
データは今日のほとんどの組織の中心にあります。データのボリュームが爆発的に増加する中、企業はデータを効果的に格納、処理、分析する方法を見つけなければなりません。これにより、データベース市場が急速に拡大し、企業は伝統的なSQLデータベースと新しいベクトルデータベースの両方を利用してさまざまなタスクを達成しています。
しかし、各種類のデータベースにはトレードオフがあります。伝統的なSQLデータベースは、構造化データに対して一貫性、正確性、使いやすさを提供しますが、ベクトルデータベースは非構造化データの大量の高速かつスケーラブルな処理に最適化されています。しかし、両方を選ぶ必要はありません。両方の利点を兼ね備えたデータベースがあればどうでしょうか?
このブログでは、テーブルの作成やインデックスの定義から高度なSQLベクトル検索まで、MyScaleの使い方について詳しく見ていきます。最後に、MyScaleを他のデータベースと比較し、なぜMyScaleが優れているのかを見ていきます。それでは、始めましょう。
# MyScaleとは
MyScale (opens new window)は、AIアプリケーションのために大量のデータを管理するために特別に設計され最適化されたクラウドベースのSQLベクトルデータベースです。MyScaleは、SQLデータベースであるClickHouse (opens new window)の上に構築されており、ベクトル類似検索の機能と完全なSQLサポートを組み合わせています。1つのインターフェースで、SQLクエリは複雑なAIの要求を処理するために異なるデータモダリティを同時にかつ迅速に活用することができます。
専門のベクトルデータベースとは異なり、MyScaleはベクトル検索アルゴリズムと構造化データベースを調和させ、同じデータベース内でベクトルデータと構造化データの両方を管理することができます。この統合により、コミュニケーションの効率化、適応可能なメタデータフィルタリング、SQLとベクトルの結合クエリのサポート、汎用性の高い汎用データベースに関連する成熟したツールとの互換性などの利点が得られます。要するに、MyScaleは統一されたソリューションを提供し、AIデータ管理の複雑さに対処するための包括的で効率的かつ学習しやすいアプローチを提供します。
# MyScaleでクラスターを起動する方法
プロジェクトでMyScaleを使用し始める前に、まずアカウントを作成し、データを格納するクラスターを作成する必要があります。 以下に手順を示します:
- myscale.com (opens new window)でMyScaleアカウントにサインイン/サインアップします。
- アカウントが作成されたら、ページの右側にある「+ 新しいクラスター」ボタンをクリックします。
- クラスターの名前を入力し、「次へ」ボタンを押します。
- クラスターの作成が完了するまで待ちます。数秒かかります。
クラスターが作成されると、ポップアップボタンに「クラスターの起動に成功しました」というテキストが表示されます。
