
更新(2023年10月17日): MyScaleとPostgreSQL、OpenSearchを比較する新しいブログ記事MyScaleとPostgres、OpenSearchの比較:統合ベクトルデータベースの探求 (opens new window)をご覧ください。
AIやMLアプリケーションの急速な成長により、大規模データ分析を含むベクトルデータの効率的な格納、インデックス作成、クエリ処理が求められるようになりました。そのため、MyScale、Pinecone、Qdrantなどのベクトルデータベースは、これらの要件を満たすために開発・拡張が続けられています。
同時に、従来のデータベースもベクトルデータの格納と検索の機能を向上させています。例えば、よく知られたリレーショナルデータベースであるPostgreSQLとその pgvector 拡張機能は、最適化されたベクトルデータベースよりも効果は劣りますが、同様の機能を提供しています。
PostgreSQLのような汎用データベースを使用する場合、パフォーマンスや精度などに大きな違いがあります。これらの違いにより、パフォーマンスやデータスケールのボトルネックが発生することがあります。そのため、MyScaleのようなより効率的なベクトルデータベースへのアップグレードが推奨されます。
MyScaleが他の専門のベクトルデータベースと異なる点は、高いパフォーマンスを損なうことなく完全なSQLサポートを提供できることです。これにより、PostgreSQLからMyScaleへの移行プロセスがスムーズかつ簡単になります。
この文を補完するために、PostgreSQLデータベースにベクトルデータが格納されており、パフォーマンスとデータスケールのボトルネックがあるというユースケースを考えてみましょう。そのため、解決策としてMyScaleへのアップグレードを選択しました。
# PostgreSQLからMyScaleへのデータ移行
PostgreSQLからMyScaleへのアップグレードの中核となる部分は、古いデータベースから新しいデータベースへのデータ移行です。これを行う方法を見てみましょう。
注意:
PostgreSQLからMyScaleへのデータ移行のデモンストレーションを行うためには、ベクトルデータが既にPostgreSQLデータベースに存在するというユースケースにもかかわらず、両方のデータベースをセットアップする必要があります。
始める前に、以下の環境とデータセットを使用することを覚えておくことが重要です。
# 環境
| データベース | ティア | DBバージョン | 拡張機能バージョン |
|---|---|---|---|
| Supabase (opens new window) 上の PostgreSQL | 無料(最大500MBのデータベーススペース) | 15.1 | pgvector 4.0 |
| MyScale (opens new window) | 開発(最大5百万個の768次元ベクトル) | 0.10.0.0 |
# データセット
この演習では、LAION-400-MILLION OPEN DATASET (opens new window)から最初の100万行(正確に1,000,448行)を使用し、データスケールが移行後も増加し続けるシナリオを示します。
注意:
このデータセットには、512次元のベクトルからなる4億のエントリがあります。
# PostgreSQLへのデータのロード
すでにPostgreSQLとpgvectorについて知っている場合は、ここをクリックして移行プロセスに進むことができます。
最初のステップは、データをPostgreSQLデータベースにロードすることです。以下のステップバイステップガイドに従って作業します。
# PostgreSQLデータベースの作成と環境変数の設定
次の手順で、Supabase上のPostgreSQLインスタンスにpgvectorを使用してデータベースを作成します。
- Supabaseのウェブサイト (opens new window)にアクセスしてログインします。
- 組織を作成し、名前を付けます。
- 組織とそのデータベースの作成が完了するのを待ちます。
pgvector拡張機能を有効にします。
以下のGIFは、このプロセスを詳しく説明しています。

PostgreSQLデータベースが作成され、pgvectorが有効になったら、次のステップは、psqlを使用してPostgreSQLへの接続を確立するために次の3つの環境変数を設定することです。
export PGHOST=db.qwbcctzfbpmzmvdnqfmj.supabase.co
export PGUSER=postgres
export PGPASSWORD='********'
さらに、次のスクリプトを実行してメモリとリクエストの期間制限を増やし、実行するSQLクエリが中断されないようにします。
$ psql -c "SET maintenance_work_mem='300MB';"
SET
$ psql -c "SET work_mem='350MB';"
SET
$ psql -c "SET statement_timeout=4800000;"
SET
$ psql -c "ALTER ROLE postgres SET statement_timeout=4800000;";
ALTER ROLE
# PostgreSQLデータテーブルの作成
以下のSQLステートメントを実行して、PostgreSQLデータテーブルを作成します。ベクトルの列(text_embeddingとimage_embedding)はどちらもvector(512)型であることを確認してください。
ノート:
ベクトルの列は、データのベクトルの次元と一致している必要があります。
$ psql -c "CREATE TABLE laion_dataset (
id serial,
url character varying(2048) null,
caption character varying(2048) null,
similarity float null,
image_embedding vector(512) not null,
text_embedding vector(512) not null,
constraint laion_dataset_not_null_pkey primary key (id)
);"
# PostgreSQLテーブルにデータを挿入する
500K行ずつデータを挿入します。
ノート:
残りのデータを追加する前に、データが正常に挿入されたかどうかをテストするために最初の500K行のみを挿入しました。
$ wget https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/laion_dataset.sql.tar.gz
$ tar -zxvf laion_dataset.sql.tar.gz
$ cd laion_dataset
$ psql < laion_dataset_id_lt500K.sql
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
...
