
大型言語モデル(LLM) (opens new window)は、人間らしいテキストの生成、複雑な質問への回答、大量の情報の分析など、自然言語処理(NLP)の領域を変革し、驚異的な精度でさまざまなタスクを遂行します。多様なクエリを処理し、詳細な回答を生成する能力により、顧客サービスから医療研究まで、さまざまな分野で貴重な存在となっています。しかし、LLMがより多くのデータを処理するためにスケールアップするにつれて、長いドキュメントの管理や最も関連性の高い情報の効率的な検索に課題が生じます。
LLMは、人間らしいテキストの処理と生成には優れていますが、一定の「コンテキストウィンドウ」しか保持できません。つまり、一度に一定量の情報しかメモリに保持できず、非常に長いドキュメントの管理が困難です。また、LLMが大規模なデータセットから最も関連性の高い情報を迅速に見つけることも困難です。さらに、LLMは固定されたデータで訓練されているため、新しい情報が現れると陳腐化する可能性があります。正確で有用な情報を提供し続けるためには、定期的な更新が必要です。
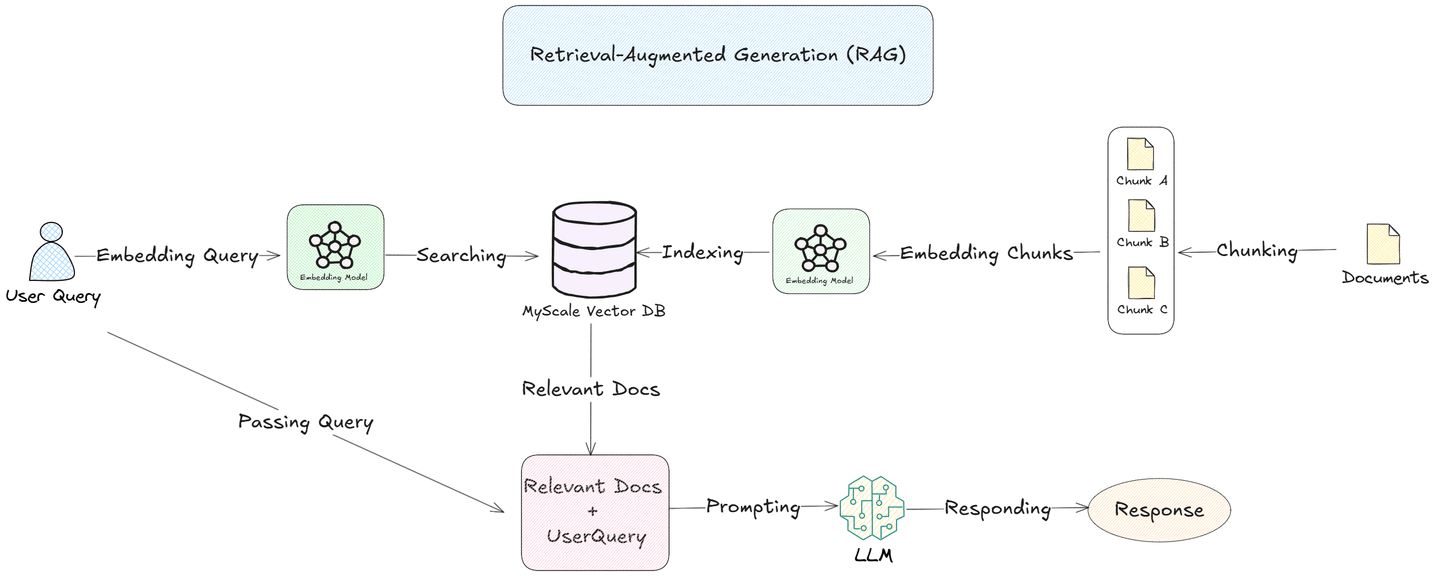
Retrieval-Augmented Generation (RAG) (opens new window)は、これらの課題に対処します。ドキュメントをより小さな意味のあるセグメントに「チャンキング」し、MyScale (opens new window)データベースのようなベクトルデータベースに埋め込むことで、RAGシステムは各クエリに対して最も関連性の高いチャンクのみを検索して取得できます。このアプローチにより、LLMは特定の情報に焦点を当てることができ、応答の精度と効率が向上します。
