
ベクトル検索は、大量のテキスト、画像、およびその他のデータ内で意味的に類似または関連する候補を迅速に見つけることができます。しかし、実際のシナリオでは、純粋なベクトル検索だけでは十分ではありません。
実際のデータには通常、時間、カテゴリ、ユーザーIDなどの属性が含まれます。これらの属性に1つ以上のフィルタリング条件を適用すると、リトリーバル・オーグメンテッド・ジェネレーション(RAG)システムの精度が向上し、大規模なマルチテナント・システムの基礎が形成されます。ClickHouseデータベース上に開発されたMyScale (opens new window)は、SQLのさまざまなデータ型をサポートし、任意のフィルタリング比率で検索において高い精度と効率を実現しています。
この記事では、フィルタリングされたベクトル検索の重要性と、その実装の背後にある技術について議論しています。これには、前フィルタリングや後フィルタリング、および行列の保存方法も含まれています。
# フィルタリングされたベクトル検索はRAGシステムの精度向上に不可欠
フィルタリングされた検索は、高精度なLLM/AIアプリケーションをサポートする上で重要な役割を果たします。純粋なベクトルリトリーバルは、通常、文書内容が限られたシナリオでは比較的正確な候補を返しますが、文書の量が増えると、リトリーバルの再現率が急速に低下する傾向があります。
この問題は主に、金融のような複雑な文書環境で発生します。こうした環境では関連するコンテンツが豊富であることがよくあります。これらの場合、純粋なベクトルリトリーバルは似ているが不正確なコンテンツを多く返すことがあり、LLMの最終的な応答の精度に悪影響を与えます。
たとえば、金融分析のシナリオでは、ユーザーが次のように尋ねることがあります: "<企業>の経営スタイルはどうですか?" <企業>が一般的でない企業名の場合、純粋なベクトルリトリーバルはしばしば類似したが正確でないコンテンツ、つまり似たような企業の経営スタイルに関する段落を多数返すことがよくあります。これはLLMによる応答の正確な生成を妨げます。
