
大規模言語モデル (opens new window)(LLM)は、自然言語処理(NLP)の分野を革新し、技術との対話の新しい方法を提供しています。GPT (opens new window)やBERT (opens new window)などの高度なモデルは、意味理解の新たな時代を切り開きました。これらのモデルは、コンピュータが人間のようなテキストを処理・生成することを可能にし、人間のコミュニケーションと機械の解釈のギャップを埋める役割を果たしています。LLMは、感情分析、機械翻訳、質問応答、テキスト要約、チャットボット、仮想アシスタントなど、さまざまなアプリケーションの動力源となっています。
実用的な応用がある一方で、大規模言語モデル(LLM)には独自の課題もあります。それらは一般化されるよう設計されているため、特定性に欠ける可能性があります。また、過去のデータで訓練されているため、常に最新の情報を提供するわけではありません。これにより、LLMが不正確または時代遅れの応答を生成し、ホールシネーションと呼ばれる現象が生じることがあります。これは、モデルが訓練データの欠如によりエラーや予測不可能な情報を生成する場合に発生します。
リトリーバル増強生成(RAG)システムは、特定性の欠如やリアルタイムの更新などの問題に対処するために使用され、LLMの責任ある展開を向上させる潜在的な解決策を提供します。
# RAGとは
2020年、Metaの研究者は、リトリーバル増強生成(RAG)を提案しました。これは、LLMの自然言語生成 (opens new window)(NLG)能力と情報検索(IR)コンポーネントを組み合わせて、出力を最適化するものです。これは、クエリに応答する前に、トレーニングデータソースの外部の信頼性のある知識源を参照します。これにより、モデルの再トレーニングを必要とせずにLLMの機能を拡張し、さまざまなコンテキストで出力の関連性、精度、および使いやすさを向上させることができます。
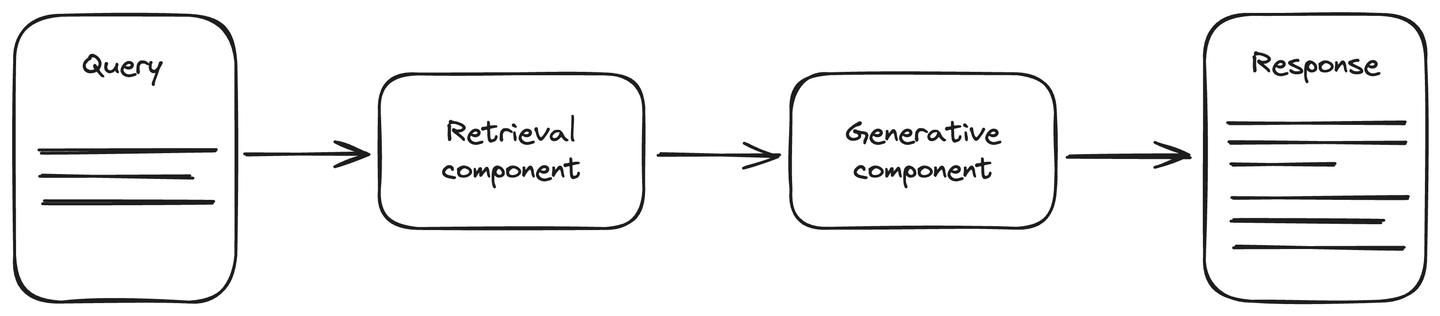