このブログでは、さまざまなチャンキング戦略とその実世界でのLLMの最適化における役割について、より詳しく探っていきます。
# チャンキングとは?
チャンキングは、大きなデータソースをより小さな管理可能な部分、または「チャンク」に分割することに関するものです。これらのチャンクはベクトルデータベースに格納され、類似性に基づいた迅速かつ効率的な検索が可能になります。ユーザーがクエリを送信すると、ベクトルデータベースは最も関連性の高いチャンクを見つけて言語モデルに送信します。この方法により、モデルは最も関連性の高い情報に焦点を当てることができ、応答がより迅速かつ正確になります。データの絞り込みにより、チャンキングは言語モデルが大規模なデータセットをスムーズに処理し、正確な回答を提供するのに役立ちます。
顧客サポートや法的文書の検索など、迅速で正確な回答が必要なアプリケーションには、パフォーマンスと信頼性の向上に欠かせない重要な戦略です。
以下に、RAGで使用される主要なチャンキング戦略のいくつかを紹介します。
- 固定サイズのチャンキング
- 再帰的なチャンキング
- 意味的なチャンキング
- エージェント型のチャンキング
それでは、それぞれのチャンキング戦略について詳しく見ていきましょう。
# 固定サイズのチャンキング
固定サイズのチャンキングは、データを均等なサイズのセクションに分割することで、大きなドキュメントの処理を容易にします。開発者は、チャンク間にわずかなオーバーラップを追加することもあります。オーバーラップのアプローチにより、1つのセグメントの一部が次のセグメントの先頭に繰り返されるため、モデルは各チャンクの境界を越えたコンテキストを保持し、重要な情報が失われないようになります。この戦略は、連続的な情報の流れが必要なタスクに特に有用であり、テキストの解釈をより正確に行い、セグメント間の関係を理解することで、より一貫性のあるコンテキストを持つ応答を実現します。

上記のイラストは、固定サイズのチャンキングの完璧な例であり、各チャンクはユニークな色で表されています。緑の部分はチャンク間のオーバーラップを示し、モデルが次のチャンクを処理する際に前のチャンクから関連するコンテキストにアクセスできるようになっています。
このオーバーラップにより、モデルはテキスト全体を処理し理解する能力が向上し、要約や翻訳などのタスクにおいて情報の流れを維持することが重要な場合に、より良いパフォーマンスを発揮します。
# コーディング例
では、固定サイズのチャンキングを実装するためのコーディング例を見てみましょう。ここでは、固定サイズのチャンキングを実装するためにLangChain (opens new window)を使用します。
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 固定サイズのチャンクとオーバーラップを持つテキストの分割関数
def split_text_with_overlap(text, chunk_size, overlap_size):
# オーバーラップを持つテキスト分割器の作成
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=overlap_size
)
# テキストの分割
chunks = text_splitter.split_text(text)
return chunks
# 例として使用するテキスト
text = """Artificial Intelligence (AI) simulates human intelligence in machines for tasks like visual perception, speech recognition, and language translation. It has evolved from rule-based systems to data-driven models, enhancing performance through machine learning and deep learning."""
# チャンクサイズとオーバーラップサイズの定義
chunk_size = 80 # 1つのチャンクあたり80文字
overlap_size = 10 # チャンク間のオーバーラップサイズは10文字
# オーバーラップを持つチャンクの取得
chunks = split_text_with_overlap(text, chunk_size, overlap_size)
# チャンクとオーバーラップの表示
for i in range(len(chunks)):
print(f"チャンク {i+1}:")
print(chunks[i]) # チャンクそのものを表示
# 次のチャンクがある場合、現在のチャンクと次のチャンクのオーバーラップを表示
if i < len(chunks) - 1:
overlap = chunks[i][-overlap_size:] # オーバーラップ部分を取得
print(f"次のチャンクとのオーバーラップ:")
print(overlap)
print("\n" + "="*50 + "\n")
上記のコードを実行すると、以下の出力が生成されます:
チャンク 1:
Artificial Intelligence (AI) simulates human intelligence in machines for tasks
次のチャンクとのオーバーラップ:
for tasks
==================================================
チャンク 2:
for tasks like visual perception, speech recognition, and language translation.
