
この記事は元々The New Stack (opens new window)に掲載されたものです。
大規模言語モデル(LLM)は、文脈を理解する能力を持っています。天文学、歴史、物理学など、どんなトピックであっても、広範なトレーニングデータを活用して、一貫性のある文脈に即した回答を提供することができます。しかし、LLMは全ての詳細を覚えることができず、特にllama2-13b-chatのような小規模モデルでは、トレーニングデータに要求された知識が存在するにもかかわらず、幻覚を見ることがあります。
Retrieval Augmented Generation(RAG)という新しい技術は、外部データを用いてプロンプトを補完することで、知識のギャップを埋め、幻覚を減らすことができます。MyScale (opens new window)のようなベクトルデータベースと組み合わせることで、Wikipediaなどの包括的な知識ベースがトレーニングセットに含まれている場合でも、抽出型の質問応答システムのパフォーマンスを大幅に向上させることができます。
この記事では、広く使用されているMMLUデータセット上でのRAGのパフォーマンス向上を評価することに焦点を当てています。商用およびオープンソースのLLMのパフォーマンスは、Wikipediaからベクトルデータベースを使用して知識を取得できる場合に、大幅に改善されることがわかりました。さらに興味深いことに、これらのモデルのトレーニングセットにWikipediaが既に含まれている場合でも、この結果が得られました。
ベンチマークフレームワークとこの例のコードはこちら (opens new window)で入手できます。
# Retrieval Augmented Generation
まずは、Retrieval Augmented Generation(RAG)について説明しましょう。
RAGは、外部の知識ベース(Wikipediaなど)、データベース、またはインターネットをLLM(例:ChatGPT)に組み合わせることで、より知識豊かで文脈を理解したシステムを作成することを目指す研究プロジェクトです。例えば、ユーザーがLLMにニュートンの最も重要な結果について尋ねた場合、正しい情報を取得するためにニュートンのWikipediaを検索し、そのWikipediaページをLLMに提供することができます。
この方法はRetrieval Augmented Generation(RAG)と呼ばれます。LewisらはRetrieval Augmented Generation for Knowledge-Intensive NLP Tasks (opens new window)を次のように定義しています。
「言語生成モデルの一種であり、パラメトリックおよび非パラメトリックなメモリを組み合わせて言語生成を行うモデル。」
さらに、この学術論文の著者らは次のように述べています。
「事前学習されたパラメトリックメモリ生成モデルに、一般的なファインチューニング手法を用いて非パラメトリックメモリを付与する。」
注意:
パラメトリックメモリLLMは、ChatGPTやGoogleのPaLMのような大規模な自己完結型の知識リポジトリです。非パラメトリックメモリLLMは、パラメトリックメモリLLMに追加のコンテキストを提供する外部リソースを活用します。
外部リソースをLLMと組み合わせることは、LLMが良い学習者であるため実現可能ですし、特定の外部知識領域に言及することで真実性を向上させることができます。しかし、この組み合わせによるどれだけの改善が得られるのでしょうか?
RAGシステムには2つの主要な要素が影響します。
- LLMが外部コンテキストから学習できる量
- 外部コンテキストの正確性と関連性
これらの要素はどちらも評価が難しいです。LLMがコンテキストから得る知識は暗黙的なものであり、これらの要素を評価する最も実用的な方法は、LLMの回答を検証することです。ただし、取得したコンテキストの正確性を評価することも難しいです。
特に質問応答や情報検索などのタスクでは、段落間の関連性を評価することは複雑な作業です。特定の質問に直接関連する情報が特定のセクションに含まれているかどうかを判断するためには、関連性の評価が重要です。これは、WikiHop (opens new window)データセットなど、大規模なデータセットやドキュメントから情報を抽出するタスクでは特に重要です。
時には、データセットでは複数の注釈者が段落と質問の関連性を評価するために投票することがあります。複数の注釈者による関連性の投票は、個々の注釈者から生じる主観性や潜在的なバイアスを軽減するのに役立ちます。この方法は一貫性を持たせ、関連性の判断がより信頼性のあるものになるようにします。
これらの不確実性の結果として、私たちはRAGシステムのオープンソースのエンドツーエンド評価を開発しました。この評価では、異なるモデル設定、リトリーバルパイプライン、知識ベースの選択、および検索アルゴリズムを考慮しています。
私たちは、RAGシステムの設計における貴重なベースラインを提供し、より多くの開発者や研究者が私たちと一緒に包括的かつ体系的なベンチマークを構築することを期待しています。さらなる結果は、これらの2つの要素を解明し、現実世界のRAGシステムにより近いデータセットを作成するのに役立ちます。
注意:
評価結果をGitHub (opens new window)で共有してください。PRは大歓迎です!
