
データベースの初期の段階では、データは基本的なテーブルに保存されていました。この方法は簡単でしたが、データの量が増えるにつれて、情報の管理と検索が困難で遅くなりました。その後、リレーショナルデータベースが導入され、データの保存と処理方法が改善されました。
リレーショナルデータベースにおける重要な技術の一つがインデックス付けです。これは、図書館に本を保存する方法と非常に似ています。図書館全体を探すのではなく、必要な本が置かれている特定のセクションに直接移動します。データベースのインデックス付けも同様に機能し、必要なデータを見つけるプロセスを高速化します。
このブログでは、ベクトルインデックスの基礎と、異なる技術を使用してその実装方法について説明します。
# ベクトル埋め込みとは
ベクトル埋め込みとは、画像、テキスト、音声などを数値的な表現に変換したものです。簡単に言えば、各アイテムに対して特性や意味を捉えた数学的なベクトルが作成されます。これらのベクトル埋め込みは、計算システムにより理解しやすく、機械学習モデルと互換性があり、異なるアイテム間の関係や類似性を理解するのに役立ちます。
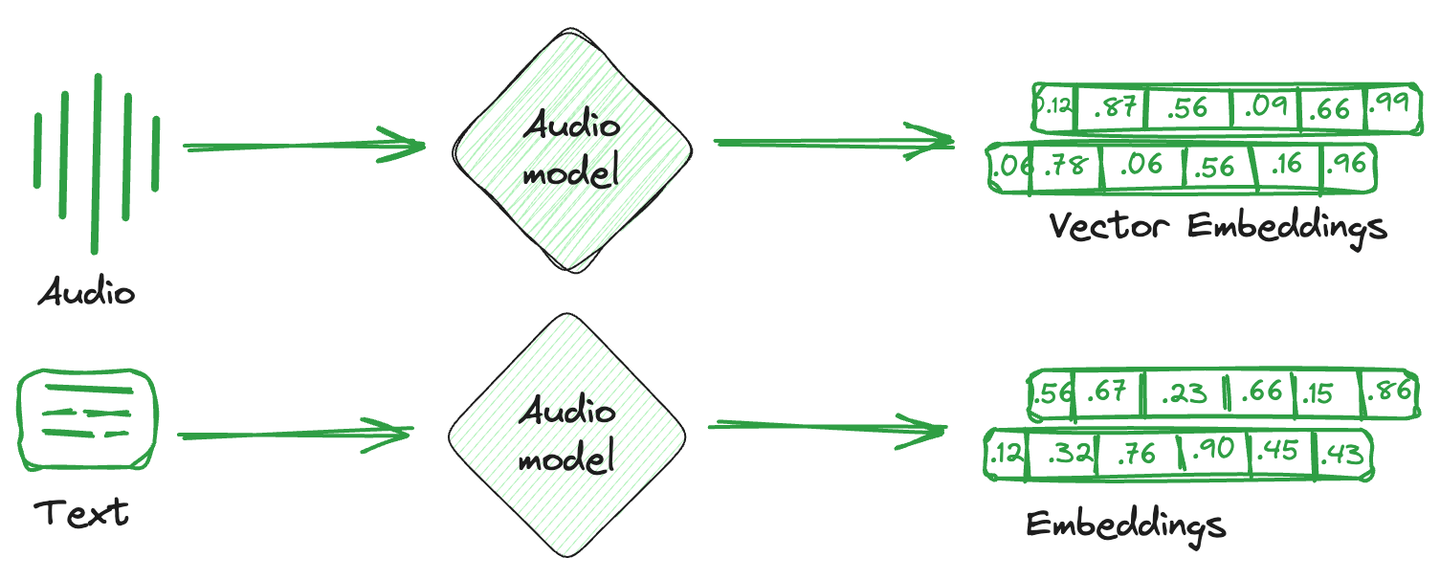
これらの埋め込みベクトルを保存するために使用される専用のデータベースは、ベクトルデータベースと呼ばれます。これらのデータベースは、埋め込みの数学的な特性を利用して、類似したアイテムを一緒に保存することができます。類似したベクトルを一緒に保存し、異なるベクトルを分離するためにさまざまな技術が使用されます。これらがベクトルインデックスの技術です。