# ANNインデックスの構築
次のステップは、近似最近傍探索(ANN)を使用するインデックスを作成することです。
ノート:
データテーブルの予想される行数が100万行なので、listsパラメータを1000に設定します。(https://github.com/pgvector/pgvector#indexing (opens new window))
$ psql -c "CREATE INDEX ON laion_dataset
USING ivfflat (image_embedding vector_cosine_ops)
WITH (lists = 1000);";
CREATE INDEX
# SQLクエリの実行
最後のステップは、次のSQLステートメントを実行してすべてが正常に動作するかテストすることです。
$ psql -c "SET ivfflat.probes = 100;
SELECT id, url, caption, image_embedding <=> (SELECT image_embedding FROM laion_dataset WHERE id=14358) AS dist
FROM laion_dataset WHERE id!=14358 ORDER BY dist ASC LIMIT 10;"
結果セットが以下のようになっている場合、続行できます。
| id | url | caption | dist |
|---|---|---|---|
| 134746 | Pretty Ragdoll cat on white background Royalty Free Stock Image | 0.0749262628626345 | |
| 195973 | cat sitting in front and looking at camera isolated on white background Stock Photo | 0.0929287358264965 | |
| 83158 | Abyssinian Cat Pictures | 0.105731256045087 | |
| 432425 | Russian blue kitten Stock Images | 0.108455925228164 | |
| 99628 | Norwegian Forest Cat on white background. Show champion black and white Norwegian Forest Cat, on white background royalty free stock image | 0.111603095925331 | |
| 478216 | himalayan cat: Cat isolated over white background | 0.115501832572401 | |
| 281881 | Sealpoint Ragdoll lying on white background Stock Images | 0.121348724151614 | |
| 497148 | Frightened black kitten standing in front of white background | 0.127657010206311 | |
| 490374 | Lying russian blue cat Stock Photo | 0.129595023570348 | |
| 401134 | Maine coon cat on pastel pink Stock Image | 0.130214431419139 |
# 残りのデータを挿入する
残りのデータをPostgreSQLテーブルに追加します。これは、pgvectorのパフォーマンスをスケールで検証するために重要です。
$ psql < laion_dataset_id_ge500K_lt1m.sql
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
...
ERROR: cannot execute INSERT in a read-only transaction
