
大規模言語モデル(LLM) (opens new window) 、例えば GPT (opens new window) はテキストを生成したり、質問に答えたり、多くのタスクをサポートすることができます。しかし、彼らは反応的であり、学習したパターンに基づいて受け取った入力にのみ応答します。LLMは自分自身で意思決定をすることはできません。また、計画を立てたり、変化する状況に適応したりすることもできません。

エージェンティックAI (opens new window) はこの問題を解決するために登場します。ジェネレーティブAI LLMとは異なり、エージェンティックAIは主導権を持ち、目標を設定し、経験から学習することができます。エージェンティックAIは積極的であり、時間の経過に伴い行動を調整することができ、持続的な問題解決と意思決定を必要とするより複雑なタスクを処理することができます。この反応的から積極的なAIへのシフトは、多くの産業において技術の新たな可能性を開拓します。
このブログシリーズでは、エージェンティックAIとジェネレーティブAIの違いを解説し、それぞれが産業や技術の未来に与える影響について考察します。この最初の投稿では、これら2つのAIの異なる点について探求していきます。
# エージェンティックAI
エージェンティックAIは、特定の目標を達成するために自律的に意思決定し、行動することができるAIシステムを指します。単にコンテンツを生成するだけでなく、これらのAIモデルは周囲と対話し、変化に対応し、最小限の人間のガイダンスでタスクを完了することができます。例えば、エージェンティックな機能を持つ仮想アシスタントは、情報を提供するだけでなく、予約をスケジュールしたり、リマインダーを管理したり、他のアクションを実行してユーザーが目標を達成するのを支援することができます。同様に、自動運転車はエージェンティックAIの例であり、安全に道路を走行し目的地に到達するためにリアルタイムで意思決定を行います。
# ジェネレーティブAI
ジェネレーティブAIは、テキスト、画像、音楽、さらにはビデオなど、新しいコンテンツを作成することに焦点を当てた人工知能の一種です。大量のデータから学習し、パターン、スタイル、構造を理解し、学習した内容に基づいてオリジナルのコンテンツを生成します。例えば、ChatGPTのようなジェネレーティブAIは、質問に対してユニークなテキストの回答を生成することができます。また、DALL-Eのような画像生成モデルは、テキストの説明から画像を生成することができます。基本的に、ジェネレーティブAIはデジタルアーティストや作家のような存在であり、学習した内容に基づいて創造的な作品を生み出します。

上記の図は、エージェンティックAIが「思考/研究」と「修正」の段階を経て進行する反復的なワークフローを示しています。この適応的なプロセスでは、継続的な自己評価と改善が行われ、エージェンティックAIはより高品質で最適化された出力を生成することができます。複数のステップを踏んで作業をテストし、改善することで、エージェンティックAIは独立して動作し、各段階から学習し、継続的な評価と調整を必要とするタスクに取り組むことができます。
