
2023年11月6日、OpenAIはGPTsのリリースを発表しました。このノーコードプラットフォームでは、プロフェッショナル(または趣味の)開発者として、ツールやプロンプトを使用してカスタマイズされたGPTsやチャットボットを構築することができ、OpenAIのGPTとのやり取りを効果的に変えることができます。以前のやり取りでは、LangChain (opens new window)やLlamaIndex (opens new window)を使用してGPTからの応答を取得するために動的なプロンプティングを使用する必要がありました。しかし、OpenAIのGPTsでは、外部のAPIやツールを呼び出すことで、動的なプロンプティングを処理するようになりました。
これにより、私たち(MyScale)がRAGシステムを構築する方法も変わり、サーバーサイドのコンテキストをGPTsモデルに注入する方法になりました。
MyScaleを使用すると、GPTsに文脈を注入する方法が非常に簡単になります。たとえば、OpenAIの方法では、Web UIを介してファイルをGPTsプラットフォームにアップロードすることが必要でした。それに対して、MyScaleでは、SQL WHERE句 (opens new window)を使用して構造化データのフィルタリングと意味的な検索を組み合わせることができます。また、より大きな知識ベースを低コストで処理・保存することができ、1つの知識ベースを複数のGPTsで共有することもできます。
MyScaleGPTをGPT Storeで試してみてください🚀。または、MyScaleのオープンな知識ベースをHugging FaceでホストされているAPIと統合して、今日からアプリに組み込んでみてください。
# BYOK: Bring Your Own Knowledge
GPTは過去1年間で大きく進化し、共有知識領域においては以前よりも多くの知識を持つようになりました。しかし、まだ特定のトピックについては何も知らないか、不確かな場合があります。たとえば、ドメイン固有の知識や最新の出来事などです。そのため、以前の記事 (opens new window)で説明したように、外部の知識ベース(MyScaleに格納されている)をGPTに統合することは必須であり、GPTの真実性と有用性を向上させることができます。
私たちは、MyScaleでRAGを構築する際にLLMを導入しました (opens new window)。今回は、MyScaleデータベースをGPTsプラットフォームに組み込む必要があります。残念ながら、GPTsとMyScaleの間で直接的な接続を確立することは現在できません。そのため、クエリインターフェースを微調整し、REST APIとして公開しました。
以前のOpenAI関数呼び出し (opens new window)の成功を受けて、GPTがSQLのようなフィルタ文字列を使用してベクトル検索クエリを書くことができる類似のインターフェースを設計することができました。パラメータは以下のようにOpenAPIで記述されます。
"parameters": [
{
"name": "subject",
"in": "query",
"description": "A sentence or phrase describes the subject you want to query.",
"required": true,
"schema": {
"type": "string"
}
},
{
"name": "where_str",
"in": "query",
"description": "a SQL-like where string to build filter",
"required": true,
"schema": {
"type": "string"
}
},
{
"name": "limit",
"in": "query",
"description": "desired number of retrieved documents",
"schema": {
"type": "integer",
"default": 4
}
}
]
このようなインターフェースを使用すると、GPTはキーワードを抽出してSQLで記述されたフィルタを使用して必要なクエリを行うことができます。
# 異なるテーブルへのクエリエントリの提供
時には異なるテーブルにクエリを行う必要がある場合もあります。これは、別々のAPIエントリを使用して実装することができます。各APIエントリには独自のスキーマとドキュメントのプロンプトがあります。GPTは適用可能なAPIドキュメントを読み取り、正しいクエリを対応するテーブルに書き込むことができます。
以前に紹介したセルフクエリリトリーバーやベクトルSQLのようなメソッドは、テーブル構造を記述するために動的または半動的なプロンプティングが必要でした。一方、GPTはLangChainの会話エージェント (opens new window)のように機能し、エージェントがテーブルをクエリするために異なるツールを使用します。
たとえば、APIエントリは次のようにOpenAPI 3.0で記述されます。
"paths": {
// arxivテーブルへのクエリエントリ
"/get_related_arxiv": {
"get": {
// 説明はツールのプロンプトに注入されます
// これにより、GPTがこのクエリツールをどのように使用し、いつ使用するかがわかります
"description": "Get some related papers."