注意:
クラスターが作成された後、独自のデータがない場合は、クラスターに事前に用意されたサンプルデータをインポートするオプションもあります。ただし、このチュートリアルでは独自のデータを読み込みます。
次に、作業環境を設定し、実行中のクラスターにアクセスする必要があります。それをやってみましょう。
# 環境の設定
MyScaleを環境で使用するには、以下が必要です:
- Python:MyScaleはデータベースとのやり取りに使用するPythonクライアントライブラリを提供しているため、システムにPythonがインストールされている必要があります。PCにPythonがインストールされていない場合は、Pythonの公式ウェブサイト (opens new window)からダウンロードできます。
- MyScale Pythonクライアント:
pipを使用してClickHouseクライアント (opens new window)パッケージをインストールします:
pip install clickhouse-connect
実行が完了したら、次のコマンドを入力してインストールが正常に行われたか確認できます:
pip show clickhouse-connect
ライブラリがインストールされている場合、パッケージに関する情報が表示されます。それ以外の場合はエラーメッセージが表示されます。
# クラスターとの接続
次のステップは、Pythonアプリをクラスターに接続することです。接続には次の詳細が必要です:
- クラスターホスト
- ユーザー名
- パスワード
詳細を取得するには、MyScaleのプロフィールに戻り、「アクション」テキストの下にある縦に並んだ3つの点をホバーし、「接続の詳細」をクリックします。
「接続の詳細」をクリックすると、次のボックスが表示されます:
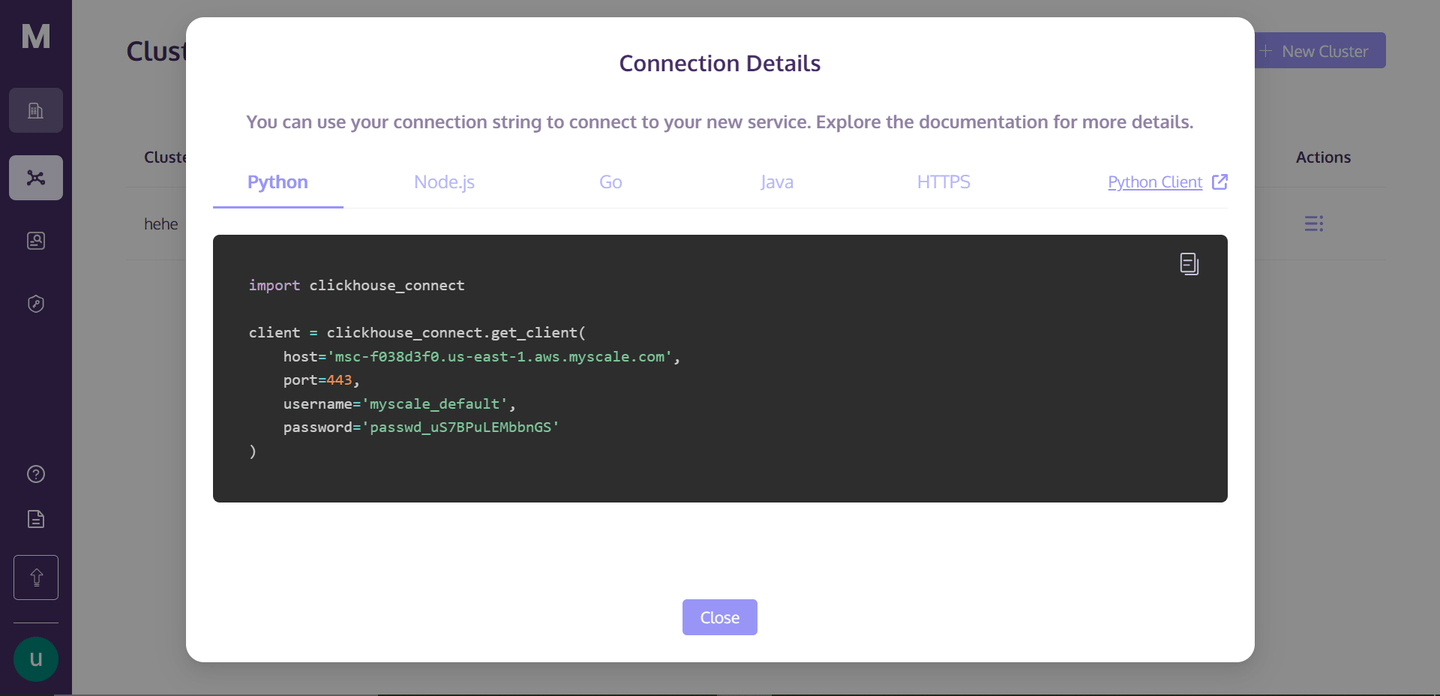
これらはクラスターに接続するために必要な接続の詳細です。ディレクトリにPythonのノートブックファイルを作成し、以下のコードをノートブックセルにコピーして実行します。セルを実行すると、クラスターとの接続が確立されます。
# データベースの作成
次のステップは、クラスター上にデータベースを作成することです。以下の方法で作成できます:
client.command("""
CREATE DATABASE IF NOT EXISTS getStart;
""")
このコマンドは、同じ名前のデータベースが存在するかどうかをまずチェックし、存在しない場合はgetStartという名前のデータベースを作成します。
# MyScaleを使用してテーブルを作成する
MyScaleでテーブルを作成するための基本的な構文は次のとおりです:
CREATE TABLE [IF NOT EXISTS] db_name.table_name
(
column_name1 data_type [options],
column_name2 data_type [options],
...