しかし、文書タイトルに <企業> に関連するキーワードが含まれることを事前に知っている場合、WHERE title ILIKE '%<企業>%' を使用して事前フィルタリングを行うことで、関連する文書のみを検索結果として取得できます。さらに、<企業> はLLMによって自動的に抽出され、クエリテキストからSQLの WHERE 句を生成する関数呼び出しのパラメータや、システムが柔軟で使いやすいようにできます。
これらの構造化された属性をフィルタリングに利用することで、金融文書分析や企業知識ベースなどの実際のアプリケーションにおいて、精度が60%から90%に向上することを観測しています。したがって、RAGシステム内で高精度なクエリを確保するためには、構造化された + ベクトルデータモデリングおよびクエリングの柔軟で普遍的なアプローチが必要です。また、フィルタリング比率に関係なく高い精度と効率を保証するベクトルリトリーバルも必要です。

# フィルタリングされたベクトル検索は大規模なマルチユーザーシステムの実装の基盤
フィルタリングされたベクトル検索は、大規模なドキュメントQA、意味的メモリを持つ仮想キャラクターチャット、およびソーシャルネットワーキングなどのアプリケーションにおいて基本的です。これらのアプリケーションでは、システムは通常、何百万ものユーザーのデータからのクエリをサポートする必要があり、各クエリは通常、単一または少数のユーザーのデータからのものです。
これには非常に低いフィルタリング比率で非常に高いクエリ精度が求められます。Pinecone、Weaviate、Milvusなど、このようなアプリケーション向けに設計された専門のベクトルデータベースは、各ユーザーのデータを個別のネームスペースに配置できる namespace メカニズムを導入して、クエリの精度を確保しています。
ただし、このアプローチは柔軟性が制限されるため、単一のクエリは通常、1つのネームスペース内でのみ検索できます。たとえば、ソーシャルネットワークでは、ユーザーが数百から数千の友達に関連するコンテンツをクエリする必要があるかもしれません。文脈分析と推薦システムでは、時間、著者、キーワードなどに基づく複雑なフィルタリングクエリがしばしば必要です。
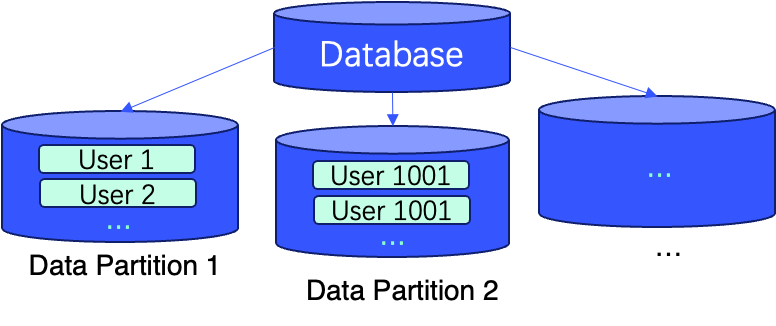