# RAGシステムのシンプルなエンドツーエンドベースライン
![]()
この記事では、MMLU(Massive Multitask Language Understanding)データセット (opens new window)を使用したシンプルなベースラインに焦点を当てています。MMLUデータセットは、歴史、天文学、経済など多くの科目に関する多肢選択単一回答の質問を含む、広く使用されているLLMのベンチマークです。
LLMが追加のコンテキストから学習できるかどうかを確認するために、LLMに複数選択肢の質問に答えさせることができるかどうかを調査しました。
この目的を達成するために、真実の情報源としてWikipediaを選びました。Wikipediaは多くの科目や知識領域をカバーしているためです。また、Hugging Face上のCohere.ai (opens new window)によってクリーンアップされたバージョンを使用しました。このバージョンには、5,745,033のタイトルに属する34,879,571の段落が含まれています。これらの段落を徹底的に検索するにはかなりの時間がかかるため、適切なANNS(Approximate Nearest Neighbor Search)アルゴリズムを使用して関連するドキュメントを取得する必要があります。さらに、関連するドキュメントを取得するために、MSTGベクトルインデックスを使用したMyScaleデータベースを使用します。
# セマンティックサーチモデル
セマンティックサーチは、多くのモデル (opens new window)と詳細なベンチマーク (opens new window)が利用可能な、よく研究されたトピックです。ベクトル埋め込みと組み合わせることで、セマンティックサーチは、言い換え表現、同義語、文脈理解を認識する能力を獲得します。
さらに、埋め込みは密で連続的なベクトル表現を提供し、関連性の意味のある指標を計算することができます。これらの密な指標は、意味的な関係と文脈を捉えることができるため、LLMの情報検索タスクにおける関連性の評価に価値があります。
上記の要素を考慮して、Hugging Faceのparaphrase-multilingual-mpnet-base-v2 (opens new window)モデルを使用して、リトリーバルタスクのための特徴を抽出することにしました。このモデルはMPNetファミリーの一部であり、セマンティックの類似性やリトリーバルなど、さまざまなNLPタスクに適した高品質な埋め込みを生成するために設計されています。
# 大規模言語モデル(LLMs)
LLMsとして、OpenAIのgpt-3.5-turboとllama2-13b-chatを選びました。これらのモデルは、商用およびオープンソースのトレンドで最も人気があります。LLaMA2モデルはllama.cpp (opens new window)によって6ビットの量子化が行われています。この6ビットの量子化設定を選んだ理由は、パフォーマンスを犠牲にすることなく手頃な価格であるためです。
注意:
RAGのパフォーマンスをテストするために、他のモデルも試すことができます。
# 私たちのRAGシステム
以下の図は、シンプルなRAGシステムの構成方法を示しています。
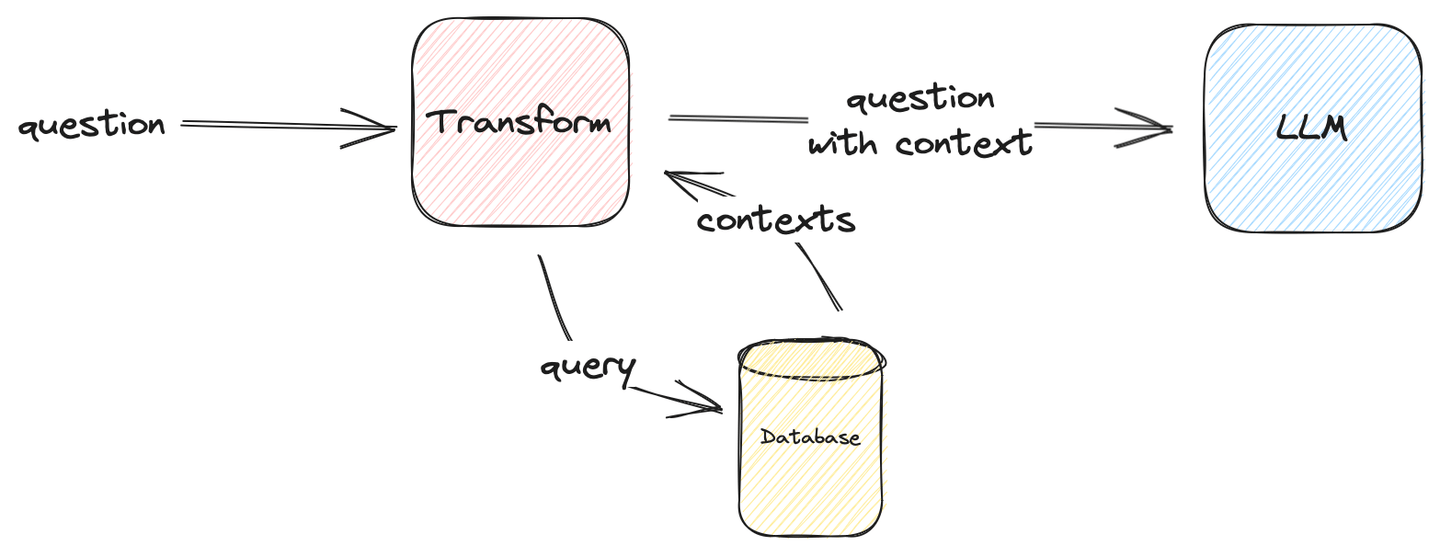
図1: シンプルなベンチマークRAG