# ベクトルインデックスとは
ベクトルインデックスは、データを保存するだけでなく、ベクトル埋め込みを知的に整理して検索プロセスを最適化することに関わるものです。この技術は、高次元のベクトルを検索可能で効率的な方法で整理するために高度なアルゴリズムを使用します。この整理はランダムではなく、類似したベクトルがグループ化されるように行われます。ベクトルインデックスにより、大規模で複雑なデータセットの検索において、迅速かつ正確な類似性検索やパターンの特定が可能になります。
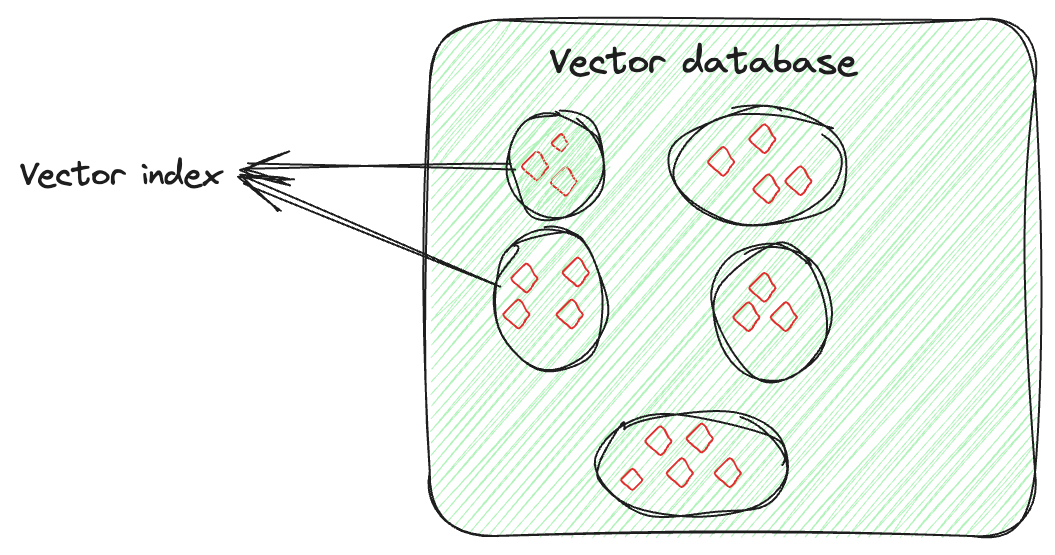
例えば、各画像に対して特徴を捉えたベクトルがあるとします。ベクトルインデックスは、これらのベクトルを類似した画像を見つけやすいように整理します。それぞれの人の画像を個別に整理しているかのように考えることができます。したがって、特定の人物の特定のイベントの写真が必要な場合、すべての写真を検索するのではなく、その人物のコレクションだけを見て簡単に画像を見つけることができます。
# 一般的なベクトルインデックスの技術
特定の要件に基づいてさまざまなインデックス技術が使用されます。いくつかについて説明しましょう。
# Inverted File (IVF)
これは最も基本的なインデックス技術です。K-meansクラスタリングなどの技術を使用して、データ全体を複数のクラスタに分割します。データベースの各ベクトルは特定のクラスタに割り当てられます。これにより、ユーザーは検索クエリを非常に高速に行うことができます。新しいクエリが来た場合、システムはデータセット全体を走査するのではなく、最も近いまたは最も類似したクラスタを特定し、それらのクラスタ内の特定のドキュメントを検索します。