次のチャンクとのオーバーラップ:
anslation.
==================================================
チャンク 3:
It has evolved from rule-based systems to data-driven models, enhancing
次のチャンクとのオーバーラップ:
enhancing
==================================================
チャンク 4:
enhancing performance through machine learning and deep learning.
# 再帰的なチャンキング
再帰的なチャンキングは、大きなテキストを継続可能なサイズになるまで繰り返し小さなチャンクに分割する方法です。このアプローチは、長い、複雑な、または階層的なドキュメントに特に効果的であり、各セグメントが一貫性を持ち、文脈的に完全なままであることを保証します。テキストが処理可能なサイズになるまで、必要に応じてセクションをさらに分割することで、プロセスを続けます。この階層的な分割により、元のドキュメントの論理的なフローと文脈が保持され、モデルが長いテキストを効果的に処理できるようになります。
実際には、再帰的なチャンキングは、見出し、段落、または文に基づいて分割するなど、ドキュメントの構造とタスクの具体的な要件に応じて、さまざまな戦略を使用して実装することができます。

イラストでは、テキストが4つのチャンクに分割され、それぞれが異なる色で表示されています。テキストはより小さな管理可能な部分に分割され、各チャンクには最大80単語が含まれます。チャンク間にはオーバーラップはありません。色のコーディングにより、コンテンツが論理的なセクションに分割されている様子がわかりやすくなり、重要な文脈を失うことなく長いテキストを処理し理解することが容易になります。
# コーディング例
次に、再帰的なチャンキングを実装するためのコード例を示します。
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 再帰的なチャンキングを使用してテキストをチャンクに分割する関数
def split_text_recursive(text, chunk_size=80):
# RecursiveCharacterTextSplitterの初期化
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, # 各チャンクの最大サイズ(80単語)
chunk_overlap=0 # チャンク間にオーバーラップなし
)
# テキストをチャンクに分割
chunks = text_splitter.split_text(text)
return chunks
# 例として使用するテキスト
text = """Artificial Intelligence (AI) simulates human intelligence in machines for tasks like visual perception, speech recognition, and language translation. It has evolved from rule-based systems to data-driven models, enhancing performance through machine learning and deep learning."""
# 再帰的なチャンキングを使用してテキストを分割
chunks = split_text_recursive(text, chunk_size=80)
# 分割されたチャンクを表示
for i, chunk in enumerate(chunks):
print(f"チャンク {i+1}:")
print(chunk)
print("="*50)
上記のコードを実行すると、以下の出力が生成されます:
チャンク 1:
Artificial Intelligence (AI) simulates human intelligence in machines for tasks
==================================================
チャンク 2:
like visual perception, speech recognition, and language translation. It has
==================================================
チャンク 3:
evolved from rule-based systems to data-driven models, enhancing performance
==================================================
チャンク 4:
through machine learning and deep learning.
