
大規模言語モデル(LLM)は、人間のようなテキストの理解と生成能力によって、非常に価値をもたらしています。しかし、これらのモデルには注目すべき課題もあります。これらのモデルは膨大なデータセットで訓練されており、膨大なコストと時間を要します。大規模なデータセットでこれらのモデルを定期的に再訓練することはほぼ不可能であり、最新のデータで更新されないため、未知のトピックに関するクエリに対して正確さに欠ける可能性があります。この現象は「幻覚」として知られ、アプリケーションのパフォーマンスを低下させ、信頼性と信憑性に関する懸念を引き起こすことがあります。
幻覚を克服するためには、さまざまな技術が用いられますが、その中でも最も広く使用されているのが「Retrieval Augmented Generation(RAG)」です。RAGは、効率とパフォーマンスの面で優れているため、AIアプリケーションの向上において最良の選択肢 (opens new window)とされています。
本記事では、本番環境で使用できる完全な高度なRAGシステムの設計方法を紹介します。
# Retrieval Augmented Generationとは
RAGは、幻覚を克服するために最も広く使用されている技術です。これにより、LLMが最新の情報を保持し、より良い応答を提供できるようになります。RAGは、モデルの応答生成フェーズで動的に関連する外部データを取得します。このアプローチにより、頻繁な再訓練の必要なしに、LLMが最新の情報にアクセスできるようになります。これにより、モデルの応答がより正確で文脈に適したものになります。
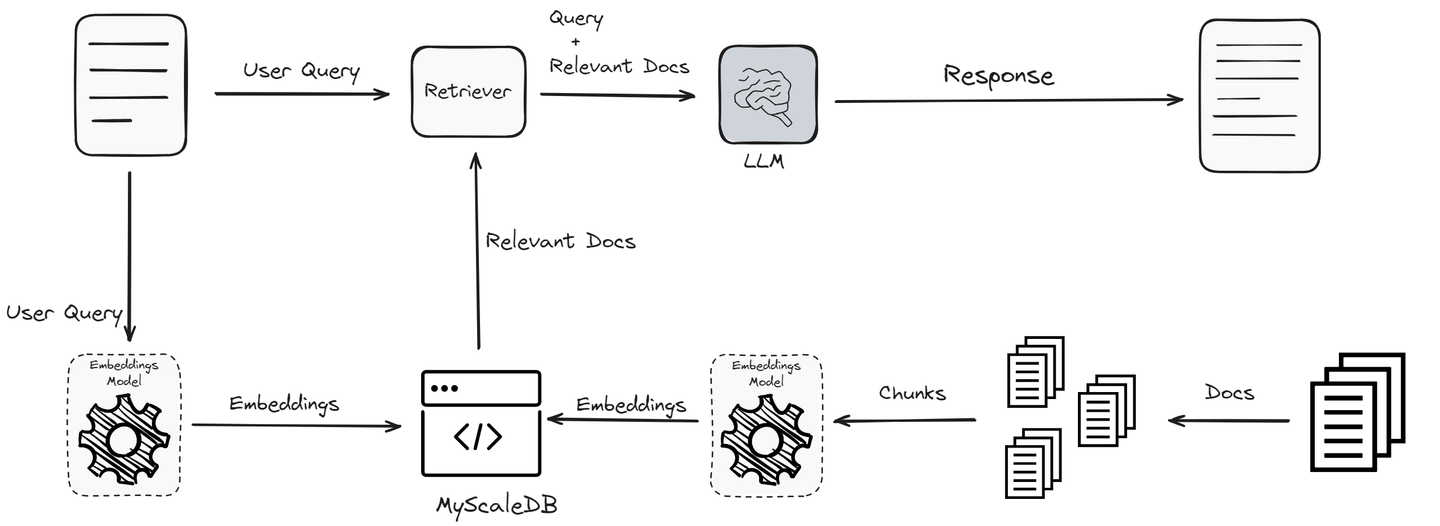
このプロセスは、ユーザーのクエリから始まり、埋め込みモデルを使用してクエリを埋め込みに変換し、意味的な本質を捉えます。次に、これらの埋め込みは、ナレッジベースまたはベクトルデータベース内のベクトルとの類似性検索を経て、最も関連性の高い情報を特定します。この検索から得られた上位の「K」個の結果は、LLMに追加の文脈として統合されます。
元のクエリとこの補足データを処理することで、LLMはより正確で文脈に適した応答を生成する能力を備えます。これにより、幻覚の問題が軽減されるだけでなく、モデルの出力が頻繁な再訓練なしで最新かつ信頼性のあるものであることが保証されます。
関連記事: RAGの仕組み (opens new window)