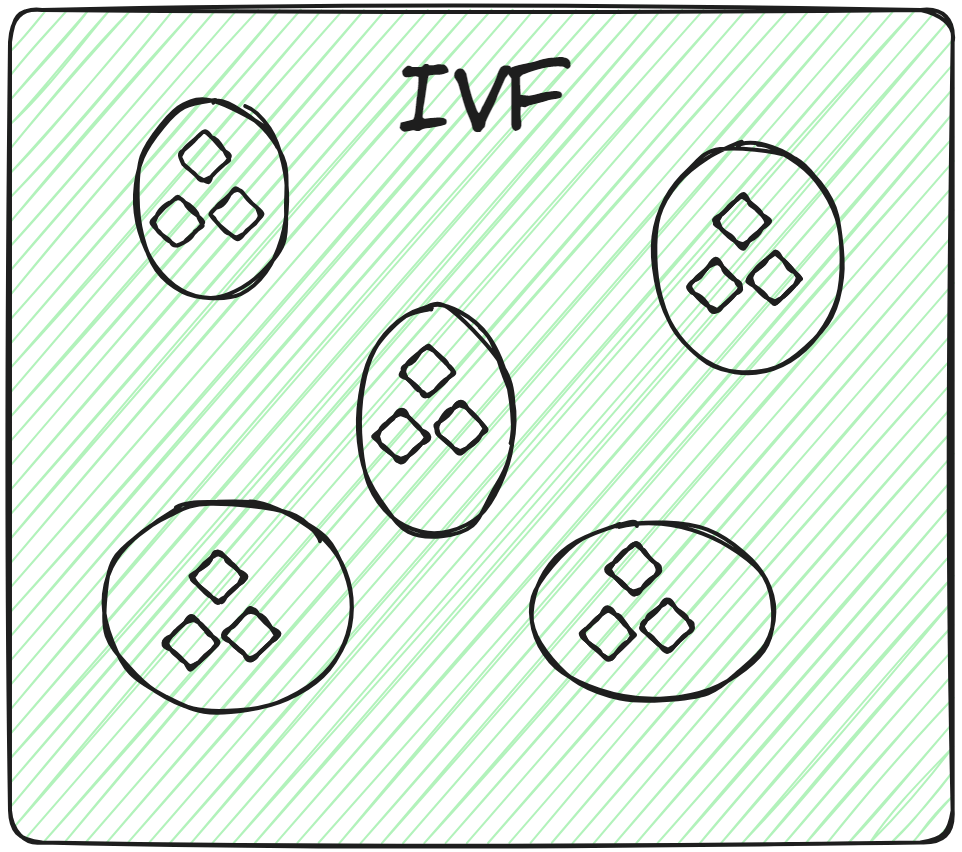
したがって、関連するクラスタ内でのみ力まかせ検索を行うことで、検索速度が向上し、クエリ時間が大幅に短縮されます。
# IVFFLAT、IVFPQ、IVFSQのバリエーション
特定の要件に応じて、IVFの異なるバリエーションが使用されます。それぞれについて詳しく見ていきましょう。
# IVFFLAT
IVFFLAT (opens new window)は、IVFのよりシンプルな形式です。データセットをクラスタに分割しますが、各クラスタ内ではフラットな構造(そのため「FLAT」という名前)を使用してベクトルを保存します。IVFFLATは、検索速度と精度のバランスを最適化するために設計されています。
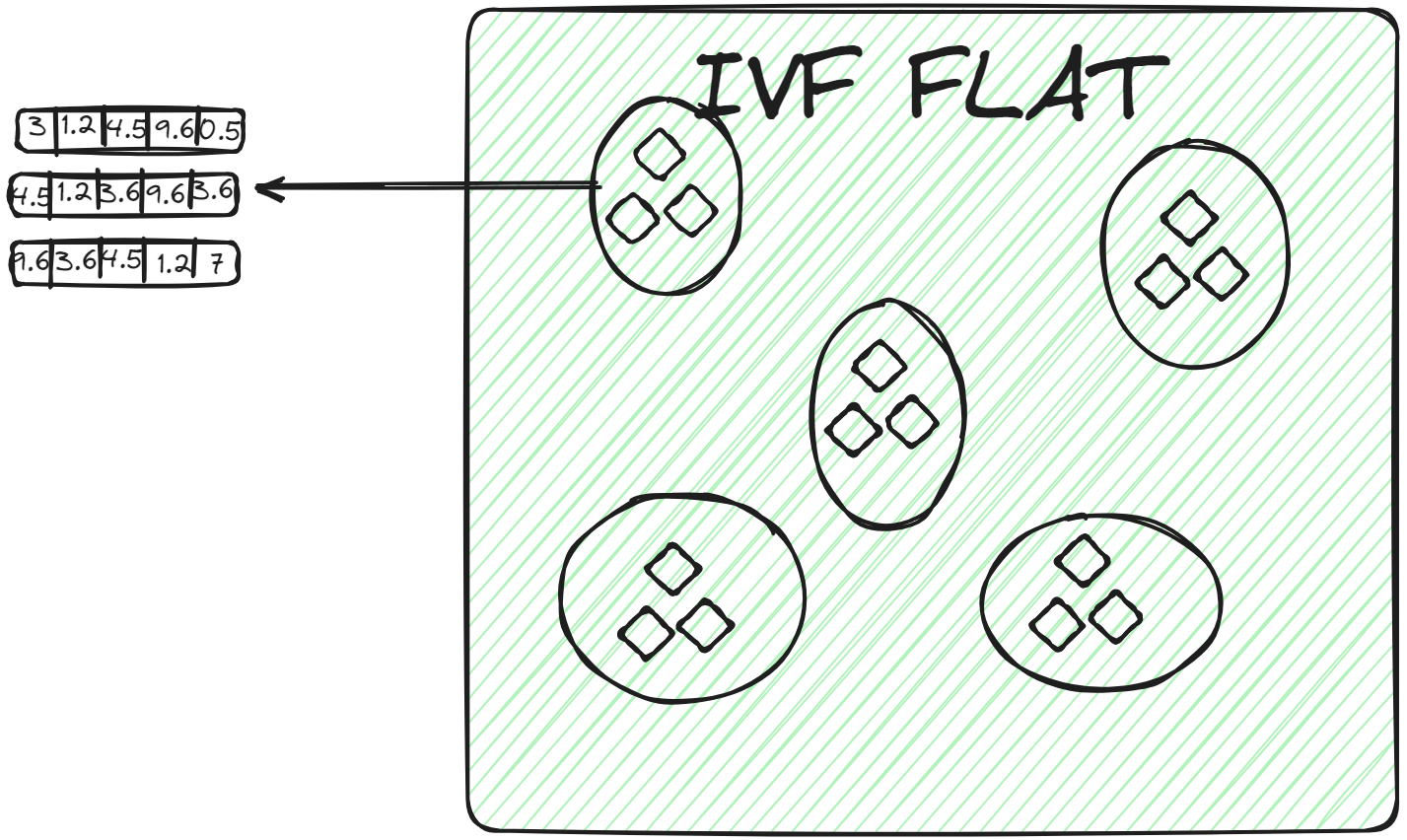
各クラスタ内では、ベクトルは追加の分割や階層構造なしでシンプルなリストまたは配列に保存されます。クエリベクトルがクラスタに割り当てられると、ブルートフォース検索が行われ、クラスタのリスト内の各ベクトルが調べられ、クエリベクトルとの距離が計算されます。IVFFLATは、データセットがかなり大きくなく、検索プロセスで高い精度を実現することを目的としたシナリオで使用されます。
