
# Testinについて

Testinは2011年に設立されたエンタープライズサービスプラットフォームで、主に2つのサービスを提供しています。1つは開発者向けのクラウドテストサービスであり、これまでに80万人以上の開発者にサービスを提供し、200万以上のアプリに対して1億5000万回以上のテストを実施しています。もう1つは機械学習(ML)モデルトレーニングサービスであり、セキュリティやIoT(モノのインターネット)などの分野でデータ注釈やモデル展開などのサービスを提供しています。Testinはこれまでに110以上の企業と協力し、自動運転技術を提供する自動車メーカーや顔認識や自然言語処理アプリケーションを扱うスマートホームや金融企業など、さまざまな業界で活躍しています。また、Testinは中国で数々の名誉ある賞を受賞しており、デロイト中国のトップ50のハイテク企業やRed Herring Global Top 100などが含まれています。
# MyScaleを使用する前の状況
MyScaleはTestinと協力し、AIデータ注釈サービスを可能な限り有用にする新しい方法を見つけるために協力しました。典型的なTestinのAIデータ注釈プラットフォームのユーザーは、以下の手順を経ています:
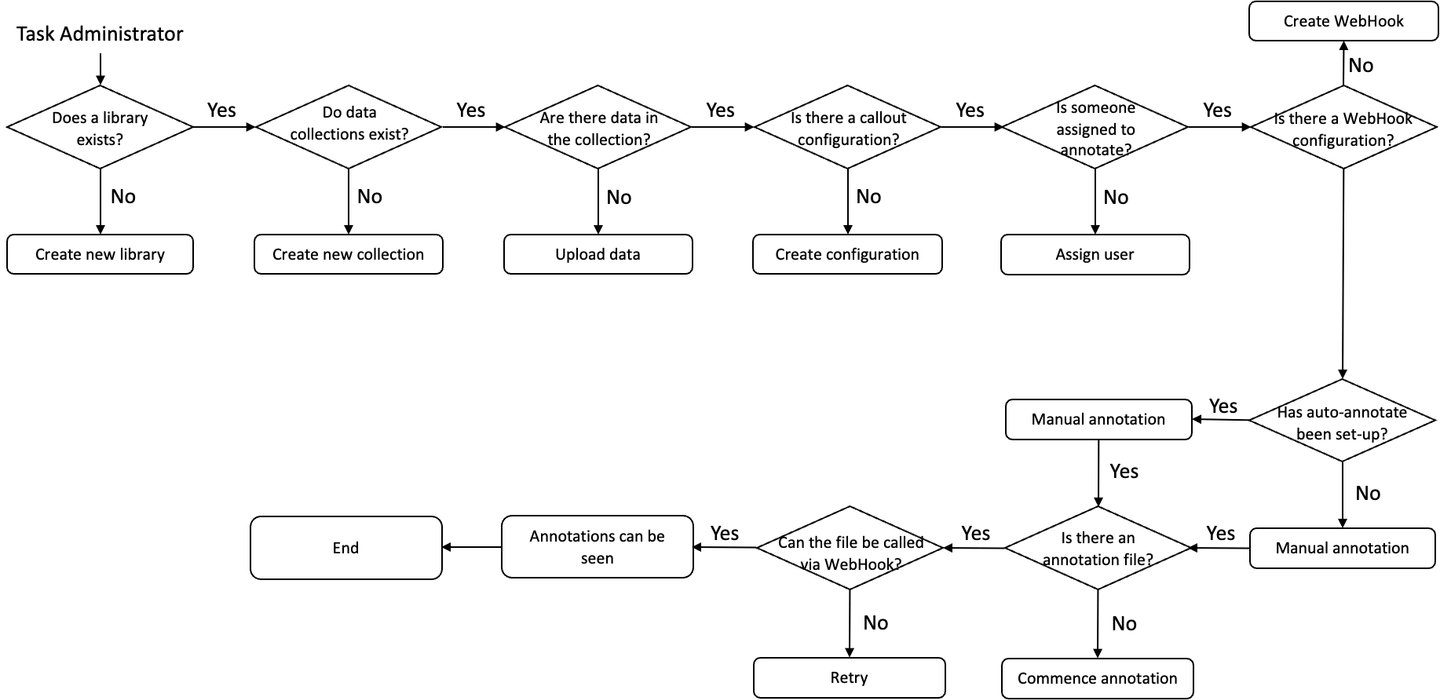
ユーザーはまずライブラリ内でコレクションを作成します。その後、データがコレクションに追加され、データの注釈が開始されます。AIデータ注釈プラットフォームは、その後、機械学習モデルなどの他のアプリケーションで使用するためにデータをエクスポートします。
データ注釈のプロセスは簡単に見えるかもしれませんが、時間がかかることがあります。たとえば、Testinの自動注釈機能は注釈の時間を節約することができますが、常に信頼性があるわけではありません。画像で見るように、プラットフォームは1台の車を識別することができますが、他の車やバスなどの大型車両を識別することはできません。すべての画像で一貫した高品質の注釈がないため、正確な注釈が付いた画像はごくわずかです。

