
大規模言語モデル(LLM)は、知識ベースからの検索結果を取り入れることで、真実の回答においてより信頼性が高まることがあります。これをRetrieval Augmented Generation(RAG)と呼びます。以前のブログ記事では、RAGのパフォーマンス向上 (opens new window)とコストとレイテンシーの実現可能性 (opens new window)について説明しました。このブログでは、マイスケールを使用したRetrieval Augmented Generationを使用したチャットボットの高度な使用法を紹介します。私たちのHuggingFaceスペース (opens new window)でも試すことができます。
注意:
マイスケールのHuggingFaceスペース (opens new window)を訪れて、チャットボットを試してみてください。
![]()
チャットボットは、単一の質問と回答のタスクとは異なります。以下にその違いを示します。
単一の質問応答タスク:
単一の質問応答タスクでは、ユーザーとシステムの間のやり取りは通常、ユーザーからの単一の質問とシステムからの明確な回答で構成されます。これらは質問応答ペアとして知られています。
チャットボット:
しかし、チャットボットとユーザーの間の会話はより複雑で、複数のターンにわたる議論が行われます。チャットボットは継続的な対話や追加の質問に対応し、複数のやり取りを通じて会話の文脈を追いかけることができます。
これを実現するために、チャットボットはユーザーの完全なチャット履歴を保存する必要があります。これには、以前の会話や最後の関数呼び出しのアクション(または結果)を含むユーザーの以前の会話全体が含まれます。さらに、チャットボットのメモリは、異なるユーザーを同時に処理し、それらの会話を互いに分離して保存できる必要があります。これは、正しく設定されていない場合には大きな課題となる可能性があります。幸いなことに、マイスケールは、SQL互換性とロールベースのアクセス制御 (opens new window)機能を介して、数百万人のユーザーのチャット履歴を簡単に管理できる完璧なソリューションを提供しています。
チャットボットもRAGの恩恵を受けることができますが、すべてのチャットでRAGが必要とされるわけではありません。たとえば、ユーザーがある言語から別の言語への翻訳を求める場合、RAGを組み合わせてもこの要求に価値を追加することはありません。そのため、チャットボットがどのようにして、どこでRAGを使用するかを決定する必要があります。
これをどのように実現するのでしょうか?
幸いなことに、OpenAIには、外部関数呼び出しとしてマイスケールを使用するための関数呼び出しAPI (opens new window)があります。
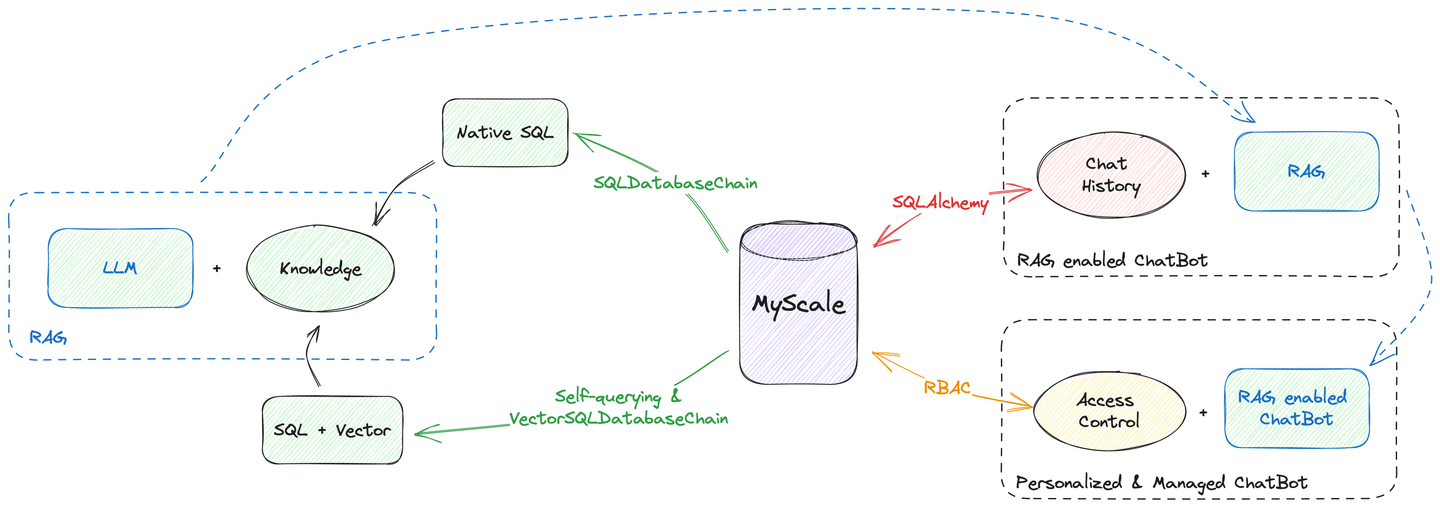
さらに、マイスケールはベクトル検索からチャット履歴の管理まで、すべてのデータホスティングの作業を行うことができます。上記の図に示されているように、マイスケールを唯一のデータソースとして使用してチャットボットを構築することができます。データが異なるデータベースやエンジンに分散していることを心配する必要はありません。