# IVFPQ
IVFPQ (opens new window)は、IVFの高度なバリエーションであり、Inverted File with Product Quantizationの略です。データをクラスタに分割しますが、各クラスタ内のベクトルはさらに小さなベクトルに分割され、各部分はプロダクト量子化を使用して制限されたビット数にエンコードまたは圧縮されます。
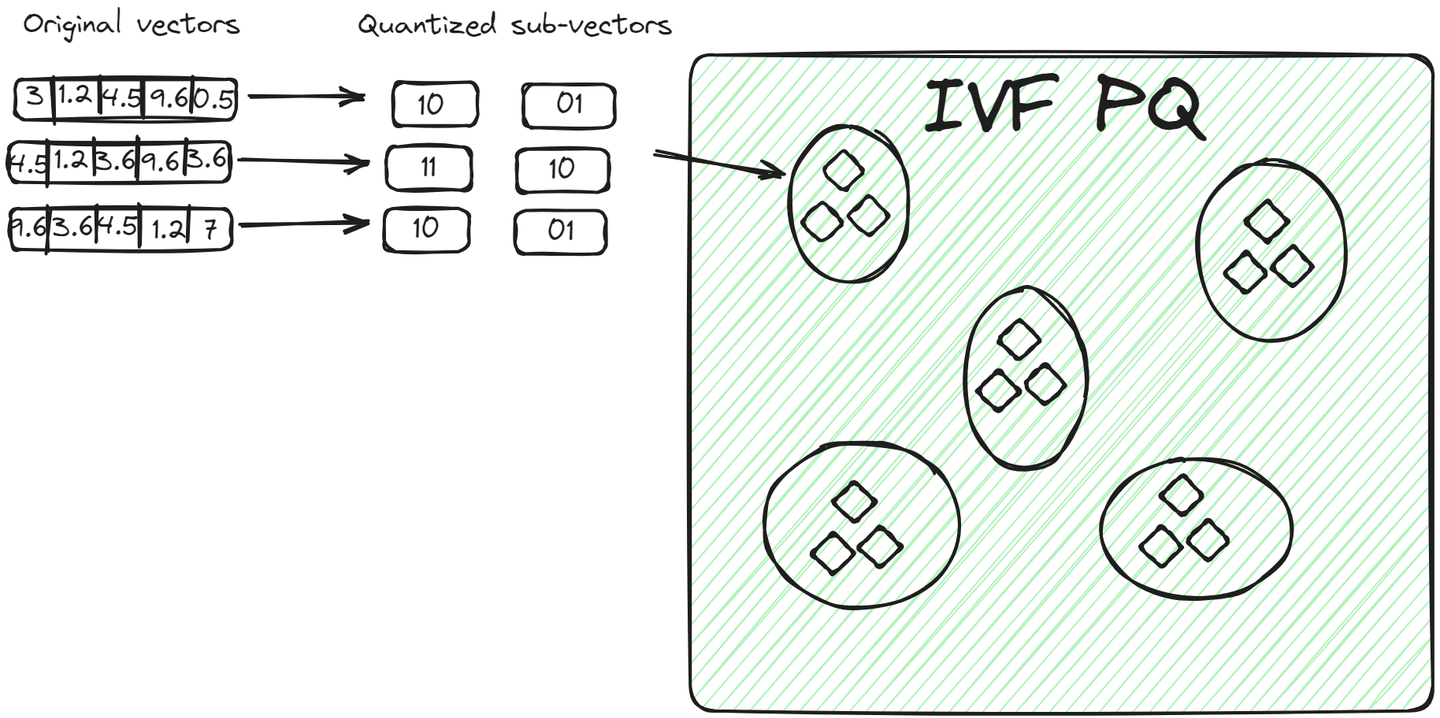
クエリベクトルに対して、関連するクラスタが特定されると、アルゴリズムはクエリの量子化された表現とクラスタ内のベクトルの量子化された表現を比較します。この比較は、次元削減と量子化により、生のベクトルを比較するよりも高速です。 この方法には、前の方法と比べて2つの利点があります。
- ベクトルは生のベクトルよりも少ないスペースを占めるコンパクトな方法で保存されます。
- クエリプロセスも高速化されます。すべての生のベクトルではなく、エンコードされたベクトルを比較するためです。
# IVFSQ
File System with Scalar Quantization (IVFSQ) (opens new window)は、他のIVFのバリエーションと同様にデータをクラスタに分割します。しかし、最も大きな違いは量子化の技術です。IVFSQでは、クラスタ内の各ベクトルがスカラー量子化を通過します。つまり、ベクトルの各次元が個別に処理されます。
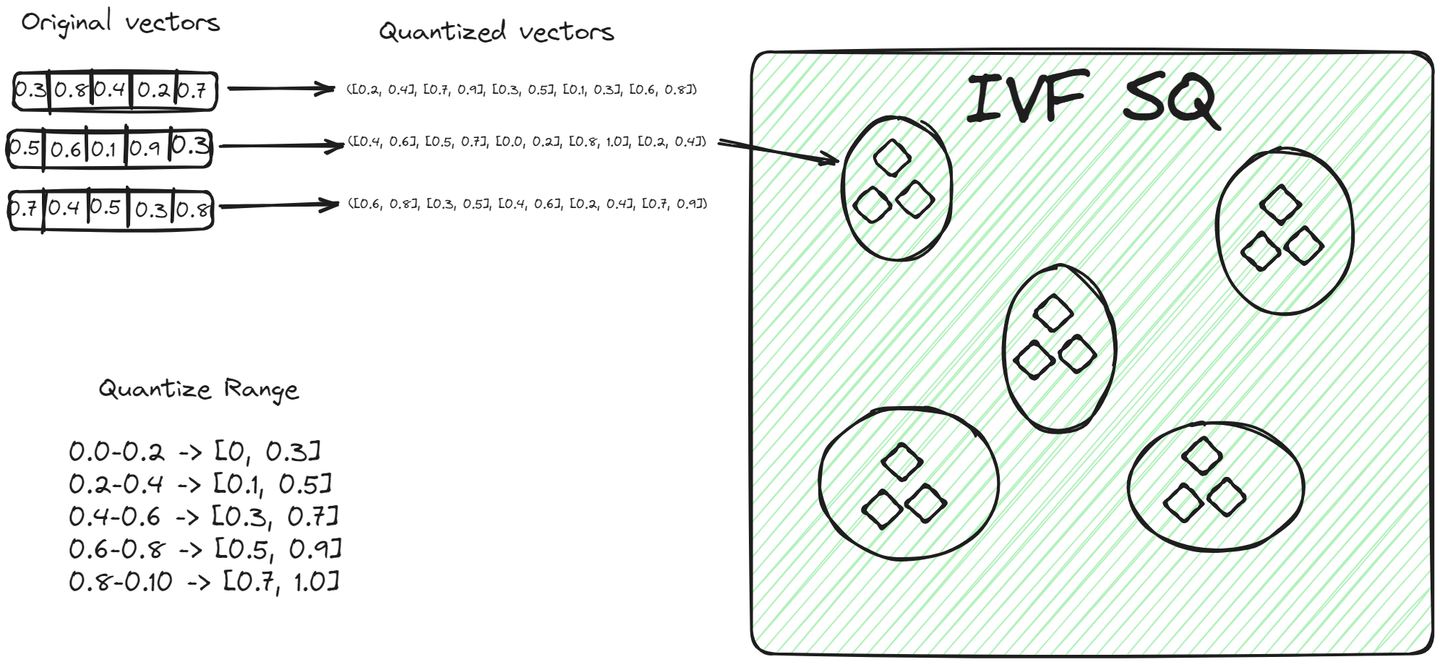
