
機械学習の世界では、かつてはモデルには1つのデータタイプしか処理できない制限がありました。しかし、機械学習の究極の目標は、さまざまなデータモダリティを同時に容易に理解する人間の知的能力に匹敵することです。GPT-4Vなどのモデルによって示される最近のブレークスルーにより、複数のデータモダリティを同時に処理する驚異的な能力が実証されました。これにより、開発者はさまざまなタイプのデータをシームレスに管理できるAIアプリケーションを作成する可能性が広がりました。これがマルチモーダルアプリケーションとして知られています。
非常に人気のある魅力的なユースケースの1つは、マルチモーダル画像検索です。これにより、ユーザーは特徴や視覚的なコンテンツを分析して類似の画像を見つけることができます。コンピュータビジョンとディープラーニングの急速な進歩のおかげで、画像検索は非常に強力になりました。
この記事では、Hugging Faceライブラリのモデルを使用してマルチモーダル画像検索アプリケーションを構築します。実際の実装に入る前に、基本的な内容を確認して準備を整えましょう。
# マルチモーダルシステムとは?
マルチモーダルシステムとは、複数のモードの相互作用やコミュニケーションを使用できるシステムを指します。つまり、テキスト、画像、音声、そして時にはタッチやジェスチャーなど、さまざまな種類の入力を同時に処理し理解することができるシステムであり、さまざまな方法で結果を返すこともできます。
例えば、OpenAIが開発したGPT-4V (opens new window)は、テキストと画像の複数の「モダリティ」を同時に処理できる高度なマルチモーダルモデルです。画像と説明的なクエリが提供されると、モデルは提供されたテキストに基づいて視覚的なコンテンツを分析することができます。
# マルチモーダル埋め込みとは?
マルチモーダル埋め込みは、画像、テキスト、音声などの複数のモダリティをベクトル形式で数値表現する高度な機械学習技術のことです。基本的な埋め込み技術とは異なり、ベクトル空間内で単一のデータタイプのみを表現するのではなく、マルチモーダル埋め込みは統一されたベクトル空間内でさまざまなデータタイプを表現することができます。これにより、テキストの説明と対応する画像の相関関係を示すことができます。マルチモーダル埋め込みのおかげで、システムは画像を分析し、関連するテキストの説明と関連付けることができるか、その逆も可能です。
それでは、このプロジェクトの開発方法と使用する技術について説明しましょう。
# ツールと技術
このプロジェクトでは、CLIP (opens new window)、MyScale (opens new window)、およびUnsplash-25kデータセット (opens new window)を使用します。それぞれ詳しく見ていきましょう。
- CLIP: Hugging Faceから提供される事前学習済みのマルチモーダルCLIP (opens new window)を使用します。このモデルはテキストと画像を統合するために使用されます。
- MyScale: MyScaleは、構造化および非構造化データを最適化された方法で格納および処理するために使用されるSQLベクトルデータベースです。MyScaleを使用してベクトル埋め込みを格納し、関連する画像をクエリするために使用します。
- Unsplash-25kデータセット: Unsplashが提供するデータセットには約2万5千枚の画像が含まれています。複雑なシーンやオブジェクトも含まれています。
# Hugging FaceとMyScaleのセットアップ方法
Hugging FaceとMyScaleをローカル環境で使用するには、いくつかのPythonパッケージをインストールする必要があります。ターミナルを開き、次のpipコマンドを入力してください。
pip install datasets clickhouse-connect requests transformers torch tqdm
インストールが完了したら、以下のコマンドをターミナルに入力して確認できます。
pip freeze | egrep '(datasets|clickhouse-connect|requests|transformers|torch|tqdm)'
新しくインストールされた依存関係とバージョンが表示されます。
# データセットのダウンロードと読み込み
最初のステップは、データセットをダウンロードしてローカルに展開することです。次のコマンドをターミナルに入力して行います。
# Download the dataset
wget https://unsplash-datasets.s3.amazonaws.com/lite/latest/unsplash-research-dataset-lite-latest.zip
# unzip the downloaded files into a temporary directory
unzip unsplash-research-dataset-lite-latest.zip -d tmp
抽出されたファイルから必要なデータをPythonのデータフレームに読み込みましょう。
# Import pandas
import pandas as pd
# Load the photos file from the directory
df_photos = pd.read_csv("tmp/photos.tsv", sep='\t', header=0)
df_photos
ディレクトリからphotosファイルを読み込んでいます。このファイルにはデータセット内の写真に関する情報が含まれています。写真のプロフィールは以下のようになります。
| photo_id | photo_url | photo_image_url |
|---|---|---|
| xapxF7PcOzU | https://unsplash.com/photos/wud-eV6Vpwo | https://images.unsplash.com/photo-143924685475... |
| psIMdj26lgw | https://unsplash.com/photos/psIMdj26lgw | https://images.unsplash.com/photo-144077331099... |
photo_urlとphoto_image_urlの違いは、photo_urlが画像の説明ページのURLであり、写真の作者やその他のメタ情報を伝えるものであるのに対し、photo_image_urlは画像のURLのみを含んでおり、画像をダウンロードするために使用します。
# モデルの読み込みと埋め込みの取得
データセットを読み込んだ後、まずclip-vit-base-patch32 (opens new window)モデルを読み込み、画像をベクトル埋め込みに変換するためのPython関数を作成しましょう。この関数では、CLIPモデルを使用して埋め込みを表現します。
# Import pytorch
import torch
# Import transformers to load the model and processor from Hugging Face
from transformers import CLIPProcessor, CLIPModel
