは、複数のエージェントが連携して動作することができます。たとえば、1 つのエージェントが生データを取得し、別のエージェントがそれを処理し、3 番目のエージェントが最終出力を視覚化またはフォーマットします。
# エージェントとモジュール性
エージェントはモジュール設計であり、さまざまなアプリケーションにカスタマイズできます。例としては:
- リトリーバルエージェント: ベクターデータベースや知識グラフからデータを取得します。
- 要約エージェント: 取得した情報を要点にまとめます。
- 計算エージェント: 計算やデータ変換を必要とするタスクを処理します。
- API インタラクションエージェント: 外部サービスと統合してリアルタイムの更新を取得します。
このモジュールアプローチにより、特定の要件を満たすために新しいエージェントを追加できる柔軟性とスケーラビリティが実現されます。
# エージェンティック RAG とは
エージェンティック RAG は、ReACT の推論能力とエージェントのタスク実行能力を組み合わせて、動的で適応的なシステムを作り出します。従来の RAG が固定されたパイプラインに従うのに対し、エージェンティック RAG は、ユーザーのクエリの文脈に基づいてエージェントを動的に調整するために ReACT を使用することで柔軟性を導入します。これにより、システムは情報を取得し生成するだけでなく、文脈、進化する目標、および相互作用するデータに基づいて情報に基づいた行動を取ることができます。
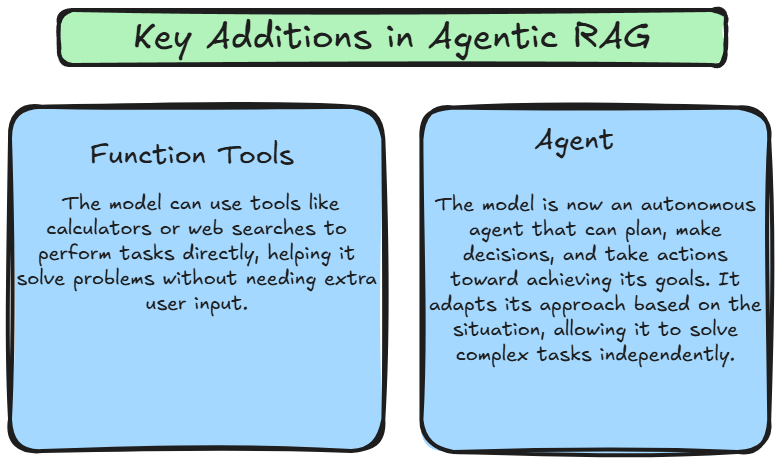
これらの進展により、エージェンティック RAG ははるかに強力で柔軟なフレームワークとなります。モデルはもはやユーザーのクエリに受動的に反応するだけではなく、独立して問題を解決するために計画、実行、アプローチを適応させることができます。これにより、システムはより複雑なタスクを処理し、新しい課題に動的に適応し、より文脈的に正確な応答を提供できるようになります。
# エージェンティック RAG の仕組み
エージェンティック RAG の重要な革新は、ツールを自律的に使用し、意思決定を行い、次のステップを計画する能力にあります。パイプラインは次のコアステージに従います:
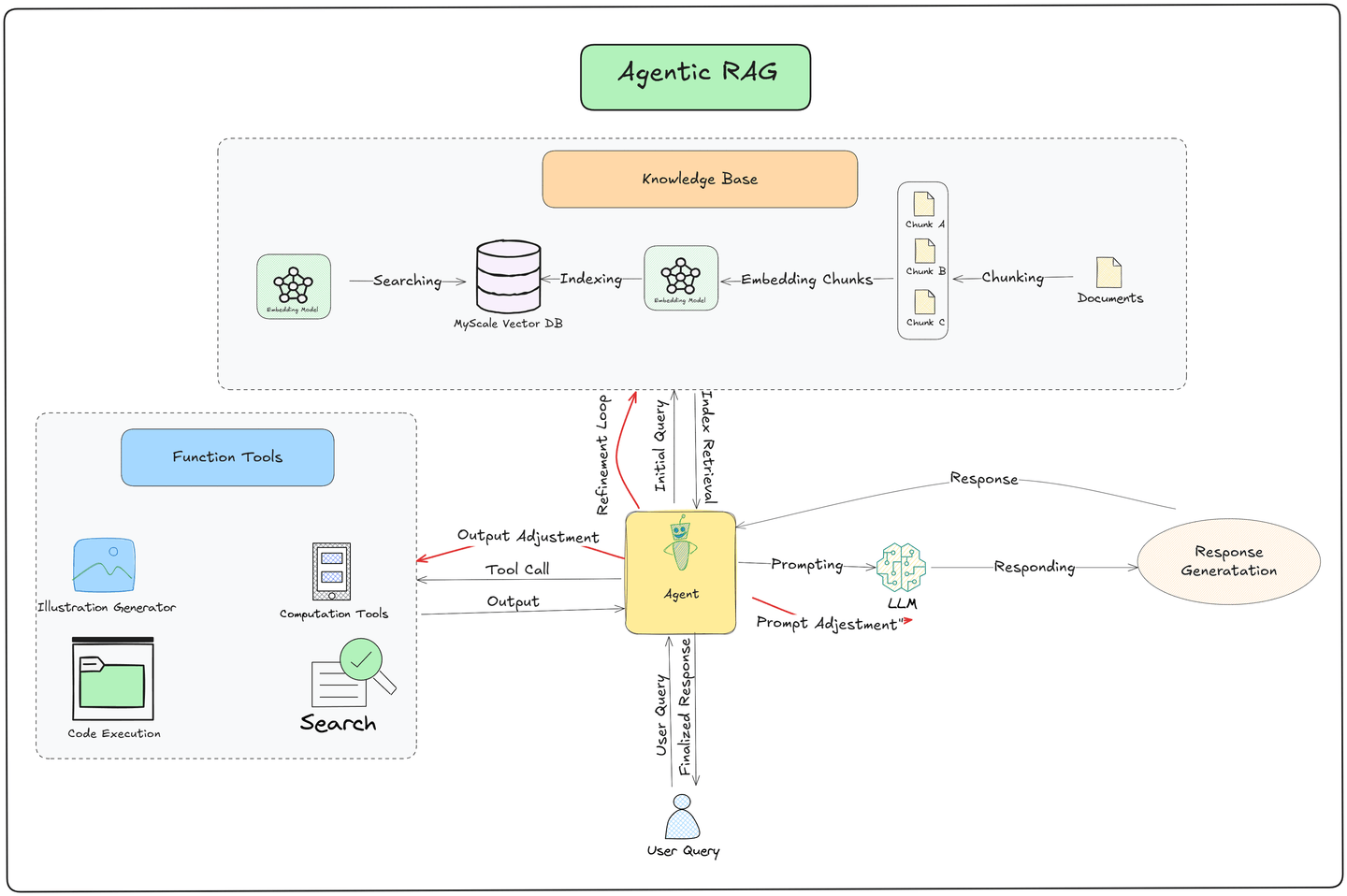
- ユーザークエリの送信:
- プロセスは、ユーザーがシステムにクエリを送信することから始まります。このクエリはパイプラインのトリガーとして機能します。
- ベクターデータベースからのデータ取得:
- エージェント が ベクターデータベース を検索し、文書が埋め込みとして保存されているため、関連情報の効率的かつ迅速な取得を保証します。
- 取得したデータが不十分な場合、エージェントはクエリを洗練させ、より良い結果を抽出するために追加の取得を試みます。
- 機能ツールを使用した外部データの取得:
- ベクターデータベース に必要な情報が不足している場合、エージェントは 機能ツール を使用して、API、ウェブ検索エンジン、または独自のデータストリームなどの外部ソースからリアルタイムデータを収集します。これにより、システムは最新かつ文脈的に関連する情報を提供します。
- 大規模言語モデル (LLM) による応答生成:
- 取得したデータは LLM に渡され、詳細で文脈を考慮した応答を生成します。
- エージェント主導の洗練:
- LLM が応答を生成した後、エージェントはそれをさらに正確性、関連性、整合性のために洗練し、ユーザーに提供します。
# 比較: エージェンティック RAG と RAG
以下は比較表です。
| 特徴 | RAG (リトリーバル拡張生成) | エージェンティック RAG |
|---|---|---|
| タスク処理 | 応答を生成する前に外部ソース (例: データベース、文書) から関連情報を取得します。 | 推論 と 行動 の能力を追加して RAG を拡張し、環境との積極的な相互作用とフィードバック学習を可能にします。 |
| 環境との相互作用 | 外部ソースからデータを取得します。 | 外部環境 (API、データソース) と積極的に相互作用し、フィードバックに基づいて適応します。 |
| 推論 | 明示的な推論はなく、文脈を提供するためにリトリーバルに依存します。 | 明示的な推論のトレースが意思決定とタスクの完了を導きます。 |
| フィードバックループ | 学習のためのフィードバックループを組み込んでいません。 | 環境からのフィードバックを取り入れて推論と行動を洗練します。 |
| 自律性 | 受動的; システムはデータを取得した後にのみ応答します。 | 推論と行動における積極的な自律性があり、動的に意思決定と学習を行います。 |
| ユースケース | 文脈的なリトリーバルを必要とするタスクに最適です (例: 質問応答)。 | 推論と外部システムとの相互作用の両方を必要とするタスクに適しています (例: 意思決定、計画)。 |
# 結論
結論として、エージェンティック RAG は AI の分野における重要な進展を表しています。大規模言語モデルの力と自律的に推論し情報を取得する能力を組み合わせることで、エージェンティック RAG は新たなレベルの知性と適応性を提供します。AI が進化し続ける中で、エージェンティック RAG はさまざまな業界でますます重要な役割を果たし、私たちの仕事や技術とのインタラクションの方法を変革していくでしょう。
エージェンティック AI の潜在能力を完全に実現するためには、MyScale ベクターデータベース (opens new window) のような堅牢で効率的なベクターデータベースが不可欠です。これは、大規模な AI アプリケーションの要求に応えるように設計されています。高度なインデックス技術と最適化されたクエリ処理能力を備えた MyScale は、エージェンティック RAG システムが関連情報を迅速に取得し、高品質な応答を生成できるようにします。MyScale の力を活用することで、エージェンティック AI の潜在能力を最大限に引き出し、革新を促進することができます。



