
# Cowarobotについて

2015年に設立されたCowarobotは、複雑な都市環境での自律走行のための総合ソリューションを提供する企業です。2022年中旬時点で、彼らは中国の10以上の都市に進出し、1,000台以上の自律走行車両を保有していました。また、彼らはCherry、BAIC、Shaanxi Automobile、Zoomlionなどの中国の自動車メーカーと協力し、これらの都市での都市物流配送および交通ソリューションの開発に取り組んでいます。
# MyScaleを使用する前
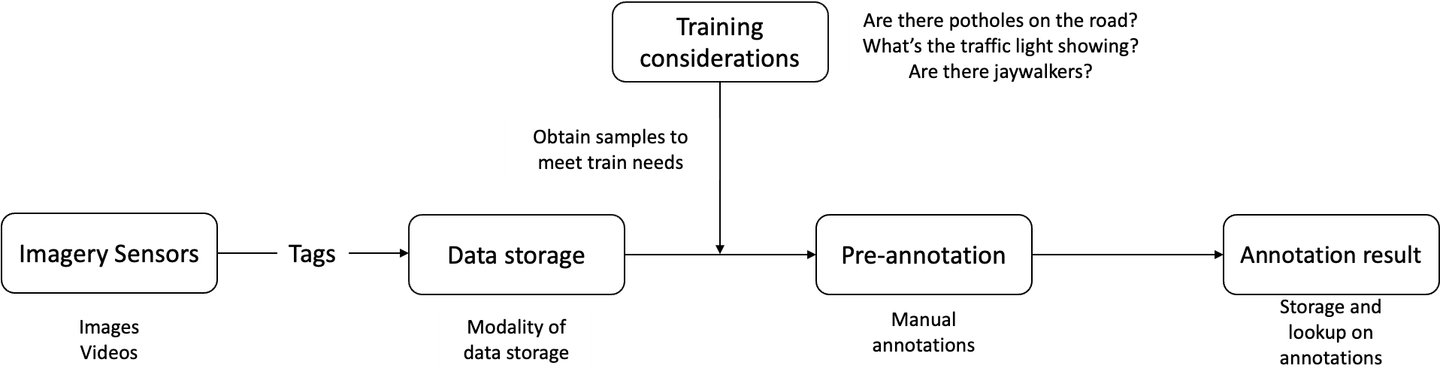
Cowarobotの自律走行フリートのトレーニングワークフローは、以下の5つのセクションに分かれています。
- 中央集権型ストレージに生データとラベルを保存する
Cowarobotは、自律走行車両にとって重要な動的情報(近くの車両、道路障害物、交通信号など)や、道路表面、舗装、地図、速度制限などの伝統的なデータなど、自動車に必要な生のビデオデータと空間データを収集・処理することに特化しています。データはラベル付けされ、複数のレベルを持つフォルダに整理され、それらはローカルドライブに保存されます。しかし、Cowarobotは大量のデータを保存するために大量のハードディスクドライブを調達・維持するという課題に直面しています。また、正確なリアルタイムのオブジェクト認識、セグメンテーション、ラベル検出には最低でも100万件のデータサンプルが必要です。
- トレーニングタスクの実行
Cowarobotは収集した生データを使用してモデルをトレーニングし、自律走行車両がA地点からB地点までナビゲートし、他の車に対して安全な速度を維持し、障害物を回避し、交通信号に従うことができるようにします。道路の状況が変化する場合、トレーニングデータを常に更新する必要があります。たとえば、道路のマーキングが変更された場合、以前のデータラベルを変更して変更を反映させる必要があります。同様に、車両が歩行者に遭遇したり、警察官が停止を指示したりするなど、新しい予期しない状況に遭遇した場合、適切に対応するようにトレーニングする必要があります。これらの更新により、Cowarobotは新しいデータを繰り返し取得・ラベル付けし、トレーニングコストがかかります。これらのコストと頻繁な更新により、Cowarobotが完了できるトレーニングタスクの種類、頻度、品質が制限されます。
- 新しいサンプルの取得