)
ENGINE = engine_type
[ORDER BY expression]
[PRIMARY KEY expression];
上記の構文では、db_nameとtable_nameを任意の値に置き換えることができます。括弧内では、テーブルの列を定義します。各列(column_name1、column_name2など)は、それぞれのデータ型(data_type)で定義され、デフォルト値や制約などの追加の列オプション([options])をオプションで指定することもできます。
注意:
MyScaleでテーブルを作成する方法を見ているだけです。次のステップでは、データに基づいて実際のテーブルを作成します。
ENGINE = engine_typeの句は、データの保存と処理方法を決定する上で重要です。ORDER BY expressionを指定することで、データがテーブル内で物理的にどのように保存されるかを決定することができます。PRIMARY KEY expressionは、データの取得効率を向上させるために使用されます。従来のSQLデータベースとは異なり、ClickHouseでは主キーは一意性を強制しませんが、クエリ処理を高速化するためのパフォーマンス最適化ツールとして使用されます。
# テーブルにデータをインポートしてインデックスを作成する
実際のデータセットをインポートして、データセットに対して列を作成する方法を実際に試してみましょう。
import pandas as pd
# URL of the data
url = 'https://d3lhz231q7ogjd.cloudfront.net/sample-datasets/quick-start/categorical-search.csv'
# Reading the data directly into a pandas DataFrame
data = pd.read_csv(url)
これにより、指定されたURLからデータセットがダウンロードされ、データフレームとして保存されます。データは次のようになります:
| id | data | date | label |
|-------|---------------------------------------------------|------------|----------|
| 0 | [0,0,1,8,7,3,2,5,0,0,3,5,7,11,31,13,0,0,0,... | 2030-09-26 | person |
| 1 | [65,35,8,0,0,0,1,63,48,27,31,19,16,34,96,114,3... | 1996-06-22 | building |
| 2 | [0,0,0,0,0,0,0,4,1,15,0,0,0,0,49,27,0,0,0,... | 1975-10-07 | animal |
| 3 | [3,9,45,22,28,11,4,3,77,10,4,1,1,4,3,11,23,0,... | 2024-08-11 | animal |
| 4 | [6,4,3,7,80,122,62,19,2,0,0,0,32,60,10,19,4,0,... | 1970-01-31 | animal |
| ... | ... | ... | ... |
| 99995 | [9,69,14,0,0,0,1,24,109,33,2,0,1,6,13,12,41,... | 1990-06-24 | animal |
| 99996 | [29,31,1,1,0,0,2,8,8,3,2,19,19,41,20,8,5,0,0,6... | 1987-04-11 | person |
| 99997 | [0,1,116,99,2,0,0,0,0,2,97,117,6,0,5,2,101,86,... | 2012-12-15 | person |
| 99998 | [0,20,120,67,76,12,0,0,8,63,120,55,12,0,0,0,... | 1999-03-05 | building |
| 99999 | [48,124,18,0,0,1,6,13,14,70,78,3,0,0,9,15,49,4... | 1972-04-20 | building |
次のステップは、MyScaleクラスタに実際のテーブルを作成し、このデータを保存することです。それをやってみましょう。
client.command("""
CREATE TABLE getStart.First_Table (
id UInt32,
data Array(Float32),
date Date,
label String,
CONSTRAINT check_data_length CHECK length(data) = 128
) ENGINE = MergeTree()
ORDER BY id
""")
上記のコマンドは、First_Tableという名前のテーブルを作成します。ここには、列名とデータ型も指定されています。制約を選択する理由は、後の部分でこの列にベクトル検索を適用するため、データ列のベクトルが完全に同じであることを望んでいるからです。
# 定義されたテーブルにデータを挿入する
テーブル作成プロセスの後、次のステップはテーブルにデータを挿入することです。したがって、前にダウンロードしたデータを挿入します。
# Convert the data vectors to float, so that it can meet the defined datatype of the column
data['data'] = data['data'].apply(lambda x: [float(i) for i in ast.literal_eval(x)])
# Convert the 'date' column to the 'YYYY-MM-DD' string format
data['date'] = pd.to_datetime(data['date']).dt.date
# Define batch size and insert data in batches
batch_size = 1000 # Adjust based on your needs
num_batches = len(data) // batch_size
for i in range(num_batches):
start_idx = i * batch_size
end_idx = start_idx + batch_size
batch_data = data[start_idx:end_idx]
client.insert("getStart.First_Table", batch_data.to_records(index=False).tolist(), column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches} inserted.")