ERROR: cannot execute INSERT in a read-only transaction
このスクリプトの出力(および次の画像)からわかるように、残りのデータを挿入するとエラーが発生します。SupabaseはPostgreSQLインスタンスを読み取り専用モードに設定しており、無料のティアの制限を超えるストレージ消費を防いでいます。
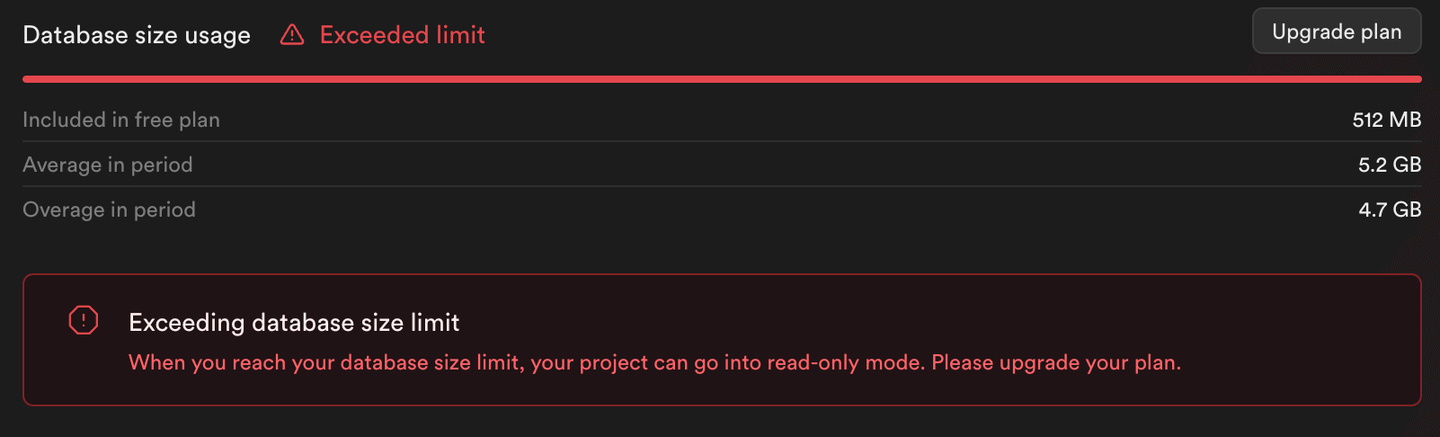
ノート:
PostgreSQLテーブルには500K行のみが挿入され、1M行ではありません。
# MyScaleへの移行
以下の手順に従って、データをMyScaleに移行します。
ノート:
MyScaleは高性能な統合ベクトルデータベースであり、ベンチマークレポートによると、検索性能、精度、リソース利用において他の専門のベクトルデータベースを凌駕しています。MyScaleの独自のベクトルインデックスアルゴリズムであるMulti-Scale Tree Graph(MSTG)は、ローカルNVMe SSDをキャッシュディスクとして使用し、インメモリの状況と比較してサポートされるインデックススケールを大幅に増加させます。
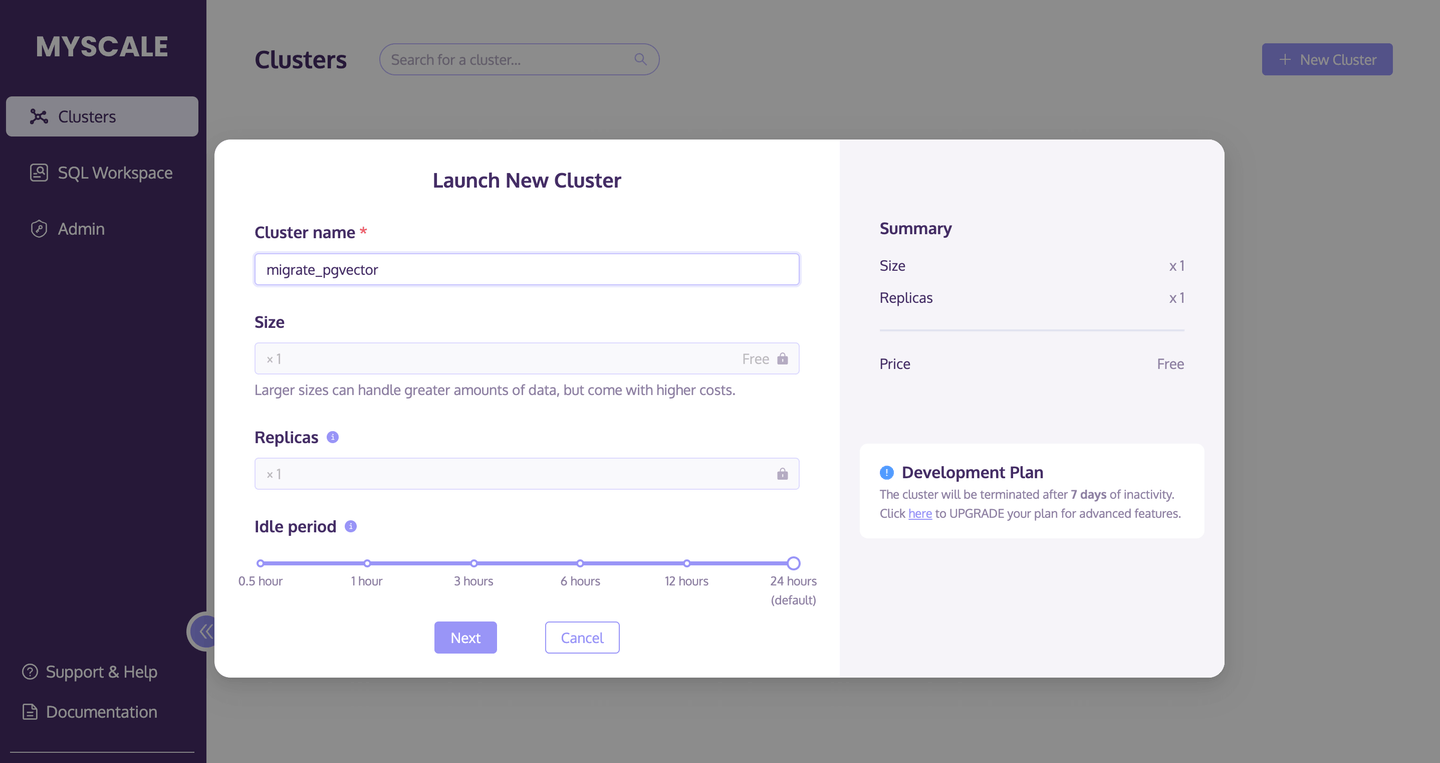
# MyScaleクラスタの作成
まず、新しいMyScaleクラスタを作成して起動します。
- クラスタのページ (opens new window)に移動し、+新しいクラスタボタンをクリックして新しいクラスタを起動します。
- クラスタに名前を付けます。
- 起動をクリックしてクラスタを実行します。
以下の画像は、このプロセスを詳しく説明しています:
# データテーブルの作成
クラスタが実行されたら、次のSQLスクリプトを実行して新しいデータベーステーブルを作成します:
CREATE TABLE laion_dataset
(
`id` Int64,
`url` String,
`caption` String,
`similarity` Nullable(Float32),
`image_embedding` Array(Float32),
CONSTRAINT check_length CHECK length(image_embedding) = 512,
`text_embedding` Array(Float32),
CONSTRAINT check_length CHECK length(text_embedding) = 512
)
ENGINE = MergeTree
ORDER BY id;
# PostgreSQLからのデータの移行
データベーステーブルを作成したら、the PostgreSQL() table engine (opens new window)を使用して簡単にPostgreSQLからデータを移行します。
INSERT INTO default.laion_dataset
SELECT id, url, caption, similarity, image_embedding, text_embedding
FROM PostgreSQL('db.qwbcctzfbpmzmvdnqfmj.supabase.co:5432',
'postgres', 'laion_dataset',
'postgres', '************')
SETTINGS min_insert_block_size_rows=65505;
注意:
min_insert_block_size_rows設定は、バッチごとに挿入される行数を制限し、過剰なメモリ使用を防ぐために追加されています。
# 挿入された総行数の確認
SELECT count(*)ステートメントを使用して、すべてのデータがPostgreSQLテーブルからMyScaleに移行されたかどうかを確認します。
SELECT count(*) FROM default.laion_dataset;
以下の結果セットは、このクエリが500K (500000)行を返すため、移行が成功していることを示しています。
| count() |
