
Retrieval-Augmented Generation (RAG) (opens new window)は、外部の知識源を参照することで大規模な言語モデルの出力を強化する技術です。この手法により、モデルの再学習が不要ながら、より正確で文脈に即した応答が可能となります。さまざまなドメインで言語モデルのパフォーマンスを向上させるための費用効果の高い方法です。
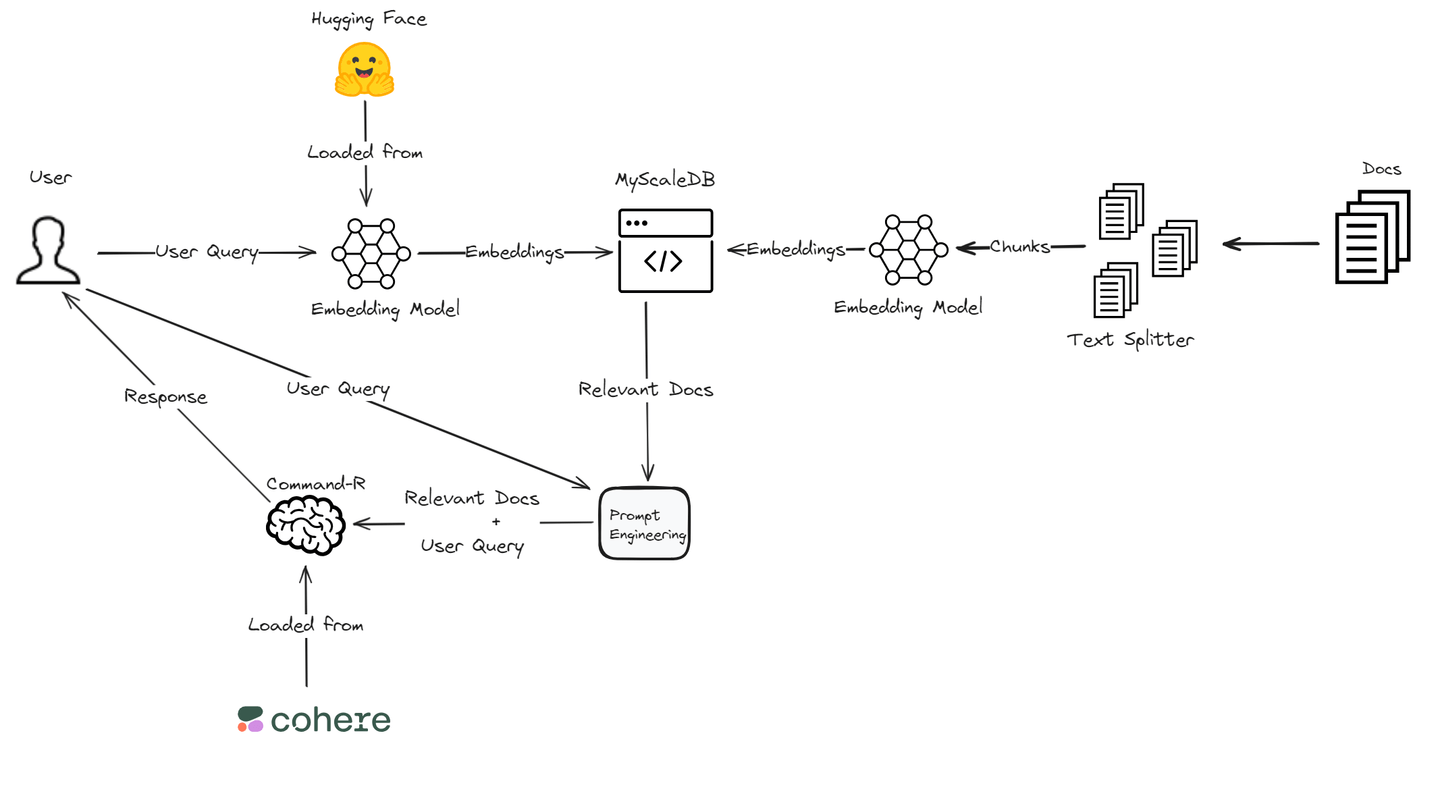
このブログでは、CohereのCommand Rモデル (opens new window)を使用してRAGアプリケーションを構築します。このモデルは、RAGにおいて優れたパフォーマンスを発揮するため、関連情報の検索と生成において高い精度を提供します。埋め込み (opens new window)については、さまざまなNLPタスクをサポートし、ディープラーニングフレームワークとの統合が容易なHugging FaceのTransformersライブラリ (opens new window)を活用します。さらに、高性能かつコスト効率の良いMyScaleDBを使用して埋め込みとテキストチャンクを保存します。この技術の組み合わせにより、特定のアプリケーションのニーズに合わせた強力で効率的なRAGシステムが実現されます。