一方、ユーザーが注釈を行いたい場合、時間がかかることになりますが、注釈の品質は向上します。このプロセスでは、ユーザーは自動運転車に関連する画像の領域を手動で特定し、カテゴリ分けする必要があります。ただし、ほとんどのユーザーにとって、大量の画像を手動で注釈することは現実的ではありません。そのため、ユーザーは自動注釈された写真から選択し、注釈の品質を向上させる必要があります。
現在のプロセスの別の問題は、データとその注釈をシームレスに別のプラットフォームに移行できないことです。TestinのAIデータプラットフォームのユーザーは、選択したクラウドドライブにすべての注釈を保存してアクセスするオプションを持っていません。注釈を実行する前に、ローカルドライブに注釈をダウンロードする必要があります。これにより、類似性検索を実行したり、AIモデルをトレーニングしたりする前に、ユーザーは注釈をダウンロードする必要があります。
# MyScaleのベクトル検索機能をTestinのAIデータプラットフォームで活用する
そのため、MyScaleはTestinに対してAIデータプラットフォームの2つの変更を提案しました:
MyScaleの教師なし学習機能を小規模なサンプルに活用すること
Testinのユーザーがオンプレミスおよびクラウドデバイスの両方からMyScaleプラットフォームで共同クエリを実行できるようにすること
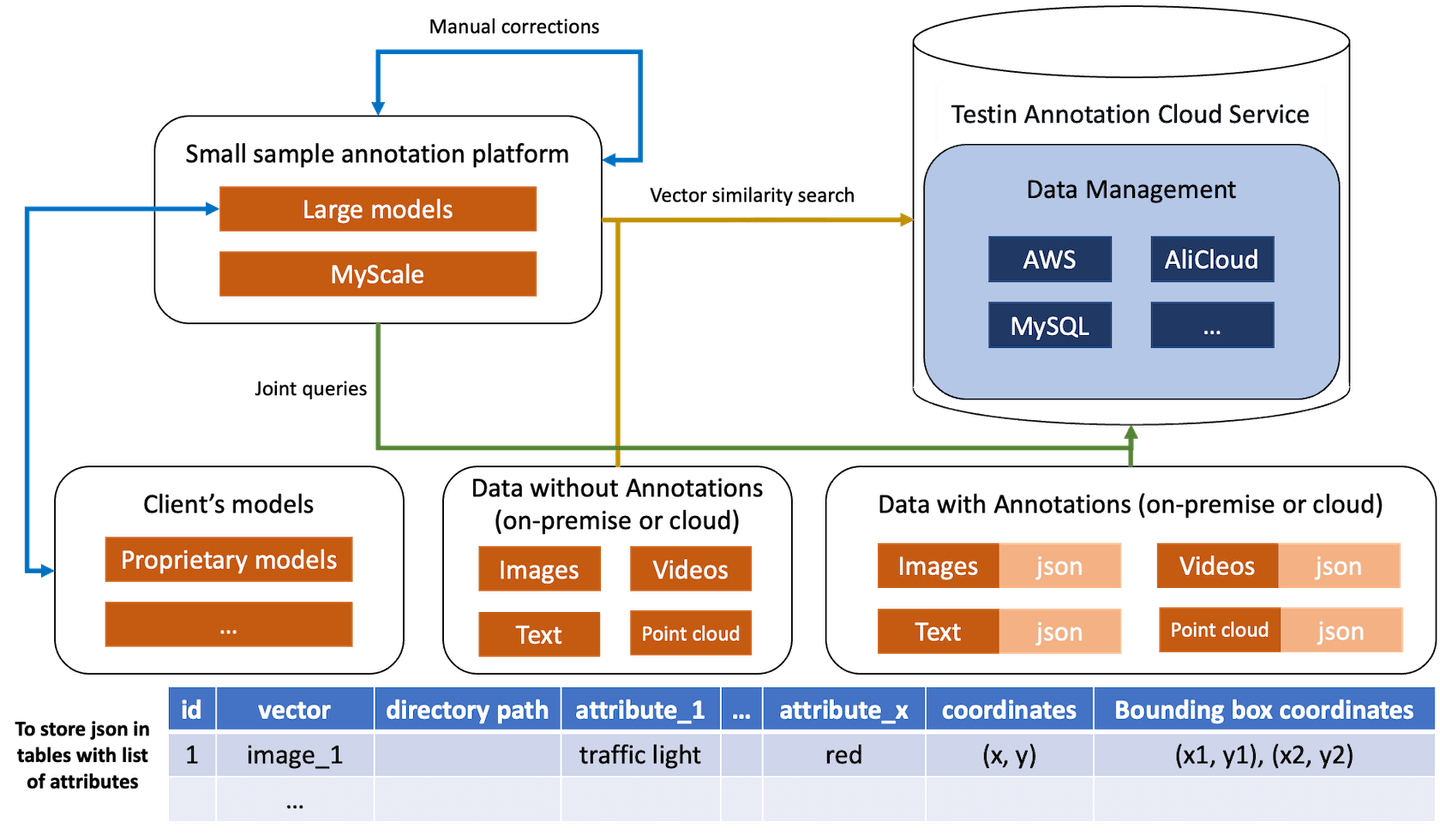
前者については、MyScaleを使用することで、ユーザーは注釈が追加の作業を必要とするかどうかを判断するために、注釈のついた画像のバッチから特定の画像を選択できます。これにより、Testinの自動注釈機能を使用したユーザーは、手動で画像を検査し、画像のバッチが注釈のついた良質なサンプル写真との一致が良いか悪いか(またはなし)を判断する必要がなくなります。これは、新しい画像とデータが常に更新される写真のリポジトリを注釈する場合にも役立ちます。MyScaleを使用することで、ユーザーは注釈が必要かどうかを画像をひとつひとつ見る必要がなくなります。
