
データのボリュームと複雑さが増え続ける中で、スケーラブルなNoSQLデータベースソリューションは、従来のリレーショナルデータベースに代わるトレンドとなっています。その中でも注目を集めているのが、ベクトルデータベースです。ベクトルデータベースは、従来のSQLクエリではなく、高次元ベクトル検索を利用してデータを意味や類似性に基づいて整理・検索することで、高度な意味検索機能を提供します。
ベクトルデータベースを選ぶ前に、アプリケーションや分析の要件を考慮し、現在と将来の両方で要件を満たすことを確認するために、いくつかの重要な要素を慎重に考慮する必要があります。それについてこのブログで説明します。これらの要素は、ベクトルデータベースのコア機能、運用上の考慮事項、および使いやすさとエコシステムの3つの主要なカテゴリに分けられます。さあ、始めましょう!
# コア機能
ベクトルデータベースのコア機能には、パフォーマンス、インデックスメソッド、クエリ言語とAPIのサポート、データモデルとスキーマが含まれます。
# パフォーマンス
ベクトルデータベースを選ぶ際には、パフォーマンスが重要です。パフォーマンスは、類似アイテムの効率的な検索、最近傍ベクトルの検索、データ分析のためのスムーズなアプリケーションの動作を保証します。ベクトルデータベースのパフォーマンスは、以下の要素によって測定されます。
- 1秒あたりのクエリ数(QPS): データベースが1秒間に処理できるクエリの数を測定します。より高いQPSは、データベースがより多くの同時検索をサポートできることを意味し、リアルタイムのデータ分析やユーザーとのインタラクションを必要とするアプリケーションにとって重要です。
- 平均クエリレイテンシ: クエリが行われてからデータベースが結果を返すまでにかかる時間です。低いレイテンシは、アプリケーションがより高速でユーザーに対してより応答性のあるものに感じられるため、全体的なユーザーエクスペリエンスを向上させます。
- データの取り込み時間: 新しいデータをデータベースに追加する速度は、データが常に最新でクエリに対して準備ができていることを保証するために重要です。効率的なデータの取り込みにより、データベースは常に最新の状態であり、クエリの準備ができています。
MyScaleDBは、他のベクトルデータベースと比較して優れたパフォーマンスを持つベクトルデータベースです。大規模なデータセットでは、MyScaleDBはLAION 5Mデータセットで390 QPS(1秒あたりのクエリ数)を達成し、95%の再現率を達成し、平均クエリレイテンシは18msを維持しています。また、MyScaleDBは、5Mのデータポイントに対してほぼ30分でタスクを完了しました。サインアップすると、最大500万のベクトルを処理できるx1ポッドを無料で使用できます。
関連記事: MyScaleDBが他の専門のベクトルデータベースを凌駕する方法 (opens new window)
# インデックスメソッド
ベクトルデータベースの鍵となるのは、高次元ベクトルデータの処理方法です。異なるベクトルデータベースは、データを迅速かつ正確に見つけるためのさまざまなインデックスメソッドを使用して、すべてを整理し効率的に保ちます。以下に、ベクトルデータベースで一般的に使用されるいくつかのインデックスメソッドを示します。
- k-dツリーは、k次元空間のポイントをインデックス化するために使用されるツリー構造です。ベクトルなどの多次元データに特に有用です。k-dツリーは、領域を分割して最近傍検索を迅速に行うことができます。
- ボールツリーは、k-dツリーに似ていますが、データ密度が異なるデータセットに効果的です。ボールツリーは、データセットを超球体で囲むことで表現し、最近傍検索などのアプリケーションに適しています。
- **局所性鋭敏ハッシュ(LSH)**は、入力アイテムをハッシュ化して類似したアイテムが高い確率で同じバケットにマップされるようにする確率的な方法です。これは、類似性検索などの近似検索に有用であり、レコメンデーションシステムなどのアプリケーションに適しています。
