
RAG (opens new window) の最初のステップは、クエリごとに複数のドキュメントを取得することであり、これらのドキュメントはクエリに関連性がないことがよくあります。したがって、これらの結果を改善するために、外部の技術が必要です。結果の関連性が高いほど、検索は強力です。
ベクトル検索を適用する際には、いくつかの理由で意味情報が失われることが一般的です。たとえば、ドキュメントはより小さなサブドキュメントに分割する必要があり、これにより文脈情報が失われる可能性があります。その結果、RAGモデルは複数の取得されたドキュメント間の情報を効果的に結びつけるのに苦労する場合があります。[1]
これらの課題に対処するために、RAGフレームワーク内でドキュメントの再ランキング技術を使用します。再ランキングされたドキュメントを再ランキングするために使用できるさまざまな方法があります。
# ドキュメントの再ランキングとは
RAGの分野が進化し続ける中で、再ランキングの役割がRAGのフルポテンシャルを引き出すための重要な要素として浮かび上がってきました。再ランキングは、単に取得された結果の再編成以上のものであり、ユーザーに提示される情報の関連性、多様性、個別化を大幅に向上させる戦略的なプロセスです。
追加のシグナルとヒューリスティックを活用することで、RAGの再ランキングステージは初期のドキュメント検索を洗練させ、最も関連性の高く価値のあるデータが上位に表示されるようにします。さらに、再ランキングは反復的なアプローチを可能にし、ますます正確で文脈に即した出力を得るために結果を洗練させます。
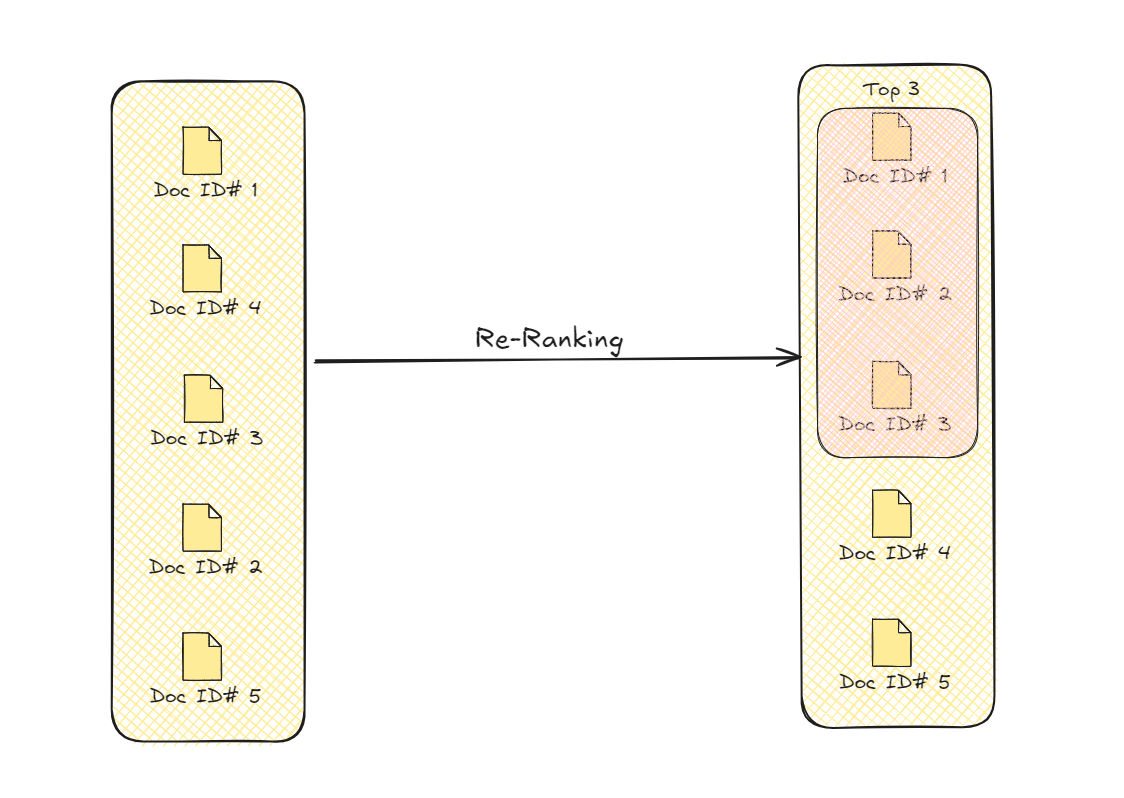
ドキュメントの再ランキング
このプロセスにより、クエリに文脈的に適したドキュメントが優先的に選択され、モデルが最終的な出力を生成するために使用する情報の全体的な品質と精度が向上します。
# Transformerを使用した再ランキング
ドキュメントの再ランキングにTransformerモデルを使用することは、RAG以前からの歴史があります。2020年、研究者たちは事前学習済みの(seq2seq) Transformerをドキュメントの再ランキングに適用しました。[2] このシステムは、ドキュメントを入力として受け取り、それが関連性があるかどうかを返します。関連性のあるドキュメント(つまり、「true」とラベル付けされたドキュメント)をフィルタリングした後、確率関数としてSoftmax (opens new window)を使用して再ランキングされます。
注意:
これらのシーケンス・トゥ・シーケンス・モデルはシーケンスを返すため、"true"または"false"のみを返すように変更されました。
# LLMの使用
LLMのオールラウンドな機能を活用してRAGを改善することは、今日では一般的になっています[4-7]。
あるアプローチでは、研究者たちはGPT-3 [4] を使用して、プロンプトのみを使用してランキングを実行し、LRL (LLMを使用したリストワイズ再ランカー) (opens new window)と名付けました。使用されたプロンプトは非常にシンプルでした。

ソートされた再ランキングされたドキュメント
