
AIの台頭により、ベクトルデータベースは大規模な構造化および非構造化データを効率的に処理するために重要な役割を果たしています。その中でも、ClickHouse上に構築されたSQLベクトルデータベースであるMyScaleDBは、開発者にとって最適な選択肢として浮上しています。SQLと完全に互換性があり、MyScaleDBは学習コストを最小限に抑えながら生成的AIアプリケーションを構築することができます。さらに、ローコードプラットフォームと組み合わせることで、開発の障壁をさらに低くすることができます。
最近、MyScaleDBはトップのローコードプラットフォームであるDronaHQと統合され、よりアクセスしやすい開発体験を提供しています。このブログでは、MyScaleDBの強力なベクトル検索を使用してDronaHQ上でスマートなレストランのレコメンデーションシステムを作成する方法を紹介します。これにより、ユーザーエクスペリエンスを向上させるためのパーソナライズされた提案を提供します。
# DronaHQとは
DronaHQ (opens new window)は、シンプルなマイクロツールからダッシュボード、データベースGUI、管理パネル、承認アプリ、カスタマーサポートツールなどの堅牢なエンタープライズグレードのアプリケーションまで、あらゆるスキルレベルの開発者が統合されたアプリケーション開発プラットフォームです。このプラットフォームでは、開発者はさまざまなデータベースの上に簡単にマルチスクリーンアプリケーションを構築し、サードパーティのAPIを統合し、堅牢なセキュリティ機能、豊富なUI要素、柔軟な共有オプションを利用し、デプロイ後のアプリケーションを活用することができます。DronaHQは、バックエンドの手間をかけずにアプリケーションを開発するためのエンジニアリング時間を最小限に抑えます。プラットフォームの要点の1つは、ドラッグアンドドロップ機能ですが、開発者は自由にコードを書き、ライブラリ関数を使用してUIとカスタマイズを設計し、ロジックを書き、デバッグすることができます。
DronaHQのローコードプラットフォームを使用すると、ユーザーフレンドリーなアプリビルディングツールと統合されたベクトル検索などの高度なデータ機能を統合した包括的なアプリケーションを作成することができます。この記事の最後まで読むと、次のことを学ぶことができます。
- ベクトル検索の基礎とその応用の理解
- より効果的な検索のためのMyScaleDBでのデータの準備と管理
- MyScaleDBをDronaHQとシームレスに統合して、位置情報に基づいたレストランのレコメンデーションアプリを構築する方法
- DronaHQプラットフォーム内で高度な検索機能を活用した強力なアプリを迅速に作成して展開する方法
# ベクトル検索とは
ベクトル検索 (opens new window)は、データをベクトルに変換し、多次元空間で表現する高度な技術です。各ベクトルはデータの主要な特徴を表し、コサイン類似度を使用してこれらのベクトルを比較します。これにより、データポイント間の概念的または文脈的な類似性を判断することができます。具体的な単語が一致しなくても、ベクトル検索は特定のキーワードに一致する従来のキーワード検索を超えて、意味的に類似したアイテムを見つけるのに特に役立ちます。