# エージェンティックAIとジェネレーティブAIの特徴
このセクションでは、エージェンティックAIとジェネレーティブAIの独特の特徴を探求し、知能、自律性、意思決定におけるそれぞれのアプローチの違いを強調します。
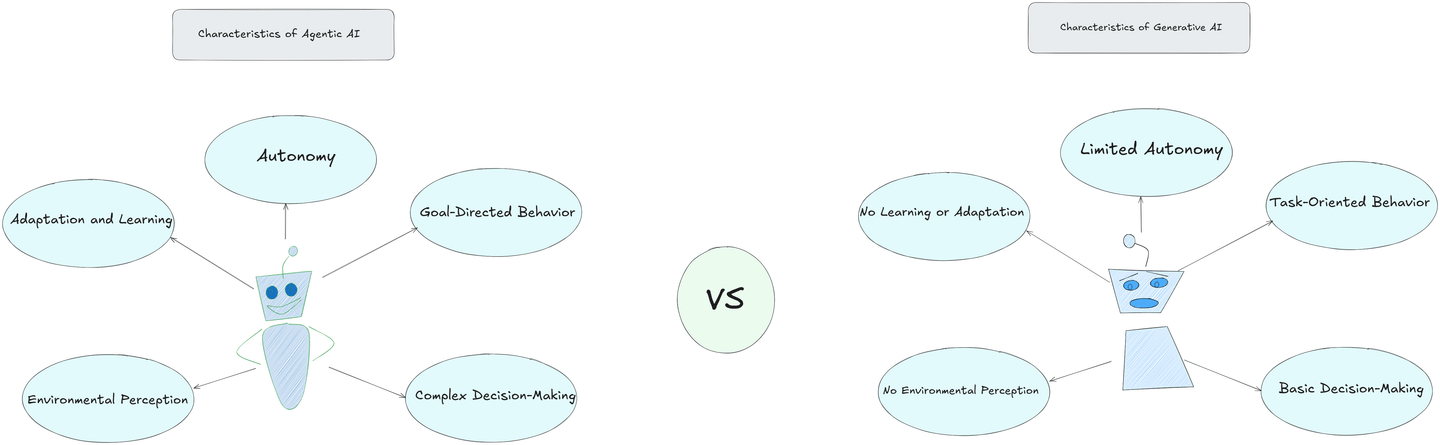
- 自律性:エージェンティックAIは、人間の持続的な入力を必要とせずに独立して行動することができます。自ら意思決定し、タスクを実行します。周囲の状況に基づいて次に何をすべきかを判断する、人間のコントローラーなしで動作するロボットのようなものと考えてください。
- 目標指向の行動:エージェンティックAIは明確な目標を持って動作します。ランダムに世界に反応するだけでなく、特定の目標に向かって積極的に取り組みます。例えば、自動運転車は安全に目的地に到着することを目指し、ステアリングからブレーキまでのすべてのアクションがその目標に対応します。
- 適応と学習:エージェントは自身の行動と経験から学習します。問題や失敗に遭遇した場合、調整します。例えば、映画を推薦するAIは、好みの映画を学習し、時間の経過とともに改善してより良い提案を提供します。
- 複雑な意思決定:エージェンティックAIは単純な選択だけでなく、多くのオプションを評価し、結果を考慮します。株式取引アルゴリズムを制御するAIを想像してみてください。それは大量のデータを分析し、トレンドを予測し、その情報に基づいて株式の売買を決定します。
- 環境認識:AIがスマートな選択をするためには、自身の環境を理解する必要があります。これはセンサーやデータを通じて行われます。例えば、ロボットはカメラを使用して障害物を「見」、それを回避します。
- 限定的な自律性:ジェネレーティブAIは限定的な自律性を持ちます。それは独立して行動せず、応答を生成するために人間の入力を必要とします。受け取った入力を処理し、学習したパターンに基づいて出力を生成しますが、外部のプロンプトなしでアクションを起こすことはできません。
- タスク指向の行動:ジェネレーティブAIはタスク指向ですが、反応的な意味でのみです。特定のプロンプトやタスクに対して関連するコンテンツ(テキストや画像など)を生成することで応答しますが、長期的な目標を追求したり、全体的な目標を持っているわけではありません。各タスクは即時の入力に基づいて完了します。
- 基本的な意思決定:ジェネレーティブAIは基本的な意思決定を行います。学習したパターンに基づいて出力を選択しますが、複数の代替案を評価したり、結果を考慮したりすることはありません。例えば、テキストを生成する際には、トレーニングに基づいて最も可能性の高い次の単語やフレーズを選択しますが、複雑な層状の意思決定は行いません。
- 学習や適応のなし:ジェネレーティブAIはリアルタイムで学習や適応を行いません。トレーニング後は、トレーニング中に学習したパターンに基づいて動作しますが、新しい相互作用に基づいてパフォーマンスを変更または改善することはありません。更新されたデータで再トレーニングされるまで、パフォーマンスは変わりません。
- 環境認識のなし:ジェネレーティブAIには環境認識のなしがあります。データ(テキスト、画像など)を扱いますが、物理的な環境を感知または解釈することはできません。周囲を理解することはできず、与えられた入力にのみ反応します。
