
現代の世界では、レコメンデーションシステムは、電子商取引、ストリーミングサービス、ニュースフィード、ソーシャルメディア、個別の学習など、さまざまなプラットフォームでユーザーエクスペリエンスを向上させるために非常に重要な役割を果たしています。
レコメンデーションシステムの領域では、従来のアプローチではユーザーとアイテムの相互作用を分析し、アイテムの類似性を評価することに頼っていました。しかし、人工知能の進歩に伴い、レコメンデーションシステムの領域も進化し、精度を向上させ、個々の好みに合わせたレコメンデーションを提供するようになりました。
# 広く採用されているコンテンツレコメンデーションのアプローチ
コンテンツレコメンデーションシステムでは、3つのタイプのフィルタリングが使用されています。いくつかは協調フィルタリング (opens new window)を使用し、いくつかはコンテンツベースのフィルタリング (opens new window)を使用し、いくつかはこれら2つの方法のハイブリッドを使用しています。それぞれについて詳しく説明しましょう。
# コンテンツベースのフィルタリング
コンテンツベースのフィルタリングは、アイテム自体の特性に焦点を当てています。ユーザーが以前に興味を示したアイテムに類似したアイテムを推奨します。
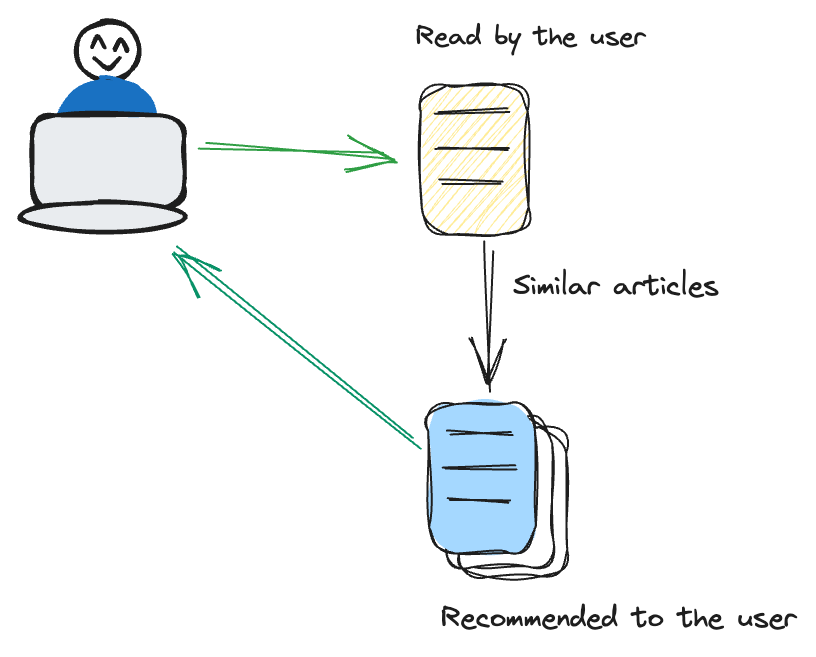
たとえば、ユーザーがよくスリラー映画を視聴する場合、レコメンデーションシステムはスリラージャンル内の追加の映画を提案するため、ターゲットに合わせたアプローチを採用します。この方法では、ジャンル、著者、アーティストなどのアイテムの固有の特性に重点を置いています。これらの属性に焦点を当てることで、システムはよりターゲットに合わせたコンテンツに特化したレコメンデーション戦略を確立し、ユーザーの好みに密接に合わせることができます。
# 協調フィルタリング
協調フィルタリングはユーザー中心です。ユーザーの行動パターンや類似性を分析して、レコメンデーションを行います。
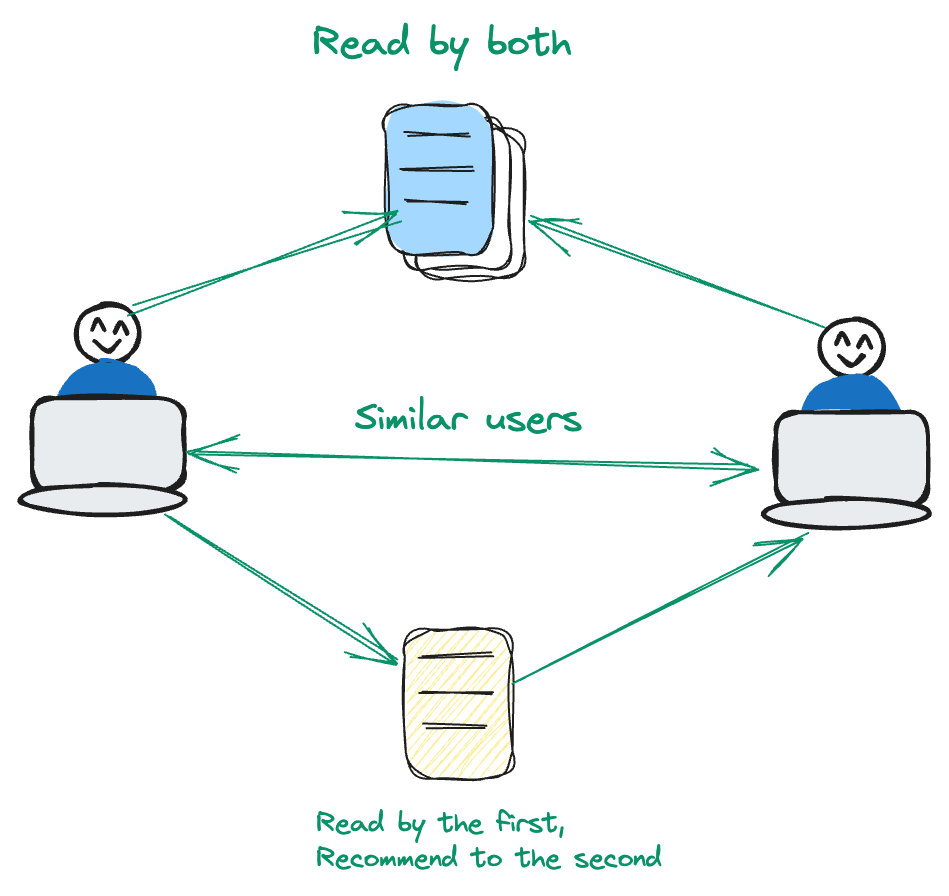
例えば、ユーザーAとユーザーBが特定の一連の映画に共通の興味を持っている場合、ユーザーBがユーザーAがまだ見ていない映画を好むことを表明した場合、レコメンデーションシステムはそれを記録します。この方法では、コンテンツ中心のアプローチから逸脱し、ユーザーとアイテムの動的な関係を重視します。ユーザーとアイテムの関係を優先することで、システムはより個別化されたユーザーエクスペリエンスのためにレコメンデーションを洗練させます。
# ハイブリッドテクニック
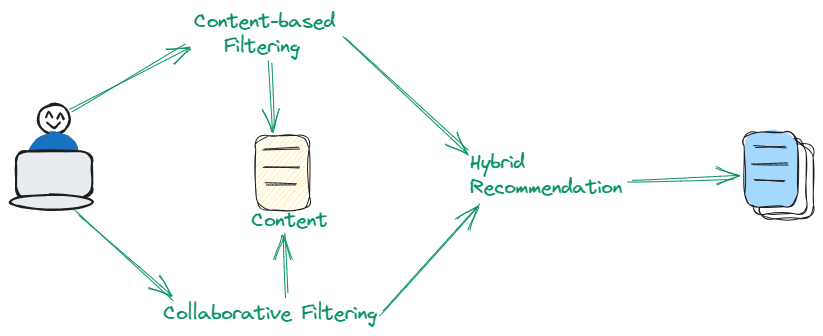
ハイブリッドテクニックは、コンテンツベースと協調フィルタリングの両方の利点を巧みに組み合わせて、レコメンデーションの精度を向上させます。アイテムの属性とユーザーの好みパターンの両方を組み合わせたデュアルアプローチを活用することで、この方法はそれぞれのアプローチを単独で依存する場合に存在する固有の制約にうまく対処します。ハイブリッドテクニックは、洗練された多様なレコメンデーションを提供するのに特に効果的です。
# 高度なコンテンツレコメンデーションアプローチ
大規模言語モデル(LLM)の台頭により、レコメンデーションシステムの進化が大幅に進みました。モダンなレコメンデーションシステムでは、コンテンツや協調フィルタリングに従う従来の依存性は、より洗練されたアプローチに置き換えられました。モダンなレコメンデーションシステムは、意味論の力を活用して、関連するアイテムを提案するために言語の意味を探索します。
このブログでは、この高度なアプローチを使用してコンテンツレコメンデーションシステムを構築する方法を紹介します。まず、このシステムに必要なツールを見てみましょう。
![]()
# ツールとテクノロジー
このプロジェクトでは、OpenAIのテキスト埋め込みモデル (opens new window)、ベクトルデータベースとしてのMyScale (opens new window)、およびTMDB 5000映画データセット (opens new window)を使用します。