単純に言えば、ベクトルの各次元に対して事前に定義された値または範囲を設定します。これらの値または範囲は、ベクトルがどのクラスタに属するかを決定するのに役立ちます。ベクトルの各成分は、これらの事前に定義された値と一致させるために、クラスタ内のベクトルと比較されます。この各次元を個別に分解し、量子化する方法により、プロセスがより簡単になります。特に低次元のデータには有用であり、エンコーディングを簡素化し、ストレージに必要なスペースを減らすことができます。
# Hierarchical Navigable Small World (HNSW) アルゴリズム
Hierarchical Navigable Small World (opens new window) (HNSW) アルゴリズムは、データを効率的に保存および取得するための洗練された方法です。そのグラフのような構造は、確率スキップリストとNavigable Small World (NSW) という2つの異なる技術からインスピレーションを受けています。
HNSWをよりよく理解するために、まずこのアルゴリズムに関連する基本的な概念を理解しましょう。
# スキップリスト
スキップリストは、リンクリストの高速な挿入能力と配列の高速な検索特性の利点を組み合わせた、高度なデータ構造です。これは、データが複数のレイヤーにわたって組織され、各レイヤーにはデータポイントのサブセットが含まれる、マルチレイヤーのアーキテクチャによって実現されます。
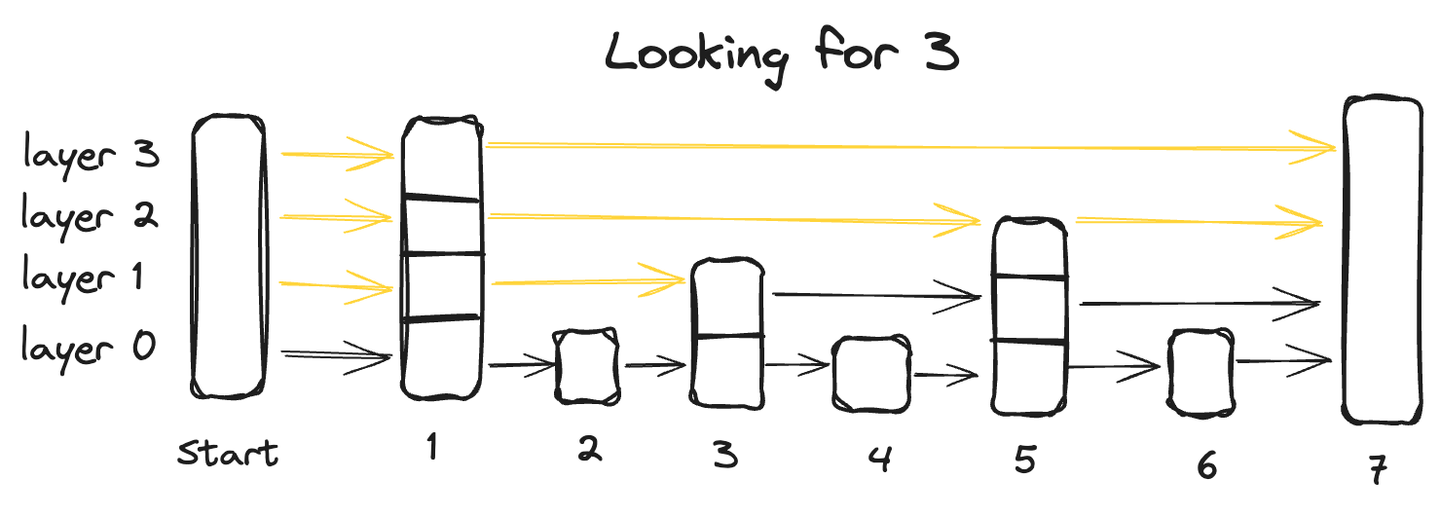
最下層から始まり、すべてのデータポイントを含むボトムレイヤーから始まり、各次のレイヤーはいくつかのポイントをスキップし、したがってデータポイントが少なくなり、最上層には最も少ないデータポイントが含まれます。