Cowarobotは、以前にデータに割り当てたラベルに簡単にアクセス・取得する手段を持っておらず、以前のラベルを呼び出すことができません。この制限により、会社は既存のデータでモデルトレーニングタスクをサポートすることしかできません。Cowarobotは、使用するためにすべてのデータをローカルドライブから手動でエクスポートする必要があり、これは時間のかかるプロセスです。さらに、既存のデータはCowarobotのモデルのトレーニングをサポートするために不十分であり、会社は新しいデータを収集し、トレーニングサンプルを生成し続ける必要があります。しかし、現在のワークフローでは、更新ごとにCowarobotがローカルドライブからすべてのデータを手動でエクスポートする必要があり、これは手間のかかる時間のかかるプロセスです。
- データラベル
Cowarobotの現在のラベルタスクプロセスの手動性は、モデルを更新し、自律フリートに新しいアップデートを展開する効率を妨げています。この労働集約型で時間のかかる手順は、最新のデータでモデルを更新する能力を制限しています。
- モデルトレーニング
現在のモデルトレーニングでは、Cowarobotはモデルトレーニングのために分散アーキテクチャを使用しており、複数のスーパーコンピュータを使用してトレーニングプロセスのさまざまな段階で計算能力を活用しています。この戦略は、より強力な単一のスーパーコンピュータを使用するよりも経済的です。ただし、この方法の欠点の1つは、トレーニングサンプルをコンピュータ間でネットワークまたはオフラインで転送する必要があることです。これは手間がかかり、時間がかかることがあります。
さらに、トレーニングされたモデルの出力は十分に活用されていません。完了したトレーニングタスクにより、Cowarobotはこれらのモデルを直接オンラインで使用できるようになりますが、モデルトレーニングサンプル以外の保存されたデータは新しいモデルを反映させるために更新されていません。
# 自律車両向けのデータウェアハウスソリューションとしてのMyScaleの採用
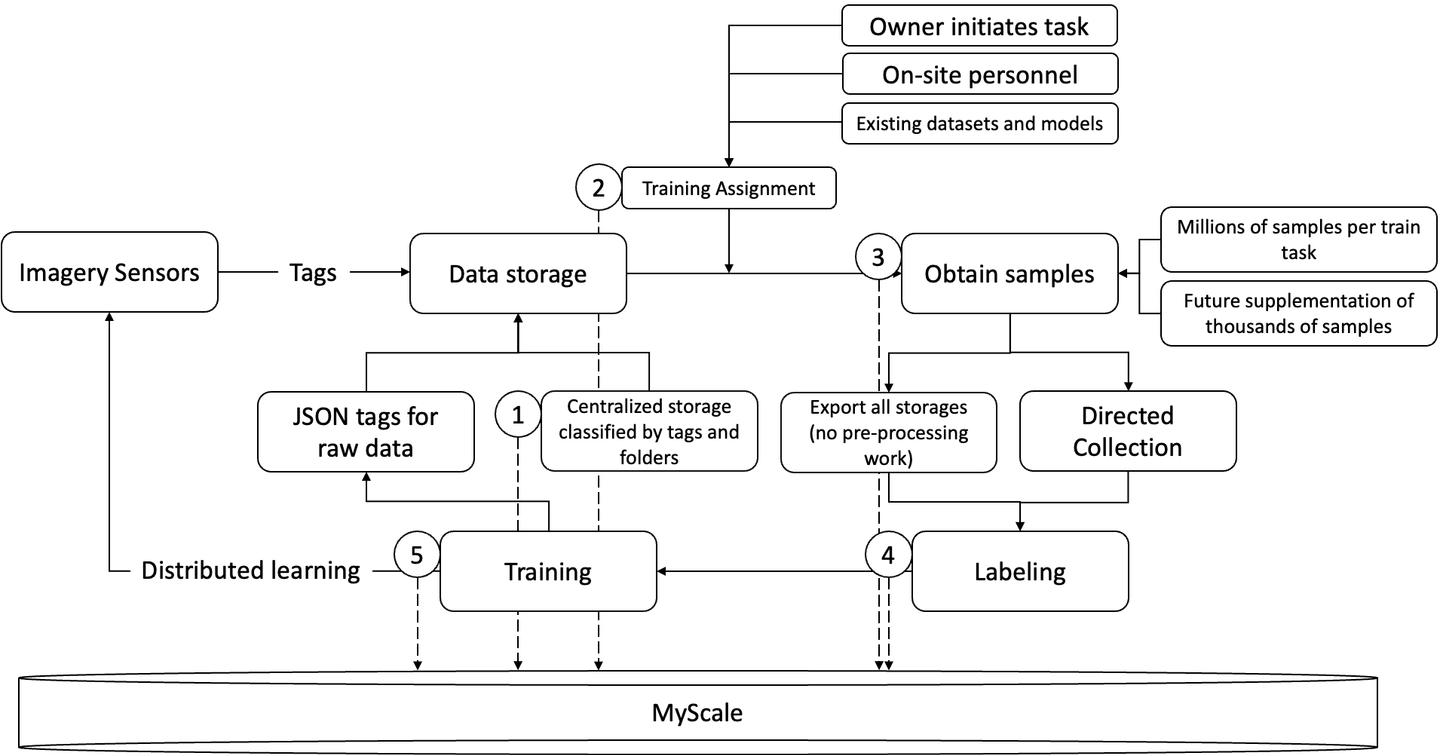
Cowarobotは、自律車両のモデルトレーニングワークフローをストレージからデータラベル、モデルトレーニングまで、MyScaleを使用して改善しました。
- 中央集権型ストレージに生データとラベルを保存する
MyScaleは、ID、ベクトルデータ、タグデータ、URLなどのデータタイプを含む、クエリとデータ管理のための統一されたストレージを提供しており、さまざまな目的でデータセットを管理・使用しやすくしています。これにより、ビジネス内の異なる部門が機械学習プロセスをより良く追跡し、データの使用を改善し、トレーニングタスクの範囲を広げることができます。
- トレーニングタスクの実行
MyScaleは、ユーザーが共同SQLクエリ(属性フィルタリング)を実行することで、在庫データからトレーニングサンプルを迅速に生成することをサポートしています。その結果、新しいトレーニングタスクでは、サンプルサイズを小さくするか、新しいデータの取得が必要ない場合もあります。これにより、トレーニングコストを削減し、ユーザーはより小さなデータセットでより頻繁なトレーニングタスクの種類を増やすことができます。