"You should use schema here:\n"
"CREATE TABLE ArXiv ("
" `id` String,"
" `abstract` String,"
" `pubdate` DateTime,"
" `title` String,"
" `categories` Array(String), -- arxivのカテゴリ"
" `authors` Array(String),"
" `comment` String,"
"ORDER BY id",
"operationId": "get_related_arxiv",
"parameters": [
// 上記で説明したパラメータ
],
}
},
// wikiテーブルへのクエリエントリ
"/get_related_wiki": {
"get": {
"description": "Get some related wiki pages. "
"You should use schema here:\n\n"
"CREATE TABLE Wikipedia ("
" `id` String,"
" `text` String,"
" `title` String,"
" `view` Float32,"
" `url` String, -- URL to this wiki page"
"ORDER BY id\n"
"You should avoid using LIKE on long text columns.",
"operationId": "get_related_wiki",
"parameters": [
// 上記で説明したパラメータ
]
}
}
}
このコードスニペットに基づいて、GPTは2つの知識ベースがあることを知ります。これらの知識ベースはユーザーの質問に答えるのに役立ちます。
GPTのActionsを知識ベースの取得に設定した後、単純にInstructionsを埋め、GPTに知識ベースをクエリしてユーザーの質問に答える方法を指示します。
最善の答えをしてください。関連情報を検索するために利用可能なツールを自由に使用してください。クエリを呼び出す際には、すべての詳細をクエリに含めてください。MyScaleの知識ベースを使用してクエリを行う場合、文字列の配列に対しては
has(column, value to match)を使用してください。公開日には、parseDateTime32BestEffort()を使用して、文字列形式のタイムスタンプ値を日時オブジェクトに変換します。この関数を使用して日時型の列を変換しないでください。使用したドキュメントには常に参照リンクを追加してください。
# データベースをOpenAPIとしてホストする
GPTsはOpenAI 3.0の標準に準拠したAPIを適応します。データベースなどの一部のアプリケーションにはOpenAPIインターフェースがありません。そのため、GPTsをMyScaleと統合するためにはミドルウェアを使用する必要があります。
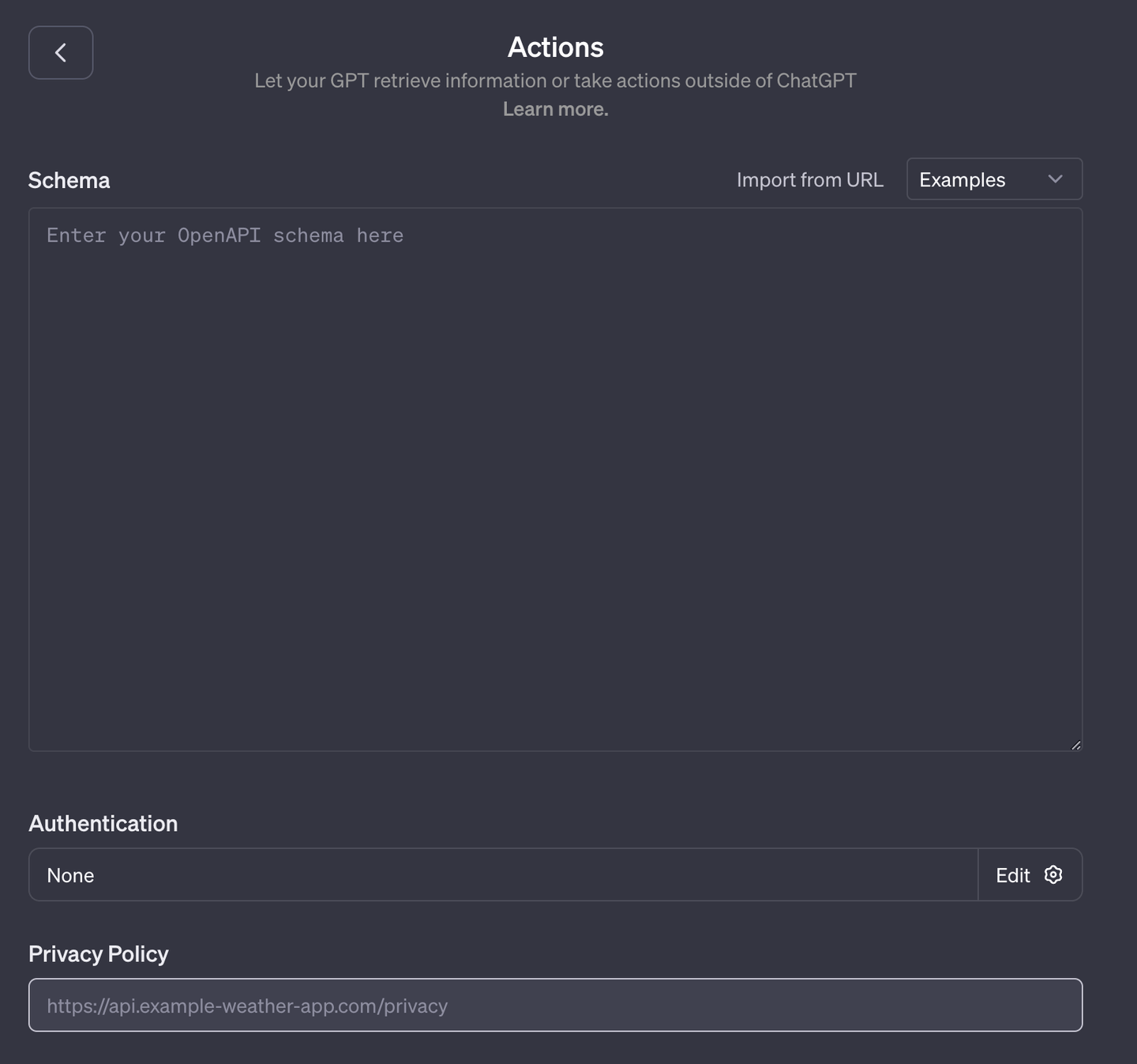
私たちは、データベースをOpenAI互換のインターフェースでHugging Face (opens new window)にホストしました。実装を簡素化し自動化するためにflask-restx (opens new window)を使用し、コードを小さく、クリーンで読みやすいものにしました:app.py (opens new window)、funcs.py (opens new window)。
この方法の良い点は、プロンプトと関数が結びついていることです。そのため、プロンプト、機能、拡張性の組み合わせについて過度に考える必要はありません。人間が読みやすい形式で書き、GPTはダンプされたOpenAI JSONファイルからこのドキュメントを読み取ります。
注意:
flask-restxはSwagger 2.0形式でのAPIを生成するだけです。まずSwagger Editorを使用してそれらをOpenAPI 3.0形式に変換する必要があります。Hugging FaceのJSON API (opens new window)を参考にしてください。