注意:
Transformは、LLMに正しい回答を返すことができるかぎり、何でも構いません。私たちのユースケースでは、Transformは質問にコンテキストを注入します。
最終的なLLMのプロンプトは次のようになります。
template = \
("The following are multiple choice questions (with answers) with context:"
"\n\n{context}Question: {question}\n{choices}Answer: ")
それでは、結果に移りましょう!
# いくつかのベンチマークの洞察
ベンチマークテストの結果は、以下の表1にまとめられています。
しかし、まずは結果の要点を挙げます:
表1: 異なるコンテキストによるリトリーバルの精度
| Setup | Dataset | Average | |||||
|---|---|---|---|---|---|---|---|
| LLM | Contexts | mmlu-astronomy | mmlu-prehistory | mmlu-global-facts | mmlu-college-medicine | mmlu-clinical-knowledge | |
| gpt-3.5-turbo | ❌ | 71.71% | 70.37% | 38.00% | 67.63% | 74.72% | 68.05% |
| ✅ (Top-1) | 75.66% (+3.95%) | 78.40% (+8.03%) | 46.00% (+8.00%) | 67.05% (-0.58%) | 73.21% (-1.51%) | 71.50% (+3.45%) | |
| ✅ (Top-3) | 76.97% (+5.26%) | 81.79% (+11.42%) | 48.00% (+10.00%) | 65.90% (-1.73%) | 73.96% (-0.76%) | 72.98% (+4.93%) | |
| ✅ (Top-5) | 78.29% (+6.58%) | 79.63% (+9.26%) | 42.00% (+4.00%) | 68.21% (+0.58%) | 74.34% (-0.38%) | 72.39% (+4.34%) | |
| ✅ (Top-10) | 78.29% (+6.58%) | 79.32% (+8.95%) | 44.00% (+6.00%) | 71.10% (+3.47%) | 75.47% (+0.75%) | 73.27% (+5.22%) | |
| llama2-13b-chat-q6_0 | ❌ | 53.29% | 57.41% | 33.00% | 44.51% | 50.19% | 50.30% |
| ✅ (Top-1) | 58.55% (+5.26%) | 61.73% (+4.32%) | 45.00% (+12.00%) | 46.24% (+1.73%) | 54.72% (+4.53%) | 55.13% (+4.83%) | |
| ✅ (Top-3) | 63.16% (+9.87%) | 63.27% (+5.86%) | 49.00% (+16.00%) | 46.82% (+2.31%) | 55.85% (+5.66%) | 57.10% (+6.80%) | |