レストランのレコメンデーションシステムでは、ベクトル検索を使用して、雰囲気、ユーザーレビュー、ダイニングエクスペリエンスなどのさまざまな要素をベクトル表現に変換し、これらの要素を比較します。これにより、料理の種類や価格帯などの特定の基準に一致するだけでなく、全体的なダイニングエクスペリエンスの点で類似したレストランを特定することができます。
# MyScaleDBでのデータの準備
このブログでは、オープンソースの高性能SQLベクトルデータベースであるMyScaleDB (opens new window)を使用します。MyScaleDBは、なじみのあるSQLクエリ言語を使用して高度なベクトル検索機能を提供するように設計されています。ClickHouseの上に構築されたMyScaleDBは、大規模なAIアプリケーションに最適な選択肢となるように、構造化およびベクトル化されたデータを効率的に管理することができます。
このプロジェクトでMyScaleDBを選択する主な理由の1つは、Multi-Scale Tree Graph (MSTG) (opens new window)インデックスアルゴリズムです。このアルゴリズムは、データの高速なベクトル操作と効率的なデータのストレージを提供し、コストとパフォーマンスの両面で専門のベクトルデータベースを上回ります。最も重要なことは、MyScaleDBでは新しいユーザーが無料で最大5百万のベクトルを保存することができるため、このMVPアプリケーションには何も支払う必要がないということです。
# MyScaleDBクラスタの作成
DronaHQアプリケーションでMyScaleDBを使用するためには、まずMyScaleDBクラウド上でデータストレージ用のクラスタを作成する必要があります。そのためには、MyScaleDBコンソール (opens new window)にアクセスし、登録してログインし、右上隅の「New Cluster」ボタンをクリックしてMyScaleクラスタを作成します。
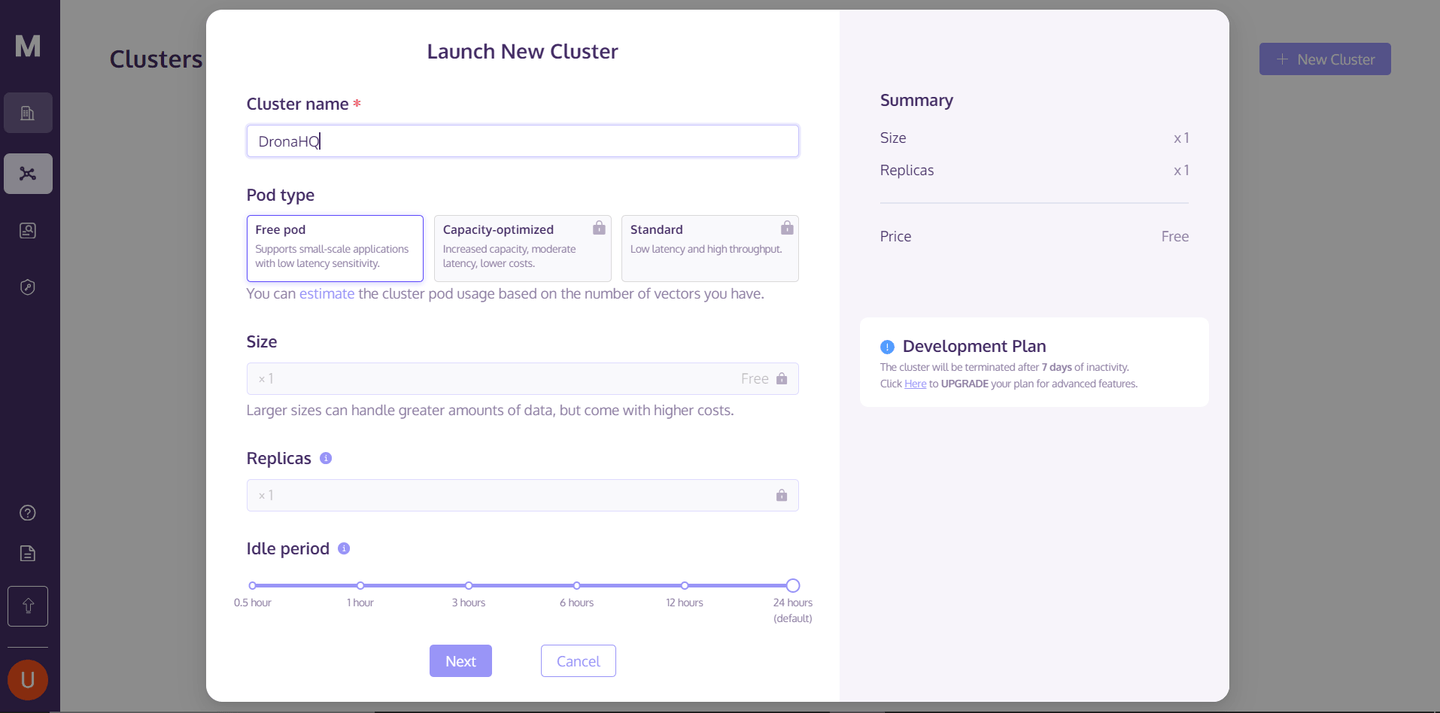
クラスタ名を入力した後、「Next」ボタンをクリックし、クラスタの起動が完了するのを待ちます。
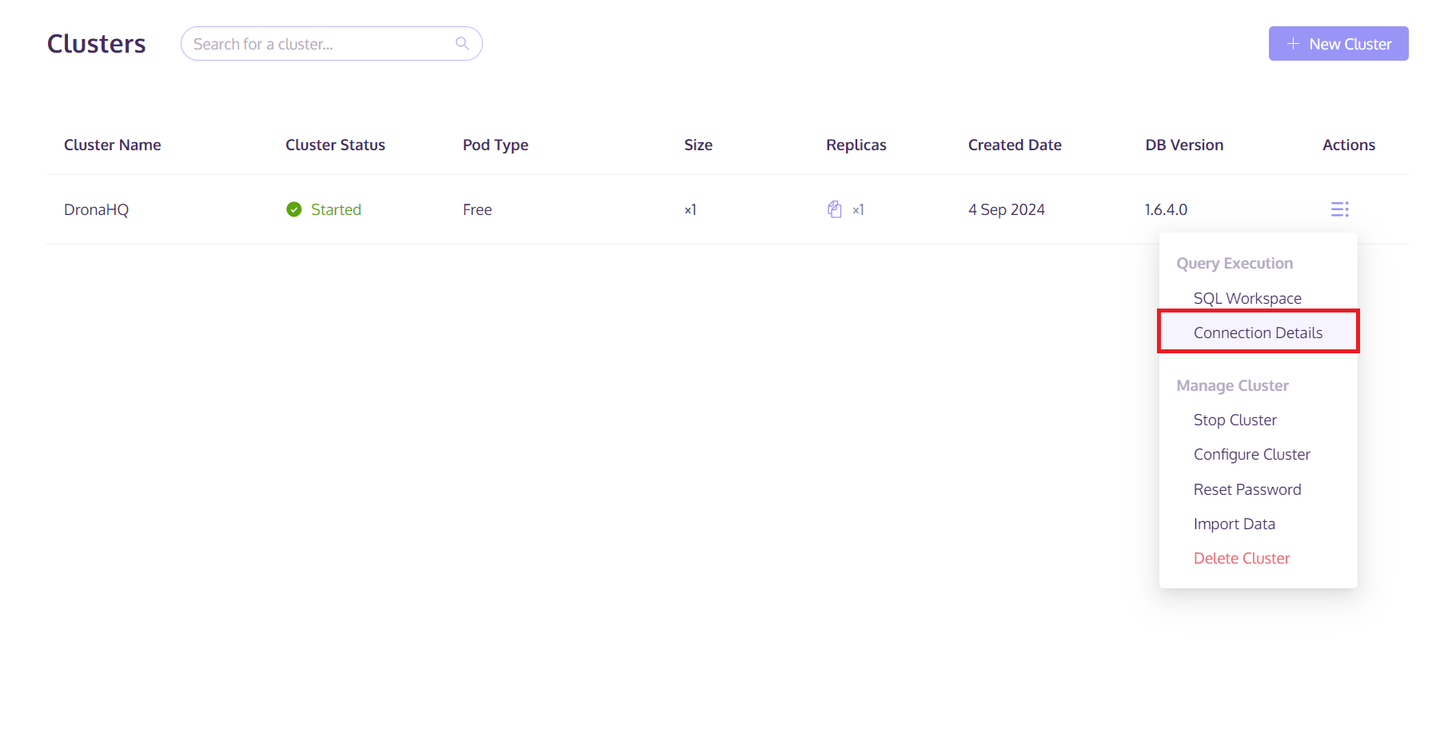
クラスタが作成されたら、クラスタの右側にある「Actions」ボタンをクリックします。次に、ポップアップリストから「Connection Details」を選択します。Pythonタブからホスト/ポート/ユーザー名/パスワードの情報を保存します。この情報は、MyScaleDBクラスタへのアクセスとデータの保存に使用されます。
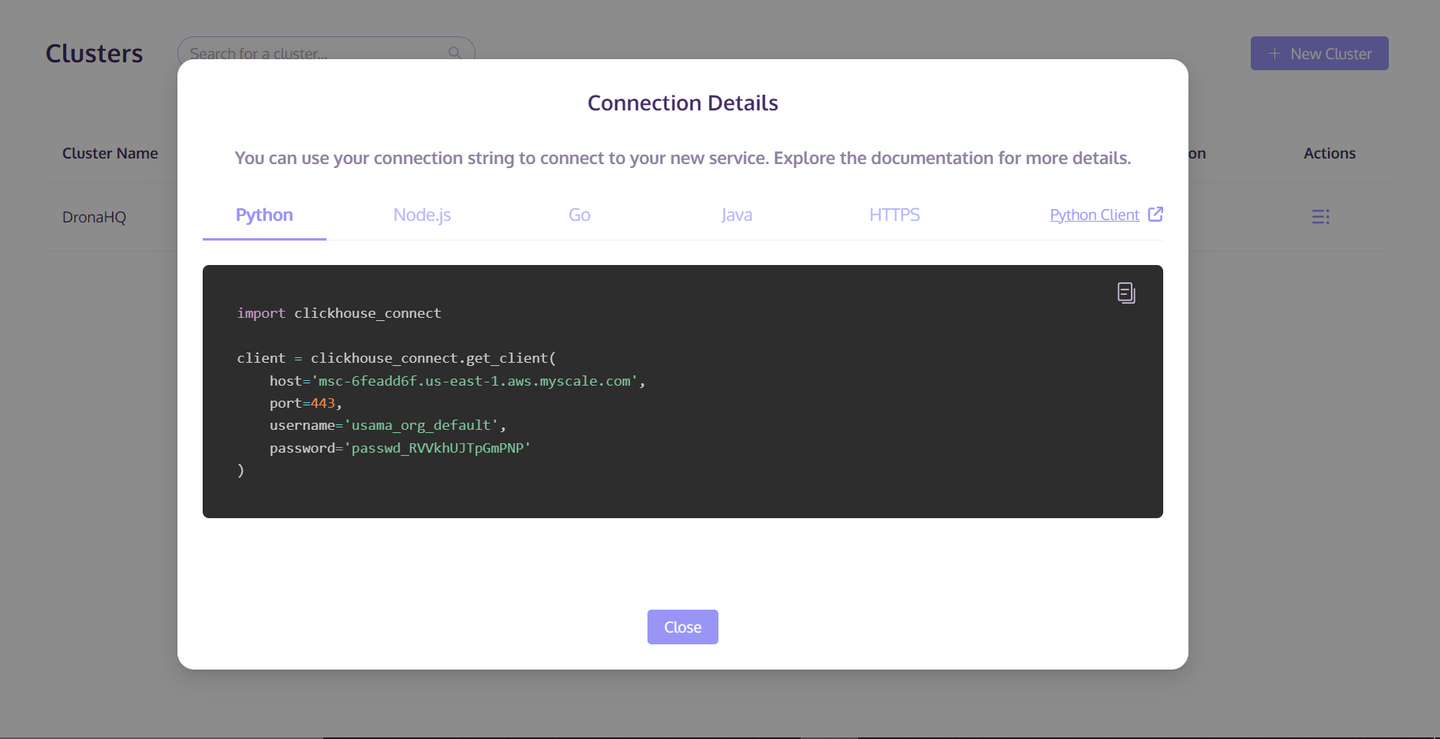
これで、MyScaleDBの設定が完了したので、次はこの新しく作成したクラスタにデータを準備して保存することです。
# データの準備と保存
このブログでは、特定の要件に合わせて作成された合成データを使用します。このデータは、大規模な言語モデル(LLM)を使用して作成されたものです。このデータセットには、対応するGitHubリポジトリ (opens new window)からアクセスできます。
