
Retrieval-augmented generation (RAG) (opens new window)は、自然言語処理(NLP)の領域での大きなブレークスルーです。そのシンプルさと効率性により、NLPのほとんどのタスクが最適化されています。検索システム(ベクトルデータベース)と生成モデル(LLM)の強みを組み合わせることで、RAGはテキスト生成、翻訳、質問応答などのAIシステムのパフォーマンスを大幅に向上させます。
ベクトルデータベースの統合は、RAGシステムのパフォーマンス革命の重要な要素です。RAGとベクトルデータベースの関係と、どのように協力してこれらの素晴らしい結果を実現しているかを探ってみましょう。
# RAGモデルの概要
RAGは、大規模言語モデル(LLM)のパフォーマンスを向上させるために特別に設計された技術です。RAGは、ベクトルデータベースからユーザーのクエリに関連する情報を取得し、LLMに参照として提供します。このプロセスにより、LLMの応答の品質が大幅に向上し、より正確で関連性のあるものになります。以下の図は、RAGモデルの動作方法 (opens new window)を簡単に示しています。
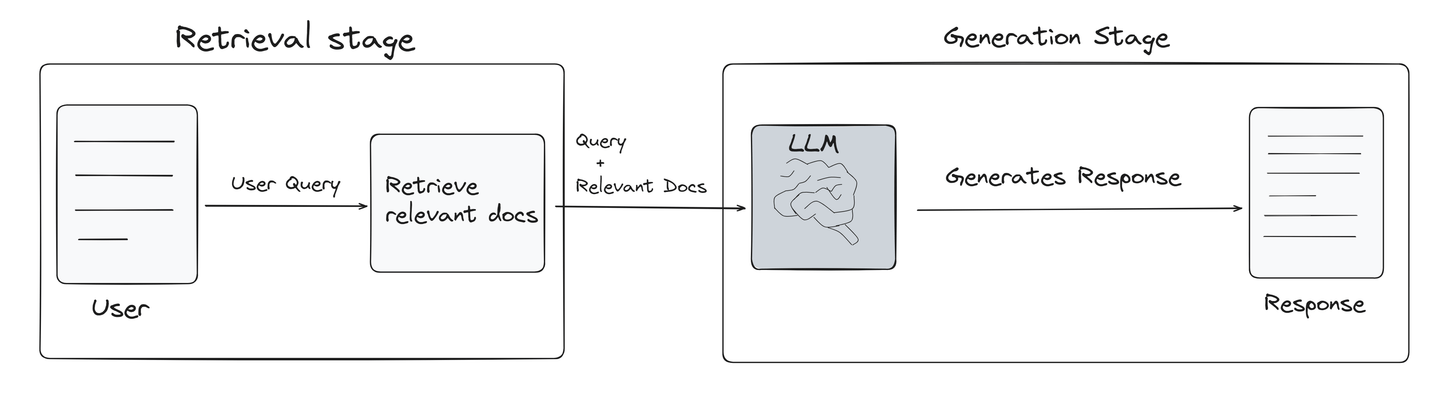
検索ステージ: RAGはまず、類似検索の力を使ってベクトルデータベースから最も関連性の高い情報を特定します。このステージは、最終的な出力の品質の基盤となるRAGシステムの最も重要な部分です。
生成ステージ: 関連する情報が取得されると、ユーザーのクエリと取得したドキュメントがLLMモデルに渡され、連続性、関連性、情報量のある新しいコンテンツが生成されます。
RAGの実装により、事実の不正確さ、時代遅れの知識、幻想などの主要な制限が解消され、ベクトルデータベースから関連性の高い最新の情報を取得することで、LLMの応答の正確性と信頼性が大幅に向上します。特に知識集約的なタスクでは、LLMの応答の正確性と信頼性が大幅に向上します。
さらに、情報の提供元を検証できるようにすることで、透明性と追跡性のレベルを導入します。LLMの生成能力と検索システムの情報提供能力を組み合わせたこのハイブリッドアプローチにより、幅広い複雑なクエリとタスクに動的に適応できるより堅牢で信頼性の高いAIアプリケーションが実現されます。
