
この記事は、MyScaleのCEOがThe AI Conference 2023 (opens new window)で行った基調講演に基づいています。
# ベクトルデータベース+LLMはGenAIアプリケーションを構築するための重要なスタックです
急速に進化するAI技術の世界で、GPTなどのLarge Language Models(LLM)とベクトルデータベースの融合は、先端的なAIアプリケーションを開発するためのインフラストラクチャスタックの重要な部分として浮上しています。この画期的な組み合わせにより、非構造化データの処理が可能となり、より正確な結果と最新情報へのリアルタイムアクセスが実現されます。OpenAIのGPT、Bard、Anthropicなどのモデルや、LLaMAなどのオープンソースモデルは、問題解決の方法を革新しました。
しかし、LLMは実世界のユースケースでは重大な制約があります。まず、トレーニングデータに含まれていなかった特定の情報や最新情報が不足している場合、モデルが間違ったまたは奇妙な応答を生成するという「幻覚」または「情報制約」と呼ばれる現象が発生する可能性があります。
ファインチューニングはLLMの振る舞いを調整しますが、ベクトルデータベースはモデルの知識を向上させることで情報制約(または幻覚)を解決するための鍵となります。そのため、LLM + ベクトルデータベースは、生成型AIアプリケーションを構築するためのキースタックとなっています。
# ジレンマ: 利便性 vs ベクトルのパフォーマンス
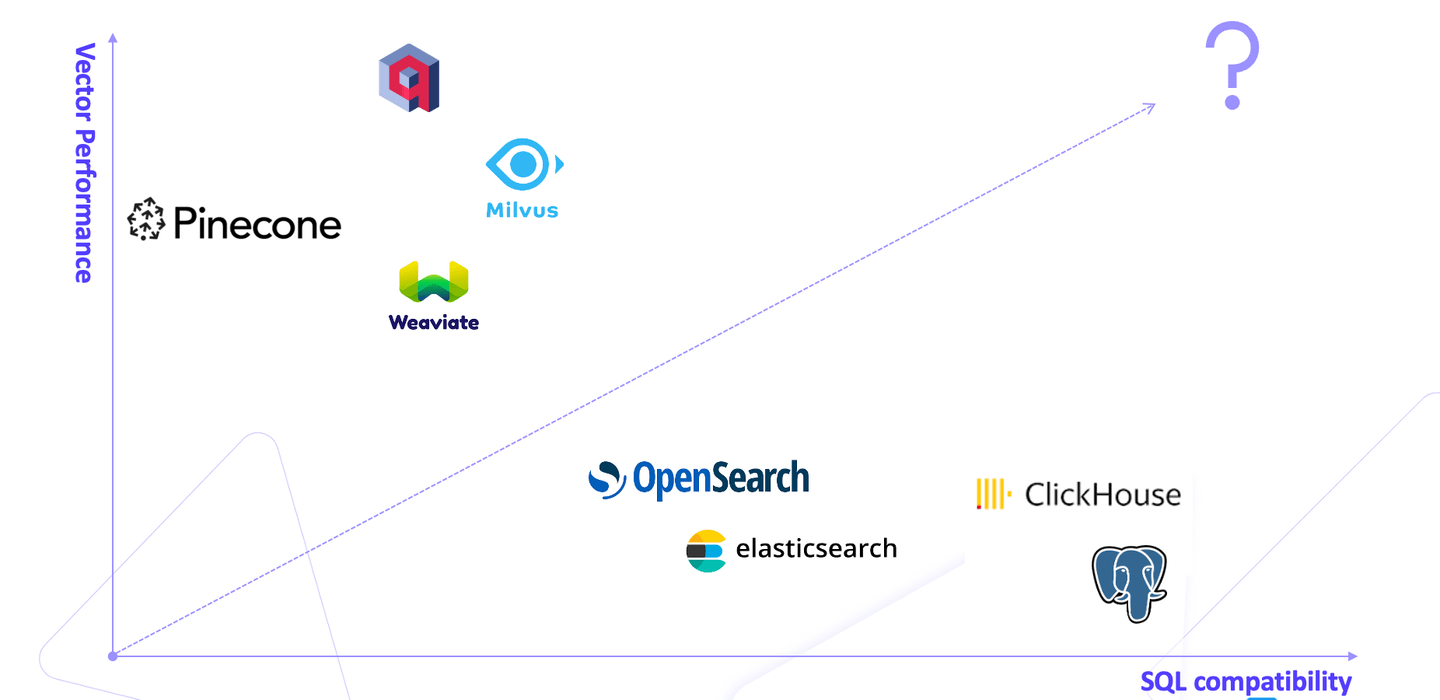
市場には、高いベクトルパフォーマンスを提供するPineconeなどの専門のベクトルデータベースと、利便性を提供するPostgreSQLなどのリレーショナルデータベースという2つのカテゴリに分類されるベクトルデータベースが溢れています。これにより、ユーザーはリレーショナルデータベースの信頼性と、専門のデータベースの高パフォーマンスなベクトル操作との間でジレンマに直面します。