# Cohereとは?
Cohere (opens new window)は、ビジネスの顧客対話を自動化し向上させるための高度な言語モデルの開発に特化したプラットフォームです。会話エージェントや要約などのアプリケーションをサポートするCommandなどの最新の大規模言語モデル(LLM)や、検索結果の関連性を最適化するRerankなどのツールを提供しています。これらのツールにより、企業のコミュニケーション効率と精度を向上させることができます。
主要なLLMに加えて、Cohereはテキスト分類や意味検索などのタスクに使用する「Embed」モデルや、ドキュメントやエンタープライズデータソースからの情報の統合と検索を可能にするRAGの機能などのモデルも提供しています。これらのモデルにより、企業は安全かつスケーラブルなAIソリューションを展開し、全体的な業務効率と顧客体験を向上させることができます。
# Hugging Faceとは?
Hugging Face (opens new window)は、最新の機械学習を広範なユーザーにアクセス可能にすることに特化したプラットフォームで、高度な言語モデルで知られています。彼らの主力製品であるTransformersライブラリはオープンソースであり、テキスト生成、要約、翻訳などのタスクをサポートしています。このライブラリはPyTorchやTensorFlowなどの人気のあるディープラーニングフレームワークと互換性があり、BERTやGPT-2などの最先端のNLPモデルを簡単に実装することができます。
強力なNLPツールを提供するだけでなく、Hugging FaceはジェネレーティブAIモデルの展開を容易にするためのさまざまなノーコードおよびローコードのソリューションも提供しています。モデルのデプロイメントを簡単にするためのInference Endpointsや、機械学習アプリケーションのホスティングに使用するSpacesなどの機能が含まれています。Hugging Faceはまた、モデルやデータセット、アプリケーションを共有およびアクセスするためのModel Hubを通じてコラボレーションをサポートしています。このコミュニティ主導のアプローチにより、機械学習の民主化とAI分野でのイノベーションが促進されます。
# CohereとHugging Faceを使用したRAGアプリケーションの構築要素
CohereとHugging Faceを使用して堅牢なRAGアプリケーションを構築するための重要なコンポーネントについて見ていきましょう。
# CohereのCommand-Rモデルの統合
RAGアプリケーションでCohereを使用する場合、Command-Rモデルは重要な機能です。このモデルは、外部データソースに接続して関連情報を取得することで、応答の関連性と精度を向上させます。この機能を使用することで、アプリケーションはより洞察に富み、文脈に適した回答を提供することができます。
# Hugging Faceの事前学習モデルへのアクセス
Hugging Faceの事前学習モデルをRAGアプリケーションに組み込むことは、効率と精度の面で大きな利点をもたらします。これらのモデルはさまざまなドメインで高品質な応答を生成するために幅広いデータセットでトレーニングされており、開発プロセスを迅速化しながら出力品質の高いレベルを維持することができます。
注意:
プロジェクトでHugging Faceモデルを利用するには、まずHugging Faceでアカウントを作成し、アクセストークン (opens new window)を取得してください。
# 環境のセットアップ
RAGアプリケーションの開発に取り組む前に、必要なツールとアカウントを準備してください。CohereやHugging Faceなどのプラットフォームにアクセスするためのアカウントが必要です。また、CohereのAPIやHugging Face Transformersなどの重要なライブラリをインストールすることも重要です。
pip install cohere transformers clickhouse-connect
このRAGアプリケーションでは、ベクトルデータベースとしてMyScaleDB (opens new window)を使用します。MyScaleDBはSQLベクトルデータベースであり、馴染みのあるSQL構文を使用してLLMの関連ドキュメントを効率的に取得します。500万件の無料ベクトルストレージを提供しており、コストなしでその機能を利用することができます。

# RAGアプリケーションの作成
CohereとHugging Faceを使用してRAGアプリケーションの基盤を築いたら、作成物をテストし、パフォーマンスを最適化するために微調整しましょう。
# データの読み込み
まず、langchain.document_loadersモジュールのTextLoaderを使用してデータを読み込みます。このチュートリアルでは、MicrosoftのWikiQAコーパス (opens new window)を使用します。
from langchain.document_loaders import TextLoader
loader = TextLoader('wikiQA-dev.txt', encoding='utf-8')
documents = loader.load()
text = documents[0].page_content
# テキストの分割
次に、CharacterTextSplitterを使用して読み込んだテキストをチャンクに分割します。これにより、大きなドキュメントを小さな管理しやすい部分に分割することができます。テキストの分割は、大規模なドキュメントの効率的な処理に必要であり、特定のセクションの処理と検索をより良く扱うことができます。
from langchain_text_splitters import CharacterTextSplitter
# テキストをチャンクに分割する
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=400,
chunk_overlap=100,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([text])
# 事前学習モデルとトークナイザの読み込み
Hugging Faceのsentence-transformers/all-MiniLM-L6-v2モデルを使用してテキストの埋め込みを生成します。トークナイザとモデルを読み込み、テキストの埋め込みを取得するための関数を定義します。埋め込みはテキストの意味を捉えた数値表現であり、類似性の検索や比較に重要です。
from transformers import AutoTokenizer, AutoModel
import torch
# 事前学習済みのトークナイザとモデルを読み込む
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
# テキストの埋め込みを取得する関数
def get_text_embeddings(text):
inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True)
with torch.no_grad():
embeddings = model(inputs).last_hidden_state.mean(dim=1)
return embeddings.numpy().flatten()
