
従来の画像分類モデル(例:畳み込みニューラルネットワーク(CNN) (opens new window))は、長年にわたりコンピュータビジョン (opens new window)のタスクの基盤となってきました。これらのモデルは、各画像が特定のクラスラベルに関連付けられている大規模なラベル付きデータセットでトレーニングすることによって動作します。通常、これらのモデルはNショット学習に依存しており、高い精度を達成するために各クラスに対して大量のラベル付き画像(Nの例)が必要です。
しかし、これらの従来のモデルにはいくつかの重要な課題があります。まず、大量のラベル付きデータを要求し、その作成には時間とコストがかかります。さらに、従来のモデルは、例(N)の数が少ない場合に特に効果的に一般化することができません。
さらに、これらのモデルは未知のデータを分類する能力に制限があります。モデルが特定のクラスでトレーニングされていない場合、そのクラスの画像を正確に分類することはできません。この制限は、新しいカテゴリが頻繁に現れるシナリオやラベル付きデータが不足している場合など、特にボトルネックとなります。
これらの課題から明らかなように、より少ないリソースでより多くのことができるよりスマートなモデルが必要です。それがCLIPの真価です。従来のモデルとは異なり、CLIPは特定のクラスごとに個別にトレーニングする必要はありません。CLIPは、巨大な画像テキストペアのデータセットと対照的な学習を使用して、画像内の内容を特定する方法を学習します。これにより、CLIPは特に従来のモデルが苦手とするシナリオで非常に有用です。
# CLIP
OpenAIは2021年にCLIP (opens new window)を発表しました。CLIPは、画像とテキストを共有のベクトル空間に配置することで、画像とテキストのギャップを埋めるモデルです。対照的な学習を使用することで、CLIPはどの画像テキストペアが関連しているか、関連していないかを判断することができます。この能力により、CLIPはゼロショット分類で非常に効果的であり、テキストの説明に基づいて新しいカテゴリを正確に識別することができます。
- ゼロショット分類 (opens new window):このアプローチでは、モデルはトレーニング中にラベル付きの例を必要とせずに新しいカテゴリを分類することができます。ゼロショットと呼ばれるのは、予測を行うためにトレーニングデータが不要であり、テキストの説明のみに依存するからです。
- Nショット分類 (opens new window):この場合、モデルは各カテゴリごとにN個のラベル付きの例を必要とし、それらを正しく分類する方法を学習します。Nは、各カテゴリを理解するためにモデルが見る必要がある例の数を表します。
# ゼロショット分類にCLIPを使用する方法
CLIPのアーキテクチャは、ゼロショット分類を簡単かつ強力な方法で処理するように設計されています。CLIPの中核には、画像用のエンコーダとテキスト用のエンコーダの2つがあります。これらのエンコーダは、入力画像とテキストの説明を、共有のベクトル空間内の高次元ベクトルまたは埋め込みに変換します。
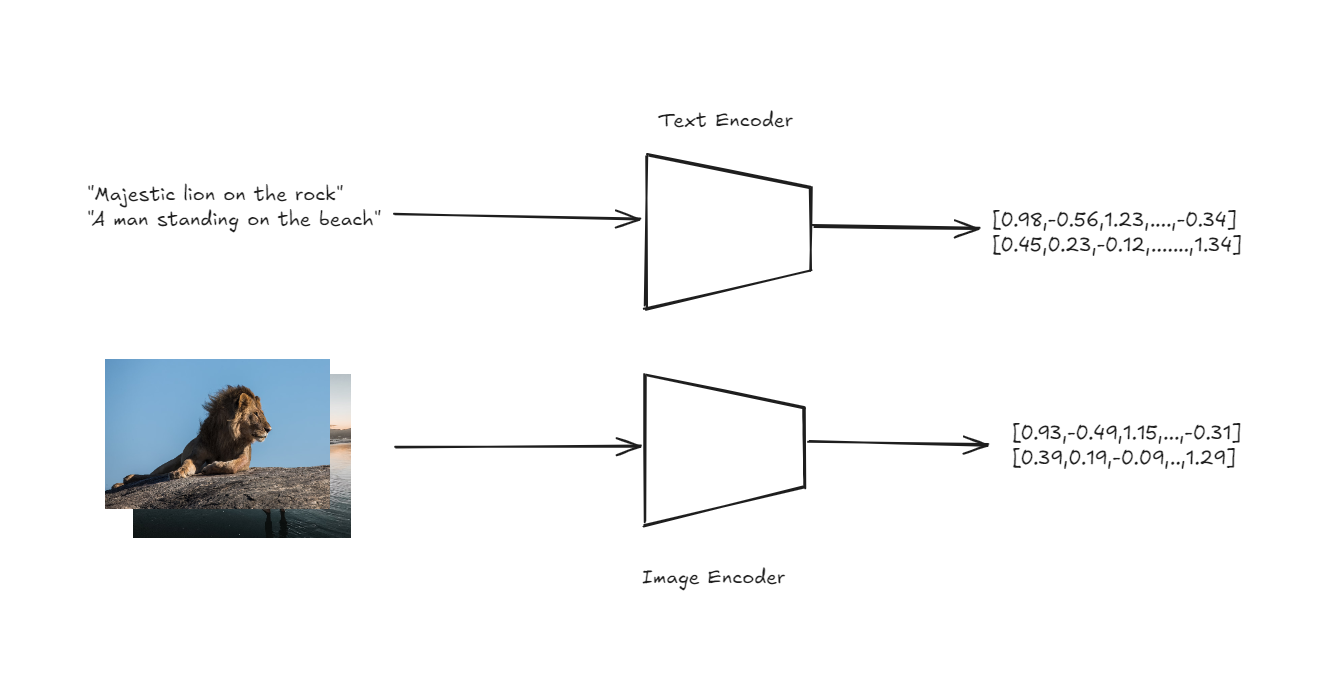
テキストと画像のエンコーダによる埋め込みの取得
ここでの主なイノベーションは、画像とテキストの両方が同じ空間で表現されていることであり、両モダリティを直接比較することができるという点です。
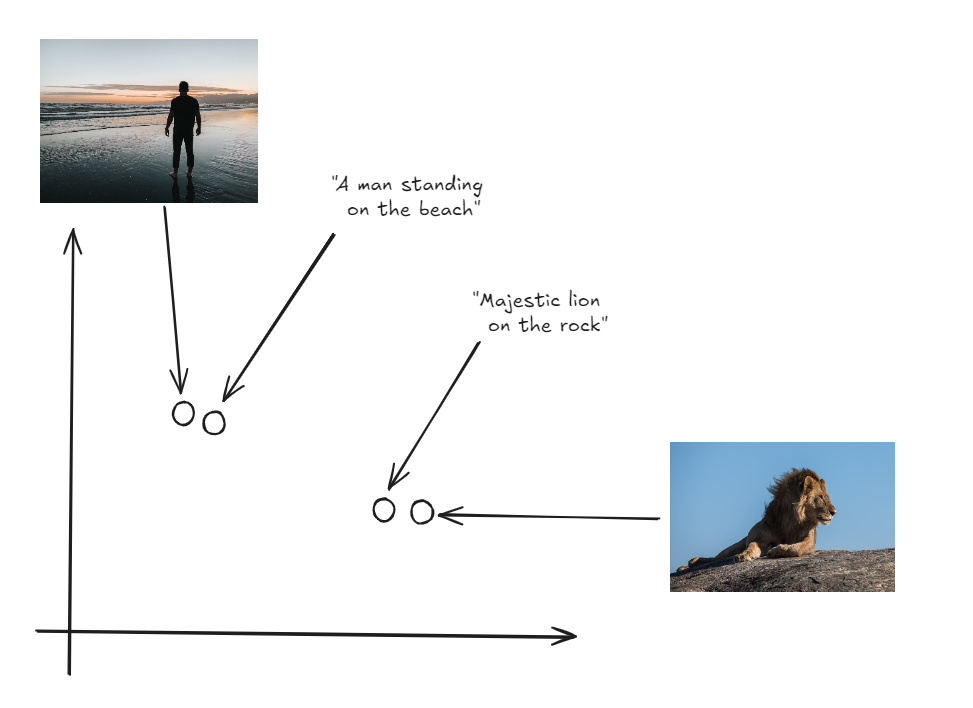
画像とラベルが同じベクトル空間に存在する