ドキュメントの関連性の信頼性を高めるために、分類にもプロンプトが使用され、PRL (LLMを使用したポイントワイズ再ランカー) (opens new window)と名付けられました。

LLMを使用した再ランキング
より方法論的なアプローチでは、LLaMA (opens new window)がドキュメントの再ランキングに使用されます。この方法(RankLLaMA (opens new window))は、次のように取得されたドキュメントにランキング関数を適用します。
再ランキング関数を適用した後、InfoNCE損失を使用してさらに最適化します(MoCoにおける対照的学習 (opens new window)で以前に見たことがあります)。
# クロスエンコーダの使用
クロスエンコーダは、ドキュメントの再ランキングによく使用される別のタイプのTransformerです。その名前が示すように、クロスエンコーダはクエリと(各)ドキュメントの両方をエンコードし、その出力は2つの間のクロス類似性/関連性を示します。

クロスエンコーダを使用した再ランキング
すべてのドキュメントをクエリとクロスマッチすることは現実的ではないため、クロスマッチするドキュメントを選別する必要があります。事前選択には2つの一般的な方法があります。
- バイエンコーダの使用
- BM25のような疎な検索方法の使用
クロスエンコーダ (opens new window)は、高い精度と改善された文脈理解力を持つため、RAGで使用される前から優れたパフォーマンスを示しています[6]。これは今やRAGのドキュメントの再ランキングで広く使用されているため、驚くことではありません。以下は、HuggingFace (opens new window)とPyTorch (opens new window)を使用した基本的な実装です。
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
tokenizer = AutoTokenizer.from_pretrained("cross-encoder/ms-marco-TinyBERT-L-6")
model = AutoModelForSequenceClassification.from_pretrained("cross-encoder/ms-marco-TinyBERT-L-6")
def ReRank(query, documents):
scores = []
for doc in documents:
inputs = tokenizer(query, doc, return_tensors="pt", padding=True, truncation=True, max_length=512)
with torch.no_grad():
outputs = model(**inputs)
scores.append(outputs.logits.squeeze().item())
rankedDocs = [doc for _, doc in sorted(zip(scores, documents), reverse=True)]
return rankedDocs
サンプルクエリに対して使用する場合は、次のようにします。
query = "Which month is most suitable to visit Bali?"