スキップリストでデータポイントを検索するには、最上層から始めて、左から右に進みながら各データポイントを調べます。任意の時点で、クエリされた値が現在のデータポイントよりも大きい場合、前のレイヤーの前のデータポイントに戻り、左から右に検索を再開し、正確なポイントを見つけるまで続けます。
# Navigable Small World (NSW)
Navigable Small World (NSW) は、互いにどれだけ似ているかに基づいてノードがリンクされる近接グラフに似ています。最も近い隣接点を探すために貪欲法が使用されます。
常に事前に定義されたエントリーポイントから始め、近くの複数のノードに接続されます。クエリベクトルに最も近いノードを特定し、そこに移動します。このプロセスを、現在のノードよりもクエリベクトルに近いノードが存在しなくなるまで繰り返します。これはアルゴリズムの停止条件となります。
さて、メインのトピックに戻り、HNSWがどのように機能するかを見てみましょう。
# HNSWの開発方法
HNSWでは、スキップリストからインスピレーションを受け、スキップリストのようなレイヤーを作成します。ただし、データポイント間の接続にはグラフのような接続が作成されます。各レイヤーのノードは、現在のレイヤーのノードだけでなく、下のレイヤーのノードとも接続されます。上部のノードは非常に少なく、下に行くほど密度が増します。最後のレイヤーにはデータベースのすべてのデータポイントが含まれます。これがHNSWのアーキテクチャの姿です。
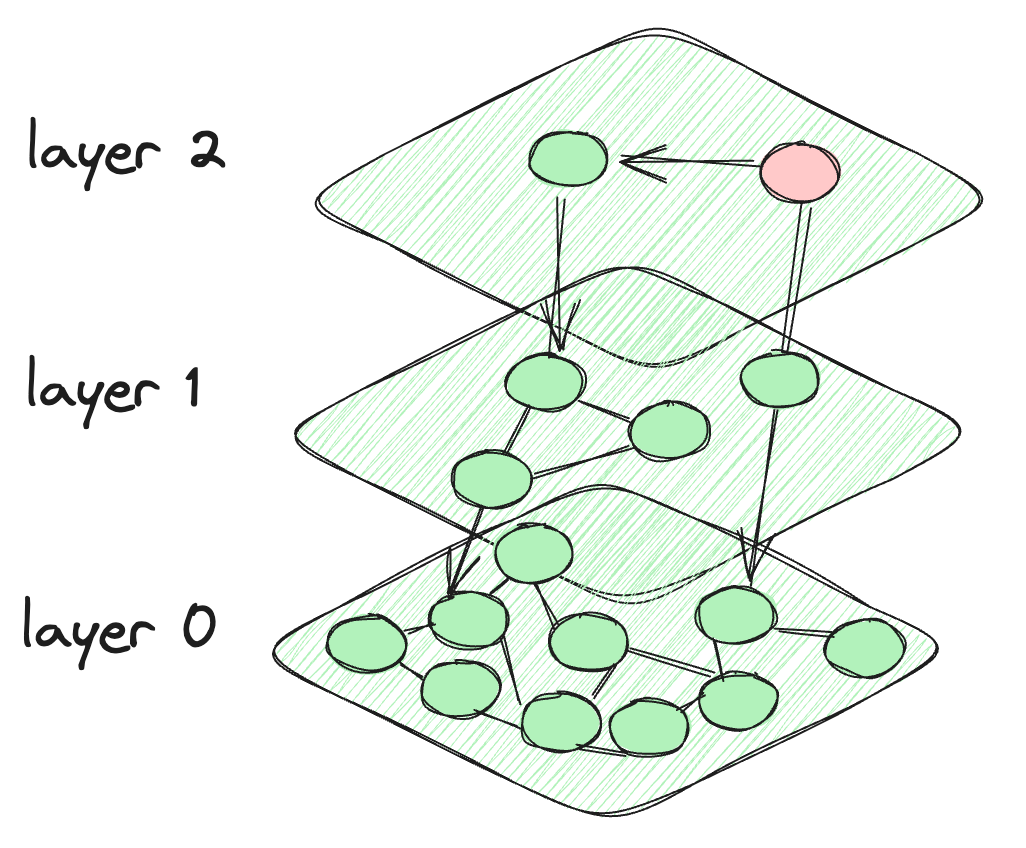