RAGアーキテクチャには、生成型AIタスク中の精度向上のための最新のデータソースが含まれています。それはリトリーバルコンポーネントと生成コンポーネントの2つの主要なコンポーネントに分かれています。リトリーバルコンポーネントは、データソース(主にベクトルデータベース)に接続され、クエリに関する更新された情報を取得します。この情報は、クエリとともに生成コンポーネントに提供されます。生成コンポーネントは、LLMモデルであり、応答を生成します。RAGはLLMの理解を向上させ、生成される応答はより正確で最新のものとなります。
関連記事:RAGから期待できること (opens new window)
# RAGシステムのリトリーバルコンポーネントの設定方法
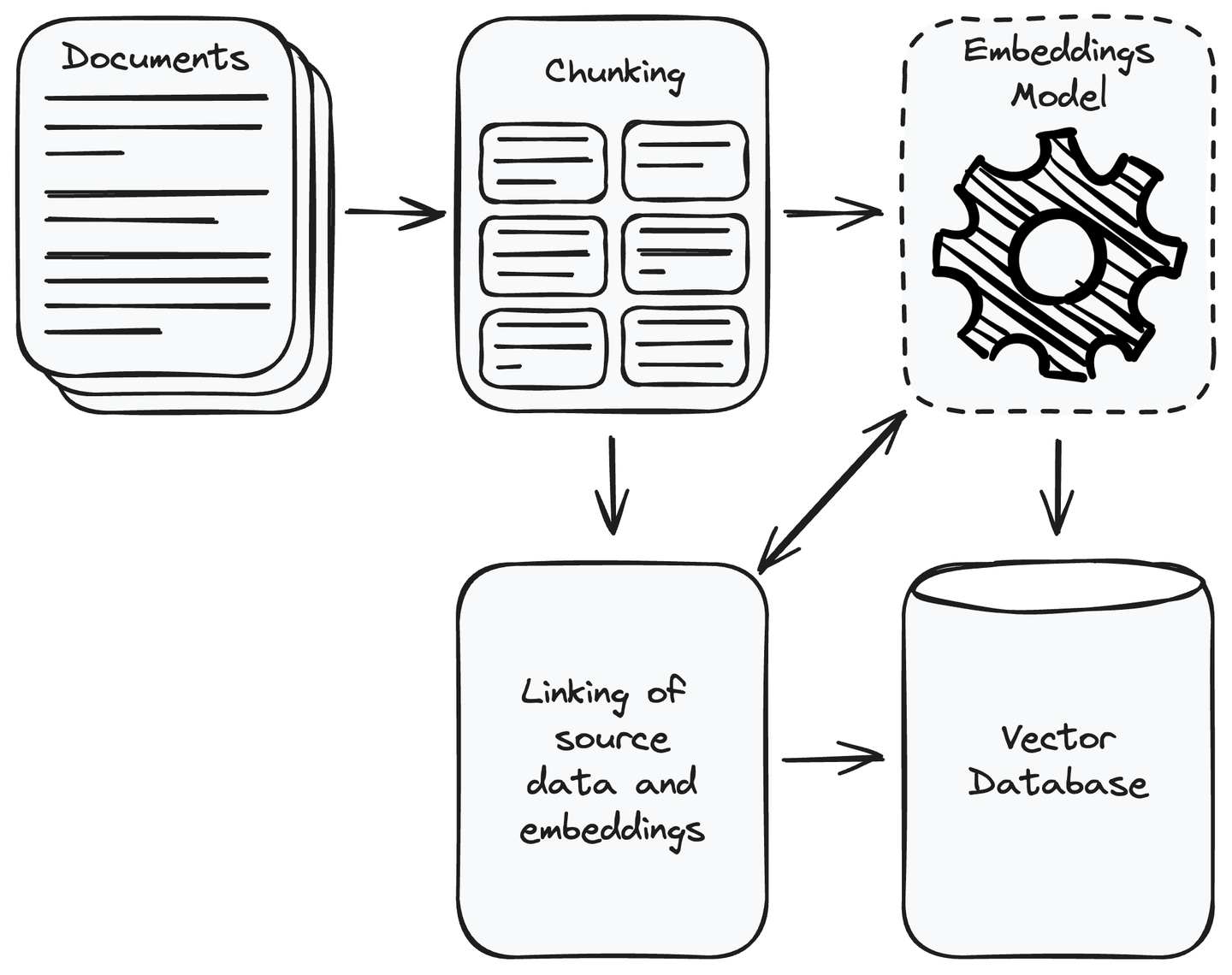
まず、アプリケーションに必要なすべてのデータを収集する必要があります。データ収集が完了したら、関連のないデータを削除します。収集したデータを管理可能な小さなチャンクに分割し、埋め込みモデル (opens new window)を使用してこれらのチャンクをベクトル表現に変換します。ベクトルは、意味的に類似したコンテンツが近くに配置される数値表現です。これにより、システムはユーザーのクエリとデータソースの関連情報を理解し、一致する情報を見つけることができます。ベクトルをベクトルデータベースに保存し、ソースデータのチャンクをその埋め込みとリンクさせます。これにより、ユーザークエリに類似したベクトルのデータチャンクを取得するのに役立ちます。
MyScale (opens new window)は、ClickHouse (opens new window)をベースとしたクラウドベースのベクトルデータベースであり、通常のSQLクエリとベクトルデータベースの強みを組み合わせています。これにより、画像の特徴やテキストの埋め込みなどの高次元データを通常のSQLクエリを使用して保存および検索することができます。MyScaleは、ベクトルの比較が重要なAIアプリケーションに特に強力です。AIおよび機械学習のタスクで大量のベクトルデータを扱う開発者にとって、費用対効果の高い実用的なソリューションとなっています。