# docs変数にリストとしてドキュメントを想定しています。
rankedDocs = ReRank(query, docs)
print(rankedDocs)
# グラフを使用した再ランキング
学術/研究者であれば、おそらくLitmaps (opens new window)やConnected Papers (opens new window)を使用したことがあるかもしれません。これらは、意味的な関係を持つグラフの良い例です。これらのグラフでは、ドキュメントはノードで表され、エッジはそれらの意味的な関係を表します。
LitmapsとConnected Papers
このドキュメントグラフを構築した後、GNN(Graph Neural Networks)を使用してメッセージパッシングを行い、隣接ノードに基づいてノードの特徴を更新します。これにより、関連するドキュメントによって提供される文脈から学習することができ、クエリへの直接的な接続が弱い場合でも関連コンテンツを特定する能力が向上します。
# Abstract Meaning Representation(AMR)
ドキュメントグラフの構築とメッセージパッシングメカニズムは、GNNのユーザーには馴染みのあるものですが、Abstract Meaning Representation(AMR) (opens new window)についても触れる価値があります。
AMRは、文の意味を抽象的に捉えた意味グラフの表現であり、文法的な詳細ではなく、表現された概念とその関係に焦点を当てています。AMRグラフは、一般的な自然言語の形式と比較して、より構造化された意味情報を持っています。RAGのためのグラフベースのドキュメント再ランキングでは、リッチな意味的および構造的情報を再ランキングプロセスにエンコードすることができるため、特に有用です。
# G-RAG
最近提案された方法で、AMRをRAGの再ランキングに活用しています。G-RAG [1] では、研究者たちはAMRを構築し、上位100のドキュメントを取得し、それらを使用してドキュメントグラフを構築します。従来のクロスエントロピー損失ではなく、G-RAGは直接関連性のランキングを最適化するためにペアワイズランキング損失を使用し、再ランキングの目標とよりよく一致します。
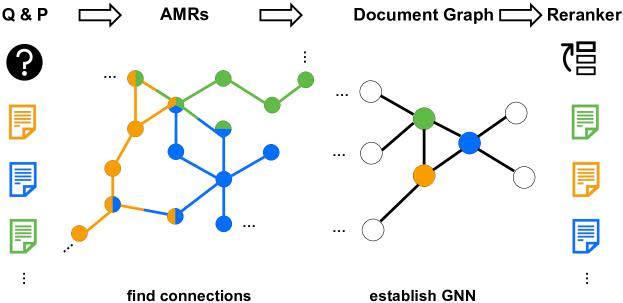
G-RAG
# MyScaleの2段階検索
MyScaleDBは、情報検索を最適化するために2段階の検索プロセスを使用しています。このプロセスは次のように構成されています。
- 初期検索:ベクトル検索などの方法を使用して、数値表現(ベクトル)に基づいて類似したドキュメントを迅速に取得します。