# テキストチャンクの埋め込みを生成する
各テキストチャンクに対して埋め込みを生成し、元のテキストとともにDataFrameに格納します。このステップにより、データを効果的に管理し、ストレージ中のデータを簡単に処理することができます。
import pandas as pd
# 各テキストチャンクに対して埋め込みを生成する
page_contents = []
embeddings_list = []
for segment in texts:
embeddings_list.append(get_text_embeddings(segment.page_content))
page_contents.append(segment.page_content)
df = pd.DataFrame({
'page_content': page_contents,
'embeddings': embeddings_list
})
# MyScaleDBに接続する
MyScaleDB (opens new window)データベースに接続して、埋め込みとテキストチャンクを保存します。MyScaleDBクラスタの認証情報を取得する手順 (opens new window)に従ってください。
import clickhouse_connect
# ClickHouseに接続する
client = clickhouse_connect.get_client(
host='your_host',
port=443,
username='your_user_name',
password='your_password'
)
# MyScaleDBテーブルの作成とデータの挿入
テキストチャンクと埋め込みを保存するためのテーブルをMyScaleに作成し、データをテーブルに挿入します。このステップにより、データベース内のデータが構造化され、効率的なクエリと検索が可能になります。
# テーブルを作成する
client.command("""
CREATE TABLE IF NOT EXISTS default.QnA (
id Int64,
page_content String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 384
) ENGINE = MergeTree() ORDER BY id
""")
# データをテーブルに挿入する
batch_size = 100
num_batches = (len(df) + batch_size - 1) // batch_size
for i in range(num_batches):
batch_data = df[i * batch_size: (i + 1) * batch_size]
client.insert('default.QnA', batch_data.values.tolist(), column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches} inserted.")
# テーブルにベクトルインデックスを追加する
ベクトルインデックスをテーブルに追加し、効率的な類似性検索を容易にします。ベクトルインデックスにより、埋め込みの高速な検索が可能となり、意味的なコンテンツに基づいて類似するドキュメントを見つけるために重要です。
# テーブルにベクトルインデックスを追加する
client.command("""
ALTER TABLE default.QnA
ADD VECTOR INDEX vector_index embeddings
TYPE MSTG
""")
# 関連するドキュメントを取得する
ユーザーのクエリに基づいて最も関連性の高いドキュメントを取得するための関数を定義します。この関数は、クエリの埋め込みと保存された埋め込みの間の距離を計算し、最も関連性の高いドキュメントを見つけます。
# 関連するドキュメントを取得する関数
def get_relevant_docs(user_query, top_k):
query_embeddings = get_text_embeddings(user_query).tolist()
results = client.query(f"""
SELECT page_content,
distance(embeddings, {query_embeddings}) as dist FROM default.QnA ORDER BY dist LIMIT {top_k}
""")
relevant_docs = []
doc_counter = 1
for row in results.named_results():
doc_key = f"doc{doc_counter}"
relevant_docs.append({doc_key: row['page_content']})
doc_counter += 1
return relevant_docs
# クエリの例
query = "How are epithelial tissues joined together?"
relevant_docs = get_relevant_docs(query, 8)
print(relevant_docs)
# Cohereを使用して応答を強化する
CohereのAPIを使用して、取得したドキュメントをクエリすることで応答を強化します。Cohereの言語モデルは、クエリと取得したドキュメントを処理してより包括的かつ正確な応答を生成します。このステップにより、高度な言語モデルのパワーが検索システムと統合されます。
import cohere
# Cohereに接続する
co = cohere.Client('your-cohere-client-api')
# Cohereを使用して関連するドキュメントをクエリする
response = co.chat(
model='command-r-plus',
message="How are epithelial tissues joined together?",
documents=relevant_docs
)
print(response.text)
# まとめと次のステップ
CohereとHugging Faceを使用したRAGアプリケーションの探求の旅を終えるにあたり、このプロセスで遭遇した課題と経験した成長について振り返ることが重要です。
RAGパイプライン (opens new window)の開発に取り組むことは、パフォーマンスの差異についての疑問や予期しない障害が生じる場合があります。しかし、CohereのCommand-RモデルやHugging Faceの事前学習モデルなどのツールを活用することで、開発者はこれらの課題を効果的に解決することができます。検索と生成の方法の統合には、最適な結果を得るための緻密な微調整が必要であり、これには忍耐力と戦略的な調整が必要です。
RAGシステムのパフォーマンスに直接影響を与えるもう一つの重要な要素は、ベクトルデータベースです。ベクトルデータベースは、データの迅速な取得とユーザーへの迅速な応答の実現において重要な役割を果たします。したがって、RAGシステムを設計する際には、適切なベクトルデータベースの選択が非常に重要です。
CohereとHugging Faceが提供する高度な機能により、開発者はRAGアプリケーションの効率とパフォーマンスの新たな次元を開拓することができます。検索メカニズムの最適化から生成プロセスのカスタマイズまで、これらのプラットフォームはアプリケーションの機能をさらに向上させるための多くのツールを提供しています。



