
OpenAI Assistants APIは、開発者が簡単にアプリケーション内で堅牢なAIアシスタントを作成できるようにするものです。このAPIには、以下の機能/機能が含まれています。
- 会話履歴の処理を不要にする
- Code InterpreterやRetrievalなどのOpenAIホストのツールへのアクセスを提供する
- サードパーティのツールの関数呼び出しを強化する
この記事では、Assistants APIとMyScaleなどのベクトルデータベースを使用してカスタムナレッジベースを構築し、柔軟性、精度、コスト削減を実現する方法について説明します。
![]()
![]()
# OpenAIアシスタントとは?
OpenAIアシスタントは、ユーザーのクエリに答えるために、Large Language Models(LLMs)、ツール、ナレッジベースを活用できる自動化されたワークフローです。そして、上記のように、OpenAIアシスタントを作成するにはAssistants APIを使用する必要があります。
まず、Assistants APIの内部を見てみましょう。
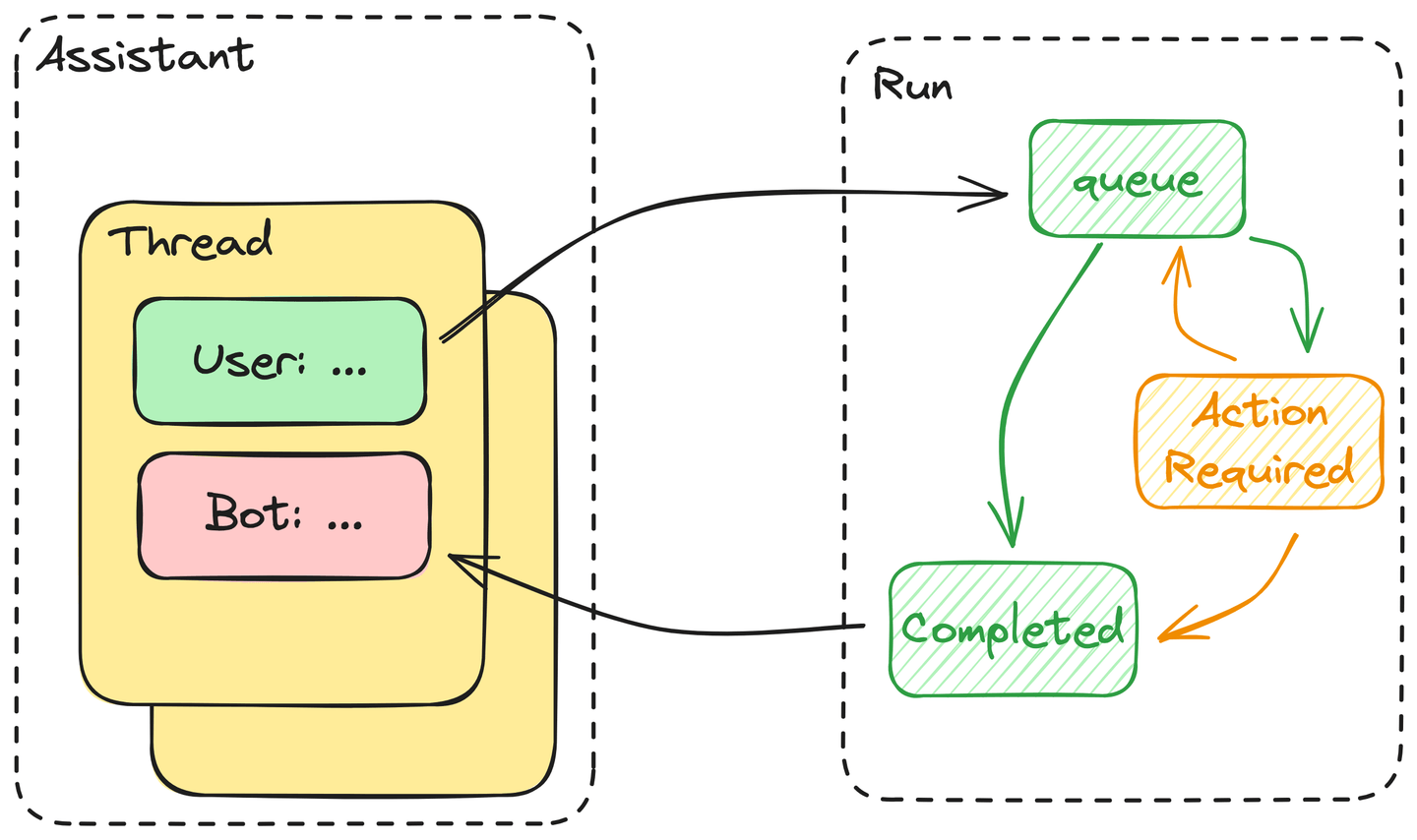
# コンポーネント
Assistants APIには、以下の主要なコンポーネントが含まれています。
- Assistant: Assistantには、使用できるツールの定義、読み込むことができるファイル、および作成されたスレッドにアタッチするシステムプロンプトが含まれています。
- Thread: スレッドは、アシスタントの会話を制御するメッセージで構成されています。
- Messages: メッセージは、スレッドを構成する基本要素であり、ユーザーの入力や生成された回答を含むすべてのテキストを含んでいます。
- Run: ユーザーは、アシスタントから回答を要求するたびに実行を開始する必要があります。実際には、アシスタントはスレッド内のすべてのメッセージを実行します。アクションが必要な場合は、ユーザーはツールの出力を実行に提出する必要があります。
# Assistants APIのツールを使用して実行を開始する
これらのアシスタントは、API呼び出しを介して与えられたツールを使用する方法を知っているため、人工知能の兆候です。このため、OpenAIは、GPTがAPIに渡される関数呼び出しを使用して、ユーザーのリクエストをフォーマットされた使用ツールに変換できることを証明しました。したがって、人間の言葉で言えば、これはツールの使用方法を知っていることに相当します。
さらに、これらのアシスタントは、単一の実行の実行中にいつ、どのツールを使用するかを決定できます。このプロセスを簡略化すると、次のようになります。
- ユーザーが実行を開始すると、スレッド内のすべてのメッセージがキューに追加されます。これらのメッセージは、リソースが利用可能になるとキューから取り出されます。
- アシスタントは、アシスタントの定義で提供されたツールのいずれかを使用するかどうかを決定します。使用する場合、アシスタントは「ActionRequired」の状態に入ります。必要なアクションが提供されるまで、ツールの出力がブロックされます。使用しない場合、アシスタントはすぐに回答を返し、この実行を「Completed」とマークします。