- 再ランキング:取得されたドキュメントを高度な技術(クロスエンコーダなど)を使用して洗練し、最も関連性の高い結果がユーザーのクエリに基づいて提示されるようにします。
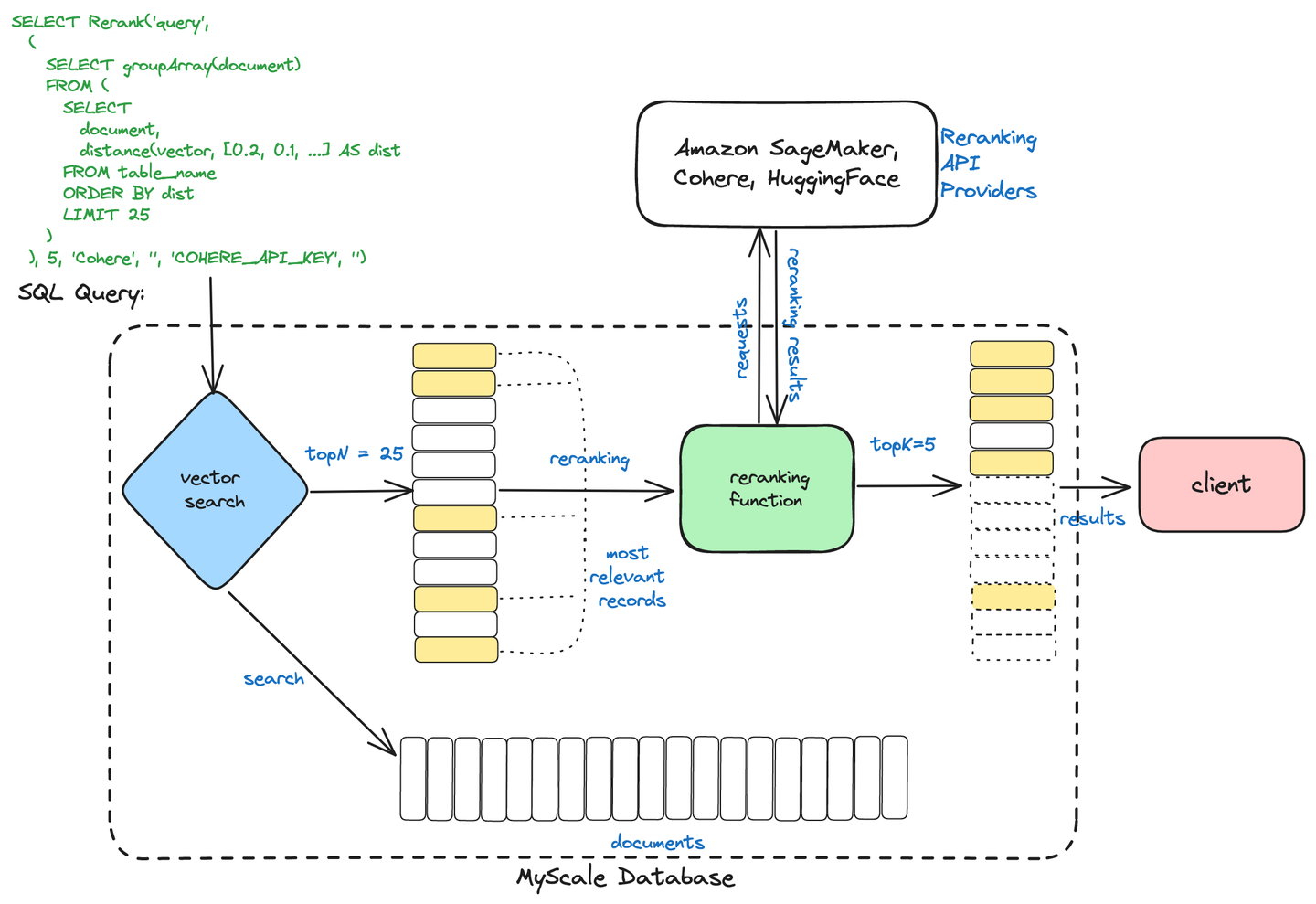
2段階検索
このアプローチにより、MyScaleDBは効率的な検索と正確なランキングを組み合わせることで、より迅速かつ正確な検索結果を提供することができます。
注意:
MyScaleの2段階検索 (opens new window)については、当社のブログをご覧ください。
# MyScaleとCohereを使用した再ランキング
最後に、具体的な例を使用して締めくくります。この例では、MyScaleベクトルデータベースを使用してRAGパイプラインでドキュメントを再ランキングします。埋め込みにはCohereを使用していますが、OpenAIやBedRockなどの他のサービスでも構いません。
from langchain_community.vectorstores import MyScale, MyScaleSettings
from langchain_cohere import CohereEmbeddings
config = MyScaleSettings(host='host-name', port=443, username='your-user-name', password='your-passwd')
index = MyScale(CohereEmbeddings(), config)
これでドキュメントをMyScaleに追加する準備が整いました。DBに追加する前に、ドキュメントを(ロードして)分割する必要があります。
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
documents = TextLoader("../../file.txt").load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
texts = text_splitter.split_documents(documents)
index.add_documents(texts)
再ランキングを適用する前に、x個のドキュメントのサブセットを取得する必要があります。
retriever = index.as_retriever(search_kwargs={"k": 20})
query = "Which place on earth is farthest away from its centre?"