これらのケースおよびその他において、WHERE 条件を使用したフィルタリングクエリが柔軟なアプローチを提供します。さらに、データのパーティショニングとプライマリキーを使用したデータのソートを採用することで、データの局所性を向上させることでクエリ効率を向上させることができます。
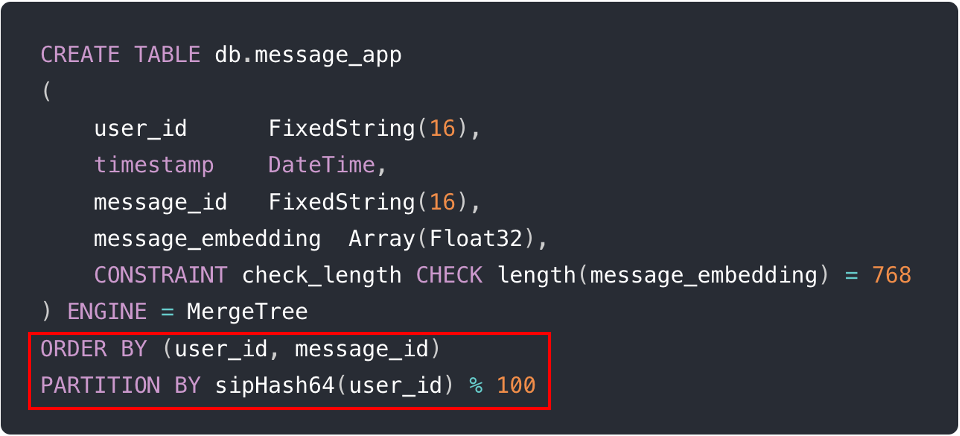
以下の図は、これらのテクニックを実装するためのSQLの2行で表の作成中に実行される実世界の例を示しています(すなわち、ORDER BY (user_id, message_id) および PARTITION BY sipHash64(user_id) % 100)。
ノート:
詳細については、マルチテナンシーのドキュメント (opens new window)を参照してください。
# MyScaleは任意の比率で高精度で高効率なフィルタリング検索をサポート
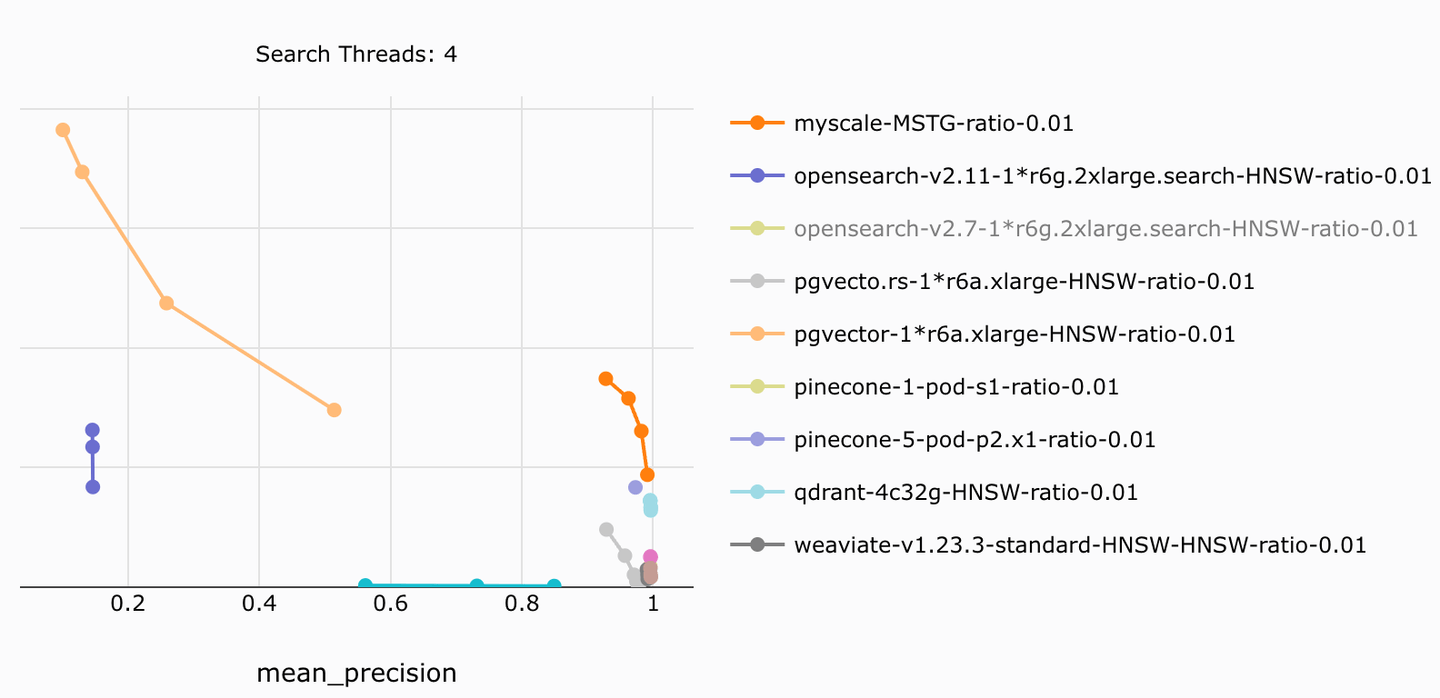
MyScaleは、列指向のストレージ、事前フィルタリング、効率的な検索アルゴリズムを組み合わせることで、任意のフィルタリング比率で高精度かつ高効率なフィルタリング検索を実現しています。他の製品と比較して、QPS比率ごとに4倍から10倍の低コストを提供しています。
例えば、MyScaleはオープンソースのベンチマーク (opens new window)で最高の検索速度と精度を達成し、精度と速度で劣る類似システムを最大5倍安価に凌駕しています。この正確で効率的なフィルタリング検索機能は、本番用のRAGシステムの堅固な基盤となっています。
ノート:
詳細な結果については、MyScale vs. pgvectorとOpenSearchの比較記事 (opens new window)を参照してください。
前述のように、MyScaleは広く使用されているClickHouse SQLデータベースをベースに開発されており、データ型および関数 (opens new window)の広範な範囲をサポートしています。これには数値、日時、地理空間、JSON、文字列などが含まれます。これにより、Pinecone、Weaviate、Qdrantなどの専門のベクトルデータベースと比較して、フィルタリングクエリの能力が向上しています。