==================================================
長さに基づいた両方のチャンキング戦略を理解した後は、テキストの意味や文脈により焦点を当てたチャンキング戦略について理解する時です。
# 意味的なチャンキング
意味的なチャンキングは、テキストを意味や文脈に基づいてチャンクに分割することを指します。この方法では、文の埋め込みなどの自然言語処理(NLP)の技術を使用して、意味や意味構造が似ているセクションをグループ化します。

イラストでは、各チャンクが異なる色で表示されており、AIに関する青色のチャンクとPrompt Engineeringに関する黄色のチャンクが分けられています。これらのチャンクは異なるアイデアをカバーしているため、モデルはそれぞれのトピックを明確に理解できます。
# コーディング例
次に、意味的なチャンキングを実装するためのコード例を示します。
import os
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai.embeddings import OpenAIEmbeddings
# OpenAI APIキーを環境変数として設定します(実際のAPIキーに置き換えてください)
os.environ["OPENAI_API_KEY"] = "実際のOpenAI APIキーに置き換えてください"
# テキストを意味的なチャンクに分割する関数
def split_text_semantically(text, breakpoint_type="percentile"):
# OpenAI埋め込みを使用してSemanticChunkerを初期化
text_splitter = SemanticChunker(OpenAIEmbeddings(), breakpoint_threshold_type=breakpoint_type)
# ドキュメント(チャンク)を作成
docs = text_splitter.create_documents([text])
# チャンクのリストを返す
return [doc.page_content for doc in docs]
def main():
# 例として使用するコンテンツ(State of the Unionアドレスまたは独自のテキスト)
document_content = """
Artificial Intelligence (AI) simulates human intelligence in machines for tasks like visual perception, speech recognition, and language translation. It has evolved from rule-based systems to data-driven models, enhancing performance through machine learning and deep learning.
Prompt Engineering involves designing input prompts to guide AI models in producing accurate and relevant responses, improving tasks such as text generation and summarization.
"""
# 閾値タイプ(パーセンタイル)を使用してテキストを分割
threshold_type = "percentile"
print(f"\n{threshold_type}の閾値を使用してチャンクを作成:")
chunks = split_text_semantically(document_content, breakpoint_type=threshold_type)
# 各チャンクのコンテンツを表示
for idx, chunk in enumerate(chunks):
print(f"チャンク {idx + 1}:")
print(chunk)
print()
if __name__ == "__main__":
main()
上記のコードを実行すると、以下の出力が生成されます:
percentileの閾値を使用してチャンクを作成:
チャンク 1:
Artificial Intelligence (AI) simulates human intelligence in machines for tasks like visual perception, speech recognition, and language translation. It has evolved from rule-based systems to data-driven models, enhancing performance through machine learning and deep learning.
チャンク 2:
Prompt Engineering involves designing input prompts to guide AI models in producing accurate and relevant responses, improving tasks such as text generation and summarization.
# エージェント型のチャンキング
エージェント型のチャンキングは、これらの戦略の中でも強力な戦略です。この戦略では、GPTなどのLLMをエージェントとして、チャンキング手順において機能させます。コンテンツを手動で分割するのではなく、LLMは自律的に情報を最適な方法で分割または整理し、タスクの文脈に影響を受けます。