- グラフベースのインデックスは、ノードとエッジをベクトルと関係として表現するグラフとしてデータを表現します。このインデックスは、複雑な関係を捉えるのに役立ち、ソーシャルネットワーク分析などのアプリケーションでよく使用されます。
- 反転ファイル(IVF)ベクトルインデックスは、高次元ベクトル空間での効率的な類似性検索のための手法で、クラスタリングを使用してベクトルをボロノイセルに分割し、クエリ中の特定のセル内のベクトルを迅速に特定するための反転インデックスを構築します。
- **プロダクト量子化(PQ)**は、ベクトルをより小さなサブベクトルに分割し、それぞれを量子化する方法です。これは高次元データに効率的であり、画像検索などのアプリケーションでよく使用されます。PQは、グラフベースのインデックスやIVFと効果的に組み合わせることもできます。
- 空間ハッシングは、ベクトル空間をセルに分割し、位置に基づいて各ベクトルをセルに割り当てる方法です。この方法は、空間クエリに有用であり、コンピュータグラフィックスやコンピュータ支援設計などで一般的に使用されます。
多くのアルゴリズムは、特に大規模なデータセットのインデックスサイズが増加すると制限が発生します。これには、すべてのベクトルデータをメモリに格納する必要がある大規模なデータセットが含まれます。マルチスケールツリーグラフ(MSTG) (opens new window)は、MyScaleDBによって開発され、階層的なツリークラスタリングとグラフトラバーサル、および高速なNVMe SSDとメモリを組み合わせることで、これらの制限を克服します。MSTGは、IVF/HNSWのリソース消費を大幅に削減し、優れたパフォーマンスを維持します。MSTGは、異なるフィルタリング検索比率でも高速かつ正確な検索を行い、リソースとコストの効率性を保ちます。
# クエリ言語とAPIのサポート
クエリ言語とアプリケーションプログラミングインターフェース(API)のサポートは、ユーザーがデータベースと対話し、情報を取得する方法を定義します。これらは、ベクトルデータベースがユーザーフレンドリーで、適応性があり、さまざまな技術エコシステムにシームレスに統合できるかどうかを評価するための重要な要素です。これらのコンポーネントにより、ユーザーはデータベースと対話することで価値ある洞察を抽出し、スムーズかつ効果的なデータ管理体験を実現できます。
MyScaleDBはオールインワンのベクトルデータベースであり、SQLと完全に互換性があります。これにより、複雑なデータ操作、意味検索、および構造化データクエリをSQLを介して簡素化するだけでなく、ほとんどの開発者が既存のSQLの知識を活用してベクトルデータベースを始めることができます。同時に、MyScaleDBのAPIサポートは、自動化や他のシステムとの統合を容易にします。
# データモデルとスキーマ
ベクトルデータベースのデータモデルとスキーマは、データの格納とアクセス方法を指示する設計図です。これは、ストレージ効率、クエリパフォーマンス、スケーラビリティ、および開発者エクスペリエンスに影響を与えます。MyScaleDBは、構造化データベースのような表形式のデータ(従来のデータベースのような)と高次元ベクトルの両方を効果的に格納できるハイブリッドデータモデルを使用しています。
# 運用上の考慮事項
ベクトルデータベースの運用上の考慮事項として、スケーラビリティ、セキュリティ、およびモニタリングについて説明します。
# スケーラビリティ
スケーラビリティとは、パフォーマンスや機能性を損なうことなく、増加するデータ量やユーザーの要求を処理する能力を指します。ベクトルデータベースでは、垂直スケーリングと水平スケーリングの2つのタイプのスケーリングがあります。垂直スケーリングは、ハードウェアとソフトウェアの計算能力を拡張することを意味します。一方、水平スケーリングは、追加のサーバーノードを追加することを意味します。これは、AIアプリケーションの成長をサポートし、ベクトルデータベースを将来にわたって確実にするために重要です。MyScaleDBは垂直スケーリングを提供します。