さらに、LLMsはSQLに高度に精通しているため、自然言語をSQLの WHERE 条件に自動変換できます。これは、技術的なバックグラウンドのないユーザーでも自然言語を使用してフィルタリングクエリを実行できるようにし、RAGシステムの柔軟性と精度をさらに向上させます。この技術はLangChainのMyScale Self-Query (opens new window)でも同様に実装されており、広く本番システムで活用されています。

# 裏にあるもの
多くのシナリオでフィルタリングされたベクトル検索が重要であるにもかかわらず、正確で効率的なフィルタリングされたベクトル検索の実装には事前フィルタリング対事後フィルタリング、行指向対列指向のストレージ、グラフ対ツリーアルゴリズム (opens new window)など、多くの技術的詳細な選択が含まれます。事前フィルタリング、列指向ストレージ、およびマルチスケールツリーグラフアルゴリズムなどの技術を統合することで、MyScaleはフィルタリングされたベクトル検索で優れた精度と速度を実現しました。
# 事前フィルタリング対事後フィルタリング
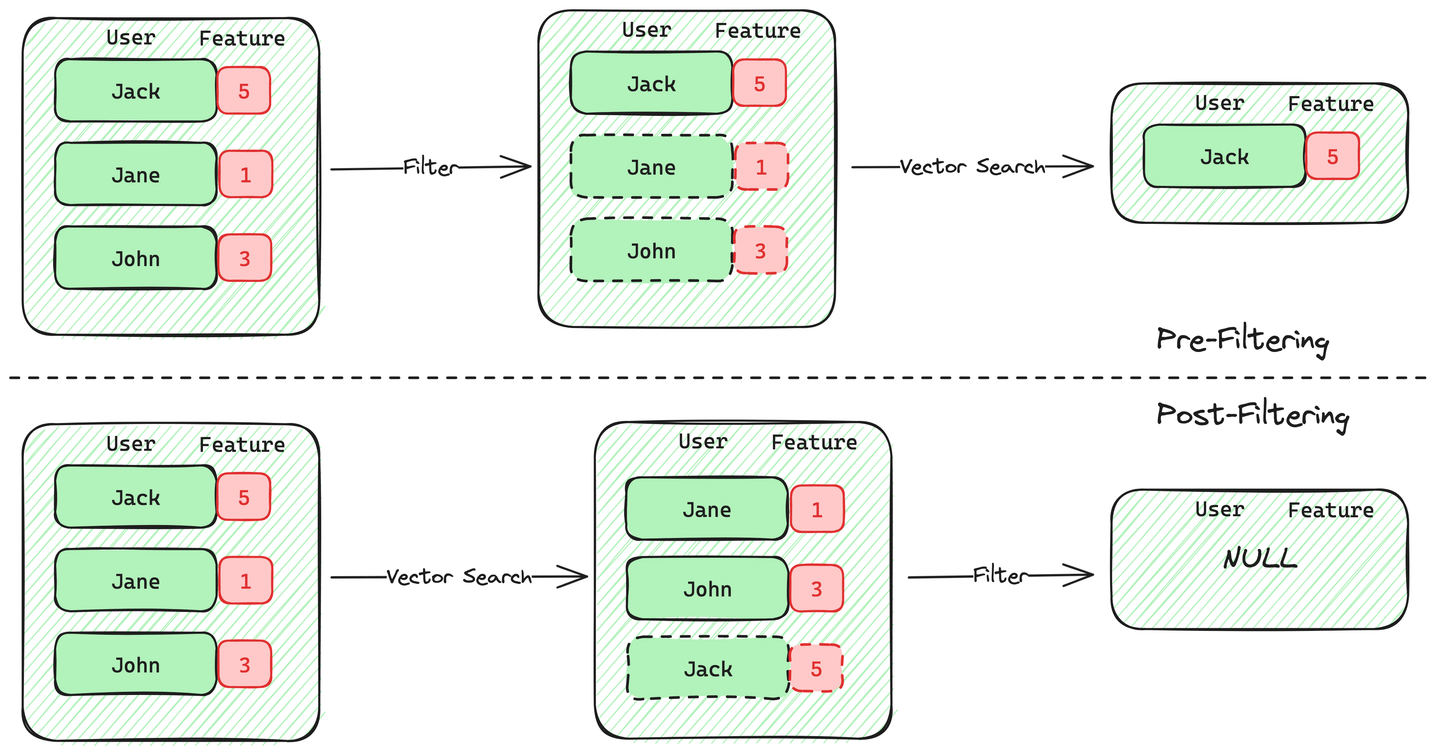
フィルタリングされたベクトル検索でメタデータフィルタリングを実装するための2つのアプローチがあります: 事前フィルタリングと事後フィルタリング。
事前フィルタリングでは、メタデータを使用して基準を満たすベクトルを最初に選択し、それらのベクトルを検索します。この方法の利点は、ユーザーがk個の最も類似したドキュメントを必要とする場合、データベースがkの結果を保証できることです。
一方、事後フィルタリングでは、まずベクトル検索を実行してmの結果を取得し、それらの結果にメタデータフィルターを適用します。この方法の欠点は、mの結果がメタデータフィルターの基準を満たすベクトルの数が不確かであり、最終的な結果がk未満になる可能性があることです。フィルタリング基準を満たすベクトルが少ない場合、事後フィルタリングの精度が著しく低下します。PostgreSQLのベクトルリトリーバルプラグインであるpgvectorは、このアプローチを採用しており、クエリングデータの割合が低い場合に精度が著しく低下します。