さらに、MyScaleは他のオプションよりも費用対効果が高く、より高速で正確です。その利点を体験してもらうために、MyScaleは無料ティアで500万件のベクトルストレージを提供しています。これにより、ベクトルデータベースをAIおよび機械学習の取り組みにおいて費用対効果の高いユーザーフレンドリーなソリューションとして提供しています。
関連記事:RAG対応のチャットボットの構築 (opens new window)
# RAGシステムの動作原理
リトリーバルコンポーネントの設定が完了したら、RAGシステムでそれを利用することができます。ユーザーのクエリに応答するために、関連情報を取得し、それをユーザーのクエリにコンテキストとして追加してから言語モデルに渡すことができます。リトリーバルコンポーネントを使用して関連情報を取得する方法を理解しましょう。
# クエリに関連情報を追加する
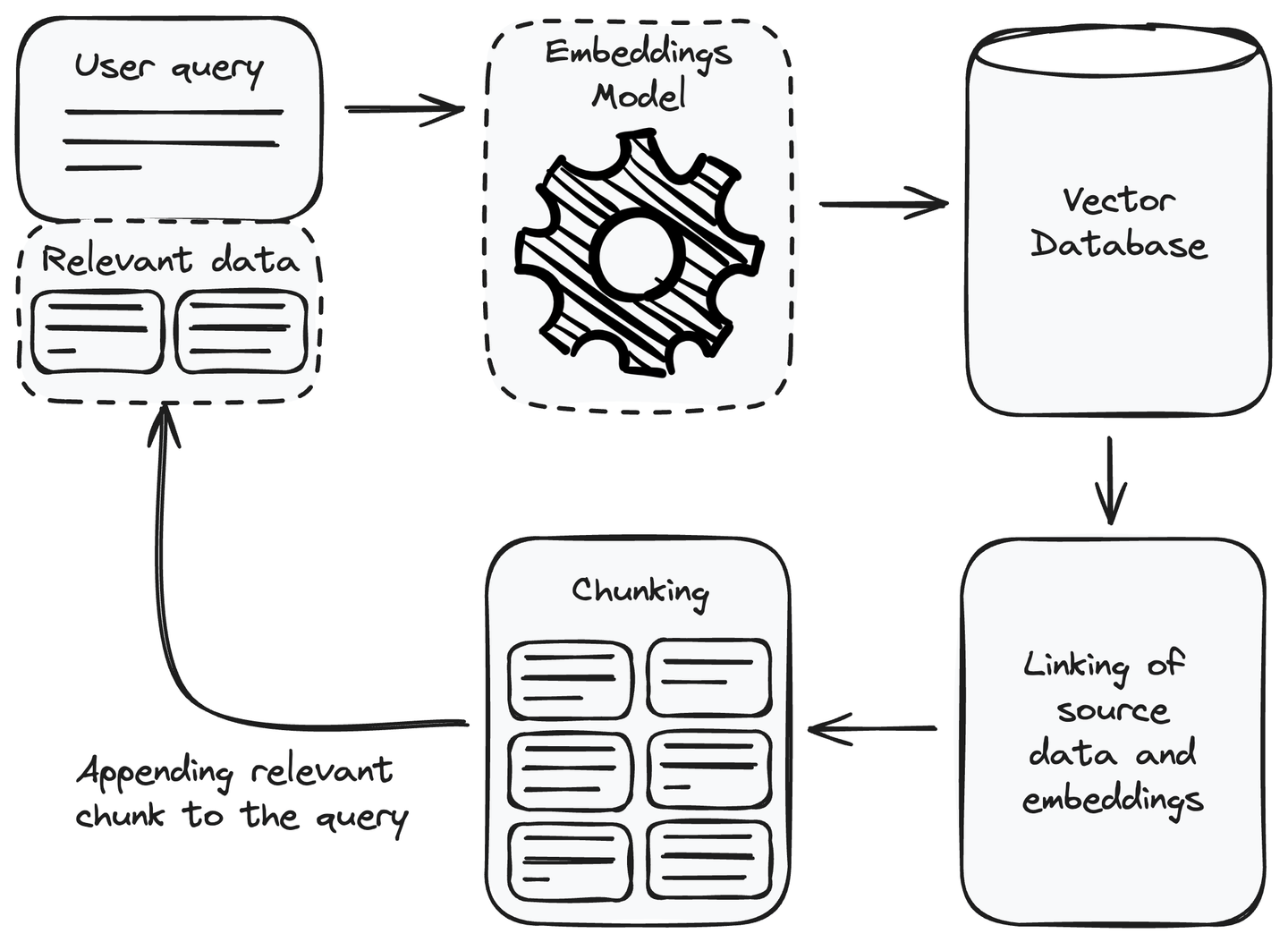
ユーザーのクエリを受け取ったら、まずユーザーのクエリを埋め込みまたはベクトル表現に変換する必要があります。リトリーバルコンポーネントの設定時に使用した埋め込みモデルと同じ埋め込みモデルを使用します。ユーザーのクエリをベクトル表現に変換した後、ユークリッド距離 (opens new window)やコサイン類似度 (opens new window)などの測定方法を使用して、ベクトルデータベースから類似する
# LLMを使用した応答の生成
これで、クエリと関連する情報を持っています。ユーザーのクエリと取得したデータをLLM(生成コンポーネント)に入力します。LLMはユーザーのクエリを理解し、提供されたデータを処理することができます。リトリーバルコンポーネントから受け取った情報に基づいて、LLMはユーザーのクエリに対する応答を生成します。
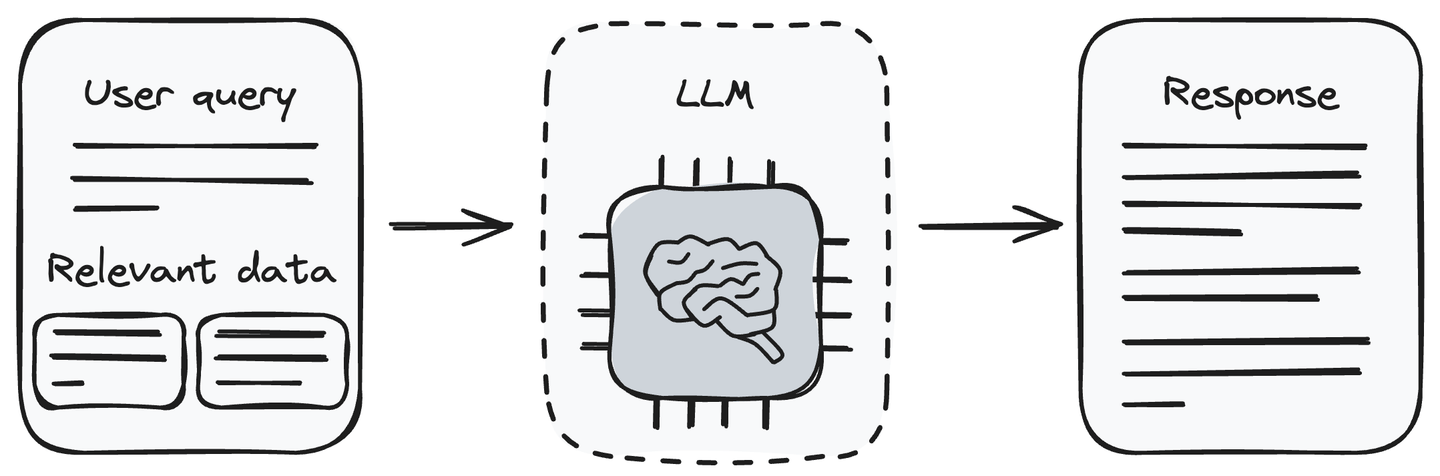
ユーザーのクエリに関連情報を渡すことにより、LLMのホールシネーションの問題が解消されます。これにより、LLMはユーザーのクエリに関連情報を使用して応答を生成することができます。
注意:モデルの精度を確保するために、定期的に最新情報でデータベースを更新することを忘れないでください。