- OpenAI:OpenAIのモデル「text-embedding-3-small」を使用してテキストの埋め込みを取得し、これらの埋め込みを使用してモデルを開発します。
- MyScale:MyScaleは、ベクトルデータと構造化データの両方を最適化された方法で格納および処理するSQLベクトルデータベースです。
- TMDB 5000映画データセット:このデータセットには、キャスト、クルー、予算、収益などの映画のメタデータが含まれています。
# データの読み込み
2つの主要なCSVファイル、「tmdb_5000_credits.csv」と「tmdb_5000_movies.csv」があります。これらのファイルには、レコメンデーションシステムの基礎となるさまざまな映画に関する重要な情報が含まれています。
import pandas as pd
credits = pd.read_csv("tmdb_5000_credits.csv")
movies = pd.read_csv("tmdb_5000_movies.csv")
# データの前処理
データの前処理は、レコメンデーションシステムの品質を確保するために重要です。2つのCSVファイルをマージし、最も関連性の高い列「title」、「overview」、「genres」、「cast」、「crew」に焦点を当てます。このステップでは、データを洗練させ、モデルに適した形式にすることが目的です。
credits.rename(columns = {'movie_id':'id'}, inplace = True)
df = credits.merge(movies, on = 'id')
df.dropna(subset = ['overview'], inplace=True)
df = df[['id', 'title_x', 'genres', 'overview', 'cast', 'crew']]
データのマージとフィルタリングにより、システムに適したクリーンで焦点を絞ったデータセットが作成されました。
# コーパスの生成
次に、各映画の「overview」、「genre」、「cast」、「crew」を1つの文字列に結合して、映画のための「corpus」を生成します。この包括的な情報は、正確なレコメンデーションを行うためにシステムをサポートします。
import pandas as pd
# 'df'がDataFrameであり、列に'overview'、'genres'、'cast'、'crew'があると仮定します
def generate_corpus(row):
overview, genre, cast, crew = row['overview'], row['genres'], row['cast'], row['crew']
corpus = ""
genre = ','.join([i['name'] for i in eval(genre)])
cast = ','.join([i['name'] for i in eval(cast)[:3]])
crew = ','.join(list(set([i['name'] for i in eval(crew) if i['job'] == 'Director' or i['job'] == 'Producer'])))
corpus += overview + " " + genre + " " + cast + " " + crew
return pd.Series([corpus, crew, cast, genre], index=['corpus', 'crew', 'cast', 'genres'])
# 各行に関数を適用する
df[['corpus', 'crew', 'cast', 'genres']] = df.apply(generate_corpus, axis=1)
# 埋め込みの取得
次に、OpenAIの埋め込みモデル「text-embedding-3-small」を使用して、コーパスを埋め込みに変換します。埋め込みは、映画のコンテンツの数値表現です。