| ✅ (Top-5) | 63.82% (+10.53%) | 65.43% (+8.02%) | 51.00% (+18.00%) | 51.45% (+6.94%) | 57.74% (+7.55%) | 59.37% (+9.07%) | |
| ✅ (Top-10) | 65.13% (+11.84%) | 66.67% (+9.26%) | 46.00% (+13.00%) | 49.71% (+5.20%) | 57.36% (+7.17%) | 59.07% (+8.77%) | |
| * ベンチマークでは、ベクトルインデックスとしてMyScale MSTGを使用しています * このベンチマークは、弊社のGitHubリポジトリ retrieval-qa-benchmark で再現できます | |||||||
# 1. 追加の文脈は通常役立ちます
これらのベンチマークテストでは、文脈の有無によるパフォーマンスを比較しました。文脈のないテストは、内部の知識が質問を解決する方法を表しています。次に、文脈のあるテストは、LLMが文脈から学習する方法を示しています。
注意:
llama2-13b-chatとgpt-3.5-turboの両方は、追加の文脈が1つだけでも全体的に約3-5%向上しています。
表には、一部の数値が負の値となっていることが報告されています。たとえば、clinical-knowledgeからgpt-3.5-turboへの文脈の挿入時にそれが起こります。
これは、Wikipediaには臨床知識に関する情報があまりないか、OpenAIの利用規約とガイドラインで、医療アドバイスにAIモデルを使用することは強く非推奨であり、禁止される場合があるため、関連しているかもしれません。それにもかかわらず、両モデルの増加は非常に明白です。
特に、gpt-3.5-turboの結果では、RAGシステムが他の言語モデルと競合するほど強力かもしれないことを示しています。prehistoryやastronomyなどの一部の報告された数値は、追加のトークンを持つgpt4のパフォーマンスに近づいており、RAGはファインチューニングと比較して、専門的な人工一般知能(AGI)への別の解決策となる可能性があります。
注意:
RAGは、プラグインソリューションであり、セルフホスト型およびリモートモデルの両方で動作するため、ファインチューニングモデルよりも実用的です。
# 2. より多くの文脈は時に役立ちます
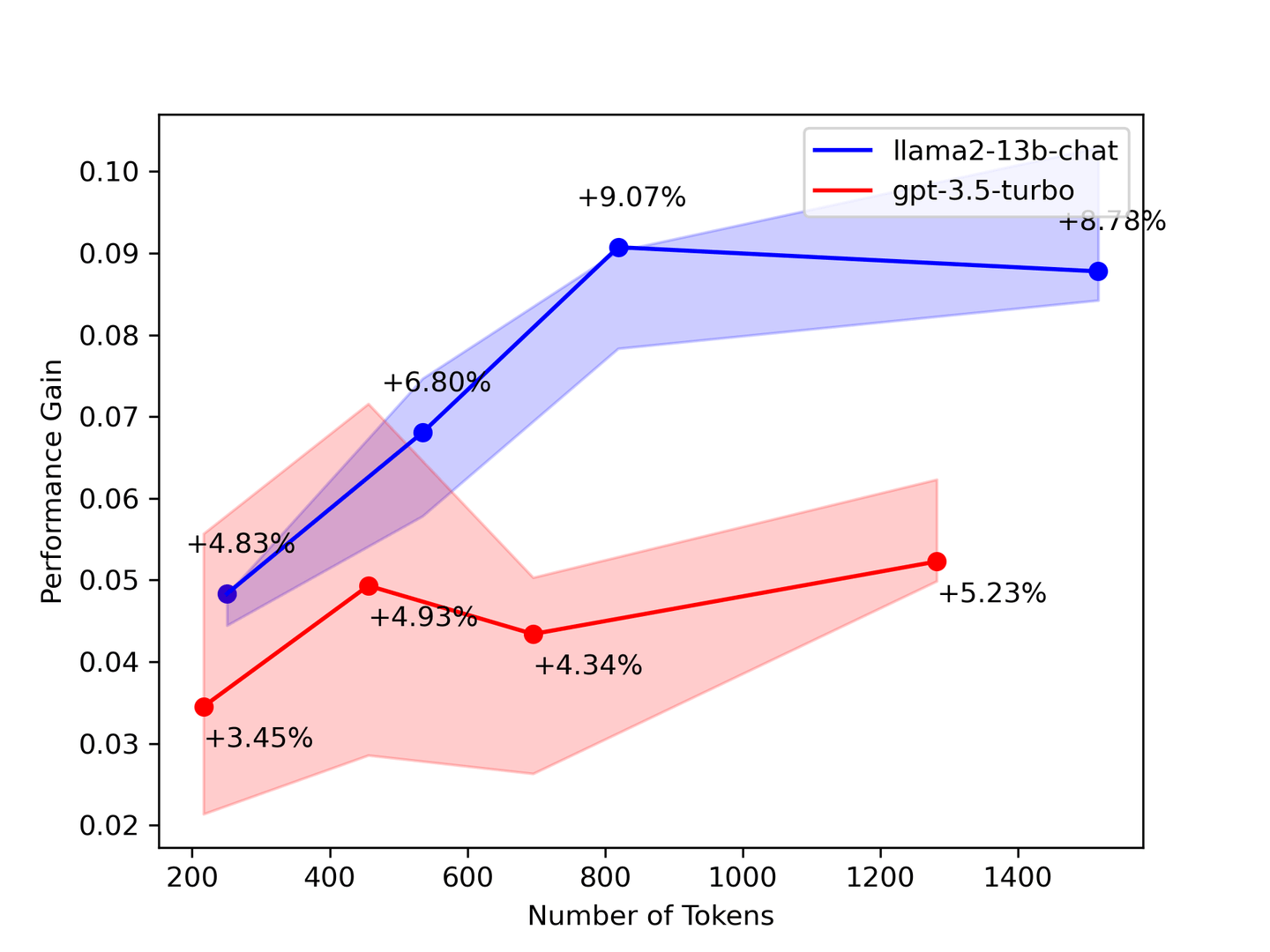
図2:パフォーマンスの向上度と文脈の数
上記のベンチマークは、できるだけ多くの文脈が必要であることを示唆しています。ほとんどの場合、LLMは提供されたすべての文脈から学習します。理論的には、回収されるドキュメントの数が増えるほど、モデルはより良い回答を提供します。しかし、私たちのベンチマークでは、一部の数値が回収される文脈の数が増えるにつれて低下することがわかりました。
私たちのベンチマーク結果を検証するために、スタンフォード大学の論文「Lost in the Middle: How Language Models Use Long Contexts (opens new window)」では、LLMが文脈の先頭と末尾のみを見ているということが示されています。そのため、LLMを補完するために、リトリーバルシステムからより少なくてもより正確な文脈を選択することをお勧めします。
