
検索補完生成 (opens new window)(RAG)は、自然言語処理(NLP)の領域での重要なブレークスルーであり、特にAIアプリケーションの開発において重要な役割を果たしています。RAGは、大規模な知識ベース (opens new window)と大規模言語モデル (opens new window)(LLM)の言語能力を組み合わせ、データの検索能力を備えています。リアルタイムで情報を検索して使用する能力により、AIとの対話がより本格的で情報に基づいたものになります。
RAGは、ユーザーがAIと対話する方法を明らかに改善しました。例えば、LLMを活用したチャットボット (opens new window)は、既に複雑な質問に対応し、個々のユーザーに合わせた応答を提供することができます。RAGアプリケーションは、トレーニングデータだけでなく、対話中に最新の情報を検索して使用することで、これをさらに向上させます。
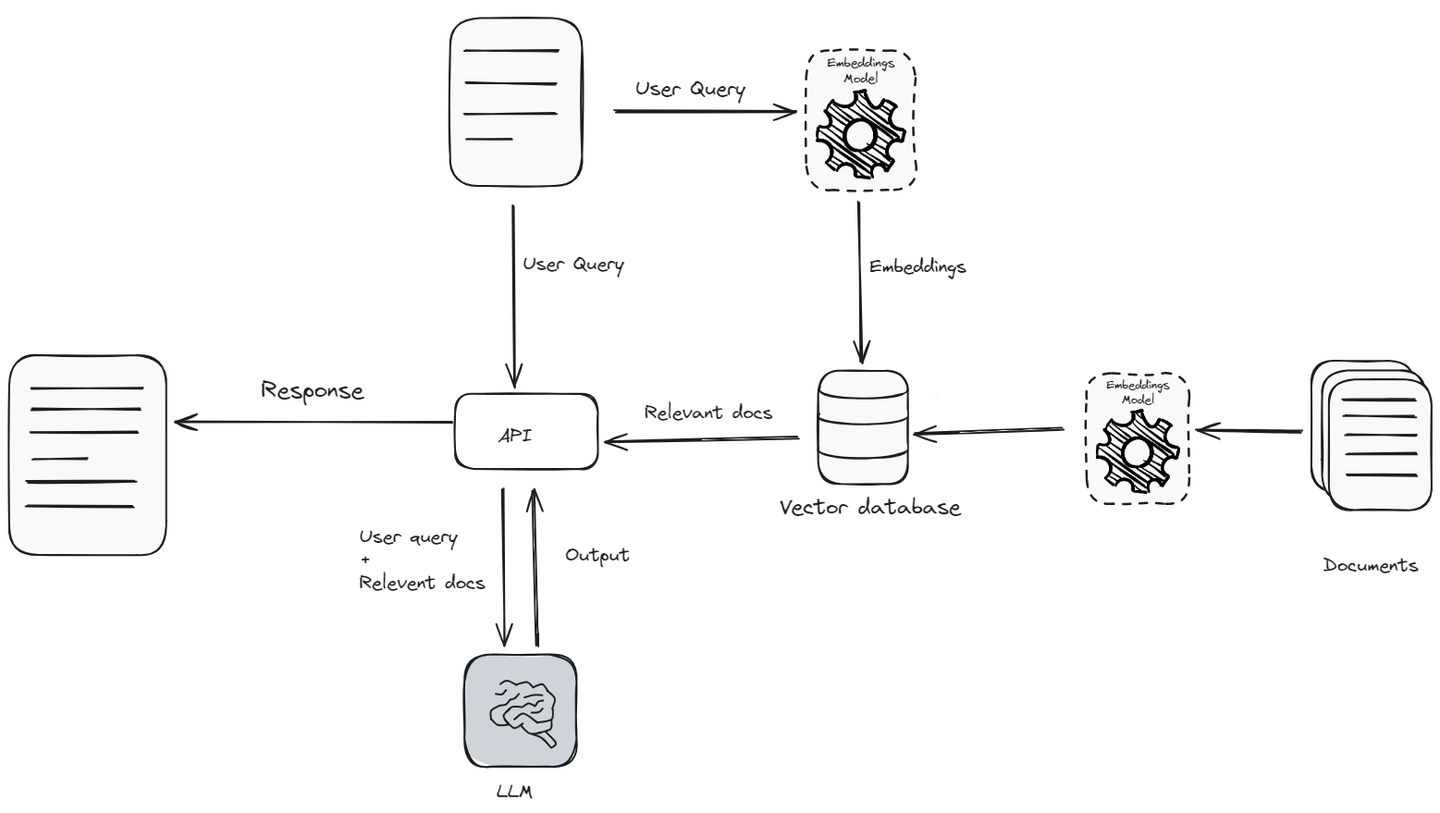
しかし、RAGアプリケーションは、小規模なスケールで使用する場合は非常にうまく機能しますが、スケーリングしようとすると、APIとデータストレージのコストの管理、レイテンシの削減とスループットの向上、大規模な知識ベースを効率的に検索すること、ユーザープライバシーの確保など、重要な課題が生じます。
このブログでは、RAGアプリケーションのスケーリング時に遭遇するさまざまな課題と、それらに対処するための効果的な解決策について探求します。
# コストの管理:データストレージとAPIの使用
RAGアプリケーションを拡大する上で最も大きなハードルの一つは、特にOpenAI (opens new window)やGemini (opens new window)などの大規模言語モデル(LLM)のAPIに依存しているため、コストの管理です。RAGアプリケーションを構築する際には、次の3つの主要なコスト要素を考慮する必要があります。
- LLM API
- 埋め込みモデルAPI
- ベクトルデータベース
これらのAPIのコストは高くなります。サービスプロバイダーが計算コストやトレーニングなどをすべて管理しているためです。このセットアップは、小規模なプロジェクトでは持続可能かもしれませんが、アプリケーションの使用量が増えるにつれて、コストは大きな負担となる可能性があります。
例えば、RAGアプリケーションでgpt-4を使用し、1日あたり1000万の入力トークンと300万の出力トークンを処理する場合、1日あたり約480ドルのコストがかかる可能性があります。これは、どのアプリケーションを実行するにしてもかなりの金額です。同時に、ベクトルデータベースも定期的な更新が必要であり、データが増えるにつれてスケーリングする必要があり、コストがさらに増えます。
# コスト削減の戦略
先述のように、RAGアーキテクチャの特定のコンポーネントは非常に高価です。これらのコンポーネントのコストを削減するためのいくつかの戦略について説明しましょう。