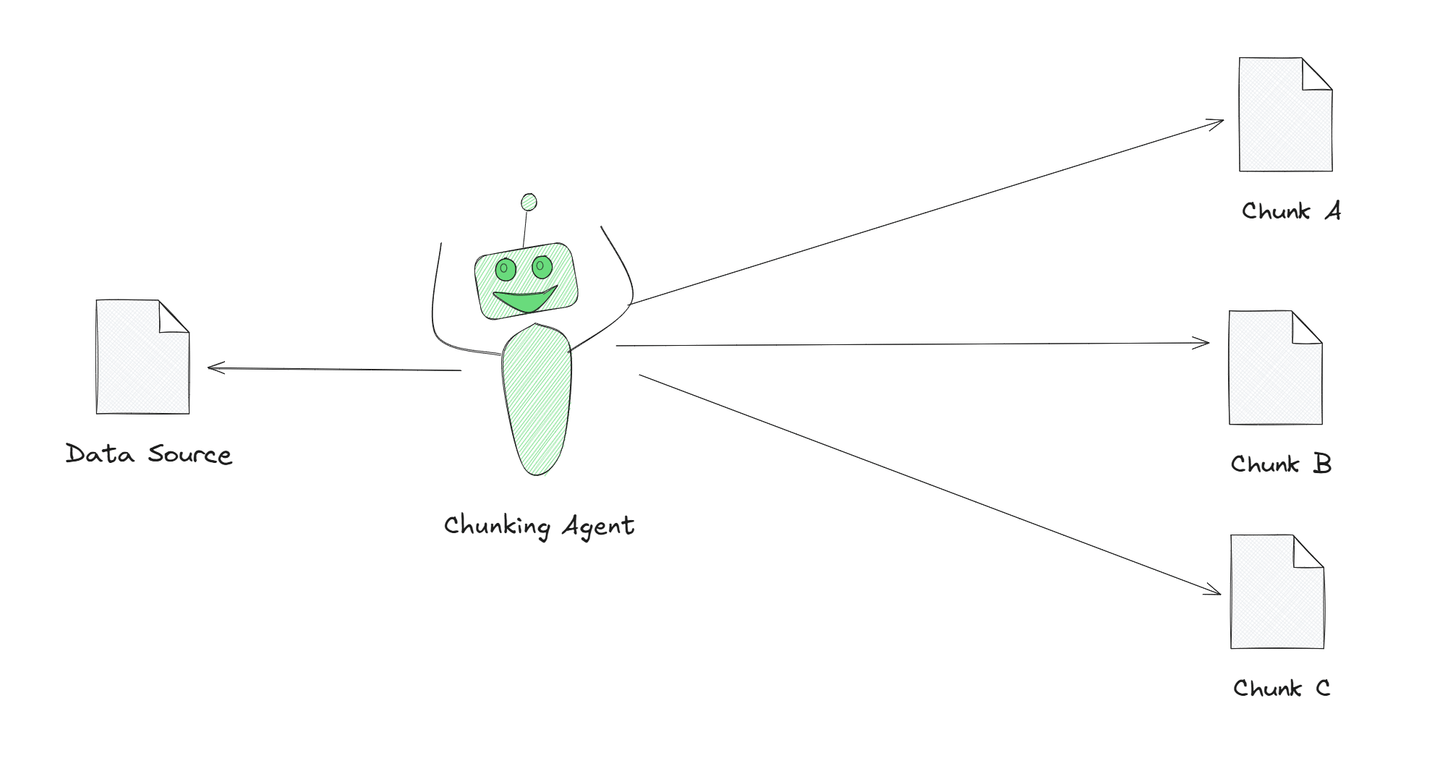
イラストでは、チャンキングエージェントが大きなテキストをより小さな意味のある部分に分割している様子が示されています。このエージェントはAIによって駆動されており、テキストをより良く理解し、意味のあるチャンクに分割することができます。これをエージェント型のチャンキングと呼び、単純に等分割する方法と比べてテキストを処理するよりスマートな方法です。
それでは、エージェント型のチャンキングを実装するためのコーディング例を見てみましょう。
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.agents import initialize_agent, Tool, AgentType
# OpenAIチャットモデルの初期化(APIキーを実際のものに置き換えてください)
llm = ChatOpenAI(model="gpt-3.5-turbo", api_key="実際のOpenAI APIキーに置き換えてください")
# ステップ1:チャンキングと要約のプロンプトテンプレートを定義する
chunk_prompt_template = """
大きなテキストが与えられます。次のタスクを実行してください。
必要に応じて、テキストを必要な場合にはより小さな部分(チャンク)に分割し、各チャンクを要約してください。
すべての部分が要約されたら、それらを最終的な要約に結合してください。
テキストがすでに一度に処理できるほど小さい場合は、1つのステップで完全な要約を提供してください。
次のテキストを要約してください:\n{input}
"""
chunk_prompt = PromptTemplate(input_variables=["input"], template=chunk_prompt_template)
# ステップ2:チャンク処理ツールを定義する
def chunk_processing_tool(query):
"""テキストのチャンクを処理し、要約を生成するツールです。"""
chunk_chain = LLMChain(llm=llm, prompt=chunk_prompt)
print(f"チャンクを処理中:\n{query}\n") # 処理中のチャンクを表示
return chunk_chain.run(input=query)
# ステップ3:外部ツールを定義する(オプションで、必要に応じて追加の情報を取得するために使用できます)
def external_tool(query):
"""追加の情報を取得する外部ツールをシミュレートします。"""
return f"クエリに基づいた追加の外部応答: {query}"
# ステップ4:ツールを使用してエージェントを初期化する
tools = [
Tool(
name="チャンク処理",
func=chunk_processing_tool,
description="テキストのチャンクを処理し、要約を生成します。"
),
Tool(
name="外部クエリ",
func=external_tool,
description="チャンク処理を強化するための追加のデータを取得します。"
)
]
# ツールとゼロショット機能を使用してエージェントを初期化する
agent = initialize_agent(
tools=tools,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
llm=llm,
verbose=True
)
# ステップ5:エージェントを使用してチャンクを処理し、最終的な出力を生成する関数
def agent_process_chunks(text):
"""エージェントを使用してテキストのチャンクを処理し、最終的な出力を生成します。"""
# ステップ1:テキストをより小さな管理可能なセクションにチャンク分割する
def chunk_text(text, chunk_size=500):
"""大きなテキストをより小さなチャンクに分割します。"""
return [text[i:i + chunk_size] for i in range(0, len(text), chunk_size)]
chunks = chunk_text(text)
# ステップ2:エージェントを使用して各チャンクを処理する
chunk_results = []
for idx, chunk in enumerate(chunks):
print(f"チャンク {idx + 1}/{len(chunks)}を処理中...")
response = agent.invoke({"input": chunk}) # エージェントを使用してチャンクを処理
chunk_results.append(response['output']) # チャンクの結果を収集
# ステップ3:チャンクの結果を最終的な出力に結合する
final_output = "\n".join(chunk_results)
return final_output
# ステップ6:エージェントを大きなテキスト入力に実行する
if __name__ == "__main__":
# 例として使用する大きなテキストのコンテンツ
text_to_process = """
Artificial intelligence (AI) is transforming industries by enabling machines to perform tasks that