# APIからコンテキストを持つGPTの実行
適切な指示に基づいて、GPTは異なるデータ型を慎重に処理するための特殊な関数を使用します。これらのデータ型の例には、配列列のためのClickHouse SQL関数has(column, value)やタイムスタンプ列のためのparseDateTime32BestEffort(value)などがあります。

正しいクエリをAPIに送信すると、API(またはAPI)はフィルタを使用してベクトル検索クエリを構築します。返された値は、データベースから取得した追加の知識として文字列形式でフォーマットされます。次のコードサンプルでは、この実装は非常にシンプルです。
class ArXivKnowledgeBase:
def __init__(self, embedding: SentenceTransformer) -> None:
# これがデフォルト.ChatArXivとwiki.Wikipediaを含む私たちのオープンな知識ベースです
self.db = clickhouse_connect.get_client(
host='msc-950b9f1f.us-east-1.aws.myscale.com',
port=443,
username='chatdata',
password='myscale_rocks'
)
self.embedding: SentenceTransformer = INSTRUCTOR('hkunlp/instructor-xl')
self.table: str = 'default.ChatArXiv'
self.embedding_col = "vector"
self.must_have_cols: List[str] = ['id', 'abstract', 'authors', 'categories', 'comment', 'title', 'pubdate']
def __call__(self, subject: str, where_str: str = None, limit: int = 5) -> Tuple[str, int]:
q_emb = self.embedding.encode(subject).tolist()
q_emb_str = ",".join(map(str, q_emb))
if where_str:
where_str = f"WHERE {where_str}"
else:
where_str = ""
# クエリベクトルとwhere_strを単純にクエリに注入するだけです
# 必要に応じて確認することもできます
q_str = f"""
SELECT dist, {','.join(self.must_have_cols)}
FROM {self.table}
{where_str}
ORDER BY distance({self.embedding_col}, [{q_emb_str}])
AS dist ASC
LIMIT {limit}
"""
docs = [r for r in self.db.query(q_str).named_results()]
return '\n'.join([str(d) for d in docs]), len(docs)
# 結論
GPTsは、OpenAIの開発者インターフェースにおいて本当に大きな進歩です。エンジニアはチャットボットを構築するためにあまり多くのコードを書く必要はありませんし、ツールはプロンプトを自己完結させることができます。GPTのエコシステムを作り出すことは美しいことだと思います。一方で、オープンソースコミュニティに既存のLLMとツールの組み合わせ方を再考させることにもなるでしょう。
私たちは、LLMとデータベースの統合について新しいアプローチを探し続けており、外部のデータベースに格納された外部の知識ベースを組み込むことがLLMの真実性と有用性を向上させると確信しています。
MyScaleGPT (opens new window)をアカウントに追加してください。または、Discord (opens new window)やTwitter (opens new window)で私たちと一緒にLLMとデータベースの統合について深く意義のある議論を始めましょう。