ゼロショット分類を実行するために、CLIPはまず、異なるクラスに対応する一連のテキスト説明の埋め込みを生成します(例:「猫の写真」、「犬の写真」)。次に、入力画像の埋め込みを生成します。モデルは、画像の埋め込みと各テキストの埋め込みのコサイン類似度を計算します。コサイン類似度は、2つのベクトルの間の角度のコサインを測定し、それらがどれだけ近くに整列しているかを示します。画像の埋め込みと最も高いコサイン類似度を持つテキスト説明が予測されたラベルとして選択されます。このプロセスにより、CLIPはトレーニング中に明示的に見たことのないカテゴリの画像を分類することができます。これは、テキストの説明に捉えられた意味情報にのみ依存することを意味します。
注意:同じアプローチを使用して、CLIPを使用した画像検索アプリケーションを構築 (opens new window)することもできます。
# 実践的な例
では、ゼロショット分類のためにCLIPモデルをImagenetteデータセットでテストしたとき、その性能は非常に優れており、99%以上の精度を達成しました。この結果からわかるように、CLIPは従来の画像分類モデルの性能をマッチまたはさらに上回ることができます。
このような素晴らしい結果から、CLIPは画像分類タスクにおける強力な代替手段を提供していることが明らかです。それでは、このモデルを実践的なシナリオでどのように実装できるかを詳しく見ていきましょう。
注意:Github (opens new window)で完全なノートブックを見つけることができます。
# 必要なライブラリのインストール
まず、必要なライブラリをインストールする必要があります。次のコマンドを使用して必要なパッケージをインストールします:
pip install datasets transformers
Hugging Faceのdatasetsライブラリは、機械学習プロジェクトに非常に役立つ、使用準備が整ったさまざまなデータセットにアクセスできます。
transformersライブラリもHugging Faceによるもので、強力な事前学習モデルを使用するための定番です。この場合、CLIPモデルを読み込んで使用するために使用します。
# 依存関係のインポート
ライブラリがインストールされたら、必要な依存関係をインポートすることができます。これには、データの処理、CLIPモデルの操作、結果の可視化に必要なモジュールが含まれます。
import torch
import numpy as np
from datasets import load_dataset
from tqdm.auto import tqdm
from transformers import AutoProcessor, CLIPModel, AutoTokenizer
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import seaborn as sns
matplotlibとseabornを使用して視覚化を作成および表示し、プロジェクト全体でデータをより良く解釈および表示するために使用します。
# CLIPモデルの読み込み
ゼロショット分類を実行するために、CLIPモデルを読み込みます。モデルはGPUに読み込まれます(利用可能な場合)、それ以外の場合はCPUにフォールバックします。また、関連するプロセッサとトークナイザも読み込みます。
device = "cuda" if torch.cuda.is_available() else "cpu"
model = CLIPModel.from_pretrained("openai/clip-vit-large-patch14").to(device)
processor = AutoProcessor.from_pretrained("openai/clip-vit-large-patch14")
tokenizer = AutoTokenizer.from_pretrained("openai/clip-vit-large-patch14")
AutoProcessorは、画像とテキストデータをCLIPモデルと互換性のある形式に変換する役割を担っています。AutoTokenizerは、テキストをモデルが理解できる形式に変換し、さらなる処理のために必要なトークンを生成します。