事前フィルタリングの課題は、基準を満たすベクトルの数が少ない場合に、データを効率的にフィルタリングし、ベクトルインデックスで検索効率を維持することです。
たとえば、広く使用されているHNSW(Hierarchical Navigable Small World)アルゴリズムは、フィルタリング比率が低い場合(たとえば、フィルタリング後にベクトルの1%しか残らない場合)に検索の効果が著しく低下します。この問題に対処するための一般的な業界全体のソリューションは、フィルタリング比率が特定の閾値を下回った場合に、ブルートフォース検索に戻ることです。Pinecone、Milvus、ElasticSearchなど、これに採用していますが、大規模なクエリで発生するブルートフォース検索は非常にコストがかかります。
例えば、Pinecone、Milvus、ElasticSearchなどはこの方法を採用していますが、大規模なデータセットではパフォーマンスに深刻な影響を与える可能性があります。それに対して、MyScaleは高効率な事前フィルタリングとアルゴリズムの革新を組み合わせることで、どんなフィルタリング比率でも高い精度と効率を確保しています。
# 行指向対列指向のストレージ
事前フィルタリング戦略を採用する際、メタデータを効率的にスキャンすることは検索のパフォーマンスにとって重要です。データベースのストレージは一般的に行指向または列指向に分類されます。
行指向ストレージは通常トランザクションデータベース(MySQLやPostgreSQLなど)で使用され、トランザクション処理に特に適しています。対照的に、列指向データベース(ClickHouseなど)は、複数の列をスキャンしたり、バッチデータの取り込み、圧縮されたストレージに特に効率的です。
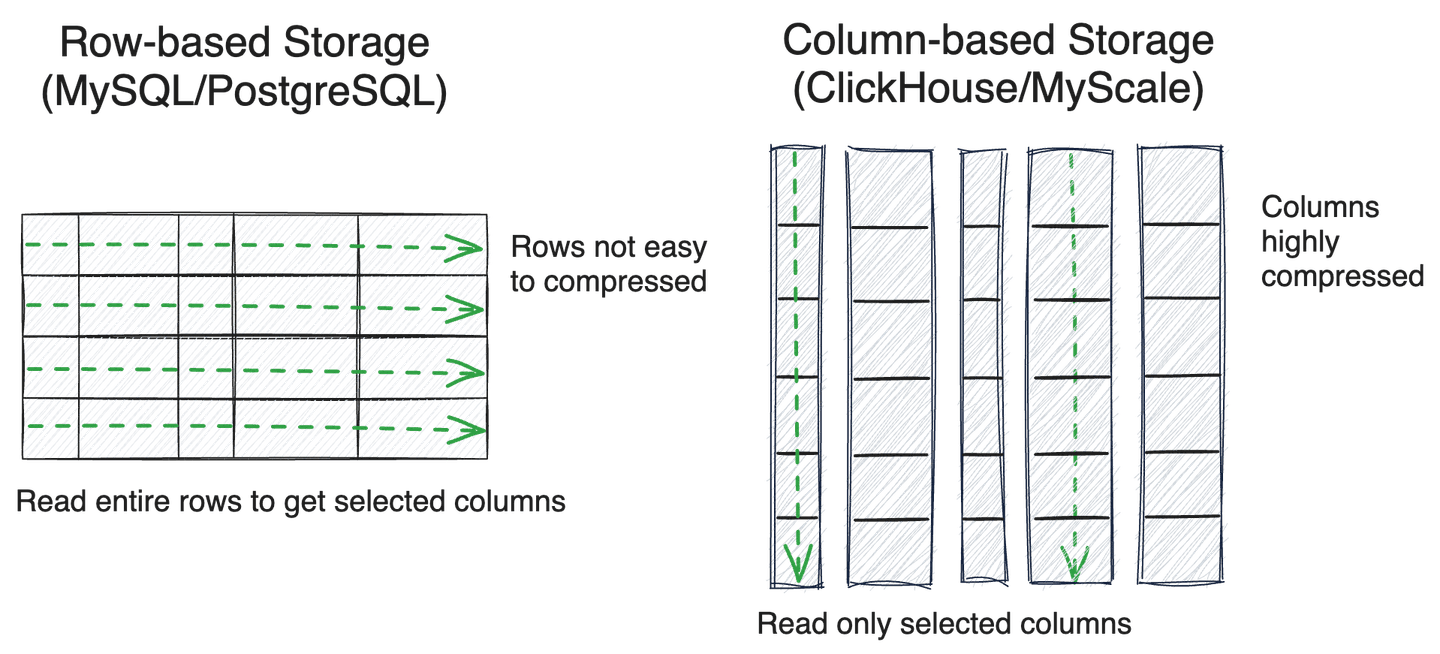