# 3. より小さなモデルはより多くの知識を求めます
LLMが大きいほど、より多くの知識を保持します。大きなLLMは情報を格納し理解する能力が高く、一般的に理解される事実の幅広い知識ベースにつながる傾向があります。私たちのベンチマークテストも同じことを示しています。小さなLLMは知識が不足しており、より多くの知識を求めています。
私たちの結果によれば、llama2-13b-chatはgpt-3.5-turboよりも知識がより大幅に増加しており、文脈がLLMに情報を注入することを示しています。さらに、これらの結果は、gpt-3.5-turboには既に知っている情報が与えられている一方、llama2-13b-chatはまだ文脈から学習していることを示唆しています。
# 最後に...
ほとんどのLLMは、トレーニングデータセットとしてWikipediaコーパスを使用しています。したがって、gpt-3.5-turboとllama2-13b-chatの両方は、プロンプトに追加された文脈には馴染みがあるはずです。したがって、次の質問が浮かび上がります。
- このベンチマークテストの増加の理由は何ですか?
- LLMは本当に提供された文脈を使用して学習しているのでしょうか?
- それとも、これらの追加の文脈はトレーニングセットデータから学んだ記憶を呼び起こすのに役立っているのでしょうか?
これらの質問にはまだ答えがありません。そのため、引き続き研究が必要です。

# RAGベンチマークの共同構築への貢献
他の人を助けるための研究に貢献しましょう。
このブログでは、限られた評価しか取り上げることができません。しかし、さらなる評価が必要であることは明白です。既存のテストの再現であれ、斬新な RAG に基づく新しい発見であれ、あらゆるベンチマークテストの結果は重要です。
誰もが独自の RAG システムをテストするためのベンチマークテストを作成できるよう支援することを目的として、エンドツーエンドのベンチマークフレームワーク: https://github.com/myscale/Retrieval-QA-Benchmark/ をオープンソース化しました。レポジトリをフォークするには、GitHub ページをご覧ください!
このフレームワークには以下のツールが含まれています:
リッチェルと LLM 生成の時間消費を測定できるユニバーサルプロファイラー 複雑な検索パイプラインを構築できるグラフ実行エンジン すべての実験設定を一箇所で記述できる統一設定 独自のベンチマークを作成するのはあなた次第です。私たちは RAG が AGI の解決策になり得ると信じています。そのため、コミュニティがすべてを追跡可能で再現可能なものにするために、このフレームワークを構築しました。
プルリクエストは大歓迎です!
# 結論
この記事では、限られたMMLUのサブセットを評価し、異なるLLMとベクトル検索アルゴリズムで構築されたシンプルなRAGシステムを評価し、そのプロセスと結果について説明しました。また、ベンチマークフレームワークをコミュニティに寄付し、さらなるRAGベンチマークを呼びかけました。私たちは引き続きベンチマークテストを実行し、最新の結果をGitHubとMyScaleブログに更新していく予定ですので、Twitter (opens new window)でフォローするか、Discord (opens new window)に参加して最新情報を入手してください。