# セキュリティ
ベクトルデータベースのセキュリティには、データ自体とデータベースシステムの機能性を保護するさまざまな側面が含まれます。ベクトルデータベースでのセキュリティ機能には、暗号化、アクセス制御、認証メカニズム、ネットワークセキュリティ、災害復旧などがあります。これらは、データを安全に保つデジタルの盾として機能します。
MyScaleDBは、チームや組織などの信頼性があります。
- MyScaleDBは、完全に管理された安全なAWSインフラストラクチャ上のマルチテナントKubernetesクラスタで実行されます。
- 顧客データは分離されたコンテナに格納されます。
- APIサービス呼び出し以外の理由でデータにアクセスすることは厳しく禁止されています。
- MyScaleDBは、システムの健全性とパフォーマンスを維持するために、運用メトリックのみを監視します。
- MyScaleDBは、情報を安全に保つための世界最高の基準であるSOC 2 Type 1のコンプライアンスを達成しています。
# モニタリング
モニタリングは、ベクトルデータベースを選ぶ際に重要な役割を果たします。パフォーマンスの最適化、継続的な改善、適応性のためのタイムリーな意思決定を行うための洞察と進捗状況を提供します。
MyScaleDBは、パフォーマンスメトリック、リソース利用状況、セキュリティイベントを追跡する包括的なモニタリングツールを提供し、データベースの健全性とアクティビティに関するリアルタイムの洞察を提供します。
関連記事: リトリーバルオーグメンテッドジェネレーションによるパフォーマンスの向上 (opens new window)
# 使いやすさとエコシステム
使いやすさとエコシステムには、価格設定、ドキュメンテーション、コミュニティ、サポート、エコシステムの統合が含まれます。
# コミュニティとサポート
コミュニティのサポートは、ベクトルデータベースを効果的に使用する上で重要な役割を果たします。コミュニティのサポートは、ユーザーに力を与え、協力を促進し、さまざまなアプリケーションや業界でのベクトルデータベースの実装の継続的な改善と成功に貢献します。また、デバッグの問題や質問のクリアリティのためにも役立ちます。MyScaleDBは、Discord (opens new window)、Twitter (opens new window)、LinkedIn (opens new window)、Medium (opens new window)など、複数のチャンネルで包括的なサポートを提供しています。また、これらのチャンネルを通じてMyScaleDBの技術エキスパートから迅速に回答を得ることができます。
# 価格設定
価格設定は、ベクトルデータベースを選ぶ際の主要な要素です。価格設定の明確な理解は、ベクトルデータベースとの費用対効果の高い持続可能な関係を確保します。さまざまなデータベースが提供する価格モデルを調査し、予算と使用要件との整合性を評価してください。
MyScaleDBは、個人向けの小規模なアプリケーションに対しては無償のサービスから、AIサービス向けの標準パッケージ、大規模な組織向けのエンタープライズパッケージまで、複数の価格オプション (opens new window)を提供しています。MyScaleDBは、ストレージと計算を別々に請求するため、クエリ実行時のみ計算料金が発生します。また、最近MyScaleDBは、たった$68/月で10Mの768Dベクトルをホストできる容量最適化ポッドをリリースしました。これにより、予算を超えることなく強力なGenAIアプリを簡単に作成できるようになりました。
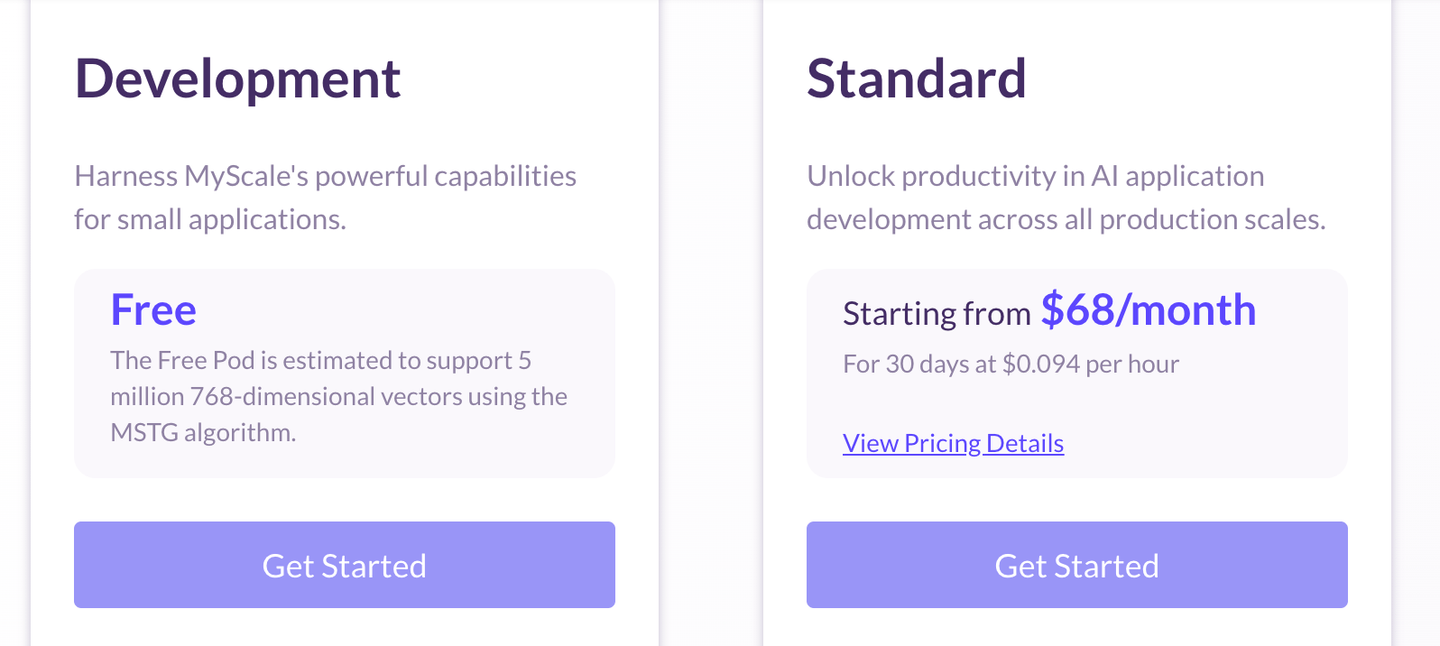
データベクトルのサイズの見積もりがある場合は、価格見積もりツールを使用して価格を計算することもできます。