# LlamaIndexとは
LlamaIndex (opens new window)(以前のGPT Index)は、LLMとナレッジベースを接続するのに役立つ接着剤のような存在です。さまざまなソースからデータを取得し、RAGアプリケーションで使用できるいくつかの組み込みメソッドを提供します。これには、PDFやPowerPointなどのさまざまなファイル形式、NotionやSlackなどのアプリケーション、PostgresやMyScaleDBなどのデータベースが含まれます。
LlamaIndexには、データの収集、整理、検索、統合を支援する重要なツールが備わっています。データへのアクセスと使用が容易になり、パワフルでカスタマイズされたLLMアプリケーションとワークフローを構築することができます。
LlamaIndexの主なコンポーネントには次のものがあります。
- データコネクタ: これにより、LlamaIndexはさまざまなデータソースにアクセスできます。ローカルファイルシステム、クラウドベースのストレージサービス、データベースなどに接続することができます。これにより、必要な情報を取得することができます。
- インデックス: LlamaIndexのインデックスは、データを迅速にアクセスできるように整理するための重要なコンポーネントです。すべての接続されたソースの情報を構造化された形式に分類し、簡単に検索できるようにします。これにより、検索プロセスが高速化され、LLMが必要なときに最も関連性の高い情報を利用できるようになります。
- クエリエンジン: このコンポーネントは、接続されたデータソースを効率的に検索します。クエリを処理し、関連する情報を検索してLLMが使用できるようにします。
LlamaIndexの各コンポーネントは、RAGアプリケーションの機能を向上させるために重要な役割を果たします。さまざまなデータに効率的にアクセスし、使用することができるようになります。
# MyScaleDBの概要
MyScaleDB (opens new window)は、AIアプリケーションの大量のデータを管理するために特別に設計され、最適化されたオープンソースのSQLベクトルデータベースです。これは、SQLデータベースであるClickHouse (opens new window)の上に構築されており、ベクトルの類似性検索の能力と完全なSQLサポートを組み合わせています。