import os
import numpy as np
import openai
os.environ["OPENAI_API_KEY"] = "your-api-key"
def get_embeddings(text):
response = openai.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data
# 5000のエントリ全体を渡すことはできないため、最初の1000のエントリを取得します
# データセット全体の埋め込みを取得する場合は、ループを適用できます
df=df[0:1000]
embeddings=get_embeddings(df["corpus"].tolist())
vectors = [embedding.embedding for embedding in embeddings]
array = np.array(vectors)
embeddings_series = pd.Series(list(array))
df['embeddings'] = embeddings_series
テキストのベクトル表現を取得することで、MyScaleを使用して簡単に意味論的な検索を適用できるようになります。
# MyScaleの設定
最初に述べたように、データの格納と管理のためにベクトルデータベースとしてのMyScaleを使用します。ここでは、データの格納の準備としてMyScaleに接続します。
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-host-name',
port=443,
username='your-user-name',
password='your-password'
)
注意:MyScaleクラスタに接続する方法の詳細については、接続の詳細 (opens new window)を参照してください。
# テーブルの作成
次に、DataFrameに基づいてテーブルを作成します。このテーブルには、埋め込みを含むすべてのデータが格納されます。
client.command("""
CREATE TABLE default.movies (
id Int64,
title_x String,
genres String,
overview String,
cast String,
crew String,
corpus String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 1536
) ENGINE = MergeTree()
ORDER BY id
""")
上記のSQLステートメントは、クラスタ上に「movies」という名前のテーブルを作成します。CONSTRAINTは、すべてのベクトル埋め込みが同じ長さ「1536」であることを確認します。
# データの格納とMyScaleでのインデックスの作成
このステップでは、処理済みのデータをMyScaleに挿入します。これには、データのバッチ挿入を行い、効率的な格納と検索を実現します。
batch_size = 100 # 必要に応じて調整
num_batches = len(df) // batch_size
for i in range(num_batches):
start_idx = i * batch_size
end_idx = start_idx + batch_size
batch_data = df[start_idx:end_idx]
client.insert("default.movies", batch_data.to_records(index=False).tolist(), column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches} inserted.")
client.command("""
ALTER TABLE default.movies
ADD VECTOR INDEX vector_index embeddings
TYPE MSTG
""")
