
ベクトル検索は、ベクトル表現に基づいてデータセット内の類似のベクトルまたはデータポイントを検索するものです。しかし、現実のシナリオでは純粋なベクトル検索だけでは十分ではありません。ベクトルには通常メタデータが付属しており、ユーザーはこのメタデータに1つ以上のフィルタを適用する必要があります。これがフィルタリングされたベクトル検索が重要になる理由です。
フィルタリングされたベクトル検索は、複雑な検索シナリオにおいてますます重要になっています。多次元埋め込みの上位k/範囲を超える望ましくないベクトルをフィルタリングするために、フィルタリングメカニズムを適用することができます。
このブログでは、まずフィルタリングされたベクトル検索の実装における技術的な課題について説明します。そして、MyScaleがフィルタリングされたベクトル検索を最適化するために、プロプライエタリなMSTGアルゴリズムとClickHouseを使用する方法について説明します。
# フィルタリングされたベクトル検索の実装における技術的な課題
現代のアプリケーションにおける大規模なデータセット内のデータタイプの多様化に伴い、適切なフィルタリングされたベクトル検索のアプローチとベクトルインデックスのアルゴリズムの選択は、検索結果の品質向上とより正確な検索結果の提供に非常に重要です。それでは、それぞれの課題について詳しく見ていきましょう。
# プリフィルタリングとポストフィルタリング
ベクトル検索プロセスにおけるフィルタリングのタイミングに基づいて、フィルタリングされた検索はプリフィルタリングまたはポストフィルタリングのいずれかに分類されます。以下の図に示すように。
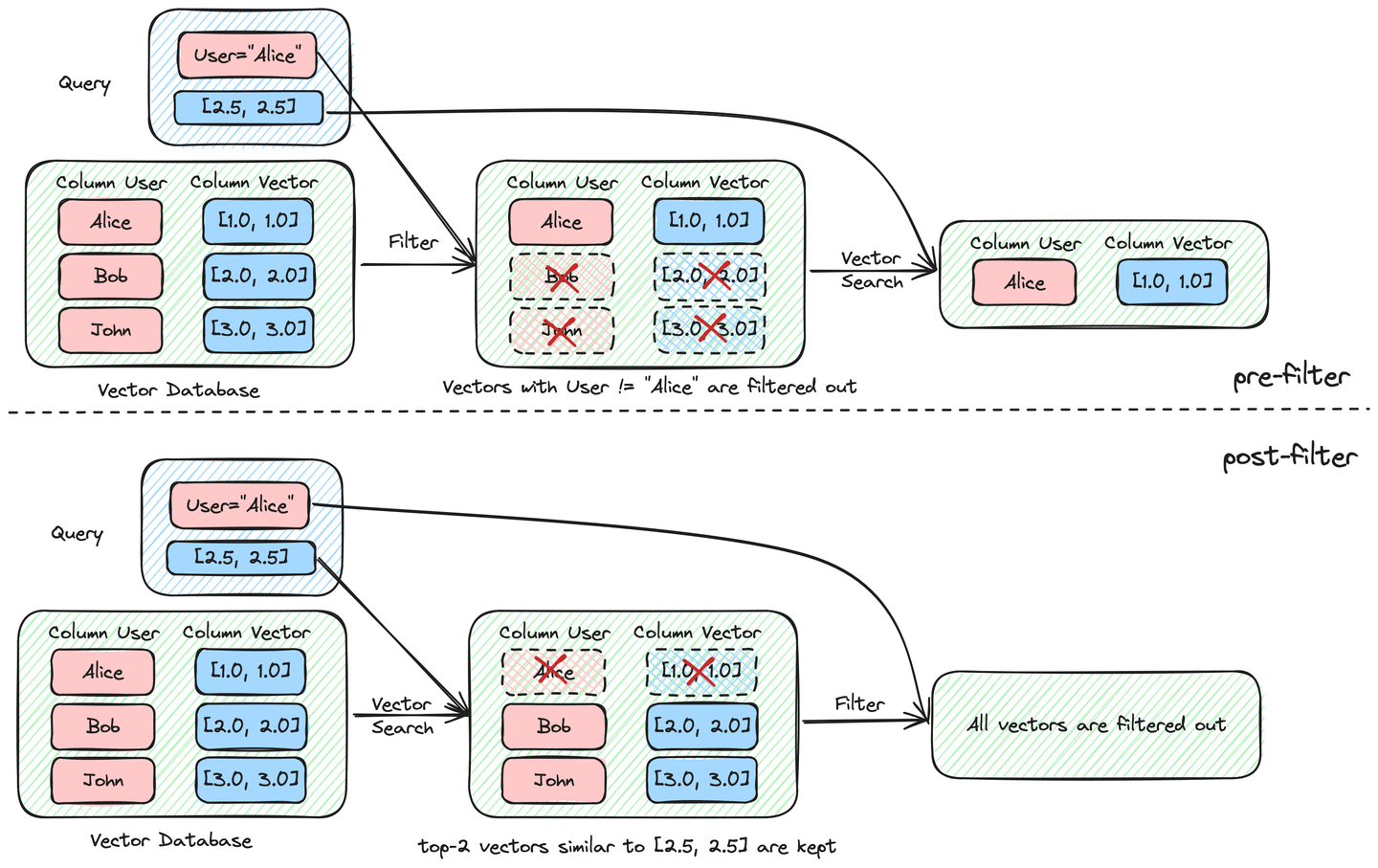 プリフィルタリングを使用すると、期待される出力
プリフィルタリングを使用すると、期待される出力 ("Alice", [1.0, 1.0]) を得ることができます。しかし、ポストフィルタリングでは結果が得られません。
# プリフィルタリング
プリフィルタリングベクトル検索は、データセット内のメインのベクトル検索クエリを実行する前に、潜在的な一致候補を初期スクリーニングする技術です。目的は、検索スペースを狭め、初期段階での不適格な結果や不要な結果を排除することにより、後続のベクトル検索の効率と精度を向上させることです。この方法は、データセットが大きく、計算リソースを適切に使用する必要があるシナリオで特に有益です。