専門のベクトルデータベースとは異なり、MyScaleDBはベクトル検索アルゴリズムを構造化されたデータベースとシームレスに統合することができます。ベクトルと構造化データを同じデータベースで管理することができます。この統合により、コミュニケーションの簡素化、柔軟なメタデータのフィルタリング、SQLとベクトルの結合クエリのサポート (opens new window)、汎用の汎用データベースに通常使用される確立されたツールとの互換性などの利点が得られます。
MyScaleDBをRAGアプリケーションに統合することで、生成されるコンテンツの品質に直接影響を与えるより複雑なデータの相互作用を可能にします。
# LlamaIndexとMyScaleDBを使用したRAG: ステップバイステップガイド
RAGアプリケーションを構築するためには、まずMyScaleDBのアカウント (opens new window)を作成する必要があります。MyScaleDBでは、新規ユーザーに対して最大500万ベクトルまでの無料ストレージを提供しているため、初期費用は必要ありません。
アカウントを作成したら、ホームページに移動し、右上隅の「+ 新しいクラスター」をクリックします。すると、次のようなダイアログボックスが表示されます。
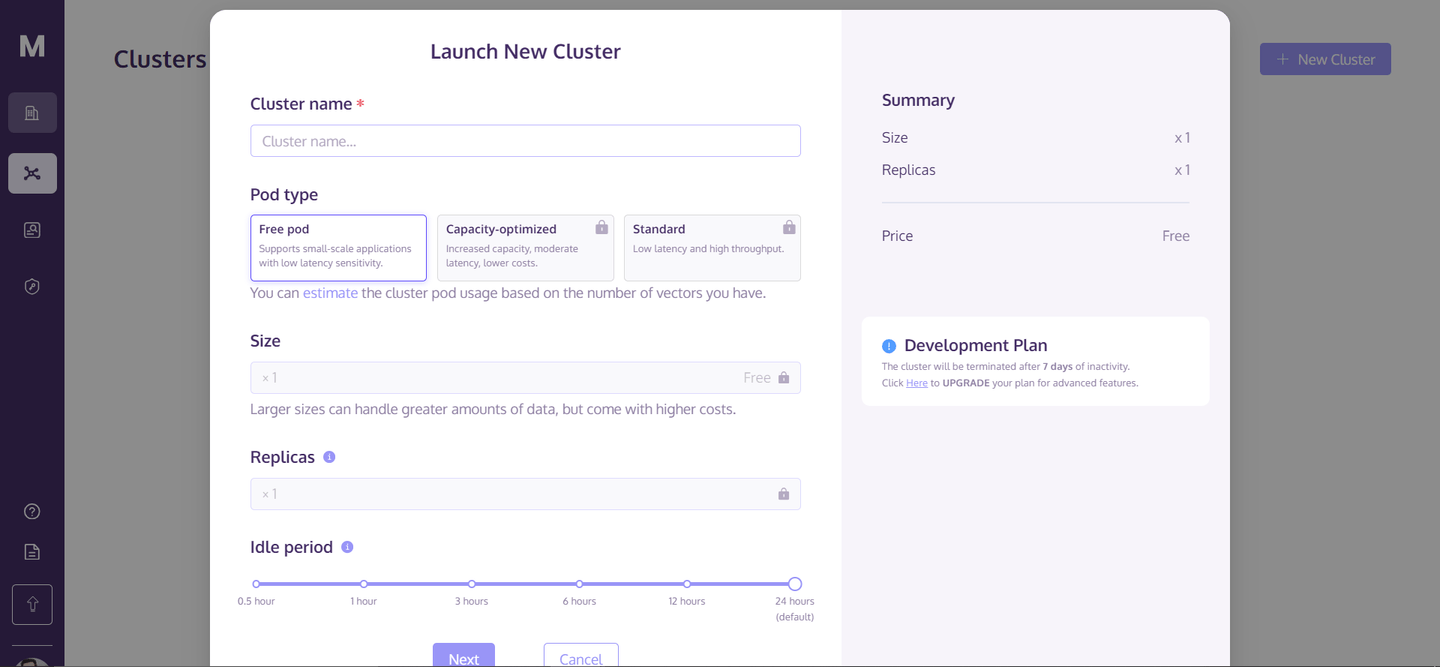
クラスターの名前を入力し、「次へ」をクリックします。クラスターの初期化には数秒かかりますが、初期化が完了するとアクセスできるようになります。
クラスターにアクセスするには、MyScaleDBのプロファイルに戻り、「アクション」テキストの下にある縦に並んだ3つの点の上にカーソルを合わせ、接続の詳細をクリックします。
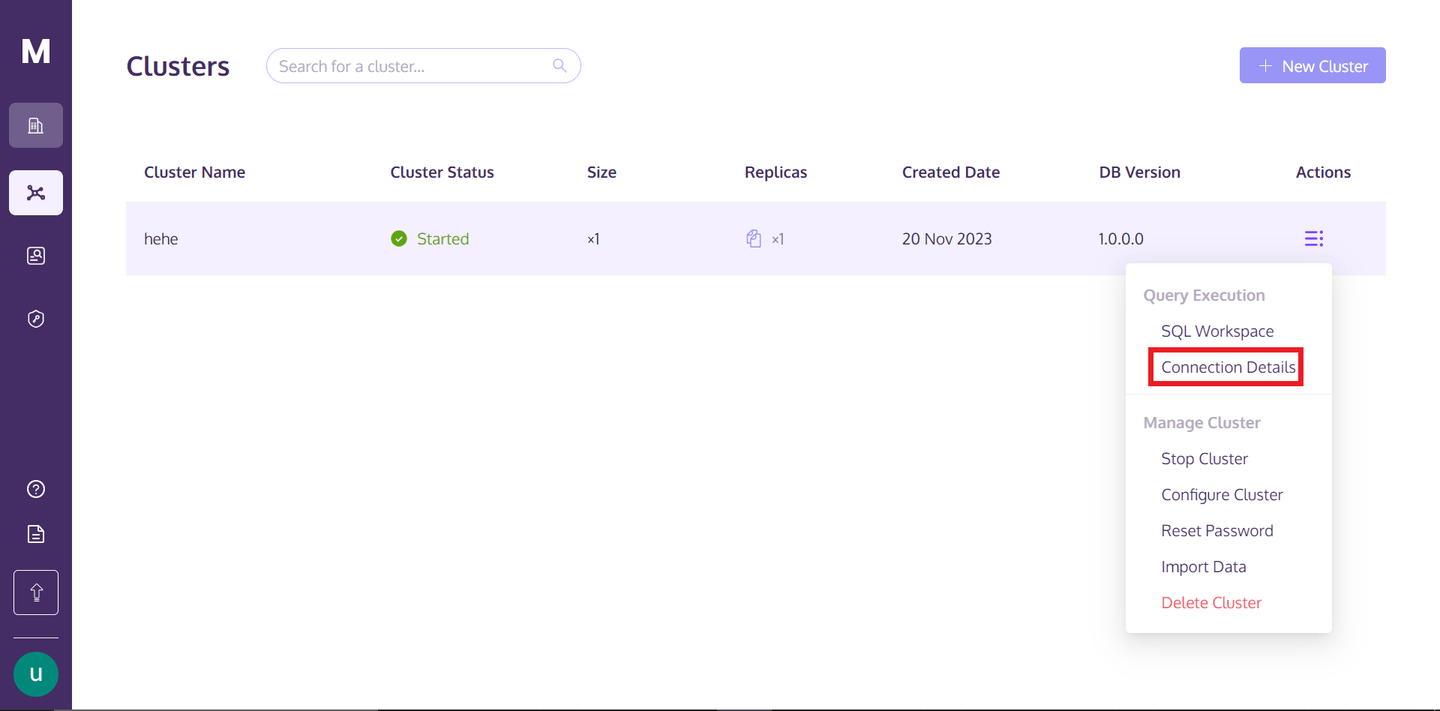
「接続の詳細」をクリックすると、次のボックスが表示されます。
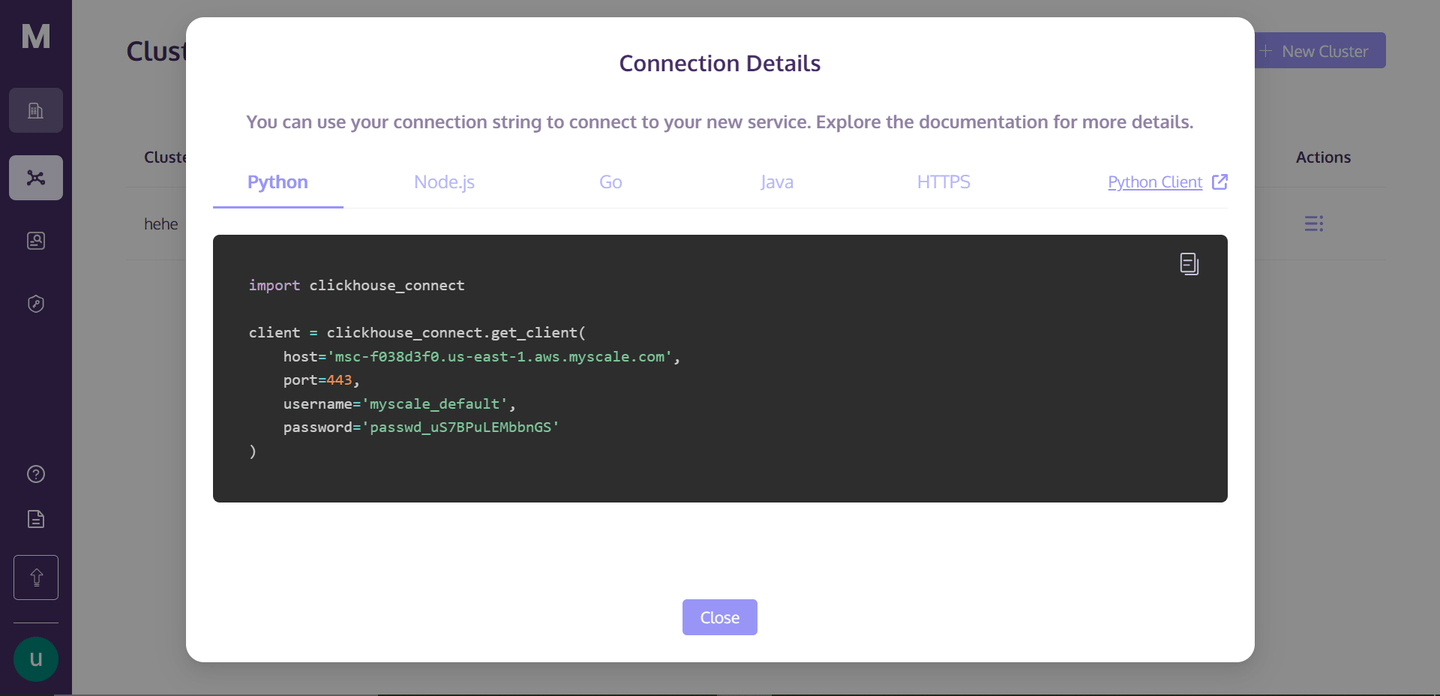
これらは、クラスターに接続するために必要な接続の詳細です。ディレクトリ内にPythonのノートブックファイルを作成し、RAGアプリを構築しましょう。

# 環境のセットアップ
依存関係をインストールするには、ターミナルを開き、次のコマンドを入力します。
pip install -U llama-index clickhouse-connect llama-index-postprocessor-jinaai-rerank llama-index-vector-stores-myscale