- LLMと埋め込みモデルの微調整: LLM APIと埋め込みモデルに関連するコストを最小限に抑えるためには、最も効果的なアプローチは、オープンソースのLLM (opens new window)と埋め込みモデルを選び、それらを自分のデータで微調整することです。ただし、これには多くのデータ、技術的な専門知識、計算リソースが必要です。
- キャッシュ: キャッシュ (opens new window)を使用してLLMからの応答を保存することで、API呼び出しのコストを削減し、アプリケーションをより高速かつ効率的にすることができます。応答がキャッシュに保存されると、必要な場合にはLLMに再度問い合わせることなく、すばやく取得することができます。キャッシュの使用により、API呼び出しのコストを最大10%削減することができます。langchainのさまざまなcaching techniques (opens new window)を使用することができます。
- 簡潔な入力プロンプト: 入力プロンプトを洗練させて短くすることで、必要な入力トークンの数を減らすことができます。これにより、モデルがユーザーのクエリをより良く理解できるだけでなく、使用されるトークン数も減少し、コストが低下します。
- 出力トークンの制限: 出力トークンの数を制限することで、モデルが不必要に長い応答を生成するのを防ぎ、関連する情報を提供しながらコストを制御することができます。
# ベクトルデータベースのコスト削減
ベクトルデータベースは、RAGアプリケーションにおいて重要な役割を果たします。また、入力するデータの種類も同様に重要です。よく言われるように、「ゴミを入れればゴミが出る」ということです。
- 前処理: データの前処理の目的は、テキストの標準化と一貫性を実現することです。テキストの標準化により、関係のない詳細や特殊文字が削除され、データがコンテキスト豊かで一貫性のあるものになります。明確さ、コンテキスト、正確さに重点を置くことで、システムの効率が向上し、データのボリュームが減少します。データのボリュームが減少することで、ストレージコストが低下し、データの検索効率が向上します。
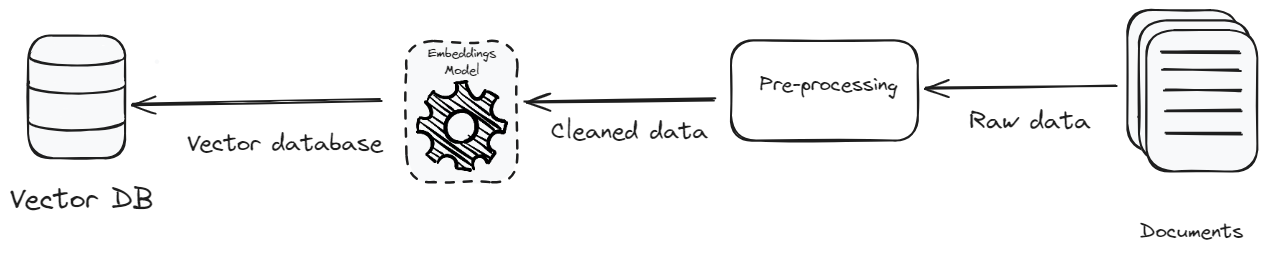
- コスト効率の高いベクトルデータベース: コストを削減するための別の方法は、より安価なベクトルデータベースを選択することです。現在、市場にはさまざまなオプションがありますが、安価でスケーラブルなものを選ぶことが重要です。MyScaleDB (opens new window)は、特にコストを考慮して開発されたスケーラブルなRAGアプリケーション向けのベクトルデータベースです。市場で最も安価なベクトルデータベースの一つであり、競合他社よりも優れたパフォーマンスを提供しています。
関連記事: MyScaleを使い始める (opens new window)