|---|
| 500000 |
# データベーステーブルのインデックスの作成
次のステップは、インデックスの作成です。インデックスのタイプはMSTGで、metric_type(距離計算方法)はcosineです。
ALTER TABLE default.laion_dataset
ADD VECTOR INDEX laion_dataset_vector_idx image_embedding
TYPE MSTG('metric_type=cosine');
このALTER TABLEステートメントの実行が完了したら、次のステップはインデックスのステータスを確認することです。以下のスクリプトを実行し、statusがBuiltと返された場合、インデックスが正常に作成されています。
SELECT database, table, type, status FROM system.vector_indices;
| database | table | type | status |
|---|---|---|---|
| default | laion_dataset | MSTG | Built |
# ANNクエリの実行
次のスクリプトを実行して、作成したばかりのMSTGインデックスを使用してANNクエリを実行します。
SELECT id, url, caption,
distance('alpha=4')(image_embedding,
(SELECT image_embedding FROM laion_dataset WHERE id=14358)
) AS dist
FROM default.laion_dataset where id!=14358 ORDER BY dist ASC LIMIT 10;
以下の結果テーブルがPostgreSQLクエリの結果と一致している場合、データの移行は成功しています。
| id | url | caption | dist |
|---|---|---|---|
| 134746 | プリティラグドールキャット、ホワイトバックグラウンドのロイヤリティフリーストックイメージ | 0.0749262628626345 | |
| 195973 | ホワイトバックグラウンドでカメラを見つめる猫が前に座っている写真 | 0.0929287358264965 | |
| 83158 | アビシニアンキャットの写真 | 0.105731256045087 | |
| 432425 | ロシアンブルーキトンの写真 | 0.108455925228164 | |
| 99628 | ホワイトバックグラウンドのノルウェージャンフォレストキャット。ショーチャンピオンの黒と白... | 0.111603095925331 | |
| 478216 | ホワイトバックグラウンドに孤立したヒマラヤンキャットの写真 | 0.115501832572401 | |
| 281881 | ホワイトバックグラウンドに横たわるシールポイントラグドールの写真 | 0.121348724151614 | |
| 497148 | ホワイトバックグラウンドの前に立つおびえた黒い子猫の写真 | 0.127657010206311 | |
| 490374 | 横たわるロシアンブルーキャットの写真 | 0.129595023570348 | |
| 401134 | パステルピンクのメインクーンキャットの写真 | 0.130214431419139 |

# MyScaleテーブルに残りのデータを挿入する
残りのデータをMyScaleテーブルに追加しましょう。
# CSV/Parquetからデータをインポートする
良いニュースは、次のMyScaleメソッドを使用して、データを直接Amazon S3バケットからインポートできることです。
INSERT INTO laion_dataset
SELECT * FROM s3(
'https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/laion-1m-pic-vector.csv',
'CSV',