ユーザーがPostgreSQLを利便性と信頼性のために使用しているが、ベクトル検索を実行する必要がある場合、PostgreSQLとPineconeの間でインターフェースすることは不便で手間がかかり、複雑さやデータの整合性の問題が生じます。
# 理想的な解決策: MyScale - リレーショナルベクトルデータベース
ここで、MyScale (opens new window)が登場します。MyScaleは、従来のリレーショナルデータベースと高パフォーマンスなベクトルデータベースのギャップを埋める解決策として機能します。Milvus、Qdrant、Weaviateなどの専用のベクトルデータベースとは異なり、MyScaleはオープンソースのSQL互換のClickHouseデータベース上に構築されており、ユーザーはSQLを使用してベクトル検索を実行できるため、異なるタイプのデータベース間を移動する手間が省けます。
リレーショナルデータベースはベクトルデータベースと同等のパフォーマンスを提供できないと広く考えられていますが、MyScaleはこの誤解を打ち破ります。MyScaleは、ユーザーが直面するジレンマに対してバランスの取れた最適化されたソリューションを提供します。専門のベクトルデータベースを凌駕し、リレーショナルデータベースのすべての利点を保持しながら、高パフォーマンスを実現します。

これは始まりに過ぎません!
MyScaleは、アルゴリズムとシステムエンジニアリングの革新的な連携により、構造化データとベクトルをシームレスに統合します。他のベクトルデータベースがコアアルゴリズムとしてIVFやHNSWを使用するのに対し、私たちは独自のアルゴリズムを開発しました。ユーザーは、非常に高いパフォーマンスで構造化データとベクトル埋め込みをベクトル化して検索することができます。
# ユースケース: MyScaleのポテンシャルを引き出す
次に、SQL+ベクトルの利点を説明する2つのユースケースを考えてみましょう。
# 1. BitCap - MyScaleによる複雑なクエリの実行
最初のユースケースは、著名なデジタル資産管理会社であるBitCapのものです。彼らは、大量のデータに対して特定のデータ型(例:タイムスタンプ)でフィルタリングしながらベクトル検索を実行する必要がありました。