- アシスタントは、タイムアウトの閾値を超えるまで、ツールの呼び出しの出力を待機します。計画通りにすべてが進む場合、アシスタントはツールの出力をスレッドに追加し、回答を返し、上記のように実行を完了とマークします。
要するに、実行の実行は、LLMによって駆動されるオートマトンです。
# MyScaleをOpenAIのアシスタントにリンクする
MyScaleにはSQLインターフェースがあり、自動化されたクエリには重要な利点です。さらに、LLMはSQLを含むコードの記述にも適しています。そのため、関数呼び出しのドキュメント (opens new window)で説明されているように、SQLのWHEREフィルタとベクトル検索を組み合わせました。
次に、この関数呼び出しをMyScaleとOpenAIのAssistants APIの間のリンクに展開してみましょう。
# アシスタントのRetrievalツールは使用しない
Assistants APIには、Retrievalツールが含まれており、1日あたり$0.2 / (GB * num_assistants)の費用がかかります。たとえば、Arxivデータセットの場合、データは埋め込みを含めて約24GBです。これは、たった1つのアシスタントに対して1日あたり$5(月額$150)の費用がかかります。また、正確性や時間の消費に関して、リトリーバルのパフォーマンスがどのようになるかはわかりません。貴重な知識を含んでいるかどうかは、GPTだけが知っています。したがって、大量のデータを保存して検索する場合は、外部のベクトルデータベースが必要です。
# アシスタントのツールとしてのナレッジベースの定義
Assistants APIの公式ドキュメントによると、既存のナレッジベースを持つアシスタントを作成するには、OpenAI().beta.create_assistants.createを使用できます。以下は、既存のナレッジベースを持つアシスタントを構築する例です。
from openai import OpenAI
client = OpenAI()
assistant = client.beta.assistants.create(
name="ChatData",
instructions=(
"You are a helpful assistant. Do your best to answer the questions. "
),
tools=[
{
"type": "function",
"function": {
"name": "get_wiki_pages",
"description": (
"Get some related wiki pages.\n"
"You should use schema here to build WHERE string:\n\n"
"CREATE TABLE Wikipedia (\n"
" `id` String,\n"
" `text` String, -- abstract of the wiki page. avoid using this column to do LIKE match\n"
" `title` String, -- title of the paper\n"
" `view` Float32,\n"
" `url` String, -- URL to this wiki page\n"
"ORDER BY id\n"
"You should avoid using LIKE on long text columns."