後者については、ユーザーはMyScaleプラットフォームのSQLクエリ機能を使用して、リンクされたクラウドデータベースアカウントとローカルに提供されたベクトルファイルの両方からベクトルの類似性検索を実行できます。たとえば、クエリが写真やテキストの場合、MyScaleは類似したテキストや写真、および類似したビデオや他のデータモダリティを検索します。さらに、高い類似性を持つ2つのベクトルが見つかった場合、Testinはこの機能を使用して重複データをフィルタリングしました。

# MyScaleがベクトル検索による新たなビジネス価値の開拓にどのように役立つか
MyScaleはソフトウェアテスト企業のTestinと協力して、データのラベリングワークフローを改善しました。Testinは、MyScaleのSQLと高性能なベクトル検索機能を活用して、独自の自動データ注釈とデータの重複排除機能を構築しました。データの手動注釈は一般的ですが、高品質なデータ注釈や時間とコストのパフォーマンスを確保するためのボトルネックでもあります。MyScaleは、TestinがMyScaleのSQL機能を使用して自動データ注釈とデータの重複排除機能を開発するのを支援しました。
機械学習モデルやアプリケーションの開発に適した高性能なデータベースであるMyScaleを使用することで、Testinはプロセスを自動化し、注釈の時間、ストレージスペース、コストを削減することで、データ注釈のワークフローを改善しました。
もし、お使いのビジネスが現在のアプリケーションでクラウドストレージを扱っており、MyScaleがアプリケーションやビジネスからより多くの価値を引き出すのにどのように役立つかをさらに探りたい場合は、お気軽にcontact@myscale.comまでお問い合わせください。