このシナリオでは、データの規模が膨大であり、BitCapは正確なフィルタ検索のためにSQL構文を使用する能力が必要でした。ベクトル検索だけでなく、フィルタ検索のパフォーマンスも多くの実世界のアプリケーションにとって非常に重要です。さらに、BitCapは、Langchainとのソリューションの統合や、セルフクエリやその他の要求のサポートが必要でした。
MyScaleは、彼らがすべての要件を1つのクエリで満たすことができるようにしました。そのため、他の代替手段と比較して、MyScaleはBitCapにとって最良の選択肢です。利用が非常に簡単であり、高いパフォーマンスを発揮します。
# 2. MyScaleは学術ユーザーに最適なコスト効率を提供します
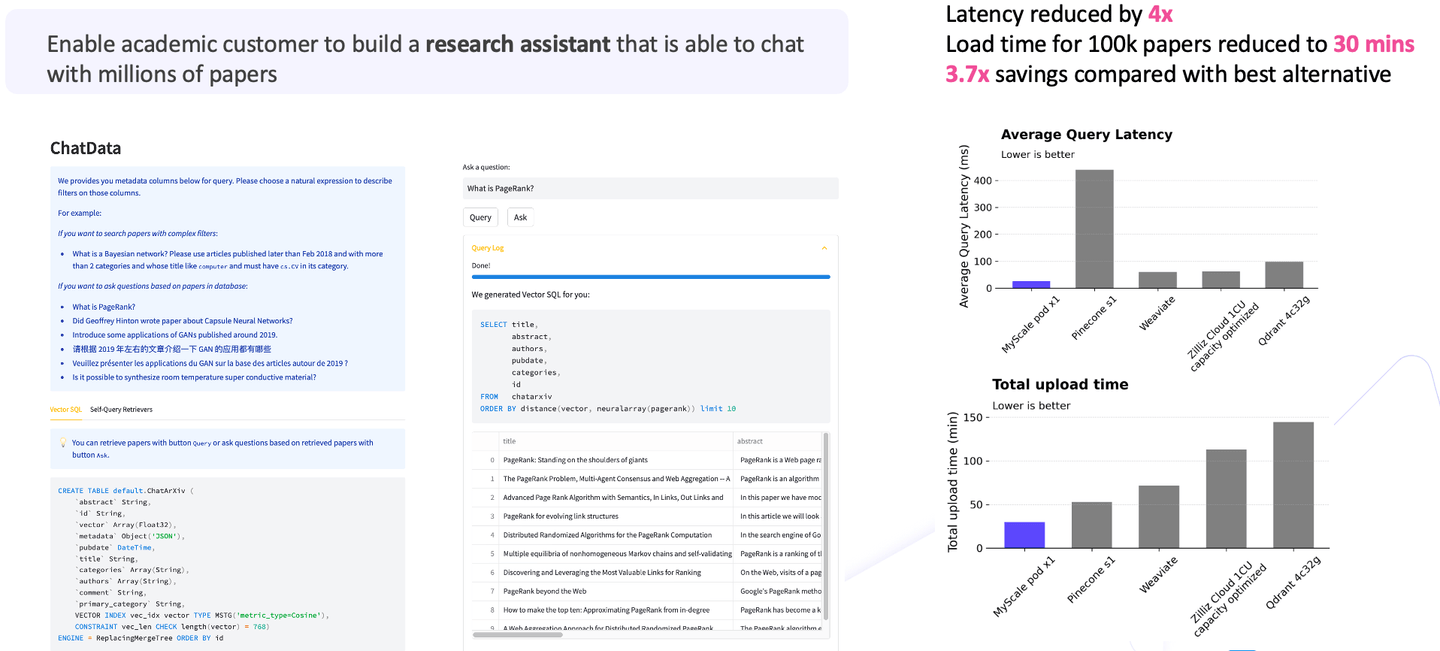
2番目のユースケースでは、学術ユーザーが数百万の論文とチャットするための研究アシスタントを作成するのを支援しました。このシナリオでは、100万件の研究論文を取り込み、これらの論文を使用して質問応答の機能を実現する必要がありました。
膨大なデータ量を考慮すると、コストを比較すると、大規模言語モデルは全体のコストの80〜90%を占めます。同時に、ベクトル検索は初期要件の重要な部分を形成します。そのため、ベクトル検索を考慮に入れると、他のオプションと比較して (opens new window)、MyScaleはレイテンシを4倍、ロード時間を30分削減し、総コスト削減は他のオプションと比較して3倍以上です。
図からわかるように、MyScaleは高いパフォーマンス、低いレイテンシ、優れたコスト効率を誇っています。これらの成果は、大規模なアプリケーションを扱う際に特に注目に値します。
これらのユースケースから、この課題に効果的に対処するためにはリレーショナルデータベースが必要であることが明確になります。そして、それに最高のベクトル機能を備えることで、可能性が広がります。

# パフォーマンス、コスト、品質の最適化の可能性は非常に大きいです
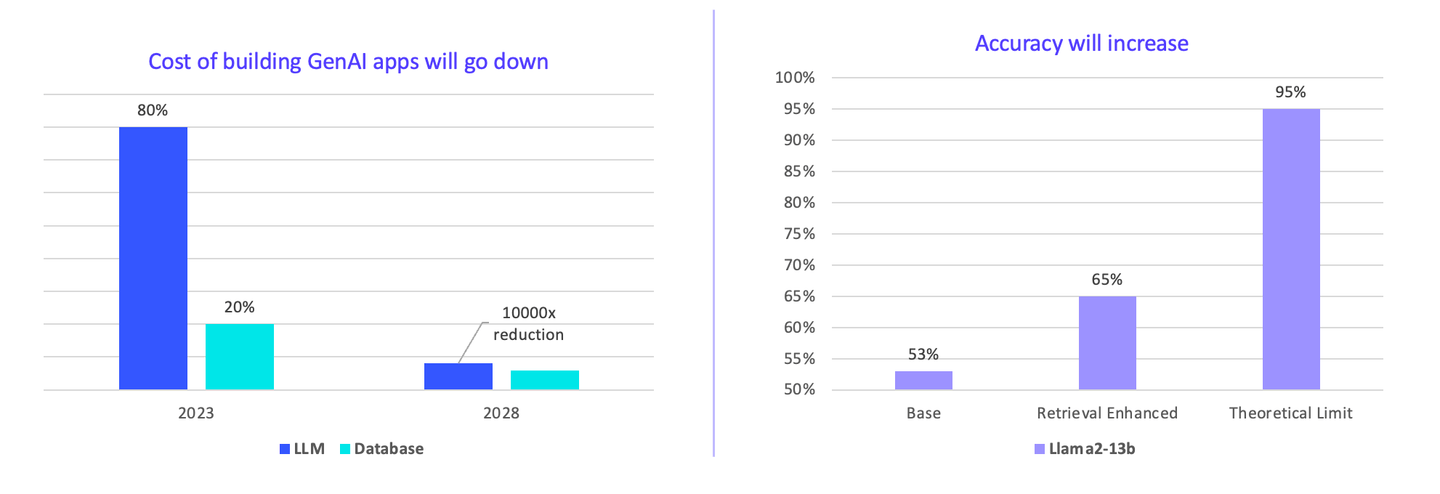