このコマンドにより、必要なすべての依存関係がインストールされます。ここでは、Jina Reranker (opens new window)を使用しています。このアルゴリズムは、検索結果を大幅に改善し、ヒット率が8%以上向上し、平均相互順位が33%向上します。
# ナレッジベースとの接続の確立
まず、MyScaleベクトルDBとの接続を確立する必要があります。これには、「接続の詳細」ページから詳細をコピーし、次のように貼り付けます。
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-host',
port=443,
username='your-user-name',
password='your-password-here'
)
これにより、ナレッジベースとの接続が確立され、オブジェクトが作成されます。
# データのダウンロードと読み込み
ここでは、Nikeの製品カタログデータセットを使用します。このコードは、まず.pdfをダウンロードし、ローカルに保存します。次に、LlamaIndexのリーダーを使用して.pdfを読み込みます。
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
import requests
url = '<https://niketeam-asset-download.nike.net/catalogs/2024/2024_Nike%20Kids_02_09_24.pdf?cb=09302022>'
response = requests.get(url)
with open('Nike_Catalog.pdf', 'wb') as f:
f.write(response.content)
reader = SimpleDirectoryReader(
input_files=["Nike_Catalog.pdf"]
)
documents = reader.load_data()
# データのカテゴリ分け
この関数は、ドキュメントを異なるカテゴリに分類します。これにより、ナレッジベース全体にフィルタリングされたクエリを書く際に使用します。ドキュメントをカテゴリ別に分類することで、関連する検索を行うことができ、RAGシステムの検索の効率と関連性が大幅に向上します。