# 依存関係のインストール
まず、必要なライブラリをインストールする必要があります。次の行のコメントを解除して実行し、必要なパッケージをインストールします。ライブラリがシステムにインストールされている場合は、このステップをスキップできます。
# pip install sentence-transformers clickhouse_connect
# データの読み込み
まず、GitHubから取得したデータをローカルディレクトリに読み込む必要があります。ファイルへのパスが正しく指定されていることを確認してください。以下はデータを読み込む方法です。
import pandas as pd
# CSVファイルからデータを読み込む
df_restaurants = pd.read_csv("restaurants.csv")
df_users = pd.read_csv("users.csv")
df_reviews = pd.read_csv("reviews.csv")
ここでは、3つのCSVファイルを使用します。
restaurants.csv:レストランの詳細(名前、評価、料理、平均価格、場所など)を含んでいます。reviews.csv:ユーザーレビューを含み、どのユーザーがどのレストランにどの評価を付けたかを指定しています。users.csv:ユーザーの好み(好きな料理、平均評価、平均支出など)を保存しています。
# 埋め込みモデルの読み込み
次に、テキストデータの埋め込みを生成するために、Huggingfaceの埋め込みモデルを使用します。使用するモデルは無料であり、sentence-transformers/all-MiniLM-L6-v2という名前です。
import torch
from transformers import AutoTokenizer, AutoModel
# 埋め込みのためのトークナイザとモデルの初期化
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
def get_embeddings(texts: list) -> list:
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt", max_length=512)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings.numpy().tolist()
get_embeddingsメソッドは、文字列のリストを受け取り、それらの埋め込みを返します。
# 埋め込みの生成
次に、データの特定のフィールド(レストランの料理タイプ、ユーザーの好みの料理、各レストランのレビュー)の埋め込みを生成します。これらの埋め込みは、後で類似性検索を実行するために重要です。
# レストランの料理タイプとユーザーの好みの料理の埋め込みを生成する
df_restaurants["cuisine_embeddings"] = get_embeddings(df_restaurants["cuisine"].tolist())