),
"parameters": {
"type": "object",
"properties": {
"subject": {"type": "string", "description": "a sentence or phrase describes the subject you want to query."},
"where_str": {
"type": "string",
"description": "a sql-like where string to build filter.",
},
"limit": {"type": "integer", "description": "default to 4"},
},
"required": ["subject", "where_str", "limit"],
},
},
}
],
model="gpt-3.5-turbo",
)
公開された関数には、subject、where_str、limitの3つの入力があります。これは、LangChainのMyScale vectorstoreの実装 (opens new window)と一致します。
プロンプトで説明されているように、
subjectはベクトル検索に使用されるテキストであり、where_strはSQL形式で記述された構造化フィルタです。
また、テーブルのスキーマをツールの説明に追加し、アシスタントが正しいSQL関数を使用してフィルタを作成できるようにします。
# MyScaleからアシスタントに外部の知識を注入する
MyScaleからアシスタントに外部の知識を注入するには、アシスタントが生成した引数に基づいてこの知識を取得するためのツールが必要です。例として、MyScaleのベクトルストアの実装を最小限に抑えたコードを示します。
import clickhouse_connect
db = clickhouse_connect.get_client(
host='msc-950b9f1f.us-east-1.aws.myscale.com',
port=443,
username='chatdata',
password='myscale_rocks'
)
must_have_cols = ['text', 'title', 'views']
database = 'wiki'
table = 'Wikipedia'
def get_related_pages(subject, where_str, limit):
q_emb = emb_model.encode(subject).tolist()
q_emb_str = ",".join(map(str, q_emb))
if where_str:
where_str = f"WHERE {where_str}"
else:
where_str = ""
q_str = f"""
SELECT dist, {','.join(must_have_cols)}
FROM {database}.{table}
{where_str}
ORDER BY distance(emb, [{q_emb_str}])
AS dist ASC
LIMIT {limit}
"""
docs = [r for r in db.query(q_str).named_results()]
return '\n'.join([str(d) for d in docs])
tools = {
"get_wiki_pages": lambda subject, where_str, limit: get_related_pages(subject, where_str, limit),
}
次に、新しいスレッドを作成して入力を保持する必要があります。
thread = client.beta.threads.create()
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="What is Ring in mathematics? Please query the related documents to answer this.",
)
client.beta.threads.messages.list(thread_id=thread.id)
実行はスレッドから作成され、特定のアシスタントにリンクされます。異なる実行は異なるアシスタントを持つことができます。その結果、スレッドにはさまざまなツールを使用して生成されたメッセージが含まれることがあります。
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id,
instructions= "You must use query tools to look up relevant information for every answer to a user's question.",
)
この実行のステータスを常にチェックし、アシスタントが呼び出す各関数に対して出力を提供する必要があります。
import json
from time import sleep
while True:
run = client.beta.threads.runs.retrieve(thread_id=thread.id, run_id=run.id)
if run.status == 'completed':
print(client.beta.threads.messages.list(thread_id=thread.id))
# 実行が完了した場合は、何もする必要はありません
break
elif len(run.required_action.submit_tool_outputs.tool_calls) > 0:
print("> Action Required <")
print(run.required_action.submit_tool_outputs.tool_calls)
# 実行にアクションが必要な場合、ツールを実行して出力を提出する必要があります
break
sleep(1)
tool_calls = run.required_action.submit_tool_outputs.tool_calls
outputs = []
# 必要なアクションごとにツールを呼び出す
for call in tool_calls:
func = call.function
outputs.append({"tool_call_id": call.id, "output": tools[func.name](**json.loads(func.arguments))})
if len(tool_calls) > 0:
# すべての保留中の出力を提出する
run = client.beta.threads.runs.submit_tool_outputs(
thread_id=thread.id,
run_id=run.id,
tool_outputs=outputs
)
出力が提出されると、実行は「queued」状態に戻ります。
注意: この実行のステータスを常にチェックする必要があります。
from time import sleep
while client.beta.threads.runs.retrieve(
thread_id=thread.id,
run_id=run.id
).status != 'completed':
print("> waiting for results... <")
sleep(1)
messages = client.beta.threads.messages.list(thread_id=thread.id).data[0].content[0].text.value
print("> generated texts <\n\n", messages)
最後に、この例ではAssistants APIの使用方法を示しています。

# 結論
MyScaleベクトルデータベースをOpenAIのAssistants APIと組み合わせることで、開発者はAIアシスタントを強化するための新たな可能性を開拓することができます。この貴重なリソースをシームレスに統合することで、開発者はMyScaleのパワーをOpenAIホストのツール(Code InterpreterやRetrievalなど)と組み合わせて活用することができます。
このシナジーにより、開発プロセスが効率化されるだけでなく、AIアシスタントはより広範な知識ベースを持つことができ、ユーザーにより堅牢で知的な体験を提供することができます。人工知能の研究の進歩を続けながら、このような統合は、多目的で能力のある仮想アシスタントの作成に向けた重要な一歩となります。
Assistants APIについてのご意見を共有するために、ぜひDiscord (opens new window)に参加してください!