# RAGのいくつかの応用例
RAGシステムは、正確で文脈に即した情報検索が必要なさまざまなアプリケーションで使用することができます。これにより、生成される応答の精度、タイムリネス、信頼性が向上します。以下に、RAGシステムのいくつかの応用例について説明します。
- 特定ドメインの質問応答:RAGシステムが特定のドメインの質問に直面した場合、外部の知識源、データベース、または特定ドメインのドキュメントに動的にアクセスすることで、文脈に即した関連情報を反映した応答を生成します。これは、医療、法的解釈、歴史的研究、技術トラブルシューティングなど、さまざまなドメインで役立ちます。
- 事実の正確性:事実の正確性は、生成されるコンテンツや応答が正確で検証されたデータと一致していることを確保する上で重要です。不正確な情報が発生する可能性がある場合、RAGは事実の正確性を優先し、信頼性のある情報を提供します。これは、ニュース報道、教育コンテンツ、情報の信頼性と信頼性が重要なシナリオなど、さまざまなアプリケーションにおいて重要です。
- 研究クエリ:RAGシステムは、研究クエリに対応するために、知識源から関連する最新の情報を動的に取得するのに役立ちます。たとえば、研究者が特定の科学分野の最新の進展に関連するクエリを入力した場合、RAGシステムはリトリーバルコンポーネントを活用して最新の研究論文、出版物、関連データにアクセスし、研究者が文脈に即した正確かつ最新の情報を受け取ることを保証します。
関連記事:レコメンデーションシステムの構築方法 (opens new window)

# RAGシステムの構築における課題
RAGシステムにはさまざまなユースケースと利点がありますが、いくつかの独自の制約も存在します。以下にそれらをまとめます。
- 統合:リトリーバルコンポーネントをLLMベースの生成コンポーネントに統合することは困難な場合があります。異なる形式の複数のデータソースで作業する場合、複数のモジュールを使用して統合する前に、すべてのデータソースの一貫性を確保してください。
- データの品質:RAGシステムは、接続されたデータソースに依存しています。RAGシステムの品質は、低品質のコンテンツの使用、複数のデータソースの場合の異なる埋め込みの使用、または一貫性のないデータ形式の使用など、さまざまな理由で低下する可能性があります。データの品質を維持するようにしてください。