# 大量のユーザー数がパフォーマンスに影響を与える
RAGアプリケーションがスケーリングするにつれて、増え続けるユーザー数をサポートし、速度、効率、信頼性を維持する必要があります。これには、システムを最適化してピークパフォーマンスを確保する必要があります。
レイテンシ: チャットボットなどのリアルタイムアプリケーションでは、低いレイテンシ (opens new window)を維持することが重要です。レイテンシとは、データの転送指示の後にデータの転送が開始されるまでの遅延を指します。レイテンシを最小限に抑えるための技術には、ネットワークパスの最適化、データ処理の複雑さの削減、より高速な処理ハードウェアの使用などがあります。レイテンシを効果的に管理するための方法の一つは、プロンプトのサイズを必要な情報に制限し、処理を遅くすることができる過度に複雑な指示を避けることです。
スループット: 需要が高まる時期には、多数のリクエストを同時に処理する能力(スループット)が重要です。これは、リクエストが到着するたびに動的にバッチ処理する連続バッチ処理などの技術を使用することで大幅に向上させることができます。
# パフォーマンスを向上させるための提案:
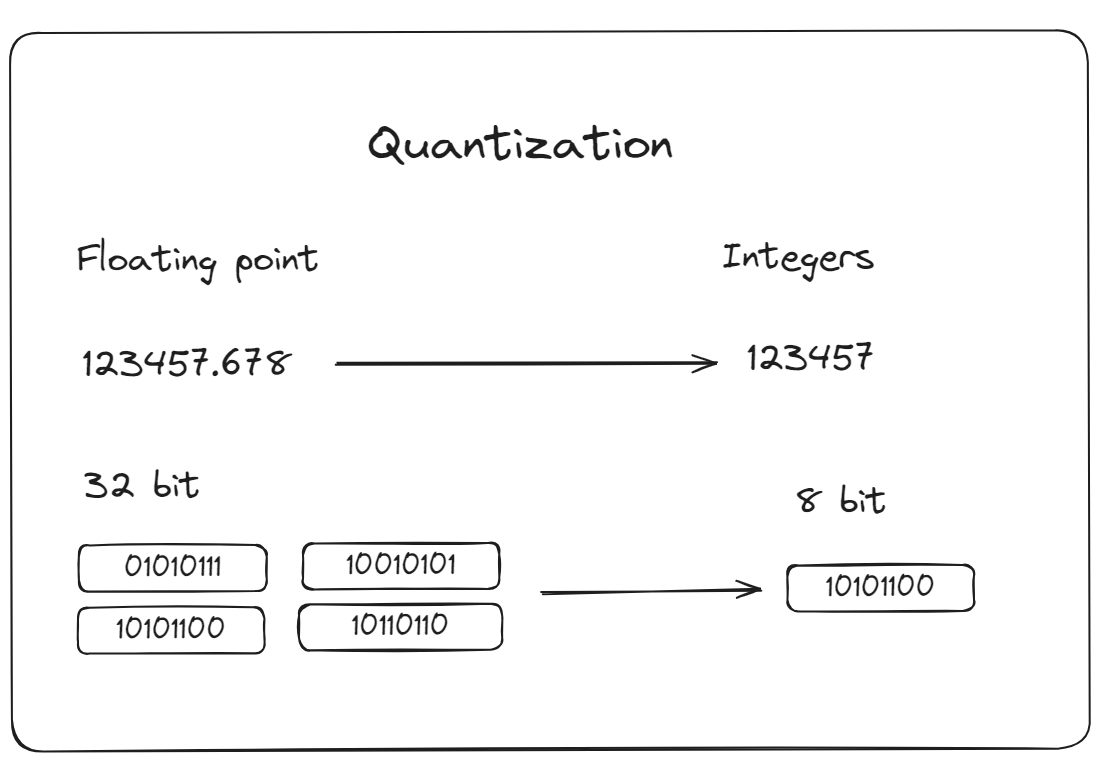
- 量子化: モデルパラメータを表す数値の精度を低下させるプロセスです。これにより、モデルの計算量が減少し、推論時間が短縮されます。MyScaleDBは、IVFPQ(Inverted File Partitioning and Quantization)やHNSWSQ(Hierarchical Navigable Small World Quantization)などの高度なベクトルインデックスオプションを提供しています。これらの手法は、データの検索プロセスを最適化することで、アプリケーションのパフォーマンスを向上させるために設計されています。
これらの人気のあるアルゴリズムに加えて、MyScaleDBはマルチスケールツリーグラフ(MSTG)(エンタープライズ機能)を開発しており、量子化と階層型ストレージに関する新しい戦略を特徴としています。このアルゴリズムは、IVFPQやHNSWSQとは異なり、低コストと高精度の両方を実現するために推奨されます。メモリと高速なNVMe SSDを組み合わせて使用することで、MSTGはIVFやHNSWアルゴリズムと比較してリソース消費を大幅に削減し、優れたパフォーマンスと精度を維持します。
マルチスレッディング: マルチスレッディングを使用すると、マルチコアプロセッサの機能を利用して複数のリクエストを同時に処理することができます。これにより、遅延が最小限に抑えられ、システム全体のスピードが向上します。特に多数のユーザーや複雑なクエリを処理する場合に効果的です。
動的バッチ処理: 大規模な言語モデル(LLM)へのリクエストを順次処理する代わりに、動的バッチ処理を使用して複数のリクエストを1つのバッチとして送信することができます。この方法を使用すると、APIのレート制限を課しているOpenAIやGeminiなどのサービスプロバイダーの場合でも、これらのレート制限内でより多くのリクエストを処理することができます。これにより、サービスがより信頼性が高く、APIの使用を最適化することができます。