それでは、どのようにしてそれを実現するのでしょうか。
# ツールとしてのリトリーバー
RAGは、外部関数として表現することができます。OpenAIの関数呼び出しドキュメント (opens new window)を参照して、MyScaleベクトルストアをツールとして使用するためのプロンプトの作成方法について詳しく説明します。
今回は、ベクトルストアではなく、LangChainのリトリーバーAPIを使用して、MyScaleの高度なフィルタ検索を使用してクエリを拡張します。以前に、自己クエリリトリーバー (opens new window)がフィルタを使用したベクトル検索クエリに翻訳する方法を紹介しました。また、ベクトルSQLデータベースチェーンから構築されたリトリーバー (opens new window)は、自己クエリリトリーバーと同じことをSQLインターフェースで行います。
注意:
これらの2つのリトリーバーは、クエリテキストのみを入力として受け取るため、チャットボットツールへの変換は簡単です。
実際には、リトリーバーをツールに変換するには、わずか数行のコードが必要です。
from langchain.agents.agent_toolkits import create_retriever_tool
retriever = ... # 自己クエリリトリーバー / ベクトルSQLデータベースリトリーバー
# 適切な説明を持つツールを作成します。Wikipediaの検索を例に挙げます:
tool = create_retriever_tool(retriever,
"search_among_wikipedia",
"Wikipedia内を検索し、関連するウィキページを返します")
# ツールセットを作成します
tools = [tool]
したがって、複数のツールを作成し、それらを単一のチャットボットに組み込むことができます。たとえば、検索する複数の知識ベースがある場合、各知識ベースに対してツールを開発し、チャットボットがどのツールを使用するかを決定させることができます。
# チャットの記憶
チャットの記憶は、チャットボットにとって重要です。複数のツールを提供するだけでなく、これらのツールからの中間結果を保存するためのメモリも提供する必要があります。これには、豊富なデータ型と高度なマルテナンシーサポートが必要ですが、マイスケールはこれに優れています。
以下のPythonスクリプトは、チャットボットのためのメモリを作成する方法を示しています。
from langchain.memory import SQLChatMessageHistory
from langchain.memory.chat_message_histories.sql import BaseMessageConverter, DefaultMessageConverter
from langchain.agents.openai_functions_agent.agent_token_buffer_memory import AgentTokenBufferMemory
# マイスケールの認証情報
MYSCALE_USER = ...
MYSCALE_PASSWORD = ...
MYSCALE_HOST = ...
MYSCALE_PORT = ...