df_users["cuisine_preference_embeddings"] = get_embeddings(df_users["cuisine_preference"].tolist())
# レビューの埋め込みを生成する
df_reviews["review_embeddings"] = get_embeddings(df_reviews["review"].tolist())
# MyScaleDBとの接続
MyScaleDBクラスタに接続するために、クラスタ作成プロセス中にコピーした接続の詳細を使用します。これにより、MyScaleDBインスタンスに接続を確立することができます。
import clickhouse_connect
# MyScaleDBに接続する
client = clickhouse_connect.get_client(
host='your_host_name_here',
port=443,
username='your_username_here',
password='your_password_here'
)
# テーブルの作成
次のステップは、データを保存するためのMyScaleDBクラスタ内にテーブルを作成することです。アプリケーションのニーズに基づいて、ユーザー、レストラン、レビューのためのテーブルを作成します。
# ユーザーテーブルの作成
client.command("""
CREATE TABLE default.users (
userId Int64,
cuisine_preference String,
rating_preference Float32,
price_range Int64,
latitude Float32,
longitude Float32,
cuisine_preference_embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(cuisine_preference_embeddings) = 384
) ENGINE = MergeTree()
ORDER BY userId
""")
# レビューテーブルの作成
client.command("""
CREATE TABLE default.reviews (
userId Int64,
restaurantId Int64,
rating Float32,
review String,
review_embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(review_embeddings) = 384
) ENGINE = MergeTree()
ORDER BY userId
""")
# レストランテーブルの作成
client.command("""
CREATE TABLE default.restaurants (
restaurantId Int64,
name String,
cuisine String,
rating Float32,
price_range Int64,
latitude Float32,
longitude Float32,
