
AIエージェント (opens new window)の登場により、さまざまな産業が再構築され、効率と生産性の向上がもたらされています。調査によると、60%以上 (opens new window)のビジネスオーナーがAIの導入による生産性の向上を期待しています。具体的には、64% (opens new window)の人々がAIが全体的なビジネスの生産性を向上させると考えており、42%の人々が仕事のプロセスを効率化することを期待しています。これらの統計は、AIエージェントがワークフローの最適化と成長を促進する上で、どれだけ変革的な影響を持っているかを示しています。
私たちは日常生活でAIエージェントに何気なく触れています。SiriやAlexaなどの仮想アシスタント (opens new window)から、ストリーミングプラットフォーム上のパーソナライズされたレコメンデーションシステム (opens new window)まで、これらのエージェントはユーザーエクスペリエンスの向上、カスタマイズされたソリューションの提供、ルーチンタスクの自動化に重要な役割を果たしています。
AI開発の世界では、LangChain (opens new window)はAIパワードの言語アプリケーションの作成を簡素化する革新的なモジュラーフレームワークとして注目されています。この革新的なツールは、言語モデルとのインタラクションを提供し、外部データソースとのシームレスな統合を可能にします。LangChainは、機械学習やAIの専門知識がなくてもアクセス可能な、通常複雑なとされる要素を抽象化することができます。
# LangChainにおけるChainとは何ですか?
LangChainは、元々LLM(Large Language Models)と外部データソースを統合するためのシームレスなインターフェースを提供するために開発されました。これにより、強力なAIモデルの機能と利用できる大量のデータとのギャップを埋めることができます。このフレームワークを使用することで、開発者はさまざまなソースからデータをアクセスし処理することができる、高度なアプリケーションを作成することができます。
LangChainの構造は、主に「チェーン」という概念に基づいています。これらのチェーンは、入力を所望の出力に変換するための操作のシーケンスを表します。LangChainの優れた点は、モジュラリティと柔軟性にあります。これにより、開発者は特定のニーズに合わせてカスタマイズされたワークフローを簡単に設計、テスト、再利用することができます。
例えば、チェーンはAPIからデータを取得し、そのデータを一連の変換を経て最終的にLLMに入力して応答を生成することから始まるかもしれません。このモジュラーアプローチにより、ワークフローの個々のコンポーネントを設計、テスト、再利用することが容易になります。
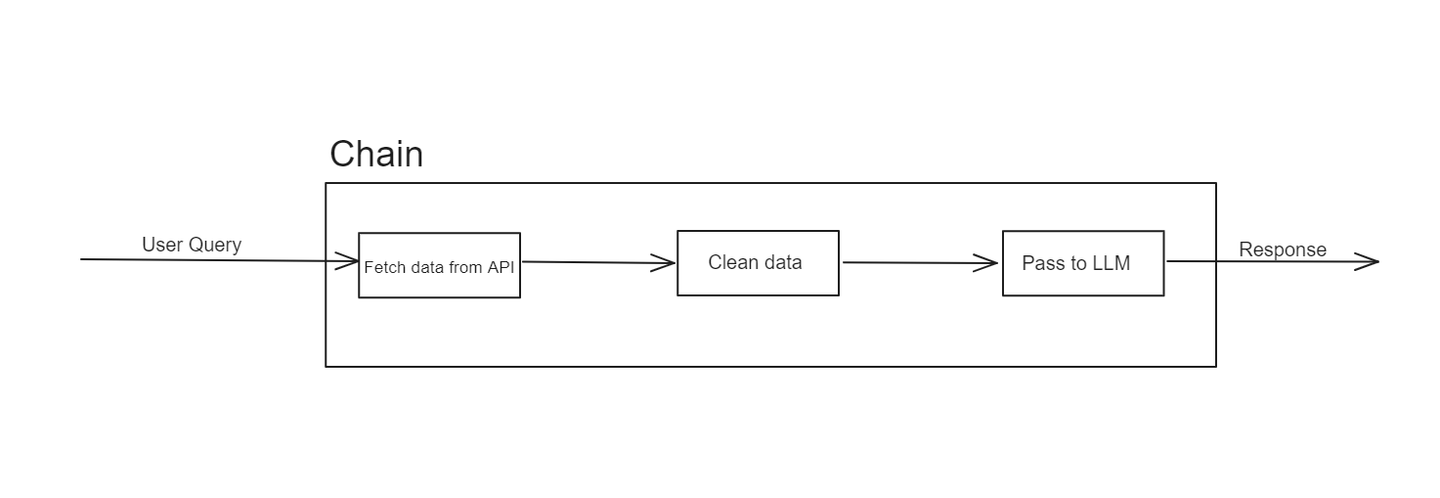
ただし、チェーンには制約があります。それらは直線的であり、より動的または適応的なタスクには苦労することがあります。ここで、LangChainエージェントが登場し、チェーンの制約に対処し、より柔軟性と知能を提供します。