# ケーススタディ:エージェンティックワークフローの実践
ジェネレーティブAIとエージェンティックAIの理論的な違いは明確ですが、これらの概念を実際に見ることで、エージェンティックAIの真の潜在能力が明らかになります。実際の価値を示すために、エージェンティックAIが実世界のシナリオで従来のLLM手法を上回る方法を示すケーススタディを探ってみましょう。
Andrew Ngは、コーディングタスクにおけるエージェンティックワークフローの力を示すためのケーススタディを共有しました。彼のチームは、HumanEvalコーディングベンチマークを使用して2つの方法をテストしました。タスクは次のようなものでした:「整数のリストが与えられた場合、偶数位置の要素の合計を返す」。最初の方法では、ゼロショットプロンプティングと呼ばれる方法を使用し、AIに追加の手順なしで問題を解決するように単純に要求しました。例えば、GPT-3.5は48%の正確さを示し、GPT-4は67%となりました。これらの結果は良好でしたが、特に優れたものではありませんでした。
クイック用語:
- ゼロショットプロンプティング:追加のガイダンスや手順を提供せずにAIに問題を解決するように要求すること。
- エージェンティックワークフロー:タスクを理解、コーディング、テスト、デバッグなどの小さなフェーズに分割し、AIが反復し改善することを可能にする方法。
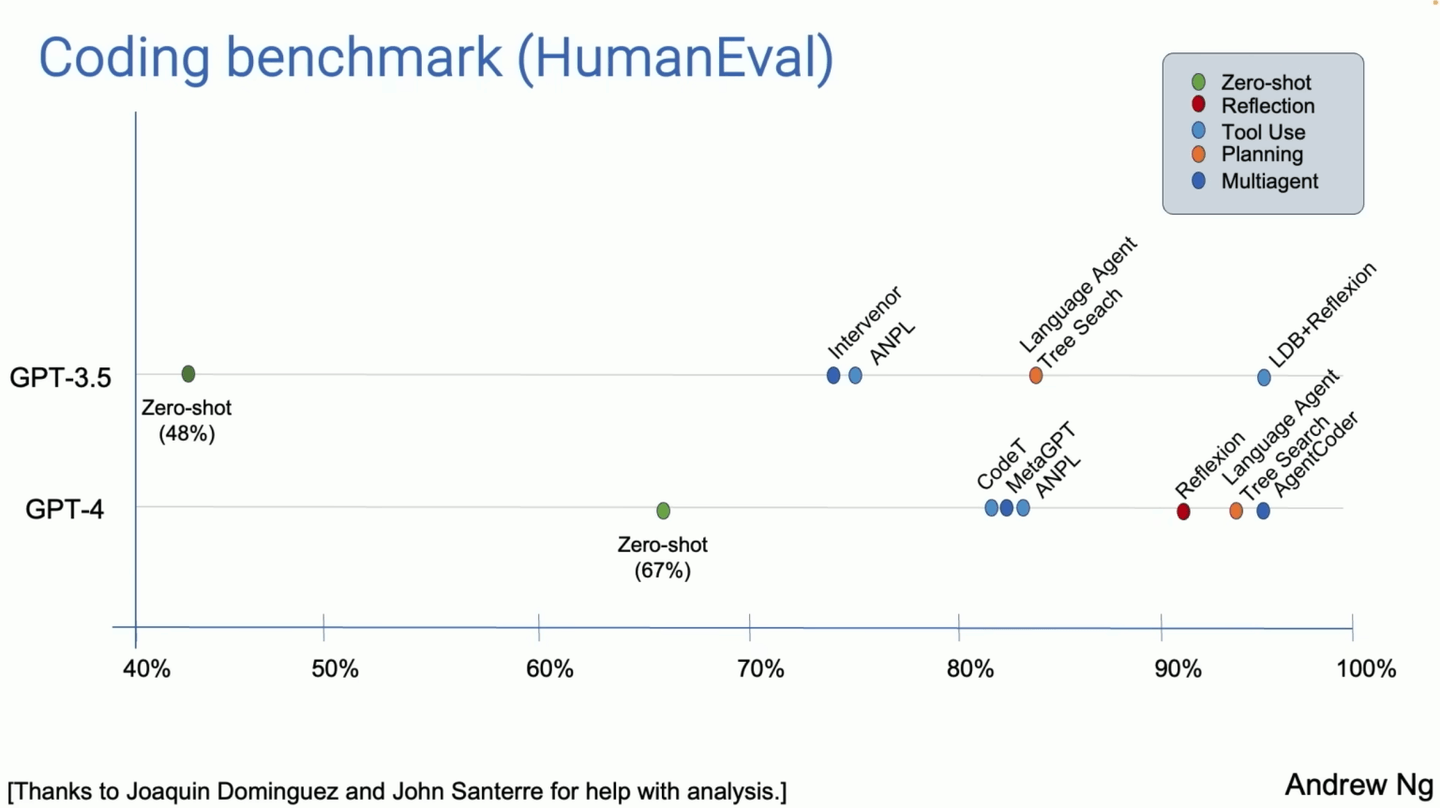
しかし、チームがエージェンティックワークフローを適用した場合、タスクを問題の理解、コードの一部を書く、テスト、エラーの修正などの小さなステップに分割する方法で、GPT-3.5はGPT-4よりもさらに優れた結果を示しました。Ngは、GPT-4もエージェンティックワークフローを使用した場合により強力な結果を示したと指摘しました。これは、ステップバイステップのアプローチを取ることで、AIモデル(特に古いモデル)が従来の方法であるゼロショットプロンプティングを使用するよりも優れたパフォーマンスを発揮できることを示しています。
# 結論
AIが私たちの生活や職場の一部となるにつれて、エージェンティックAIとジェネレーティブAIの違いを理解することは非常に重要です。ジェネレーティブAIはテキスト生成やプロンプトに対するテキストや画像の生成などのタスクに非常に役立っています。しかし、それは真の自律性なしに指示に従うことに限定されています。一方、エージェンティックAIは一歩進んでおり、自ら目標を設定し、意思決定を行い、変化する状況に適応する能力を持ち、持続的な人間のガイダンスなしで複雑なタスクに取り組むことができます。
エージェンティックワークフローなどの方法を使用することで、AIシステムは効果的になり、各フェーズから学習し、反復的なステップを通じてパフォーマンスを向上させることができます。このシフトにより、高度なアプリケーションの可能性が広がり、古いモデルでも進化し続け、有用性を保つことができます。このシリーズの次の部分では、エージェンティックAIの実際の動作方法と産業を再構築し、新たなイノベーションを推進する可能性について探求していきます。