注意:このブログでは、処理時間を大幅に短縮するために、Google Colabで利用可能な無料のGPUを使用しています。
# Imagenetteデータセットの読み込み
次に、Imagenetteデータセットを読み込みます。これは、より大きなImageNetデータセットの一部である小さなサブセットです。このサブセットには10のクラスが含まれており、迅速な実験にはより管理しやすいです:
imagenette = load_dataset(
'frgfm/imagenette',
'320px',
split='validation',
revision="4d512db"
)
Hugging Faceのdatasetsライブラリのload_dataset関数を使用して、Imagenetteデータセットをダウンロードして準備します。このバージョンのデータセットは、320ピクセルにリサイズされた画像で構成され、モデルのパフォーマンスを評価するために検証セットに分割されています。
# データセットの分析
まず、データセットに含まれるクラスラベルを出力して、作業するカテゴリを把握します:
labels = imagenette.features["label"].names
print(f"データセットのクラスラベル:{labels}")
上記のコードは次の結果を出力します:
データセットのクラスラベル:['tench', 'English springer', 'cassette player', 'chain saw', 'church', 'French horn', 'garbage truck', 'gas pump', 'golf ball', 'parachute']
# クラスの分布の可視化
さまざまなクラス間の画像の分布をよりよく理解するために、棒グラフを作成します。
plt.figure(figsize=(10, 6))
sns.barplot(x=labels, y=class_counts, palette='viridis')
plt.xticks(rotation=45, ha='right')
plt.title('Imagenetteデータセットのクラス分布')
plt.xlabel('クラスラベル')
plt.ylabel('画像の数')
plt.show()
上記のコードは、次のような棒グラフを生成します: グラフからわかるように、Imagenetteデータセットのクラス分布は均一ではありません。ただし、このデータセットはトレーニングに使用していないため、ゼロショット分類には問題ありません。
# 画像の選択と処理
次に、データセットを反復処理して画像とそれに対応するラベルを選択します。このステップでは、後続の埋め込み生成のためにデータを準備します。
selected_images = []
selected_labels = []
for example in tqdm(imagenette):
label = example["label"]
selected_images.append(example["image"])
selected_labels.append(label)
# テキスト入力の準備
ゼロショット分類では、クラスラベルをトークナイザを使用してテキスト入力に変換します。これらの入力は、モデルにフィードされてテキストの埋め込みを生成します。
text_inputs = tokenizer([f"a photo of a {c}" for c in labels], return_tensors="pt", padding=True).to(device)
文字列を"a photo of a {label}"という形式にフォーマットする理由は、CLIPモデルが類似のテキスト-画像ペアでトレーニングされているためです。このフレーズは、モデルがテキストを対応する画像によりよく一致させるのに役立ちます。