私は現在、企業がAIに過剰に支払っていると考えています。LLMは総コストの80〜90%を占めています。しかし、将来的には、アプリケーションの構築コストが低下するでしょう。私たちは合意によって価格をより速く下げることができます。コスト削減の余地は10000倍あります。
これはどのように可能なのでしょうか?
- 商用APIを使用する代わりに独自のモデルをホストすることで、コストを10倍削減できます。
- 高度なキャッシングシステムにより、さらに10倍の削減が可能です。
- その他の技術によって、合わせて100倍の削減が可能です。
これらの技術を知っている人は皆ありません。
さらに、ベクトル検索の精度は向上する可能性があります。現在のベースモデルはLlama2ですが、ベクトルデータベースプラグインを使用することで、精度が53%から65%に大幅に向上します。
注意:
データベースは既にトレーニングセットに含まれていますが、ベクトルデータベースを使用することでパフォーマンスが大幅に向上します。
もしもっと大きなベクトルデータベースを使用すれば、理論的な限界ははるかに高くなります。LLMのみを提供するためにGPUを使用する場合と比較して、コストははるかに低くなります。これが私たちが進むべき将来の方向だと考えています。
# 未来
未来に目を向けましょう:
SQL+ベクトルリレーショナルデータベースは、GenAIアプリケーションを強化する画期的なアプローチを表しています。MyScaleは、リレーショナルデータベースとベクトルデータベースのギャップを埋め、利便性と高性能を提供することで、リレーショナルデータベースがベクトルパフォーマンスの面で専門のデータベースを凌駕できることを示しています。MyScaleは、可能性を再定義し、コストを削減することで、AIアプリケーションがこれまで以上にアクセス可能で強力になる未来の道を切り拓いています。コスト削減と精度向上の余地は非常に大きく、それが私たちの進むべき方向です。 もし質問がある場合や私たちの提供に興味がある場合は、お気軽にDiscord (opens new window)でお問い合わせいただくか、MyScaleをTwitter (opens new window)でフォローしてください。
ありがとうございました!