# ベクトルデータベースの役割
ベクトルデータベースは、数値ベクトル(埋め込み)の形式でデータを格納および管理するために設計された特殊なタイプのデータベースです。これらの埋め込みは、データの意味的な意味と文脈情報をエンコードします。データはテキスト、画像、音声など、どんな種類のデータでも構いません。ベクトルデータベースはこれらの埋め込みを効率的に格納し、類似検索を通じて埋め込みの迅速な検索を提供します。これらの機能は、情報検索、推薦システム、意味検索などのタスクで重要な役割を果たします。これらのデータベースは、データを複雑なパターンや関係を捉えるためにベクトル空間に変換することがよくある機械学習(ML)や人工知能(AI)のアプリケーションで特に有用です。
ベクトルデータベースの主な特徴は次のとおりです:
- 高次元データのサポート:これらのデータベースは、機械学習モデルで一般的に使用される高次元ベクトルデータを処理するために設計されています。
- 効率的な検索:これらのデータベースは、迅速に最も類似したベクトルを大規模なデータセットから見つけるための最適化された検索アルゴリズムを提供します。最も基本的な検索機能は最近傍探索であり、すべてのアルゴリズムはこのアプローチを最適化するように設計されています。
- スケーラビリティ:ベクトルデータベースは、大量のデータとユーザークエリを処理するために設計されています。これにより、成長するデータセットと増加する要求に対応できます。
- インデックス:これらのデータベースは、ベクトルの検索と比較のプロセスを高速化するために高度なインデックス技術を使用することがよくあります。
- 統合:これらのデータベースは、リアルタイムのデータ検索機能を提供するために、簡単に機械学習パイプラインに統合できます。
ベクトルデータベースは、画像認識、テキスト分析、推薦アルゴリズムなど、機械学習を活用するシステムで重要なコンポーネントです。これらのシステムでは、ベクトル化された大量のデータを迅速にアクセスして比較する能力が重要です。
# ベクトルデータベースがRAGのパフォーマンスを向上させる方法
ベクトルデータベースは、ワークフローのさまざまなステージを最適化することで、RAGシステムのパフォーマンスを大幅に向上させます。まず、テキストデータは埋め込みモデルを使用してベクトルに変換されます。この変換は重要であり、テキストデータを意味的な意味に基づいて効率的に格納および検索できる形式に変換します。