'id Int64, url String, caption String, similarity Nullable(Float32), image_embedding Array(Float32), text_embedding Array(Float32)')
WHERE id >= 500000 SETTINGS min_insert_block_size_rows=65505;
これにより、データの挿入プロセスが自動化され、手動で500Kバッチごとに行を追加する時間が削減されます。
# 挿入された行の総数を確認する
再度、次のSELECT count(*)ステートメントを実行して、S3バケットからのすべてのデータがMyScaleにインポートされたかどうかを確認します。
SELECT count(*) FROM default.laion_dataset;
以下の結果セットは、正しい行数がインポートされたことを示しています。
| count() |
|---|
| 1000448 |
注意:
無料のMyScaleポッドでは、合計5Mの768次元ベクトルを保存できます。
# ANNクエリを実行する
1M行のデータセットに対してクエリを実行するために、前述のSQLクエリと同じクエリを使用できます。
メモリをリフレッシュするために、以下にSQLステートメントを再掲します。
SELECT id, url, caption, distance('alpha=4')(image_embedding,
(SELECT image_embedding FROM laion_dataset WHERE id=14358)) AS dist
FROM default.laion_dataset WHERE id!=14358 ORDER BY dist ASC LIMIT 10;
以下は、新たに追加されたデータを含むクエリの結果セットです。
| id | url | caption | dist |
|---|---|---|---|
| 134746 | プリティラグドールキャット、ホワイトバックグラウンドのロイヤリティフリーストックイメージ | 0.07492614 | |
| 195973 | ホワイトバックグラウンドでカメラを見つめる猫が前に座っている写真 | 0.09292877 | |
| 693487 | ロシアンブルーキャット、神秘的な猫、友好的な猫、フランシス・シンプソン、猫の品種、猫の品種 | 0.09316337 | |
| 574275 | ミックスブリードキャット、Felis catus、6ヶ月のロイヤリティフリーストック写真 | 0.09820753 | |
| 83158 | アビシニアンキャットの写真 | 0.10573125 | |
| 797777 | オレンジの猫のためのオスの猫の名前 | 0.10775411 | |
| 432425 | ロシアンブルーキトンの写真 | 0.10845572 | |
| 99628 | ホワイトバックグラウンドのノルウェージャンフォレストキャット。ショーチャンピオンの黒と白... | 0.1116029 | |
| 864554 | メインクーンの子猫が座って上を見上げている写真、4ヶ月、ホワイトバックグラウンドで孤立している | 0.11200631 | |
| 478216 | ホワイトバックグラウンドに孤立したヒマラヤンキャットの写真 | 0.11550176 |
# まとめ
この議論では、PostgreSQLからMyScaleへのベクトルデータの移行は簡単であることを説明しました。また、PostgreSQLからデータを移行し、新しいデータをインポートすることで、データのボリュームを増やしても、MyScaleはデータセットのサイズに関係なく信頼性のあるパフォーマンスを発揮し続けます。俗語「大きければ大きいほど良い」という言葉は、この点で真実です。MyScaleのパフォーマンスは、超大規模なデータセットをクエリする場合でも信頼性があります。
したがって、ビジネスがデータのスケールやパフォーマンスのボトルネックを経験している場合、この記事で説明した手順に従ってデータをMyScaleに移行することを強くお勧めします。