- スケーラビリティ:外部データの量が増えるにつれて、RAGシステムのパフォーマンスが低下する可能性があります。データを埋め込みに変換し、類似するデータの意味を比較し、リアルタイムでデータを取得するタスクは、計算量が増える可能性があります。これにより、RAGシステムの動作が遅くなる場合があります。この問題に対処するために、MyScaleを使用することができます。MyScaleは、LAION 5Mデータセットで390 QPS(クエリ/秒)、95%の再現率、平均クエリ待ち時間17msを提供することで、この問題を解決しています。
# 結論
RAGは、知識ベースをLLMにアタッチすることで、LLMの機能を向上させるための手法の1つです。言語生成能力を持つ検索エンジンとして理解することができます。これらのシステムは、再トレーニングや微調整のコストなしにLLMのホールシネーションの問題を解決します。ユーザーのクエリに対して外部データソースを使用することにより、特に事実、最新情報、または定期的に更新されるデータとの作業時に、より正確で最新の応答を提供します。RAGシステムの利点にもかかわらず、制約も存在します。
MyScaleは、ClickHouse、高度なベクトル検索アルゴリズム、および共通のSQLベクトル最適化の強みを組み合わせた、大規模かつ複雑なRAGアプリケーションに対する強力なソリューションを提供します。MyScaleは、コストとスケーラビリティを含むすべての要素を考慮してAIアプリケーションに特化して設計されています。さらに、LangChain (opens new window)やLlamaIndex (opens new window)などの有名なAIフレームワークとの統合も提供しています。これらの特性と機能により、MyScaleは次のAIアプリケーションに最適な選択肢となります。
ご意見やフィードバックがありましたら、Twitter (opens new window)またはDiscord (opens new window)までお気軽にお問い合わせください。