HNSWアルゴリズムのアーキテクチャ
# HNSWにおける検索クエリの動作
アルゴリズムは、最上層の事前定義されたノードから開始します。次に、現在のレイヤーの接続ノードと下のレイヤーのノードとの間の距離を計算します。もし下のレイヤーのノードへの距離が現在のレイヤーのノードへの距離よりも小さい場合、アルゴリズムは下のレイヤーに移動します。このプロセスは、最後のレイヤーに到達するか、他の接続ノードと比較して最小の距離を持つノードに到達するまで続きます。最終的なレイヤーであるレイヤー0には、データポイントがすべて含まれており、データセットの包括的で詳細な表現を提供します。このレイヤーは、検索がすべての潜在的な最近傍点を含むようにするために重要です。
# HNSWの異なるバリエーション:HNSWFLATとHNSWSQ
IVFFLATとIVFSQのように、生のベクトルを保存するものと量子化された範囲を保存するものの2つのバリエーションが存在するように、HNSWFLATとHNSWSQにも同じプロセスが適用されます。HNSWFLATでは、生のベクトルがそのまま保存されますが、HNSWSQではベクトルが量子化された形式で保存されます。データの保存方法におけるこの主な違いを除いて、HNSWFLATとHNSWSQのインデックスと検索の全体的なプロセスと方法は同じです。

# Multi-Scale Tree Graph (MSTG) アルゴリズム
標準の逆ファイルインデックス(IVF)は、ベクトルデータセットを多数のクラスタに分割し、階層的なナビゲーション可能な小さなワールド(HNSW)はベクトルデータのための階層グラフを構築します。