database = 'chat'
# マイスケールは`clickhouse-sqlalchemy`パッケージを介してSQLAlchemyをサポートしています
conn_str = f'clickhouse://{MYSCALE_USER}:{MYSCALE_PASSWORD}@{MYSCALE_HOST}:{MYSCALE_PORT}'
# LangChainは、SQLデータベースをチャット履歴のバックエンドとして使用するためのネイティブサポートを提供しています
chat_memory = SQLChatMessageHistory(
# セッションIDはユーザー固有である必要があり、セッションを分離します
session_id,
# マイスケールSaaSはHTTPS接続を使用しています
connection_string=f'{conn_str}/{database}?protocol=https',
# ここではメッセージコンバータとテーブルスキーマをカスタマイズしています
custom_message_converter=DefaultClickhouseMessageConverter(name))
# AgentTokenBufferMemoryを使用して、ユーザー、ボット、ツールからのすべての中間メッセージを保存します
memory = AgentTokenBufferMemory(llm=llm, chat_memory=chat_memory)
マイスケールはリレーショナルデータベースとしても機能します。そして、LangChainのSQLChatMessageHistoryを介して、clickhouse-sqlalchemyを使用してメモリのバックエンドとしてマイスケールを使用することができます。データベースにより、より多くの情報をデータベースに保存するためにカスタマイズされたメッセージコンバータが必要です。
メモリのテーブルスキーマを定義する方法は次のとおりです。
import time
import json
import hashlib
from sqlalchemy import Column, Text
try:
from sqlalchemy.orm import declarative_base
except ImportError:
from sqlalchemy.ext.declarative import declarative_base
from clickhouse_sqlalchemy import types, engines
from langchain.schema.messages import BaseMessage, _message_to_dict, messages_from_dict
def create_message_model(table_name, DynamicBase): # type: ignore
# テーブル名を動的に指定するために関数内でモデルを宣言します
class Message(DynamicBase):
__tablename__ = table_name
# SQLChatMessageHistoryはメッセージをIDで並べ替えます
# そのため、ここではタイムスタンプをIDとして保存します
id = Column(types.Float64)
# セッションIDはセッションを分離するためのものです
session_id = Column(Text)
# メッセージの実際の主キーです
msg_id = Column(Text, primary_key=True)
# メッセージのタイプ、HumanMessage / AIMessageなどがあります
type = Column(Text)
# JSON文字列での追加のメッセージ
addtionals = Column(Text)
# テキスト形式のメッセージ
message = Column(Text)
__table_args__ = (
# ReplacingMergeTreeは主キーに基づいて重複を排除します
engines.ReplacingMergeTree(
partition_by='session_id',
order_by=('id', 'msg_id')),
{'comment': 'チャット履歴の保存'}
)
return Message
class DefaultClickhouseMessageConverter(DefaultMessageConverter):
"""SQLChatMessageHistory用のClickHouseメッセージコンバータ。"""
def __init__(self, table_name: str):
# チャットメモリのためのテーブルスキーマを作成します
self.model_class = create_message_model(table_name, declarative_base())
def to_sql_model(self, message: BaseMessage, session_id: str) -> Any:
tstamp = time.time()
msg_id = hashlib.sha256(f"{session_id}_{message}_{tstamp}".encode('utf-8')).hexdigest()
# 空欄を埋めます
return self.model_class(
id=tstamp,
msg_id=msg_id,
session_id=session_id,
type=message.type,
addtionals=json.dumps(message.additional_kwargs),
message=json.dumps({
"type": message.type,
"additional_kwargs": {"timestamp": tstamp},
"data": message.dict()})
)
def from_sql_model(self, sql_message: Any) -> BaseMessage:
# 検索された履歴をメッセージオブジェクトに変換します
msg_dump = json.loads(sql_message.message)
msg = messages_from_dict([msg_dump])[0]
msg.additional_kwargs = msg_dump["additional_kwargs"]
return msg
これで、マイスケールをバックエンドとする完全に機能するチャットメモリができました。おめでとうございます!
# チャットメモリの管理
ユーザーの会話履歴は貴重な資産であり、安全に保管する必要があります。LangChainのチャットメモリは既にsession_idによるセッションの分離 (opens new window)を制御しています。
何百万人ものユーザーがチャットボットと対話する可能性があるため、メモリの管理は課題となることがあります。幸いなことに、これらのすべてのユーザーのチャット履歴を管理するためのいくつかの「トリック」があります。
マイスケールは、ユーザーごとに異なるテーブル、パーティション、または主キーを作成することでデータの分離をサポートしています。データベースに多数のテーブルを作成するとシステムが過負荷になるため、メタデータフィルタリング指向のマルテナンシー戦略 (opens new window)を採用することをお勧めします。具体的には、ユーザーごとにパーティションを作成するか、主キーを使用して順序付けすることができます。これにより、データベースからの高速な検索が可能になり、検索と保存よりも効率的です。
このシナリオでは、主キーを使用したソリューションをお勧めします。session_idを主キーのリストに追加することで、特定のユーザーのチャット履歴を取得する際の速度が向上します。
# SQLAlchemyモデルを変更します
def create_message_model(table_name, DynamicBase): # type: ignore
class Message(DynamicBase):
__tablename__ = table_name
id = Column(types.Float64)
session_id = Column(Text, primary_key=True)
msg_id = Column(Text, primary_key=True)
type = Column(Text)
addtionals = Column(Text)
message = Column(Text)
__table_args__ = (
engines.ReplacingMergeTree(
# ||| これにより、1,000のセッションごとにパーティションが作成されます
# vvv (多すぎるパーティションはシステムを遅くします)
partition_by='sipHash64(session_id) % 1000',
# ここではセッションIDとメッセージIDで並べ替えています
# これにより、検索が高速化されます
order_by=('session_id', 'msg_id')),
{'comment': 'チャット履歴の保存'}
)
return Message
注意:
マルテナンシー戦略 (opens new window)について詳しく学びたい場合は、ドキュメントを参照してください。
# それらを組み合わせる
これで、RAGを使用したチャットボットを構築するために必要なすべてのコンポーネントが揃いました。次のコードスニペットに示すように、それらを組み合わせましょう。
from langchain.agents import AgentExecutor
from langchain.schema import SystemMessage
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import MessagesPlaceholder
from langchain.agents.openai_functions_agent.base import OpenAIFunctionsAgent
# OpenAI LLMの初期化
chat_model_name = "gpt-3.5-turbo"
OPENAI_API_BASE = ...