# Load the CLIP model from Hugging Face
model = CLIPModel.from_pretrained('openai/clip-vit-base-patch32')
# Load the processor used to pre-process the images and make them compatible with the model
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# Define the method
def create_embeddings(image=None, text=None):
# Initialize embeddings
image_embeddings = None
text_embeddings = None
# Process the image if provided
if image is not None:
image_embeddings = extract_image_features(image)
image_embeddings = torch.tensor(image_embeddings)
image_embeddings = image_embeddings / image_embeddings.norm(dim=-1, keepdim=True)
# Process the text if provided
if text is not None:
text_inputs = processor(text=[text], return_tensors="pt", padding=True)
with torch.no_grad():
text_outputs = model.get_text_features(**text_inputs)
text_embeddings = text_outputs / text_outputs.norm(dim=-1, keepdim=True)
text_embeddings = text_embeddings.squeeze(0).tolist()
# Combine the embeddings if both image and text are provided, and normalize
if image_embeddings is not None and text_embeddings is not None:
combined_embeddings = (image_embeddings + torch.tensor(text_embeddings)) / 2
combined_embeddings = combined_embeddings / combined_embeddings.norm(dim=-1, keepdim=True)
return combined_embeddings.tolist()
# Return only image or text embeddings if one of them is provided
return image_embeddings.tolist() if text_embeddings is None else text_embeddings
以下のコードは、テキストと画像の両方の入力を処理し、それぞれ個別にまたは同時に対応する埋め込みを返すように設計されています。それらがどのように機能するかを見てみましょう:
- もし画像とテキストの両方を提供する場合、コードは両方の埋め込みを組み合わせた単一のベクトルを返します。
- もしテキストまたは画像のいずれかを提供する場合(両方ではない場合)、コードは単に提供されたテキストまたは画像の埋め込みを返します。
ノート
我々は単にマルチモーダルの概念に焦点を当てるために、2つの埋め込みを結合する基本的な方法を使用しています。しかし、結合や注意メカニズムのような、より良い埋め込みを結合する方法がいくつかあります。
上記のcreate_embeddings関数にデータセットから最初の1000枚の画像をロードし、ダウンロードし、渡します。返された埋め込みは、新しい列 photo_embed に保存されます。
# Import the Image moduke for image processing
from PIL import Image
# Import the requests module for making HTTP requests
import requests
# Import tqdm for processing bar visualization
from tqdm.auto import tqdm
# Get the first 1000 images
photo_ids = df_photos['photo_id'][:1000]
# Filter the DataFrame to get the required columns
df_photos = df_photos.loc[photo_ids.index, ['photo_id', 'photo_image_url']]
# Create a session to make HTTP requests
session = requests.Session()
# Define the Python function to download and get embeddings
def process_image(url):
try:
# Make a GET request to download the image
response = session.get(url, stream=True)
response.raise_for_status()
image = Image.open(response.raw)
# Get the embeddings and return
return create_embeddings(image)
except requests.RequestException:
return None
# construct a URL to download the image with a smaller size
df_photos['photo_image_url'] = df_photos['photo_image_url'].apply(lambda x: x + "?q=75&fm=jpg&w=200&fit=max")
# Pass the images one by one to the 'process_image' and save the embeddings to the newly created column 'photo_embed'
df_photos['photo_embed'] = [process_image(url) for url in tqdm(df_photos['photo_image_url'], total=len(df_photos))]
# Remove rows where image processing failed
df_photos.dropna(subset=['photo_embed'], inplace=True)
# Reset the index and rename the 'id' column to 'index'
df_photos = df_photos[df_photos['photo_id'].isin(photo_ids)].reset_index().rename(columns={'index': 'id'})