# 大規模な埋め込み空間での効率的な検索
効率的な検索は、ベクトルデータベースがデータをインデックス化し、関連する情報を迅速かつ効果的に取得する能力に大きく依存します。データセットが小さい場合、すべてのベクトルデータベースは非常に優れたパフォーマンスを発揮しますが、データのボリュームが増えると問題が発生します。インデックス化と関連する情報の取得の複雑さが増します。これにより、検索プロセスが遅くなり、リアルタイムまたはリアルタイムに近い応答が必要な環境で重要な問題となります。さらに、データベースが大きくなるほど、正確性と一貫性を維持するのが難しくなります。エラーや重複、古い情報が簡単に混入する可能性があり、LLMアプリケーションが提供する出力の品質に影響を与える可能性があります。
さらに、広範なデータセットから最も関連性の高い情報を取得することに依存するRAGシステムの性質上、データの品質の低下は、アプリケーションのパフォーマンスと信頼性に直接影響を与えます。データセットが成長するにつれて、各クエリに最も正確で文脈に適した応答が返されることを確保することはますます困難になります。
# 最適な検索のための解決策:
データのボリュームの増加がシステムのパフォーマンスや出力の品質に影響を与えないようにするためには、次の要素を考慮する必要があります。
- 効率的なインデックス化: 大規模なデータセットを処理するためには、より高度なインデックス化方法やより効率的なベクトルデータベースソリューションの使用が必要です。MyScaleDB (opens new window)は、非常に大きなデータセットを処理するために設計された最新の高度なベクトルインデックスメソッドであるMSTG (opens new window)を提供しています。また、LAION 5Mデータセットで390 QPS(クエリ数/秒)を達成し、95%の再現率を達成し、平均クエリレイテンシが18msであるs1.x1ポッドでのパフォーマンスも他のインデックス化方法を上回っています。
- より良い品質のデータ: RAGシステムの正確性と信頼性にとって非常に重要なデータの品質を向上させるためには、いくつかの前処理技術を実装する必要があります。これにより、データセットを洗練し、ノイズを減らし、取得される情報の精度を高めることができます。これは、RAGアプリケーションの効果に直接影響を与えます。
- データの整理と最適化: データセットを定期的に見直し、古くなったり関連性のないベクトルを削除してデータベースをスリムかつ効率的に保つことができます。
さらに、MyScaleDBは、5Mのデータポイントに対してほぼ30分でタスクを完了しました。サインアップすると、5百万のベクトルを処理できるx1ポッドを無料で使用することができます。