ベクトルデータベースの強みは、高度なインデックスメソッドにあります。データがベクトルに変換されると、HNSW(Hierarchical Navigable Small World)やIVF(Inverted File Index)などの高度なインデックスメソッドを使用してベクトルデータベースに保存されます。これらのインデックスメソッドは、ベクトルを迅速かつ効率的に検索できるようにベクトルを整理します。インデックスプロセスにより、クエリが行われると、システムは広範なデータセットから関連するベクトルを迅速に特定できます。
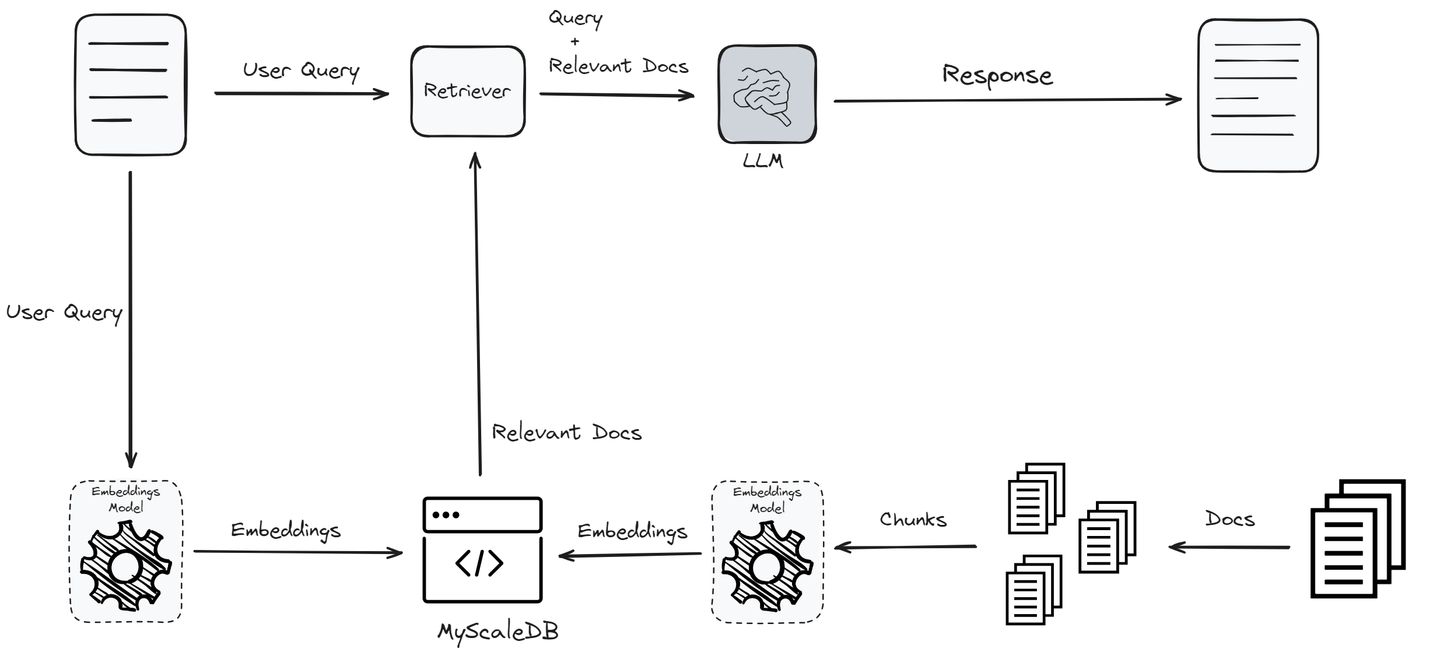
ユーザーがクエリを送信すると、同じ埋め込みモデルを使用してクエリもベクトルに変換されます。ベクトルデータベースは、クエリベクトルに最も類似したクラスタを探します。ベクトルデータベースは、クエリベクトルに意味的に最も近いベクトルのクラスタを検索します。この類似検索は、RAGシステムの基盤であり、ベクトルデータベースは迅速かつ正確に意味的に類似したベクトルを特定することによって、これを実現します。
類似したドキュメントは、リトリーバーに渡され、クエリと関連するドキュメントを組み合わせてLLMに送信され、応答の生成が行われます。ベクトルデータベースの使用により、リトリーバーは最も関連性の高い情報で作業することが保証されます。これにより、生成される応答の正確性と関連性が向上します。
ベクトルデータベースは、検索速度を向上させるだけでなく、大量のデータを効率的に処理します。このスケーラビリティは、大規模なデータセットを扱うアプリケーションにとって重要です。迅速かつ正確な検索を保証することで、ベクトルデータベースはリアルタイムのクエリングをサポートし、ユーザーに即座かつ関連性のある応答を提供します。

# 理想的なソリューション:専門のベクトルデータベース vs. SQLベクトルデータベース
実際のRAGシステムでは、検索の正確性(および関連するパフォーマンスのボトルネック)を克服するために、構造化データ、ベクトルデータ、キーワードデータのクエリを効率的に組み合わせる方法が必要です。
一部のベクトルデータベース(Pinecone、Weaviate、Milvusなど)は、最初からベクトル検索に特化して設計されています。これらのデータベースはこの領域で良好なパフォーマンスを発揮しますが、一般的なデータ管理機能にはやや制約があります。
- クエリの機能制約:メタデータの保存が制限されているため、複雑なクエリ(複数の条件、結合、集計を含むクエリなど)に対するサポートが制限されています。
- データ型の制約:主にベクトルと最小限のメタデータの保存に特化しているため、整数、文字列、日付などのさまざまなデータ型を処理する柔軟性に欠けています。