cuisine_embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(cuisine_embeddings) = 384
) ENGINE = MergeTree()
ORDER BY restaurantId
""")
# テーブルへのデータの挿入
テーブルが作成されたら、挿入メソッドを使用してこれらのテーブルにデータを挿入することができます。
# ユーザーテーブルにデータを挿入する
client.insert("default.users", df_users.to_records(index=False).tolist(), column_names=df_users.columns.tolist())
# レビューテーブルにデータを挿入する
client.insert("default.reviews", df_reviews.to_records(index=False).tolist(), column_names=df_reviews.columns.tolist())
# レストランテーブルにデータを挿入する
client.insert("default.restaurants", df_restaurants.to_records(index=False).tolist(), column_names=df_restaurants.columns.tolist())
# MSTGインデックスの作成
最後に、データ内で効率的な検索を可能にするために、各テーブルにMSTGインデックスを作成します。
# ユーザーのためのMSTGインデックスを作成する
client.command("""
ALTER TABLE default.users
ADD VECTOR INDEX user_index cuisine_preference_embeddings
TYPE MSTG
""")
# レストランのためのMSTGインデックスを作成する
client.command("""
ALTER TABLE default.restaurants
ADD VECTOR INDEX restaurant_index cuisine_embeddings
TYPE MSTG
""")
# レビューのためのMSTGインデックスを作成する
client.command("""
ALTER TABLE default.reviews
ADD VECTOR INDEX reviews_index review_embeddings
TYPE MSTG
""")
これで、アプリケーションのバックエンドは完了しました。次は、DronaHQを使用してフロントエンドを構築することに焦点を当てましょう。DronaHQを使用してどのようにフロントエンドを構築するかを見てみましょう。
# DronaHQでのアプリの構築
DronaHQは、カスタムのWebおよびモバイルアプリケーションを10倍速く作成するために設計されたローコードアプリ開発プラットフォームです。事前に構築されたUIコンポーネント、データコネクタ、ワークフローオートメーションツールなどの強力なビルディングブロックを使用することで、DronaHQは開発に必要な時間と労力を大幅に削減し、複雑なフロントエンドフレームワークを扱うことなくアプリを素早く構築することができます。