OPENAI_API_KEY = ...
# LLMを作成する
chat_llm = ChatOpenAI(model_name=chat_model_name, temperature=0.6, openai_api_base=OPENAI_API_BASE, openai_api_key=OPENAI_API_KEY)
# チャットボットが検索機能を使用するようにするためのプロンプトの開始
_system_message = SystemMessage(
content=(
"質問に最善の回答をしてください。"
"関連情報を検索するために利用可能なツールを自由に使用してください。"
"検索関数を呼び出す際に、クエリのすべての詳細を保持してください。"
)
)
# 関数呼び出しのプロンプトを作成します
prompt = OpenAIFunctionsAgent.create_prompt(
system_message=_system_message,
# ここにデータベースからのチャット履歴を配置します
extra_prompt_messages=[MessagesPlaceholde(variable_name="history")],
)
# OpenAI関数エージェントを使用します
agent = OpenAIFunctionsAgent(llm=chat_llm, tools=tools, prompt=prompt)
# すべてのコンポーネントを組み合わせます
executor = AgentExecutor(
agent=agent,
tools=tools,
memory=memory,
verbose=True,
# これらのすべての中間ステップをデータベースに保存するため、必要です
return_intermediate_steps=True,
)
これで、RAG対応のチャットボットとAgentExecutorが完成しました。簡単なコードでチャットボットと対話することができます。
response = executor({"input": "こんにちは!"})
注意: すべてのチャット履歴はexecutor.memory.chat_memory.messagesの下に保存されます。メモリからメッセージをレンダリングするための参照が必要な場合は、GitHub上の実装 (opens new window)を参照してください。

# まとめ
マイスケールは高性能なベクトル検索を得意とし、SQLデータベースが提供するすべての機能を備えています。ベクトルデータベースとSQLデータベースの両方として使用することができます。さらに、アクセス制御などの高度な機能を備えており、ユーザーやアプリの管理が容易です。
このブログでは、マイスケールを使用してチャットボットを構築する方法を紹介しました。単一のデータベースとチャットボットを統合することで、データの整合性、セキュリティ、一貫性を確保することができます。また、レコードへの参照を保存することでデータの冗長性を減らし、データアクセスと共有を改善することができます。これにより、信頼性と品質が大幅に向上し、ビジネスのニーズに応じてスケーリング可能なモダンなサービスとなるチャットボットを実現することができます。
HuggingFace (opens new window)でチャットボットを試してみるか、GitHub (opens new window)からコードを実行してみてください!また、Twitter (opens new window)やDiscord (opens new window)でご意見を共有してください。
# 参考文献:
- https://myscale.com/blog/ja/teach-your-llm-vector-sql/ (opens new window)
- https://myscale.com/docs/ja/advanced-applications/chatdata/ (opens new window)
- https://myscale.com/docs/ja/sample-applications/openai-function-call/ (opens new window)
- https://python.langchain.com/docs/modules/memory/ (opens new window)
- https://python.langchain.com/docs/integrations/memory/sql_chat_message_history (opens new window)
- https://python.langchain.com/docs/use_cases/chatbots (opens new window)
- https://python.langchain.com/docs/use_cases/question_answering/how_to/conversational_retrieval_agents (opens new window)