def analyze_and_assign_category(text):
if "football" in text.lower():
return "Football"
elif "basketball" in text.lower():
return "Basketball"
elif "running" in text.lower():
return "Running"
else:
return "Uncategorized"
# インデックスの作成
ここでは、MyScaleVectorStoreが提供するベクトルストアにデータをロードします。まず、各ドキュメントのメタデータを追加し、次にベクトルストアに追加します。インデックスを作成することで、高速で効率的な検索操作が可能になります。データをインデックス化することで、システムは類似性の尺度に基づいて関連するドキュメントを迅速に検索することができます。これは、RAGアプリケーションにおいて関連性の高いドキュメントを取得するために重要です。
from llama_index.vector_stores.myscale import MyScaleVectorStore
from llama_index.core import StorageContext
for document in documents:
category = analyze_and_assign_category(document.text)
document.metadata = {"Category": category}
vector_store = MyScaleVectorStore(myscale_client=client)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)
注意: MyScaleDBでインデックスを作成する際には、OpenAIの埋め込みモデルを使用します。これを有効にするには、OpenAIキーを環境変数として追加する必要があります。
# シンプルなクエリ
シンプルなクエリを実行するには、既存のインデックスをクエリエンジンに変換する必要があります。クエリエンジンは、検索クエリを処理し解釈する特殊なツールです。
query_engine = index.as_query_engine()
response = query_engine.query("I want a few running shoes")