フルスタックの開発者、バックエンドまたはフロントエンドの作業に特化した開発者、または開発者としての旅を始めたばかりの方でも、DronaHQを使用すると、UI要素をドラッグアンドドロップで簡単に配置し、さまざまなデータソースに接続し、印象的なアプリケーションを構築することができます。
MyScaleDBとDronaHQを統合するためには、MyScaleDBは実際にはClickHouse上で動作しているため、ClickHouseコネクタを活用することができます。以下に設定方法を示します。
- ClickHouseコネクタの選択:DronaHQで、コネクタセクションに移動し、ClickHouseコネクタを選択します。これは、MyScaleDBに接続するためのインターフェースとして機能します。

MyScaleDBの認証情報の入力:MyScaleDBインスタンスの必要な詳細を入力します。
- データベースURL:MyScaleDBインスタンスがホストされているエンドポイント。
- ユーザー名とパスワード:認証情報。
- データベース名:デフォルトの場合は
defaultに設定しますが、セットアップによっては異なるデータベースが指定されている場合があります。
テストと保存:認証情報を入力した後、接続が正常に確立されていることを確認するために「テスト」をクリックします。テストが成功した場合は、設定を保存します。これにより、DronaHQにMyScaleDBとの連携が可能なコネクタが作成されます。
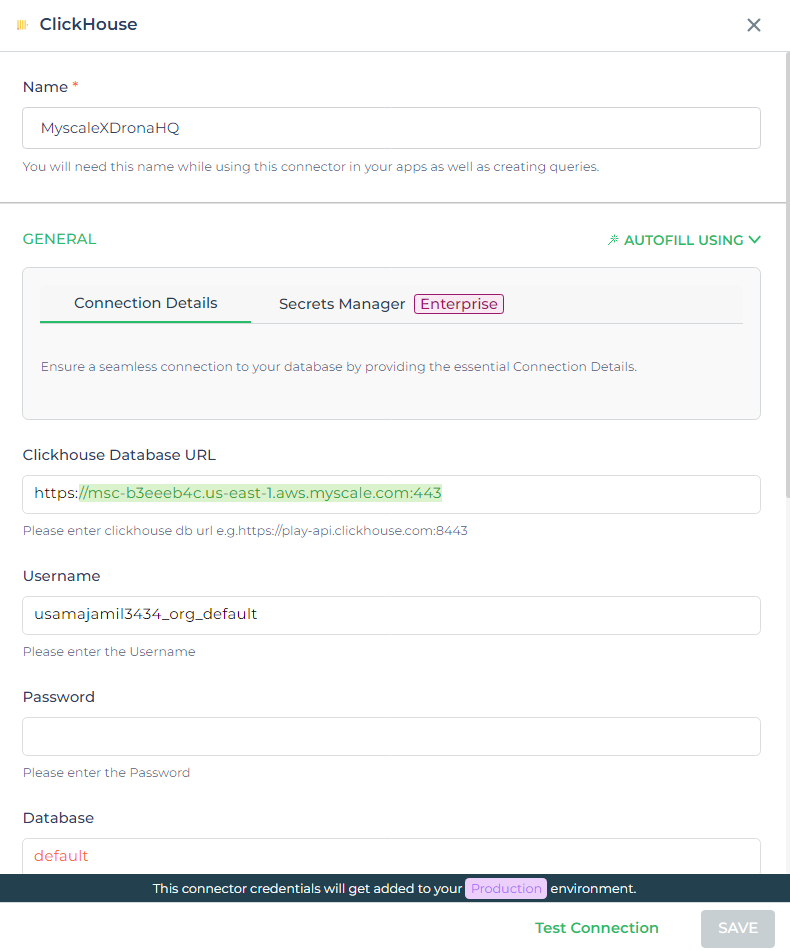
これらの手順に従うことで、MyScaleDBとDronaHQを統合するための完全に機能するコネクタがDronaHQに作成され、MyScaleDBとのやり取り、データの取得、高度なデータベース機能をアプリケーションに組み込むことができます。
# レストランファインダーのためのクエリの作成
DronaHQでMyScaleDBコネクタが設定されたら、ユーザーの入力に基づいてレストランのレコメンデーションを取得するためのクエリを作成することができます。クエリは、ユーザーの料理の好みと価格帯に一致するレストランのリストを動的に取得するために使用されます。
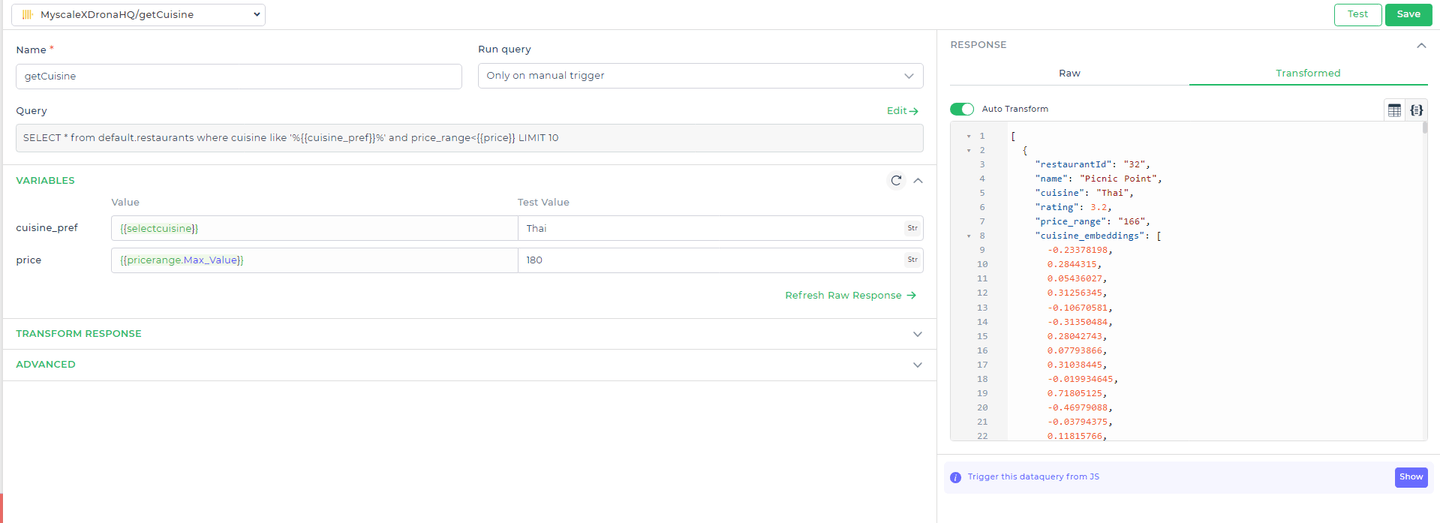
# クエリ1:初期のレストランのレコメンデーションの取得
まず、ユーザーの好みの料理タイプに一致し、指定された価格帯内にあるレストランのリストを取得する必要があります。次のクエリでこれを実現します。
クエリ:
SELECT * FROM default.restaurants
WHERE cuisine LIKE '%{{cuisine_pref}}%'
AND price_range < {{price}}
LIMIT 10;
説明:
default.restaurants:レストランデータが保存されているMyScaleDBのテーブルを参照します。cuisine LIKE '%{ { cuisine_pref } }%':この条件は、ユーザーの料理の好みに基づいて結果をフィルタリングします。{ { cuisine_pref } }は、DronaHQが実際のユーザーの入力で置き換えるプレースホルダです。price_range < { { price } }:価格帯がユーザーが指定した予算よりも低いレストランに絞り込みます。{ { price } }はユーザーが指定した予算を表すプレースホルダです。LIMIT 10:結果を上位10件に制限して、扱いやすい数のレコメンデーションを返します。
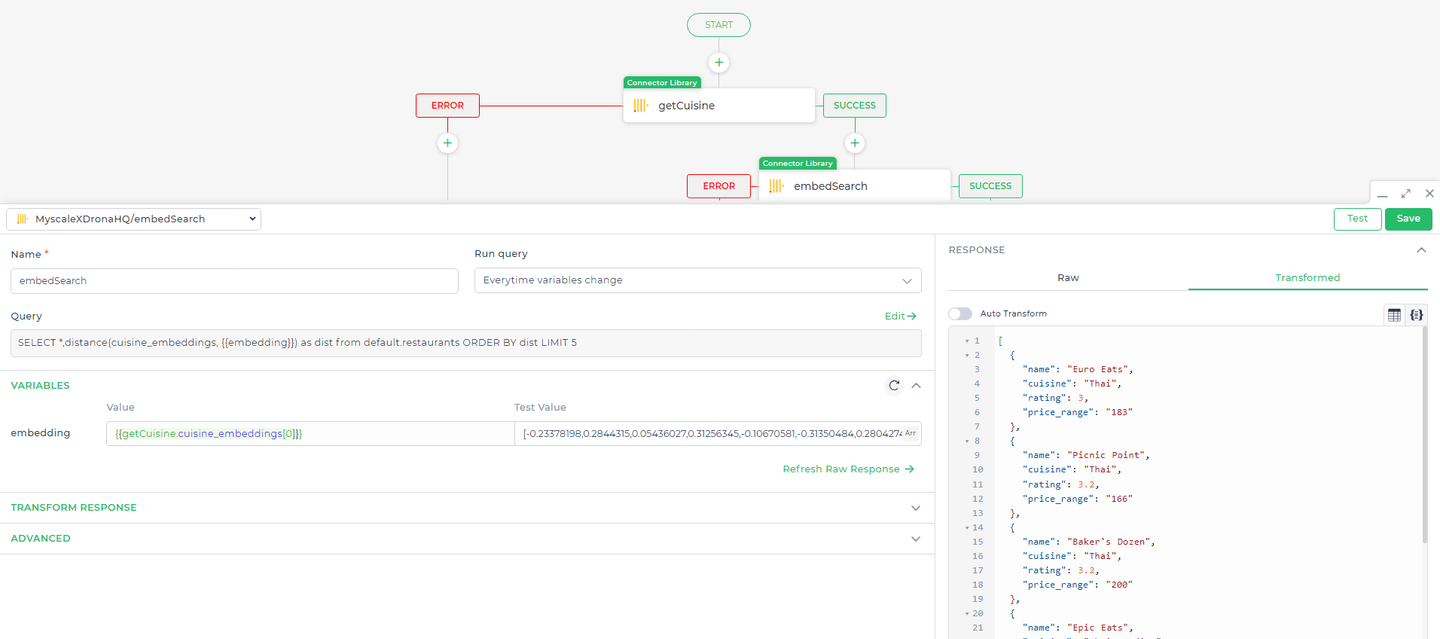
# クエリ2:ベクトル検索による高度なレコメンデーションの実行
最初のレストランのリストが表示された後、埋め込みベースの検索を使用して、初期の選択肢の特性に基づいて追加のレコメンデーションを提供したいと考えています。これにより、アプリケーションはキーワードの一致だけでなく、概念的または体験的に類似したレストランを提案することができます。
クエリ:
SELECT *, distance(cuisine_embeddings, {{embedding}}) AS dist
FROM default.restaurants
ORDER BY dist
LIMIT 5;
説明:
distance(cuisine_embeddings, { { embedding } }) AS dist:この式は、各レストランの料理のベクトル埋め込みとユーザーの好みの料理の埋め込みとの距離を計算します。{{ embedding } }は、ユーザーの料理の好みをベクトルに変換したものであり、データベースに保存されているcuisine_embeddingsと比較されます。ORDER BY dist:結果は計算された距離で並べ替えられ、最も近いマッチ(つまり、距離が最も小さいもの)が最初に表示されます。LIMIT 5:結果を上位5件に制限して、関連性の高いレコメンデーションを提供します。
これにより、標準のSQLフィルタリングとベクトル検索の組み合わせにより、正確なフィルタリングと文脈に即したレストランのレコメンデーションを提供することができます。これにより、ユーザーエクスペリエンスが向上します。
# インターフェースの設計
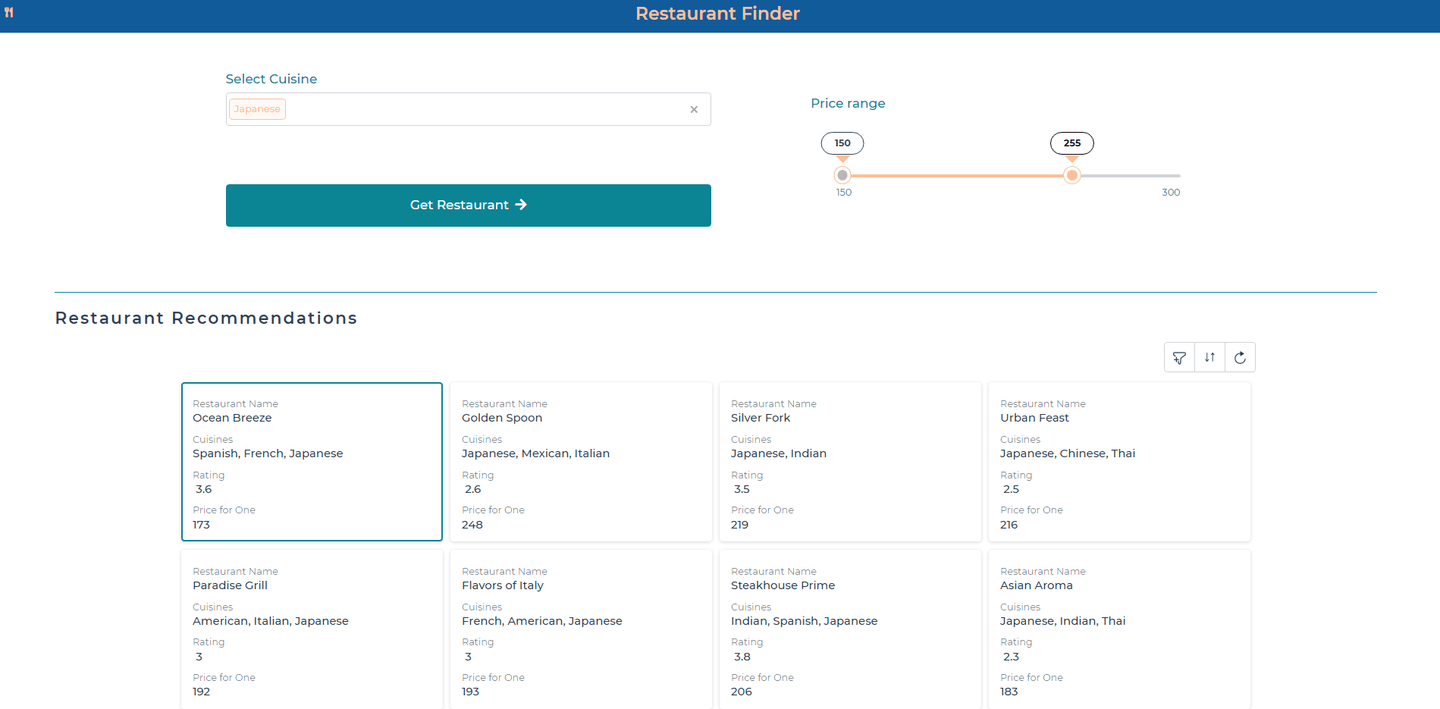
レストランファインダーを設計する際の主な焦点は、高機能なインターフェースを作成することです。DronaHQの豊富なコンポーネントライブラリを使用することで、最小限のコーディングでこれを実現することができます。
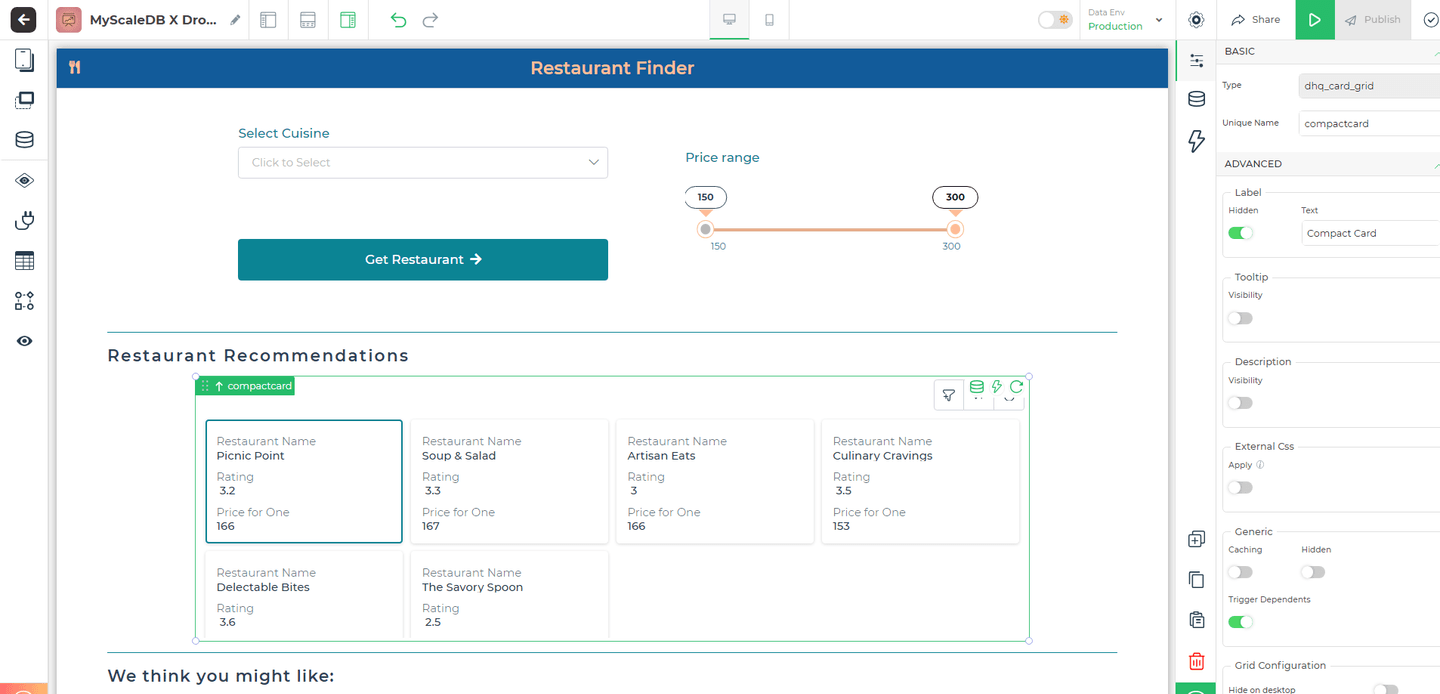
アプリケーションは、ユーザーがドロップダウンメニューから好みの料理を選択し、価格帯スライダーを調整して予算に基づいてレストランをフィルタリングすることを開始します。検索を絞り込むための即時フィードバックが提供されます。レコメンデーションは、レストランの名前、評価、食事ごとの価格が表示されるレスポンシブなカードで表示され、DronaHQのグリッドレイアウトを使用して配置されます。ユーザーエクスペリエンスを向上させるために、レコメンデーションは「レストランのレコメンデーション」と「おすすめのレストラン」のセクションに分けられ、ターゲットと探索的なオプションの両方を提供します。