# 映画のレコメンデーションの生成
最後に、ユーザーの入力に基づいて映画のレコメンデーションを生成する関数を作成します。この関数は指数的な減衰係数を使用して、最近視聴した映画により関連性を高め、レコメンデーションの品質を向上させます。
import numpy as np
from IPython.display import clear_output
genres = []
for i in range(3):
genre = input("ジャンルを入力してください:")
genres.append(genre)
genre_string = ', '.join(genres)
genre_embeddings=get_embeddings(genre_string)
embeddings=genre_embeddings[0].embedding
embeddings = np.array(genre_embeddings[0].embedding) # numpy配列に変換
decay_factor = 0.9 # 指数的な減衰のために必要に応じて調整
while True:
clear_output(wait=True)
# 結合された埋め込みを使用してデータベースをクエリします
results = client.query(f"""
SELECT title_x, genres,
distance(embeddings, {embeddings.tolist()}) as dist FROM default.movies ORDER BY dist LIMIT 10
""")
# 結果を表示します
print("おすすめの映画:")
movies = []
for row in results.named_results():
print(row["title_x"])
movies.append(row['title_x'])
# ユーザーに映画を選択するように求めます
selection = int(input("映画を選択してください(終了するには0を入力):"))
if selection == 0:
break
selected_movie = movies[selection - 1]
# 選択した映画の埋め込みを取得します
selected_movie_embeddings = get_embeddings(selected_movie)[0].embedding
selected_movie_embeddings_array = np.array(selected_movie_embeddings)
# 指数的な減衰を適用し、結合された埋め込みを更新します
embeddings = decay_factor * embeddings + (1 - decay_factor) * selected_movie_embeddings_array
# 結合された埋め込みを正規化します
embeddings = embeddings / np.linalg.norm(embeddings)
これで、MyScaleとベクトル埋め込みを使用して完全に機能する映画のレコメンデーションシステムが構築されました。このチュートリアルを自由に試してみるか、必要に応じて独自のシステムを作成してください。

# まとめ
このチュートリアルでは、LLMとMyScaleのようなベクトルデータベースを組み合わせてコンテンツレコメンデーションシステムを作成する方法を探りました。適切なベクトルデータベースの選択は、効率的なアプリケーションの開発に非常に重要です。MyScaleは、ベクトルデータと構造化メタデータの両方を処理する能力に優れており、高速かつ正確なクエリ応答を保証します。効率的なスケーリング能力により、データセットが拡大しても強力なパフォーマンスを提供します。高度なインデックスとクエリ機能により、MyScaleはアプリケーションのパフォーマンスと精度を大幅に向上させます。
MyScaleを使用してAIアプリケーションを構築する予定はありますか?Twitter (opens new window)とDiscord (opens new window)でご意見を共有してください。