print(response.source_nodes[0].text)
クエリエンジンを使用して、「I want a few running shoes」というクエリを実行します。エンジンはこのクエリを処理し、インデックスされたドキュメントを検索して、クエリの条件に最も適合するマッチを見つけます。
# フィルタリングされたクエリ
ここでは、MetadataFiltersとExactMatchFilterクラスを使用して、メタデータフィルタを設定したクエリエンジンを構成します。ExactMatchFilterは「Category」メタデータフィールドに適用され、明示的に「Running」と分類されたドキュメントのみを含めます。このフィルタにより、クエリエンジンはランニングに関連するドキュメントのみを考慮し、より関連性の高い結果を得ることができます。similarity_top_k=2の設定は、上位2つの類似性の高いドキュメントに検索を制限し、vector_store_query_mode="hybrid"は、最適な結果を得るためにベクトルと従来の検索方法の組み合わせを示しています。
from llama_index.core.vector_stores import ExactMatchFilter, MetadataFilters
query_engine = index.as_query_engine(
filters=MetadataFilters(
filters=[
ExactMatchFilter(key="Category", value="Running"),
]
),
similarity_top_k=2,
vector_store_query_mode="hybrid",
)
response = query_engine.query("I want a few running shoes?")
print(response.source_nodes[0].text)
この出力は、ユーザーのクエリに非常に近いものであり、メタデータフィルタが検索結果の精度を向上させる方法を示しています。
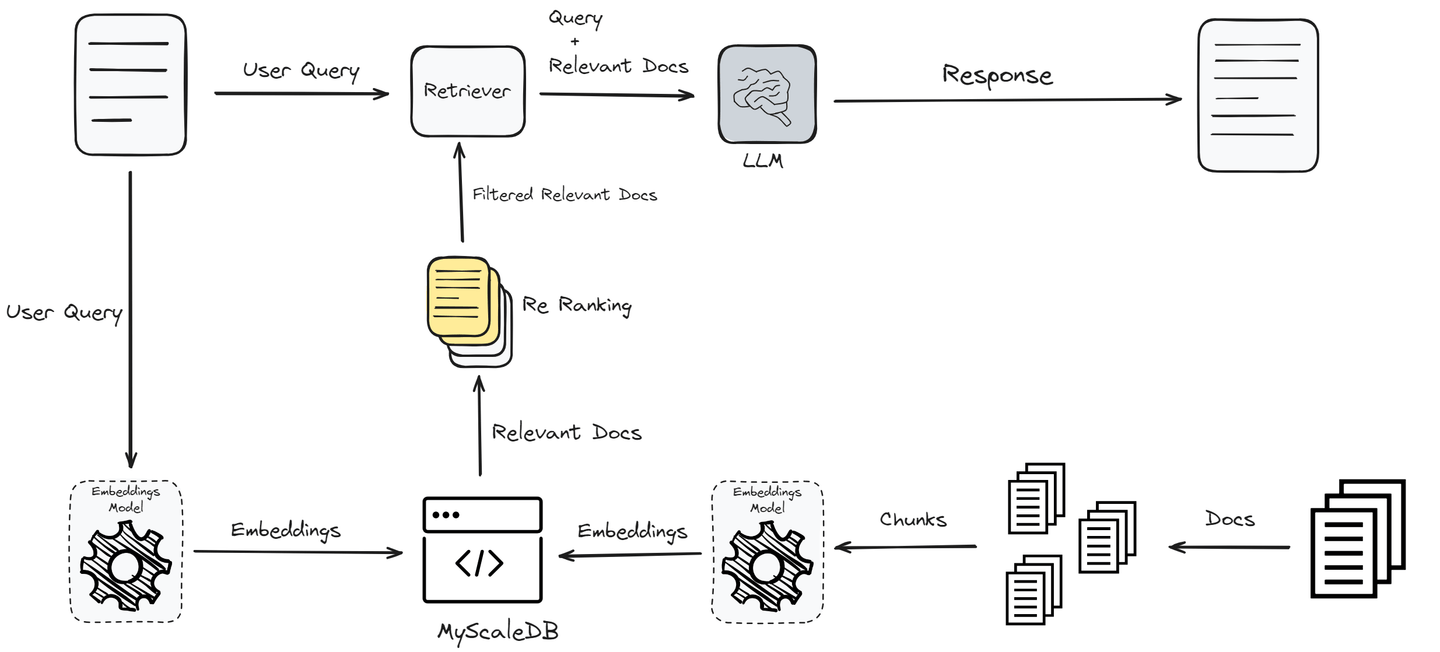
これまで、最も単純な形式のRAGを実装しましたが、最良のパフォーマンスを得ることはできません。パフォーマンスを向上させ、ユーザーに正確な回答を提供するために、さらにフィルタリングされたクエリや前処理、再ランキングなどの高度なテクニックを使用します。