上記のコードは、定義されたテーブルに基づいていくつかの列のデータ型を変更します。データ量が多いため、データをバッチ形式で挿入しています。したがって、1000のようなバッチを作成してデータを挿入しています。
# ベクトルインデックスを作成する
次のステップは、ベクトルインデックスを作成することです。やり方を見てみましょう。
client.command("""
ALTER TABLE getStart.First_Table
ADD VECTOR INDEX vector_index data
TYPE MSTG
""")
注意:
ベクトルインデックスの作成時間は、テーブル内のデータに依存します。
MSTGベクトルインデックスは、MyScale社内で作成され、速度、精度、コスト効率の面で競合他社を大きく上回っています。
ベクトルインデックスが正常に作成されたかどうかを確認するために、次のコマンドを試してみましょう:
get_index_status="SELECT status FROM system.vector_indices WHERE table='First_Table'"
print(f"The status of the index is {client.command(get_index_status)}")
コードの出力は「The status of the index is Built」となる必要があります。"Built"という言葉は、インデックスが正常に作成されていることを意味します。
注意:
現時点では、MyScaleではテーブルごとに1つのインデックスの作成しか許可されていません。しかし、将来的には1つのテーブルに複数のインデックスを作成することができるようになります。
# MyScaleを使用してさまざまなタイプのSQLクエリを書く
MyScaleでは、基本的なものから複雑なものまで、さまざまな種類のクエリを書くことができます。まずは非常に基本的なクエリから始めましょう。
result=client.query("SELECT * FROM getStart.First_Table ORDER BY date DESC LIMIT 1")
for row in result.named_results():
print(row["id"], row["date"], row["label"],row["data"])
ベクトルの類似スコアを使用して、エンティティの最も近い隣接点を見つけることもできます。抽出された結果を取得し、その最も近い隣接点を取得してみましょう:
results = client.query(f"""
SELECT id, date, label,
distance(data, {result.first_item["data"]}) as dist FROM getStart.First_Table ORDER BY dist LIMIT 10
""")
for row in results.named_results():
print(row["id"], row["date"], row["label"])
注意:
first_itemメソッドは、結果配列から最初の要素を取得します。
これにより、指定されたエントリの上位10件の最も近い隣接点が表示されます。
# MyScaleを使用して自然言語クエリを書く
MyScaleを使用して自然言語クエリを実行することもできますが、そのためには、ニューラルネットワークからの特徴を持つ新しいデータを含む別のテーブルを作成する必要があります。
テーブルを作成する前に、データをロードしましょう。元のファイルはこちら (opens new window)からダウンロードできます。
with open('/`../../modules/state_of_the_union.txt`', 'r', encoding='utf-8') as f:
texts = [line.strip() for line in f if line.strip()]
このコマンドは、テキストファイルをロードし、個々のドキュメントに分割します。これらのテキストドキュメントをベクトル埋め込みに変換するために、OpenAI APIを使用します。これをインストールするには、ターミナルを開き、次のコマンドを入力します:
pip install openai
インストールが完了したら、埋め込みモデルをセットアップし、埋め込みを取得できます:
import os
# Import OPENAI
import openai
# Import pandas
import pandas as pd
# Set the environment variable for OPENAI API Key
os.environ["OPENAI_API_KEY"] = "your_api_key_here"
# Get the embedding vectors of the documents
response = openai.embeddings.create(
input = texts,
model = 'text-embedding-ada-002')
# The code below creates a dataframe. We will insert this dataframe directly to the table
embeddings_data = []
for i in range(len(response.data)):
embeddings_data.append({'id': i, 'data': response.data[i].embedding, 'content': texts[i]})
# Convert to Pandas DataFrame
df_embeddings = pd.DataFrame(embeddings_data)
上記のコードは、テキストドキュメントを埋め込みに変換し、それをテーブルに挿入するデータフレームを作成します。さて、テーブルの作成に進みましょう。
client.command("""
CREATE TABLE getStart.natural_language (
id UInt32,
content String,
data Array(Float32),
CONSTRAINT check_data_length CHECK length(data) = 1536
) ENGINE = MergeTree()
ORDER BY id;
""")
次のステップは、データをテーブルに挿入することです。
# Set the batch size to 20
batch_size = 20
# Find the number of batches
num_batches = len(df_embeddings) // batch_size
# Insert the data in the form of batches
for i in range(num_batches + 1):
# Define the starting point for each batch
start_idx = i * batch_size
# Define the last index for each batch
end_idx = min(start_idx + batch_size, len(df_embeddings))
# Get the batch from the main DataFrame
batch_data = df_embeddings[start_idx:end_idx]
# Insert the data
if not batch_data.empty:
client.insert("getStart.natural_language",
batch_data.to_records(index=False).tolist(),
column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches + 1} inserted.")