# テキストの埋め込みの生成
CLIPモデルを使用して、各クラスラベルのテキスト埋め込みを生成します。これらの埋め込みは後で画像埋め込みと比較され、類似度スコアが計算されます。
with torch.no_grad():
label_emb = model.get_text_features(input_ids=text_inputs['input_ids'], attention_mask=text_inputs['attention_mask'])
label_emb = label_emb.cpu().numpy()
# バッチ処理と画像埋め込みの生成
選択した画像をバッチで処理して画像埋め込みを生成します。これらの埋め込みは、テキスト埋め込みと比較して類似度スコアを計算するために使用されます。
preds = []
batch_size = 50
for i in tqdm(range(0, len(selected_images), batch_size)):
i_end = min(i + batch_size, len(selected_images))
images = processor(
images=selected_images[i:i_end],
return_tensors='pt'
)['pixel_values'].to(device)
with torch.no_grad():
img_emb = model.get_image_features(images)
img_emb = img_emb.cpu().numpy()
# 画像埋め込みとテキスト埋め込みの間の類似度スコアを計算する
scores = np.dot(img_emb, label_emb.T)
preds.extend(np.argmax(scores, axis=1))
これで、選択した画像の予測ラベルのセットが得られました。次に、モデルのパフォーマンスとこれらの予測が提供する洞察を探ってみましょう。
# 精度の計算と表示
最後に、予測されたラベルと実際のラベルを比較して、ゼロショット分類の精度を計算します。
accuracy = accuracy_score(selected_labels, preds)
print(f"Imagenetteでのゼロショット分類の精度:{accuracy * 100:.2f}%")
上記のスニペットは、次の出力を生成します:

CLIPモデルは、Imagenetteデータセットで非常に優れたパフォーマンスを発揮し、高い精度を達成しました。この高いパフォーマンスは、高品質な画像と比較的少数のクラスがデータセットに含まれていることによるものであり、モデルが画像を対応するテキストの説明と整合させやすくなっているためです。CLIPは、通常、224x224ピクセル程度にリサイズされた画像を使用してトレーニングされた、4億枚の画像-テキストペアの巨大なデータセットでトレーニングされており、広範な視覚的およびテキストデータにわたる一般化を学習するのに役立ちました。
ただし、低解像度の画像やクラス数が多いデータセットを使用すると、モデルのパフォーマンスは異なります。たとえば、32x32ピクセルの画像を使用したCIFAR-10データセットでモデルをテストした場合、精度は94.76%に低下しました。同様に、102のクラスを持つSaulLu/Caltech-101データセットでテストした場合、画像の品質のばらつきやクラス数の増加により、精度は81.21%に低下しました。
注意:SaulLu/Caltech-101 (opens new window)、CIFAR-10 (opens new window)の結果を含む完全なノートブックをここで見つけることができます。

これらの課題にもかかわらず、CLIPは特にトレーニングデータが制限されている場合やトレーニングデータがない場合に優れた選択肢です。ゼロショット分類を実行し、広範なタスクを処理する能力により、従来のモデルでは不十分なシナリオで価値のあるツールとなります。