# ドキュメントの取得を向上させるための再ランキングの追加
このコードは、Jina AIを使用して初期クエリで取得したドキュメントをさらに絞り込むための再ランキングメカニズムを統合しています。
from llama_index.postprocessor.jinaai_rerank import JinaRerank
jina_rerank = JinaRerank(api_key="api-key-here", top_n=2)
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-4", temperature=0)
query_engine = index.as_query_engine(
similarity_top_k=10, llm=llm, node_postprocessors=[jina_rerank]
)
response = query_engine.query("I want a few running shoes?")
print(response.source_nodes[0].text)
注意: Jina Rerankerのキーはこちら (opens new window)で見つけることができます。APIをクリックし、新しく開かれたページをスクロールすると、Reranker APIセクションのすぐ下にAPIキーが表示されます。
# 結論
RAGは、LLMが最新の情報を保持し、応答が正確かつ関連性のあるものになるようにするために大きな助けとなります。ただし、単純なRAGシステムは、パフォーマンスの面で本番環境で使用されることはありません。パフォーマンスを向上させるためには、再ランキング、前処理、フィルタリングされたクエリなどの高度なテクニックを使用します。
ベクトルデータベースの選択も、RAGシステムのパフォーマンスに影響を与える要素です。
アプリケーションのニーズに合わせたベクトルデータベースの選択は重要です。MyScaleDBはSQLベクトルデータベースであり、使い慣れたSQLインターフェースを備えているため、開発者にとって良い選択肢です。また、手頃な価格であり、高速で本番レベルのアプリケーションに最適化されています。
ご意見やご提案がありましたら、Twitter (opens new window)またはDiscord (opens new window)までお気軽にお問い合わせください。