SQLベクトルデータベース (opens new window)は、伝統的なSQLデータベースの機能とベクトルデータベースの特殊な機能を統合した高度なシステムです。これらのシステムは、ベクトル検索アルゴリズムを構造化データ環境に直接統合することで、ベクトルデータと構造化データの両方を統一されたデータベースフレームワーク内で管理できるようにします。
この統合により、次のようないくつかの主な利点が得られます:
- データ型間のシームレスな通信。
- メタデータに基づいた柔軟なフィルタリング。
- SQLクエリとベクトルクエリの両方の実行サポート。
- 一般的なデータベース向けの既存のツールとの互換性。
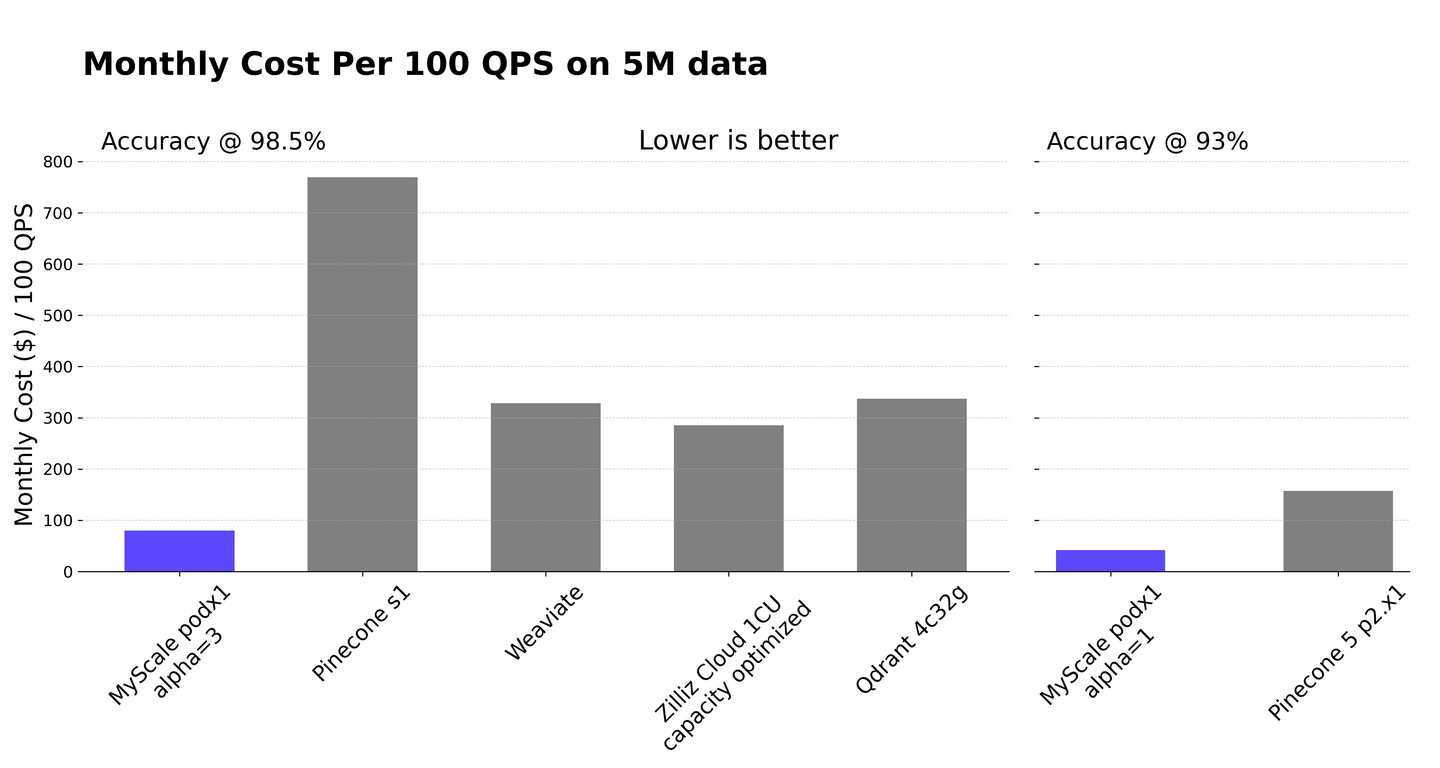
SQLベクトルデータベースの中でも、MyScaleDB (opens new window)は、ClickHouseの機能を拡張したオープンソースのオプションです。MyScaleDBは、構造化データの管理とベクトル操作をシームレスに組み合わせることで、複雑なデータの相互作用のパフォーマンスを最適化し、RAGシステムの効率を向上させます。フィルタリングされた検索 (opens new window)を使用することで、MyScaleDBは特定の属性に基づいて大規模なデータセットを効率的にフィルタリングし、RAGシステムのための迅速かつ正確な検索を実現します。
# 結論
ベクトルデータベースは、データの検索と処理を最適化することで、RAGシステムを大幅に向上させました。これらのデータベースは、意味的な意味に基づいて効率的な格納と迅速な検索を可能にします。HNSWやIVFなどの高度なインデックスメソッドにより、関連するデータが迅速に特定され、応答の正確性が向上します。さらに、ベクトルデータベースは大量のデータを効率的に処理し、リアルタイムのクエリングと即座のユーザー応答に必要なスケーラビリティを提供します。
SQLベクトルデータベースは、ベクトル検索をSQLと統合することで、これらの利点をさらに高めます。これにより、複雑で正確なデータの相互作用が可能になります。この統合により、堅牢なRAGアプリケーションの構築のための開発が簡素化され、学習コストが削減されます。
GitHub (opens new window)でオープンソースのMyScaleDBリポジトリを探索し、SQLとベクトルを活用して革新的な本番レベルのRAGアプリケーションを構築してください。