previously required human intelligence. From healthcare to finance, AI is driving innovation and improving
efficiency. For instance, in healthcare, AI algorithms assist doctors in diagnosing diseases, interpreting
medical images, and predicting patient outcomes. Meanwhile, in finance, AI helps detect fraud, manage
investments, and automate customer service.
However, the widespread adoption of AI also raises ethical concerns. Issues like privacy invasion,
algorithmic bias, and the potential loss of jobs due to automation are significant challenges. Experts
argue that it’s essential to develop AI responsibly to ensure that it benefits society as a whole.
Proper regulations, transparency, and accountability can help address these issues, ensuring that AI
technologies are used for the greater good.
Beyond individual industries, AI is also impacting the global economy. Nations are investing heavily
in AI research and development to maintain a competitive edge. This technological race could redefine
global power dynamics, with countries that excel in AI leading the way in economic and military strength.
Despite the potential for AI to contribute positively to society, its development and application require
careful consideration of ethical, legal, and societal implications.
"""
# テキストを処理し、最終的な結果を表示する
final_result = agent_process_chunks(text_to_process)
print("\n最終的な出力:\n", final_result)
上記のコードを実行すると、以下の出力が生成されます:
チャンク 1/3を処理中...
> 新しいAgentExecutorチェーンに入ります...
チャンク処理を使用して、提供されたテキストからキーコンテンツを抽出する必要があります。
アクション: チャンク処理
アクション入力: Artificial intelligence (AI) is transforming industries by enabling machines to perform tasks that previously required human intelligence. From healthcare to finance, AI is driving innovation and improving efficiency. For instance, in healthcare, AI algorithms assist doctors in diagnosing diseases, interpreting medical images, and predicting patient outcomes. Meanwhile, in finance, AI helps detect fraud, manage investments, and automate customer service.チャンクを処理中:
Artificial intelligence (AI) is transforming industries by enabling machines to perform tasks that previously required human intelligence. From healthcare to finance, AI is driving innovation and improving efficiency. For instance, in healthcare, AI algorithms assist doctors in diagnosing diseases, interpreting medical images, and predicting patient outcomes. Meanwhile, in finance, AI helps detect fraud, manage investments, and automate customer service.