# 結果を表示するためのアクションフローの構築
データベースクエリが設定され、UIが準備できたら、最後のステップは、アクションフローを確立し、これらのクエリをトリガーとして使用し、リアルタイムで結果をユーザーに表示することです。
アプリケーション内のボタンコンポーネントのアクションフロー設定に移動して、必要なコネクタアクションを追加します。これにより、クエリと対話し、結果をユーザーにリアルタイムで表示するための必要なコネクタアクションが追加されます。
- クエリとユーザーの入力のリンク
ユーザーの入力に基づいてレストランの詳細を取得するために設計されたクエリを選択します。変数セクションで、料理のタイプや価格帯などの入力フィールドを、UI内の適切なコンポーネントにリンクします。これにより、クエリがユーザーが提供したデータを使用するようになります。これらをリンクした後、アクションフローを「テスト」して正常に動作することを確認し、「保存」します。
- 埋め込みを使用して類似のオプションを検索する 最初のクエリがデータを正常に取得した後、埋め込みベースの検索をトリガーする別のコネクタアクションを設定します。この検索では、前のクエリの結果からの埋め込みデータ(特に埋め込み配列の0番目のインデックス)を使用して類似のオプションを検索します。このステップにより、ユーザーに表示される結果の関連性が向上します。
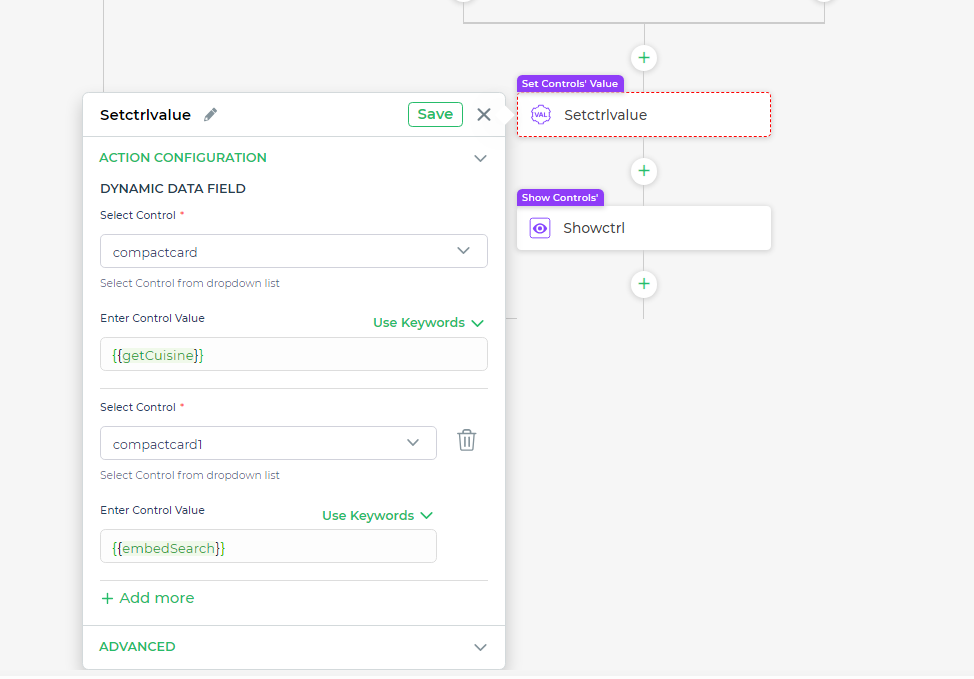
- UIでの結果の表示 最後のステップでは、コントロールの値を設定します。これにより、クエリから取得したデータが、ユーザーが対話するリストやカードなどのUIコンポーネント内で適切に表示されます。コントロールの値を正しく設定することで、ユーザーの入力に応じて動的に表示が更新されるようになります。

# 結論
MyScaleDBのベクトル検索のパワーとDronaHQのローコード環境を組み合わせることで、高度にパーソナライズされたレコメンデーションを提供する洗練されたレストランファインダー (opens new window)を作成しました。この統合により、ユーザーの好みに基づいた正確なフィルタリングだけでなく、埋め込み技術を使用して類似のダイニングオプションを提案することで、ユーザーエンゲージメントを向上させるよりスマートで直感的なアプリケーションが実現されます。
レストランファインダー以外にも、MyScaleDBとDronaHQの組み合わせは、インテリジェントなチャットボットの構築や大規模な言語モデル(LLM)の観察システムなど、さまざまなシナリオに適用することができます。ベクトルデータベースの柔軟性とローコードプラットフォームの組み合わせにより、現代のAIアプリケーションに必要な複雑さを犠牲にすることなく、開発を加速することができます。これにより、プロトタイピングのスピードが向上し、拡張性が向上し、高度な機能を日常のアプリケーションにシームレスに統合することができます。さらに、開発時間を節約することができます。
オリジナルの記事はDronaHQ (opens new window)で公開されています。