ただし、これらの方法の注目すべき制約の1つは、大規模なデータセットの場合、インデックスサイズが著しく増加し、すべてのベクトルデータをメモリに保存する必要があることです。DiskANNのような手法はベクトルストレージをSSDにオフロードできますが、インデックスの構築が遅く、非常に低いフィルタードサーチのパフォーマンスを持っています。
Multi-Scale Tree Graph(MSTG)はMyScale (opens new window)によって開発され、これらの制約を克服するために階層的なツリークラスタリングとグラフトラバーサルを組み合わせ、メモリと高速なNVMe SSDを使用しています。MSTGはIVF/HNSWのリソース消費を著しく削減し、優れたパフォーマンスを維持します。高速に構築し、高速に検索し、異なるフィルタードサーチの比率で高速かつ正確なままでありながら、リソースとコスト効率が高いです。
# 結論
ベクトルデータベースは、データの保存方法を革新し、高速性だけでなく、人工知能やビッグデータ分析などのさまざまな領域で非常に有用です。特に非構造化の形式での指数関数的なデータの成長が進む時代において、ベクトルデータベースの応用は無限です。カスタマイズされたインデックス技術は、フィルタリングされたベクトル検索のパワーと効果をさらに高めます。MyScaleは、独自のMSTGアルゴリズムにより (opens new window)、複雑な大規模ベクトル検索に対する強力なソリューションを提供し、MyScaleを今すぐお試しください (opens new window)。