効率的なメタデータのスキャンが必要なため、MilvusやQdrantなどの多くの専門のベクトルデータベースも列指向ストレージを採用しています。長年にわたる構造化データ解析クエリの最適化を経て、ClickHouseなどの列指向SQLデータベースは、スキップインデックスやSIMD演算などの技術を使用して、多くの実用的なシナリオ全体でデータのスキャン効率を著しく向上させています。
豊富なユーザーリサーチによれば、AI/LLMアプリケーション(RAGなど)では小規模な書き込みトランザクションの必要性が少なく、効率的なデータのスキャンと分析が不可欠です。そのため、私たちにとっては列指向のストレージがより適しています。
これがMyScaleがClickHouseをベースに開発する理由の一つです。対照的に、pgvectorやpgvecto.rsなどのシステムは、PostgreSQLの行指向ストレージの制約からくる、フィルタリング検索の精度や速度の問題に直面しています。
最後に、列指向データベースの最大の課題は、複数列のポイントリードが効率的でないことです。データの読み取り増幅や圧縮のオーバーヘッドが影響しています。しかし、これには非圧縮データのキャッシングなどの技術を用いて対処できます。また、構造化データとベクトルデータの共同クエリにおいても、vbase (opens new window)のようなリラックスした単調性の最適化など、改善の余地が多く存在します。
# まとめ
構造化データとベクトルデータを一つのクエリで組み合わせることで、フィルタリングされたベクトル検索は高度なRAGシステム、大規模なマルチユーザーシステムなど、幅広い応用分野で重要な役割を果たします。列指向のClickHouse SQLデータベースを基に構築されたMyScaleは、多様なメタデータタイプと関数をサポートし、柔軟なセルフクエリ機能を提供しています。
事前フィルタリング、列指向のストレージ、アルゴリズムの最適化を組み合わせることで、MyScaleはどんなフィルタリング比率でも高い精度と速度を実現し、LLMアプリケーションのための確かなデータ基盤を築いています。
もし、フィルタリング検索に関するご意見があり、アイデアを共有したい場合は、Twitter (opens new window)をフォローし、Discord (opens new window)コミュニティに参加してください。