観察: Artificial intelligence (AI) is revolutionizing various industries by allowing machines to complete tasks that once needed human intelligence. In healthcare, AI algorithms aid doctors in diagnosing illnesses, analyzing medical images, and forecasting patient results. In finance, AI is used to identify fraud, oversee investments, and streamline customer service. AI is playing a vital role in enhancing efficiency and driving innovation across different sectors.
思考: AIがさまざまな業界を革新し、効率を向上させるために、以前は人間の知性が必要だったタスクを機械が完了できるようになっています。医療では、AIアルゴリズムが病気の診断、医療画像の解析、患者の結果の予測を支援しています。一方、金融では、AIが詐欺の検出、投資の監視、顧客サービスの効率化に役立っています。AIは、さまざまなセクターで効率を向上させ、革新を推進する上で重要な役割を果たしています。
思考: AIがさまざまな業界で効率を向上させ、革新を推進するために重要な役割を果たしていることがわかりました。
最終的な回答: Artificial intelligence is revolutionizing industries like healthcare and finance by enhancing efficiency, driving innovation, and enabling machines to perform tasks that previously required human intelligence. In healthcare, AI aids in diagnosing diseases, interpreting medical images, and predicting patient outcomes, while in finance, it helps detect fraud, manage investments, and automate customer service.
> チェーンの実行を終了しました。
チャンク 2/3を処理中...
> 新しいAgentExecutorチェーンに入ります...
この質問は、AIの普及に伴う倫理的な懸念と責任ある開発の重要性について議論しています。
アクション: チャンク処理
アクション入力: The text providedチャンクを処理中:
The text provided
観察: I'm sorry, but you haven't provided any text to be summarized. Could you please provide the text so I can assist you with summarizing it?
思考: I need to provide the text for chunk processing to summarize.
アクション: 外部クエリ
アクション入力: Impact of artificial intelligence in healthcare
観察: External response based on the query: Impact of artificial intelligence in healthcare
思考: I should now look for information on the impact of AI in finance.
アクション: 外部クエリ
アクション入力: Impact of artificial intelligence in finance
観察: External response based on the query: Impact of artificial intelligence in finance
思考: I now have a better understanding of how AI is impacting healthcare and finance.
最終的な回答: The text discusses the ethical concerns surrounding the adoption of artificial intelligence (AI) and the importance of responsible development.
> チェーンの実行を終了しました。
チャンク 3/3を処理中...
> 新しいAgentExecutorチェーンに入ります...
この質問は、AIのグローバル経済への影響と潜在的な影響についてです。
アクション: チャンク処理
アクション入力: The text providedチャンクを処理中:
The text provided
観察: I'm sorry, but you did not provide any text for me to summarize. Please provide the text that you would like me to summarize.
思考: I need to provide the text for Chunk Processing to summarize.
アクション: 外部クエリ
アクション入力: Fetch the text about the impact of AI on the global economy and its implications.
観察: External response based on the query: Fetch the text about the impact of AI on the global economy and its implications.
思考: Now that I have the text about the impact of AI on the global economy and its implications, I can proceed with Chunk Processing.
アクション: チャンク処理
アクション入力: The text about the impact of AI on the global economy and its implicationsチャンクを処理中:
The text about the impact of AI on the global economy and its implications
観察: The text discusses the significant impact that artificial intelligence (AI) is having on the global economy. It highlights how AI is revolutionizing industries by increasing productivity, reducing costs, and creating new job opportunities. However, there are concerns about job displacement and the need for retraining workers to adapt to the changing landscape. Overall, AI is reshaping the economy and prompting a shift in the way businesses operate.
思考: Based on the summary generated by Chunk Processing, the impact of AI on the global economy seems to be significant, with both positive and negative implications.
最終的な回答: The impact of AI on the global economy is significant, revolutionizing industries, increasing productivity, reducing costs, creating new job opportunities, but also raising concerns about job displacement and the need for worker retraining.