データの挿入処理には、データのサイズに応じて時間がかかる場合がありますが、次のように進捗状況を監視することができます。さて、次はテーブルのインデックスを作成する作業に移りましょう。
client.command("""
ALTER TABLE getStart.natural_language
ADD VECTOR INDEX vector_index_new data
TYPE MSTG
""")
インデックスが作成されたら、クエリを開始する準備が整いました。
# Convert the query to vector embeddigs
response = openai.embeddings.create(
# Write your query in the input parameter
input = 'What did the president say about Ketanji Brown Jackson?',
model = 'text-embedding-ada-002'
)
# Get the results
results = client.query(f"""
SELECT id,content,
distance(data, {list(response.data[0].embedding)}) as dist FROM getStart.natural_language ORDER BY dist LIMIT 5
""")
for row in results.named_results():
print(row["id"] ,row["content"], row["dist"])
以下の結果が表示されるはずです。
| ID | Text | Score |
| --- | ---------------------------------------------------------------------------------------------------------------- | ------------------- |
| 269 | And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson... | 0.33893799781799316 |
| 331 | The Cancer Moonshot that President Obama asked me to lead six years ago. | 0.4131550192832947 |
| 80 | Vice President Harris and I ran for office with a new economic vision for America. | 0.4235861897468567 |
| 328 | This is personal to me and Jill, to Kamala, and to so many of you. | 0.42732131481170654 |
| 0 | Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet... | 0.427462637424469 |
これはいくつかのクエリの例ですが、自分のニーズやプロジェクトに応じて複数の複雑なクエリを書くことができます。

# MyScaleがSQLベクトルデータベース市場をリードする
MyScaleは、他の統合ベクトルデータベース(pgvectorなど)や専門のベクトルデータベース(Pineconeなど)よりも優れた精度、パフォーマンス、コスト効率を備えて、SQLベクトルデータベース市場で際立っています。MyScaleは、ベクトル検索の精度がはるかに優れており、クエリ処理がより高速で、かつ低コストで行われます。さらに、SQLインターフェースは開発者にとって非常に使いやすく、最小限の学習で最大の価値を提供します。
MyScaleは本当にゲームを変えます。ベクトルを介したより良い検索だけでなく、複雑なメタデータフィルタを含むシナリオでの高精度とクエリ毎秒(QPS)を提供します。さらに重要なことは、サインアップすると、最大500万のベクトルを処理できるS1ポッドを無料で使用できるということです。パワフルでコスト効果の高いベクトルデータベースソリューションを必要とするすべての人にとって、これは選択肢となるでしょう。
# MyScaleはAI統合によりアプリケーションを強化します
MyScaleは、AI技術との統合により、より堅牢なアプリケーションを作成することができます。以下では、MyScaleアプリケーションをより向上させるいくつかの統合を紹介します。
LangChainとの統合: AIアプリケーションのユースケースが日々増えている現代の世界では、LLMとデータベースを組み合わせるだけでは堅牢なAIアプリケーションを作成することはできません。より良いアプリケーションを開発するためには、さまざまなフレームワークやツールを使用する必要があります。その点で、MyScaleは完全なLangChainとの統合 (opens new window)を提供し、高度な検索戦略を備えた効果的で信頼性の高いAIアプリケーションを作成することができます。特に、MyScaleのセルフクエリリトリーバー (opens new window)は、テキストをメタデータフィルタ付きのベクトルクエリに変換する柔軟で強力なメソッドを実装し、多くの実世界のシナリオで高い精度を実現します。
OpenAIとの統合: MyScaleをOpenAIと統合することで、AIアプリケーションの精度と堅牢性を大幅に向上させることができます。OpenAIは、コンテキストと意味を保持した最高の埋め込みベクトルを取得することができます。これは、自然言語クエリを使用したベクトル検索やデータからの埋め込みの抽出において非常に重要です。これにより、アプリケーションの精度と正確性を向上させることができます。詳細な理解のためには、OpenAIとの統合 (opens new window)のドキュメントをご覧ください。
最近、OpenAIはGPTをリリースし、開発者がGPTやチャットボットを簡単にカスタマイズできるようにしました。MyScaleはこの変化に適応し、構造化データのフィルタリングとSQL WHERE句を介したセマンティック検索により、GPTモデルにサーバーサイドのコンテキストをシームレスに注入することで、RAGシステムの開発を最適化しています。MyScaleを使用して、知識ベースのストレージを効率的に最適化し、GPT間での共有を可能にする、GPT StoreでMyScaleGPT (opens new window)を試してみることもできますし、知識ベースをGPTにフックする (opens new window)こともできます。
# 結論
AIと機械学習のアプリケーションが増えるにつれて、MyScaleのような現代のAIアプリケーションに特化したデータベースへの需要が高まっています。MyScaleは、従来のデータベースの速度と機能性を最新のベクトル検索機能と組み合わせた、最先端のSQLベクトルデータベースです。この組み合わせは、AIアプリケーションの向上に最適です。
最も重要なことは、MyScaleがSQL構文と完全に互換性があり、SQLに精通したすべての開発者がMyScaleをすばやく始めることができるということです。さらに、MyScaleのコストは他のベクトルデータベースよりもはるかに低いです。 (opens new window)これにより、大量のデータを管理する企業にとって、SQLの使い慣れた感覚とパワーを活かした本格的なGenAIアプリケーションの構築において明確な優位性を提供します。MyScaleの最新情報を知りたい方は、ぜひDiscord (opens new window)またはTwitter (opens new window)に参加してください。