# LangChainエージェントとは何ですか?
LangChainエージェントは、LLMの能力を向上させるために設計された強力なコンポーネントであり、LLMが意思決定を行い、その結果に基づいてアクションを実行することができるようにします。チェーンが事前に決められたアクションのシーケンスに従うのに対し、エージェントはLLMを推論エンジンとして使用し、実行するアクションのシーケンスを動的に決定します。
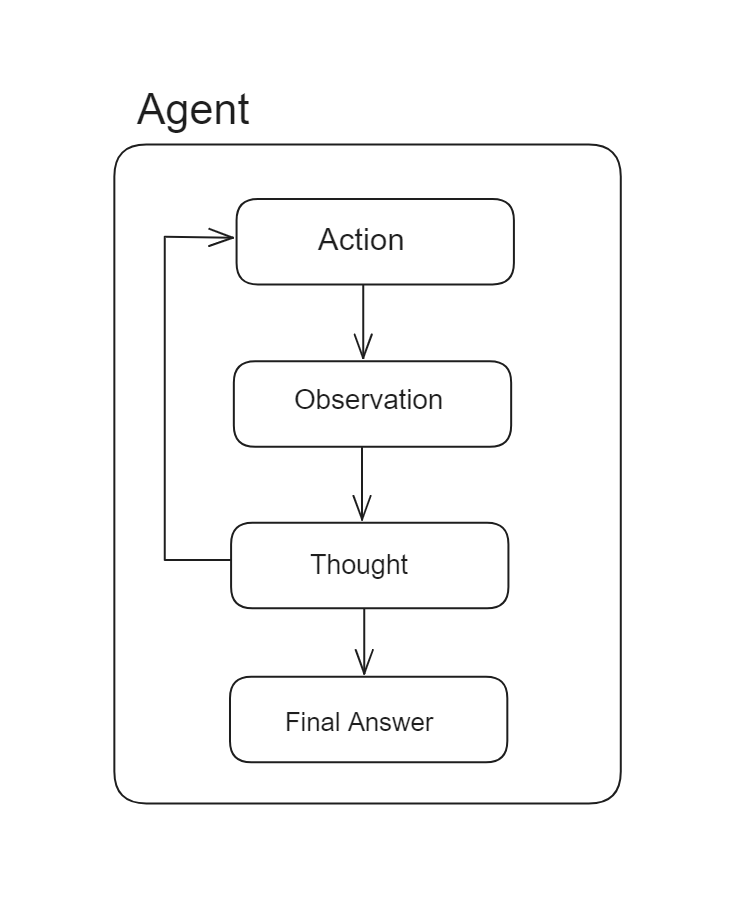
LangChainエージェントの主な機能は、入力データと前のアクションの結果に基づいてアクションを選択し実行することです。これにより、人間の介入を最小限に抑えつつ、複雑なタスクを処理することができます。例えば、エージェントはさまざまなツールやデータソースと対話し、情報を処理し、反復的にアクションを洗練させて特定の目標を達成することができます。
チェーンではアクションのシーケンスがハードコードされていますが、エージェントではアクションのシーケンスは事前に決まっておらず、言語モデルがどのアクションを取るか、どの順序で取るかを決定するために使用されます。
エージェントにはいくつかの重要な特徴があります:
- 適応性:エージェントは遭遇したデータとコンテキストに基づいてアクションを調整することができます。これにより、チェーンのような事前に定義されたステップのシーケンスに制約されることはありません。
- 自律性:エージェントは独立して動作し、常に監視を必要とせずに即座に意思決定を行うことができます。
- インタラクティブ性:エージェントは複数のデータソース、ツール、LLMと対話することができるため、さまざまなタスクを柔軟に処理することができます。
エージェントを組み込むことで、より洗練されたワークフローを管理し、動的な応答と適応的な振る舞いを必要とするタスクを処理することができます。これにより、単純なチェーンの制約を克服することができます。