# Close the session
session.close()
ノート
このプロセスには時間がかかることがあり、また、インターネットの速度にも依存します。
このプロセスが完了したら、データセットが完成します。次のステップは、新しいテーブルを作成し、データをMyScaleに保存することです。
# MyScaleとの接続
アプリケーションをMyScaleに接続するには、セットアップと構成のためにいくつかの手順を完了する必要があります。
- アカウントの作成: まず、MyScale (opens new window)でアカウントを作成してください。
- クラスタの作成: 次に、クラスタを作成する必要があります。そのためには、MyScaleが提供する"クラスタの作成 (opens new window)"のドキュメンテーションを参照して、詳細な手順を確認してください。
- 接続詳細の取得: クラスタが設定されたら、次のステップは、アプリケーションとMyScaleクラスタの間の接続を確立するために接続詳細を取得 (opens new window)することです。
接続詳細を取得したら、以下のコード内の値を置き換えることができます:
import clickhouse_connect
client = clickhouse_connect.get_client(
host='ホストのアドレス',
port=443,
username='ユーザー名',
password='パスワード'
)
# テーブルの作成
接続が確立されたら、次のステップはテーブルの作成です。まず、次のコマンドでデータフレームを確認しましょう。
df_photos
データフレームは以下のようになります:
| photo_id | photo_image_url | photo_embed |
|---|---|---|
| wud-eV6Vpwo | https://images.unsplash.com/uploads/1411949294... | [0.0028754104860126972, 0.02760922536253929, 0... |
| psIMdj26lgw | https://images.unsplash.com/photo-141633941111... | [0.019032524898648262, -0.04198262840509415, 0... |
| 2EDjes2hlZo | https://images.unsplash.com/photo-142014251503... | [-0.015412664040923119, 0.01923416182398796, 0... |
データフレームに基づいてテーブルを作成しましょう。
# Check if a table with the same name exists or not. If exists, drop that table
client.command("DROP TABLE IF EXISTS default.myscale_photos")
# create a table for photos
client.command("""
CREATE TABLE default.myscale_photos
(
id UInt64,
photo_id String,
photo_image_url String,
photo_embed Array(Float32),
CONSTRAINT vector_len CHECK length(photo_embed) = 512
)
ORDER BY id
""")
上記のコマンドは、MyScaleクラスターにテーブルを作成します。
# データの挿入
新しく作成したテーブルにデータを挿入しましょう:
# upload data from datasets
client.insert("default.myscale_photos", df_photos.to_records(index=False).tolist(),
column_names=df_photos.columns.tolist())
# check count of inserted data
print(f"photos count: {client.command('SELECT count(*) FROM default.myscale_photos')}")
# create vector index with cosine
client.command("""
ALTER TABLE default.myscale_photos
ADD VECTOR INDEX photo_embed_index photo_embed
TYPE MSTG
('metric_type=Cosine')
""")
# check the status of the vector index, make sure vector index is ready with 'Built' status
get_index_status="SELECT status FROM system.vector_indices WHERE name='photo_embed_index'"
print(f"index build status: {client.command(get_index_status)}")
上記のコードは、データをテーブルに挿入し、MSTGアルゴリズムを使用してインデックスを作成します。インデックスは、テーブルからデータを高速に取得するために作成されます。最後のコマンドは、インデックスが正常に作成されたかどうかを確認するために使用されます。成功した場合、"index build status: Built"と表示されます。
注意:
MSTGアルゴリズムはMyScaleによって作成されたものであり、IVFやHNSWなどの他のインデックスアルゴリズムよりも高速です。

# MyScaleのクエリ方法
データが挿入されたら、MyScaleを利用してデータをクエリし、マルチモーダルを使用して画像を取得する準備が整いました。まず、テーブルからランダムな画像を取得してみましょう。
import requests
import matplotlib.pyplot as plt
from PIL import Image
from io import BytesIO
# download image with its url
def download(url):
response = requests.get(url)
return Image.open(BytesIO(response.content))
def show_image(url, title=None):
img = download(url)
fig = plt.figure(figsize=(4, 4))
plt.imshow(img)
plt.show()
random_image = client.query("SELECT * FROM default.myscale_photos ORDER BY rand() LIMIT 1")
target_image_url = random_image.first_item["photo_image_url"]
print("ターゲット画像を読み込んでいます...")