# データ漏洩のリスクは常に存在します
RAGアプリケーションでは、2つの主要な側面により、プライバシーに関する懸念が特に重要です。それは、LLM APIの使用とデータのベクトルデータベースへの保存です。LLM APIを介してプライベートデータを送信する際には、データが第三者のサーバーに公開されるリスクがあり、機密情報の漏洩につながる可能性があります。また、ベクトルデータベースにデータを保存する際にも、完全に安全ではない可能性があり、データのプライバシーにリスクが生じる可能性があります。
# プライバシー向上のための解決策:
特に機密性の高いデータや非常に機密性の高いデータを扱う場合、次の戦略を考慮してこれらのリスクに対処することが重要です。
社内でのLLM開発: サードパーティのLLM APIに頼る代わりに、オープンソースのLLMを選択し、社内でデータを使って微調整 (opens new window)することができます。このアプローチにより、すべての機密データが組織の管理下で保持されるため、データ漏洩の可能性が大幅に低下します。
セキュリティの強化されたベクトルデータベース: ベクトルデータベースが最新の暗号化基準とアクセス制御で保護されていることを確認してください。MyScaleDBは、堅牢なセキュリティ機能を備えているため、チームや組織から信頼されています。MyScaleDBは、安全で完全に管理されたAWSインフラストラクチャ上にホストされたマルチテナントのKubernetesクラスタ上で動作しています。MyScaleDBは、顧客データを分離されたコンテナに保存し、システムの健全性とパフォーマンスを維持するために運用メトリクスを継続的に監視しています。さらに、MyScaleDBは、データセキュリティの最高のグローバル基準に準拠するため、SOC 2 Type 1の監査を成功裏に完了しました。MyScaleDBを使用することで、データが厳密に所有者のものであることを確信することができます。
関連記事: MyScaleで専門のベクトルデータベースを凌駕する (opens new window)
# 結論
検索補完生成(RAG)はAIの大きな進歩ですが、課題もあります。これには、APIとデータストレージの高コスト、増加するレイテンシ、より多くのユーザーが参加するにつれての効率的なスループットの必要性、データのプライバシーとセキュリティが含まれます。
これらの問題には、いくつかの戦略で対処することができます。社内でのオープンソースのLLMの使用やキャッシュの使用により、コストを削減することが可能です。レイテンシとスループットを改善するために、動的バッチ処理や高度な量子化などの技術を使用することができます。セキュリティの向上のためには、プロプライエタリなLLMの開発やMyScaleDBなどのベクトルデータベースの使用が有効です。
ご意見やご提案がありましたら、**Twitter (opens new window)またはDiscord (opens new window)**までお気軽にお問い合わせください。