# エージェントの主要なコンポーネントは何ですか?
LangChainで効果的なエージェントを構築するには、いくつかの主要なコンポーネントが必要です:
# ツール
ツールは、エージェントがタスクを実行するために使用するビルディングブロックです。API、データベース、データ処理関数との対話など、さまざまなタスクを実行するための特定の機能を提供します。
LangChainでは、さまざまなツールを利用する方法が用意されており、これには事前定義されたツール、リトリーバー (opens new window)をツールとして使用する方法、カスタムツール (opens new window)を定義する方法などがあります。それぞれについて詳しく見ていきましょう:
# 事前定義されたツール
LangChainでは、エージェント内で利用できるように事前に定義されたツールのコレクションが提供されています。これらのツールは、インポートしてエージェントに統合することで即座に使用することができます。例えば:
from langchain_community.tools import DuckDuckGoSearchRun
search = DuckDuckGoSearchRun()
この例では、langchain_community.toolsモジュールからDuckDuckGoSearchRunツールをインポートし、初期化しています。初期化後、このツールは後述するツールキット (opens new window)を介してエージェント内で利用することができます。
# ツールとしてリトリーバーを使用する
ユーザーのクエリに基づいてベクトルデータベース (opens new window)からデータを取得する場合、LangChainではリトリーバーをツールに変換し、エージェント内で使用することができます。以下のように行います:
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
"ツールの名前",
"ツールの説明",
)
LangChainのcreate_retriever_toolメソッドを使用することで、任意のリトリーバーをLangChainのツールに変換することができます。このメソッドは3つの引数を受け取ります:以前に作成したリトリーバー、ツールの名前、ツールの説明です。説明はLLMがこのツールを使用するタイミングとどのようなデータを保持しているかを判断するのに役立ちます。
# カスタムツール
LangChainは、開発者がアプリケーションやユースケースに合わせてカスタマイズされたツールを定義することも可能です。カスタムツールを定義する最も簡単な方法は、Pythonのメソッドに@toolデコレータを使用することです。以下に例を示します:
from langchain.agents import tool
@tool
def get_word_length(word: str) -> int:
"""単語の長さを返します。"""
return len(word)
get_word_length.invoke("abc")
この例では、_メソッド名がツール名_として使用され、_docstringがツールの説明_として機能します。この設定により、エージェントはツールを効果的に理解し利用することができます。
より複雑なツールの場合は、LangChainが提供するBaseToolクラスを拡張して、特定のニーズに合わせた洗練されたカスタムツールを作成することができます。
# ツールキット
ツールキットは、エージェントがアクセスできるツールのコレクションです。エージェントが実行できるアクションの範囲と利用できるリソースを定義します。以下のように、エージェントで使用するツールのリストを指定してツールキットを作成します:
tool_kit=[retriever_tool,get_word_length]
ツールキット内のすべてのツールは、どのように定義されているかに関係なく、同じように機能します。
# LLM(Large Language Model)
LLMはエージェントの知能の核であり、自然言語の入力を処理し、応答を生成し、意思決定プロセスを推進します。LangChainは、GPT-4 (opens new window)、BERT (opens new window)、T5 (opens new window)など、最先端のLLMとシームレスに統合されるため、エージェントが最新のAI機能にアクセスできるようにしています。
この統合により、自然言語の理解が向上し、洗練された意思決定が可能になり、特定のドメインにカスタマイズすることができます。これにより、LangChainエージェントは、複雑なタスクを実行する際に柔軟で強力な性能を発揮します。
# プロンプト
プロンプトは、LLMの動作をガイドする初期の指示またはクエリです。明確で効果的なプロンプトの作成は、エージェントが正確かつ効率的にタスクを実行するために重要です。
LangChain Hub
LangChain Hubは、プロンプト、チェーン、エージェントなどを検索、共有、管理するための中央リポジトリです。開発者やチームは、特定のユースケースや使用している言語モデルに合わせて作成された高品質のプロンプトにアクセスし、開発プロセスを加速することができます。
LangChain Hubの使用方法
LangChain Hub (opens new window)を使用すると、パブリックプロンプトを簡単にコードベースに取り込むことができます。これにより、特定のユースケースと使用している言語モデルに合わせて作成された緻密なプロンプトを活用することができます。以下に、事前に書かれたプロンプトをインポートする方法を示します:
from langchain import hub
prompt = hub.pull("hwchase17/openai-functions-agent")
コードhub.pull("hwchase17/openai-functions-agent")は、LangChain Hubから事前定義されたプロンプトを取得するために使用されます。この特定のプロンプトは、OpenAIの強力な言語モデルを使用するエージェントの機能を向上させるために設計されたコレクションの一部です。
# エージェントエグゼキューター
エージェントエグゼキューターは、LangChainエコシステムの重要な要素です。エージェントの活動を組織し、操作のフローを管理し、各コンポーネントが円滑に機能するようにします。
LangChainのドキュメントによれば、エージェントエグゼキューターのワークフローはおおよそ次のようになります:
next_action = agent.get_action(...)
while next_action != AgentFinish:
observation = run(next_action)
next_action = agent.get_action(..., next_action, observation)
return next_action
つまり、エージェントが最終的な応答を返すまで、エージェントの次のアクションメソッドを繰り返し呼び出すwhileループです。エグゼキューターは次のような役割を果たします:
- タスクの開始:与えられたプロンプトとコンテキストに基づいてエージェントの活動を開始します。
- ワークフローの管理:ツール、ツールキット、LLMの相互作用を調整し、ワークフローのスムーズな実行を確保します。
- エラーの処理:エージェントの操作中に発生するエラーや例外 (opens new window)を管理し、堅牢で信頼性の高いパフォーマンスを提供します。
これらのコンポーネントは、エージェントの機能において重要な役割を果たします。LangChainはこれらのコンポーネントを非常に柔軟に扱い、開発者が各部分をカスタマイズして最適化することができるようにしています。

# MyScaleDBとLangChainを使用してエージェントを作成する
これまで、エージェントを構築するために必要な重要なコンポーネントを探索してきました。では、MyScaleDB (opens new window)とDuckDuckGo (opens new window)を使用してエージェントを作成しましょう。このエージェントには2つのツールがあります:
- リトリーバー:このツールはMyScaleDBのテレメトリ (opens new window)に関連する情報を取得します。
- DuckDuckGoツール:このツールはインターネットからデータを取得します。
# 環境のセットアップ
エージェントの構築を開始する前に、必要なツールとテクノロジーをインストールしましょう。ターミナルを開き、次のコマンドを入力します:
pip install langchain langchain_openai duckduckgo-search
これにより、このエージェントの構築に必要なすべてのパッケージがインストールされます。
# リトリーバーツールのデータの読み込み
まず、LangChainのWebBaseLoaderを使用してリトリーバーツールのデータを読み込みましょう:
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# インターネットからデータを読み込む
loader = WebBaseLoader("https://myscale.com/blog/ja/myscale-telemetry-llm-app-observability/")
docs = loader.load()
# テキストをより小さなチャンクに分割する
documents = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200
).split_documents(docs)
# MyScaleDBの認証情報の設定
リトリーバーを初期化する前に、ベクトルデータベースの認証情報を設定する必要があります。ここではMyScaleを使用しているため、クイックスタートガイド (opens new window)を参照してください。以下のように認証情報を設定します:
import os
# MyScaleDBの認証情報
os.environ["MYSCALE_HOST"] = "ホスト名"
os.environ["MYSCALE_PORT"] = "443"
os.environ["MYSCALE_USERNAME"] = "ユーザー名"
os.environ["MYSCALE_PASSWORD"] = "パスワード"
# OpenAI LLMのAPIキーを設定
os.environ["OPENAI_API_KEY"] = "APIキー"
このプロジェクトでは、OpenAIの埋め込み (opens new window)とChatGPTを利用するため、OpenAI API (opens new window)キーの設定が必要です。
# リトリーバーの初期化
次に、リトリーバーを初期化し、データをMyScaleDBリトリーバー (opens new window)に入れましょう。