show_image(target_image_url)
上記のコードは、テーブルからランダムに画像を検索し、それをコードエディタに表示するはずです。
# テキストと画像を使用して関連する画像を取得する方法
学んだように、マルチモーダルモデルは複数のデータモダリティを同時に処理することができます。同様に、私たちのモデルは画像とテキストの両方を同時に処理し、関連する画像を提供することができます。以下のテキストと一緒に次の画像を提供します:「ビーチに立つ男性」。

画像のURLとテキストをcreate_embeddings関数に渡しましょう。
image_url="https://images.unsplash.com/photo-1701443478334-c1a4bfda91ff?q=80&w=1936&auto=format&fit=crop&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D"
query_text="ビーチに立つ男性"
embeddings=create_embeddings(download(url),query_text)
次のステップは、データセットからtop_k個の関連する結果を取得するためのクエリを書くことです。
top_k = 5
# Query to get the relevant results from the database
results = client.query(f"""
SELECT photo_id, photo_image_url, distance(photo_embed, {embeddings}) as dist
FROM default.myscale_photos
ORDER BY dist ASC
LIMIT {top_k}
""")
# Download the relevant images
images_url = []
for r in results.named_results():
# construct a URL to download an image with a smaller size by modifying the image URL
url = r['photo_image_url'] + "?q=75&fm=jpg&w=200&fit=max"
images_url.append(download(url))
# display the images
print("Loading candidate images...")
for row in range(int(top_k / 5)):
fig, axs = plt.subplots(1, 5, figsize=(20, 4))
for i, img in enumerate(images_url[row * 5:row * 5 + 5]):
axs[i % 5].imshow(img)
plt.show()
注意:
distance関数は、クエリベクトルとすべての関連ベクトルのユークリッド距離を求めます。
上記のコードは、次のような結果を生成します。
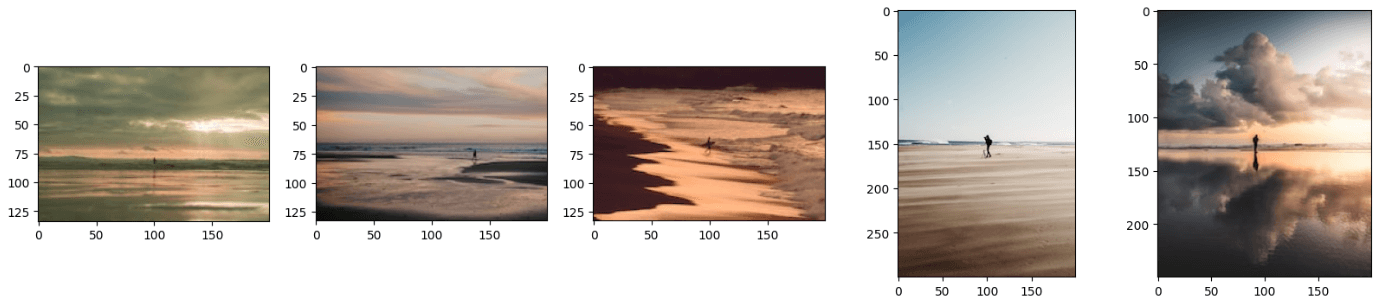
注意:
埋め込みをマージするためのより良いテクニックを使用して結果をさらに改善することができます。
結果の画像は、テキストと画像の組み合わせのように見えることに気付いたかもしれません。このモデルには、画像またはテキストのどちらかを提供しても結果を得ることができます。そのためには、コードのimage_urlまたはquery_textの行をコメントアウトするだけです。
# 結論
従来のモデルは、単一のデータタイプのベクトル表現を取得するために使用されていましたが、最新のモデルはより多くのデータでトレーニングされ、さまざまなタイプのデータを統一されたベクトル空間で表現することができるようになりました。私たちは最新のモデルであるCLIPの機能を利用して、テキストと画像の両方を入力として受け取り、関連する画像を返すアプリケーションを開発しました。
マルチモーダル埋め込みの機能は、画像検索アプリケーションに限定されるものではありません。これを使って最先端のレコメンデーションシステムや、ユーザーが画像に関連する質問をすることができるビジュアルクエスチョンアンサリングアプリケーションなど、さまざまなアプリケーションを開発することができます。これらのアプリケーションを開発する際には、超高速なデータ検索機能を備えた統合SQLベクトルデータベースであるMyScale (opens new window)を使用することを検討してください。
画像検索アプリを開発している場合は、MyScaleのDiscord (opens new window)でアイデアやフィードバックを交換してください。