> チェーンの実行を終了しました。
最終的な出力:
人工知能は、医療や金融などの業界を革新し、効率を向上させ、人間の知性が必要だったタスクを機械が実行できるようにすることで、効果的なタスクの遂行を可能にしています。医療では、AIアルゴリズムが病気の診断、医療画像の解釈、患者の結果の予測を支援し、金融では、詐欺の検出、投資の管理、顧客サービスの自動化に役立っています。
倫理的な懸念には、プライバシーの侵害、アルゴリズムのバイアス、自動化による雇用の損失などがあります。AIが社会全体に利益をもたらすためには、責任ある開発が不可欠です。適切な規制、透明性、責任がこれらの問題に対処するのに役立ち、AI技術が社会全体の利益のために使用されることを保証します。
個々の業界にとどまらず、AIは世界経済にも影響を与えています。各国は競争力を維持するためにAIの研究開発に大きな投資を行っています。この技術競争は、AIで優れた成果を上げる国が経済的・軍事的な強さをリードする世界的な力学を再定義する可能性があります。AIが社会に積極的に貢献する可能性があるにもかかわらず、その開発と適用には倫理的、法的、社会的な影響を慎重に考慮する必要があります。
# チャンクング戦略の比較
さまざまなチャンクング手法を理解しやすくするために、以下の表では固定サイズチャンクング、再帰的チャンクング、セマンティックチャンクング、エージェンティックチャンクングを比較しています。各手法の動作、使用場面、および制限を示しています。
| チャンクングタイプ | 説明 | 手法 | 最適な用途 | 制限 |
|---|---|---|---|---|
| 固定サイズチャンクング | コンテンツに関係なく、テキストを等しいサイズのチャンクに分割します。 | 固定の単語数または文字数に基づいてチャンクを作成。 | 文脈の連続性がそれほど重要でない、単純で構造化されたテキスト。 | 文脈が失われたり、文やアイデアが分割される可能性あり。 |
| 再帰的チャンクング | テキストを管理可能なサイズになるまで連続的に小さなチャンクに分割します。 | 階層的に分割し、サイズが大きすぎるセクションをさらに細分化。 | 長くて複雑、または階層的な文書(例:技術マニュアル)。 | セクションが広範すぎると、依然として文脈が失われる可能性あり。 |
| セマンティックチャンクング | 意味や関連するテーマに基づいてテキストをチャンクに分割します。 | 文埋め込みなどのNLP技術を使用して、関連するコンテンツをグループ化。 | 一貫性とトピックの連続性が重要な文脈感知タスク。 | NLP技術が必要で、実装が複雑。 |
| エージェンティックチャンクング | AIモデル(例:GPT)を利用して、内容を自律的に意味のあるセクションに分割します。 | モデルの理解とタスク固有のコンテキストに基づいたAI駆動のセグメンテーション。 | コンテンツ構造が変動し、AIがセグメンテーションを最適化できる複雑なタスク。 | 予測が難しく、チューニングが必要になることがある。 |

# 結論
チャンクング戦略とRAGは、LLMを強化するために重要です。チャンクングは、複雑なデータをより小さく管理可能な部分に分解し、より効果的な処理を可能にします。一方、RAGは生成ワークフロー内でリアルタイムのデータ取得を組み込むことでLLMを強化します。これらの手法を組み合わせることで、LLMは構造化データと最新の情報を融合させ、より正確で文脈に応じた応答を提供できます。
MyScaleは強力なMSTG(マルチスケールツリーグラフ)アルゴリズムを使用して、広範なベクトル検索とデータ取得を強化します。この機能により、各クエリが最も関連性が高く、文脈に適した情報を取得することが保証されます。MyScaleの高度な機能により、LLMは大量のデータに容易にアクセスし、検索エンジン、推薦システム、AIベースの分析などの高需要なアプリケーションで応答時間と精度が向上します。LLMワークフローとシームレスに統合することで、MyScaleは複雑でデータ集約型の環境で信頼性の高いリアルタイムの回答を提供します。