- 新しいサンプルの取得
MyScaleの主な利点は、わずかな数のデータサンプルのみが必要であることです。必要なサンプル数が少なくなるため、モデルをトレーニングするために新しいサンプルを取得する作業量が減少します。MyScaleは、保存されたデータから迅速にトレーニングサンプルを生成するために、ユーザーが共同SQLクエリを実行できるようにしています。また、大量のサンプルを持つ既存のデータベースがある場合にも役立ちます。MyScaleはトレーニングサンプルをスクリーニングし、より高品質なトレーニングサンプルを探すことができます。これにより、ラベル付けデータの正確性が向上します。
- データラベル
MyScaleは、モデルトレーニングプロセスを開始するために、すでにラベル付けされたわずかなデータサンプルを必要とします。データラベリングは、手作業で変更する必要のあるデータサンプルが少ない場合、時間と費用を節約することができます。
- モデルトレーニング
MyScaleはトレーニングデータを管理し、完全なSQLサポートを提供します。MyScaleを使用すると、ユーザーは簡単なSQLステートメントを書いて直接トレーニングサンプルを作成できます。モデルトレーニングは、元のデータを直接呼び出してモデルのトレーニングプロセスを開始することができます。これにより、モデルトレーニングタスクとデータの転送方法が大幅に簡素化されます。

# MyScaleがビデオデータから新たなビジネス価値を引き出すのにどのように役立つか

MyScaleは、ロボタクシー企業のCowarobotと協力して、データ収集、ストレージ、取得ラベリング、モデルトレーニングなどの機械学習プロセスを管理しました。ベクトルデータやデータ注釈など、さまざまなデータソースが統合されたプラットフォームで管理されています。MyScaleプラットフォームはまた、単一のクエリ言語のみを必要とすることで、モデルトレーニングを簡素化するための完全なSQLサポートを提供しています。
MyScaleは、保存されたデータからトレーニングサンプルを迅速に検索するための検索機能も提供しています。これにより、モデルのトレーニングコストが削減され、トレーニングの頻度と方法が改善されます。Cowarobotは、MyScaleとfew-shot learningを活用して、トレーニングデータのスクリーニング、データの分類、データのマーキングを行いました。この戦略により、必要なデータの注釈と収集の量が減少しました。
もし、お使いのビジネスが現在のアプリケーションで画像やビデオを扱っており、MyScaleがアプリケーションやビジネスからより多くの価値を引き出すのにどのように役立つかをさらに探りたい場合は、お気軽にcontact@myscale.comまでお問い合わせください。