# エコシステムの統合
以下でエコシステムの統合について説明します。
開発者ツール:開発者ツールは、プロジェクトに適したベクトルデータベースを選ぶ際に重要です。既存の開発者ツールを統合することで、生産性と効率を向上させることができます。MyScaleDBは、Pythonクライアント (opens new window)、Node.js (opens new window)、Goクライアント (opens new window)、ClientJDBCドライバー (opens new window)、HTTPSインターフェース (opens new window)など、さまざまな開発者ツールを統合しています。
大規模言語モデル(LLM):LLMの統合は、ベクトルデータベースの機能を大幅に拡張し、高度な意味検索、データのコンテキスト化、パーソナライズされた推薦、知識の拡張、対話型インターフェースを可能にします。MyScaleDBは、OpenAI (opens new window)、LangChain (opens new window)、LangChain JS/TS (opens new window)、LlamaIndex (opens new window)など、複数のLLMの統合を提供しています。
関連記事: ベクトルデータベースによる高度なFacebookイベントデータ分析 (opens new window)
# ドキュメンテーション
詳細なドキュメンテーションの提供は、ベクトルデータベースを選ぶ際に重要です。これにより、機能の理解、効率的な開発、統合、長期的なサポート、スムーズな学習カーブが可能になります。
MyScaleDBは、ユーザーガイド (opens new window)、チュートリアル (opens new window)、ブログ (opens new window)、サンプルアプリケーション (opens new window)、API統合 (opens new window)のドキュメントを提供しており、DiscordやTwitterなどのアクティブなサポートチャンネルもあります。

# 比較
MyScaleDBをいくつかの人気のあるベクトルデータベースと比較しましょう。
| 機能 | MyScaleDB | Pinecone | Weaviate | Milvus | Qdrant |
|---|---|---|---|---|---|
| オープンソース | はい | いいえ | はい | はい | はい |
| SQL | はい | いいえ | いいえ | いいえ | いいえ |
| クラウドデプロイメント | はい | はい | はい | はい | はい |
| クエリ言語 | SQL & SDK | SDK | GraphQL | C++、Python SDK | SDK |
| LLMの統合 | Llamalindex、LangChain | Llamalindex、LangChain | Llamalindex、LangChain | Llamalindex、LangChain | Llamalindex、LangChain |
| 価格 | 無料&有料 | 有料 | 14日間無料&有料 | 有料 | 無料&有料 |
# 結論
正しいベクトルデータベースを選ぶことは簡単ではありませんが、コア機能、運用上の考慮事項、使いやすさとエコシステムの統合という異なる要素を考慮することで、適切な選択ができます。
さらに、大規模なデータボリュームの効率的な処理とデータの複雑さへの対応が最も重要な選択基準である場合は、MyScaleDBの使用を検討してください。ClickHouseの強みとMSTGアルゴリズムを組み合わせることで、MyScaleDBは速度と精度の両方で複雑な大規模ベクトル検索のための費用効果の高いソリューションを提供します。
また、以下のコンテンツでもMyScaleDBと他の競合製品のベンチマークレポートを見つけることができます。