docs = retriever.invoke(query)
これで再ランキングの準備が整いました。Cohereを使用した言語モデルを初期化し、CohereRerankで再ランカーを設定し、ContextualCompressionRetrieverでベースのリトリーバーと組み合わせます。このセットアップにより、文脈の関連性に基づいて検索結果を圧縮し、再ランキングします。
from langchain.retrievers.contextual_compression import ContextualCompressionRetriever
from langchain_cohere import CohereRerank
from langchain_community.llms import Cohere
llm = Cohere(temperature=0)
compressor = CohereRerank()
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"Your-query-here"
)
再ランカーを追加した後、RAGシステムの応答はより洗練され、ユーザーエクスペリエンスが向上し、使用されるトークンの数も減少します。

# 結論
RAGの重要性と広範な応用は、公然の秘密です。私たちが深く探求したadvanced RAGの技術を詳しく見てきましたが、データ駆動型の知能が可能にすることの限界を押し広げるこの分野は、急速に進化しています。このブログシリーズを通じて、クエリの最適化、ベクトル検索、チャンキング戦略、再ランキング方法、および現代のRAGシステムの基盤を形成する他の重要なコンポーネントについて詳しく説明しました。
これらの高度な概念をマスターすることで、RAGイニシアチブのフルポテンシャルを引き出すための知識とツールを手に入れました。関連情報の迅速な検索を実現するためにクエリを最適化し、先進的なベクトルインデックスと検索機能を活用することで、意思決定プロセスを本当に変革することができるRAGシステムを構築する準備が整いました。
これから先は、Retrieval Augmented Generationの分野は常に進化し続けています。警戒心を持ち、学び続け、MyScaleのような革新的なソリューションを探求するなど、進んでいきましょう。データ駆動型知能の未来は明るく、このブログシリーズを通じて得た知識を活かすことで、このエキサイティングなフロンティアの最前線に立つことができます。
高度なRAG技術についてさらに議論したい場合は、Discord (opens new window)に参加して、私たちとコミュニケーションを取ることを歓迎します。
# 参考文献
- Dong, J., Fatemi, B., Perozzi, B., Yang, L. F., & Tsitsulin, A. (2024). Don't Forget to Connect! Improving RAG with Graph-based Reranking. ArXiv. https://arxiv.org/abs/2405.18414
- Nogueira, R., Jiang, Z., & Lin, J. (2020). Document Ranking with a Pretrained Sequence-to-Sequence Model. ArXiv. https://arxiv.org/abs/2003.06713
- Dengrong Huang, Zizhong Wei, Aizhen Yue, Xuan Zhao, Zhaoliang Chen, Rui Li, Kai Jiang, Bingxin Chang, Qilai Zhang, Sijia Zhang, et al. Dsqa-llm: Domain-specific intelligent question answering based on large language model. In International Conference on AI-generated Content, pages 170–180. Springer, 2023.
- Xueguang Ma, Xinyu Zhang, Ronak Pradeep, and Jimmy Lin. Zero-shot listwise document reranking with a large language model. arXiv preprint arXiv:2305.02156, 2023
- Xueguang Ma, Liang Wang, Nan Yang, Furu Wei, and Jimmy Lin. Fine-tuning llama for multi-stage text retrieval. arXiv preprint arXiv:2310.08319, 2023.
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS. https://arxiv.org/abs/2005.11401
- Zhang, L., Zhang, Y., Long, D., Xie, P., Zhang, M., & Zhang, M. (2023). A Two-Stage Adaptation of Large Language Models for Text Ranking. ArXiv. https://arxiv.org/abs/2311.16720
- Cunxiang Wang, Zhikun Xu, Qipeng Guo, Xiangkun Hu, Xuefeng Bai, Zheng Zhang, and Yue Zhang. Exploiting Abstract Meaning Representation for open-domain question answering. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Findings of the Association for Computational Linguistics: ACL 2023, pages 2083–2096, Toronto, Canada, July 2023b. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-acl.131.