from langchain_community.vectorstores import MyScale
from langchain_openai import OpenAIEmbeddings
vector = MyScale.from_documents(documents, OpenAIEmbeddings())
retriever = vector.as_retriever()
リトリーバーが準備できたら、次のステップはリトリーバーをLangChainのツールに変換することです。これにはcreate_retriever_toolメソッドを使用します:
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
"MyScale_telemetry",
"MyScaleのテレメトリに関する情報を検索します。テレメトリに関する質問は、このツールを使用する必要があります!",
)
定義したツールは、ユーザーのクエリがMyScaleのテレメトリに関するものである場合に使用されます。先述したように、ツールの説明は非常に重要です。クエリに基づいて適切なツールを選択するために役立ちます。
# 検索ツールの定義
次に、エージェントのための2番目のツールを定義しましょう。これは、現在のイベントを検索したり、インターネットから最新の情報を取得するための事前定義されたツールです。
from langchain_community.tools import DuckDuckGoSearchRun
search = DuckDuckGoSearchRun()
# ツールキットの作成
エージェントはリトリーバーとWeb検索の2つのツールを使用します。ツールキットを作成しましょう:
tools = [search, retriever_tool]
# LLMの初期化
エージェントにはOpenAIのGPT-3.5-turboモデルを使用します:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
# プロンプトの取得
エージェントはLangChain Hubの同じ事前定義のプロンプトを使用します。これは、エージェントにOpenAIモデルを使用しているためです。
from langchain import hub
# プロンプトテンプレートを取得
prompt = hub.pull("hwchase17/openai-functions-agent")
prompt.messages
# エージェントとエージェントエグゼキューターの作成
LangChainでは、エージェント (opens new window)の種類がいくつか提供されており、それぞれが独自の推論能力と機能を備えています。このプロジェクトでは、最も高度で堅牢なエージェントであるOpenAI Toolsエージェント (opens new window)を使用します。公式のドキュメントで強調されているように、このエージェントはOpenAIの最新モデルを利用しており、パフォーマンスが向上し、幅広い機能を提供しています。
from langchain.agents import create_tool_calling_agent
agent = create_tool_calling_agent(llm, tools, prompt)
エージェントを作成したら、AgentExecutorにエージェントを渡して、定義したエージェントの機能をすべて処理させましょう。
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
AgentExecutorでverbose=Trueを設定すると、エージェントの操作の詳細なログが記録されます。これにより、エージェントの意思決定プロセスをデバッグや理解に役立つ詳細な情報を提供します。
# エージェントにメモリを追加する
エージェントにメモリを追加することで、以前の対話からのコンテキストを保持し、関連性のある一貫した応答を提供する能力が向上します。メモリにより、エージェントは学習し適応することができ、パフォーマンスを向上させ、対話をよりパーソナライズされたものにし、よりインテリジェントにします。
from langchain.memory import ChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
memory = ChatMessageHistory(session_id="test-session")
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
lambda session_id: memory,
input_messages_key="input",
history_messages_key="chat_history",
)
セッションIDを使用することで、個々のユーザーセッションを維持し、各セッションに固有の対話を正確に追跡および呼び出すことができます。
# エージェントの呼び出し
最後に、エージェントを呼び出して情報を取得することができます。次のクエリを行うと:
# MyScaleのテレメトリに関する情報を取得
agent_executor.invoke({"input": "MyScaleのテレメトリについて教えてください。"}, config={"configurable": {"session_id": "<foo>"}})
結果は次のようになります:
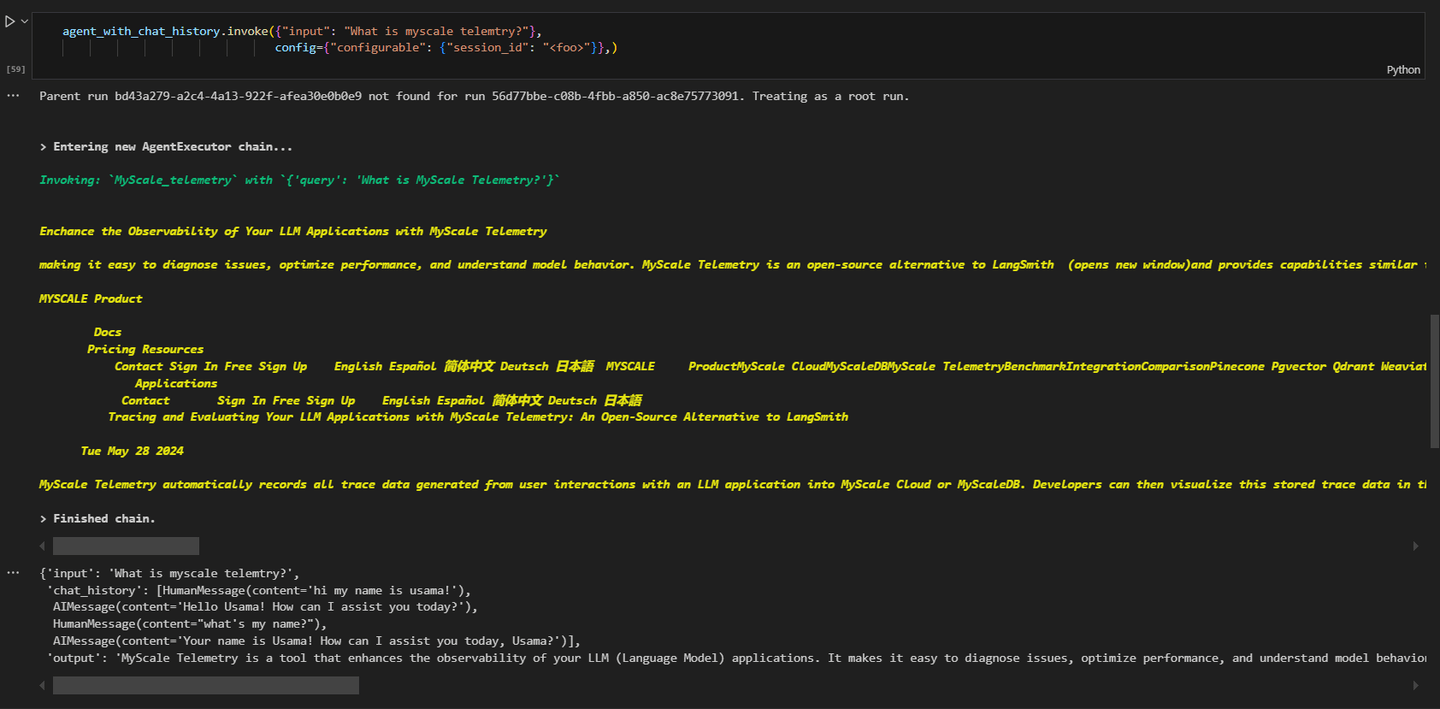
クエリはMyScaleのテレメトリに関連しており、エージェントはこのためにMyScale_telemetryエージェントを呼び出しています。
別のクエリを行い、インターネットから最新のデータを取得しましょう。
# カリフォルニアの天気はどうですか?
agent_executor.invoke({"input": "カリフォルニアの天気はどうですか?"}, config={"configurable": {"session_id": "<foo>"}})
結果は次のようになります:
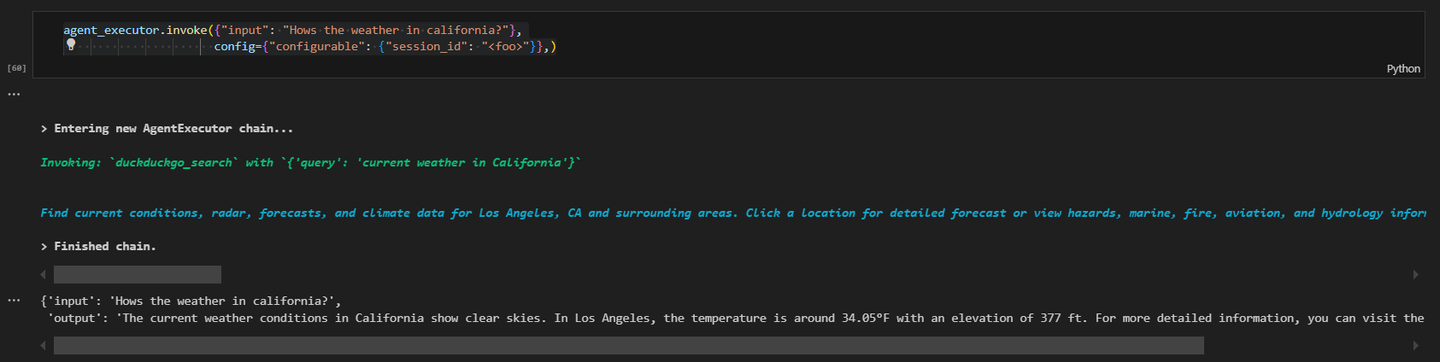
この実践的な例では、MyScaleDBとDuckDuckGoツールを使用してLangChainエージェントを作成する方法を示しました。各コンポーネントはエージェントの機能にとって重要であり、環境を正しく設定することでスムーズな動作が保証されます。
# 結論
LangChainエージェントは、LLMの機能を向上させる高度なコンポーネントです。これは、LLMが意思決定を行い、その結果に基づいてアクションを実行することができるようにすることで実現されます。事前に決められたアクションのシーケンスに従う従来のチェーンとは異なり、エージェントはLLMを使用してアクションのシーケンスを動的に決定します。この柔軟性により、エージェントはより効率的に複雑で変化するタスクを処理することができます。LangChainエージェントは非常にモジュラーであり、さまざまなツールやカスタム関数を統合することが容易であり、開発者は特定のニーズに合わせたワークフローを作成することができます。
MyScaleDB (opens new window)は、優れたパフォーマンスとスケーラビリティで知られるベクトルデータベースのトップ選択肢です。MSTG(Multi-Stage Tree Graph)アルゴリズム (opens new window)により、より高速かつ正確なデータの取得が可能であり、これはAI駆動のタスクにとって重要です。MyScaleDBは大量のデータを効率的に処理するために設計されており、信頼性の高い高速な操作を提供します。これにより、効率的なデータ管理とスケーラビリティが必要な堅牢なAIアプリケーションを作成する開発者にとって、重要なツールとなります。