例えば、大量の画像データベースがあり、与えられたクエリ画像に近い画像を取得したい場合を考えてみましょう。画像データセット全体に詳細なベクトル検索を実行する代わりに、クエリ画像と似た色の分布やアスペクト比、または低レベルの記述子などの単純な特徴に基づいて潜在的な候補をプリフィルタリングすることができます。たとえば、クエリ画像と似た色の分布や形状を持つ画像をプリフィルタリングすることができます。
まとめると、プリフィルタリングは、検索操作の範囲を賢明に絞り込むことにより、類似検索の全体的なパフォーマンスを向上させる戦略的なアプローチです。
注意:
MyScaleのフィルタリングされた検索実装では常にプリフィルタリングが使用されます。
# ポストフィルタリング
プリフィルタリングとは異なり、ポストフィルタリングは、純粋なベクトル検索クエリがデータセット上で実行され、初期結果を取得した後に追加のフィルタリングや改善ステップが適用される技術です。ただし、この方法には、検索結果の効率と精度に影響を与える特定の制約と欠点があります。フィルタが適用される結果が減少したセットに対してフィルタが適用されるため、これらの結果は予測できない場合があります。フィルタが非常に制限的で、データセットのサイズに対してデータポイントのわずかな割合のみを対象とする場合、初期のベクトル検索でゼロの一致が発生する可能性があります。
PostgreSQL/pgvectorやOpenSearchなどの人気のあるベクトルデータベースは、このアプローチを採用しており、前のブログ (opens new window)で示したように、フィルタリングされた検索の精度が低くなっています。
# フィルタリング検索におけるHNSWのパフォーマンスの低下
人気のあるグラフアルゴリズムであるHNSWは、フィルタリングされていないベクトル検索においては優れたパフォーマンスを発揮しますが、フィルタリングされたベクトル検索においてはパフォーマンスが著しく低下する場合があります。
まず、フィルタリングされたベクトル検索のフィルタ比率を次のように定義しましょう:
フィルタ比率が低い場合、フィルタリングは非常に制限的になります。以下の図に示すように、フィルタ比率が1%未満の場合、HNSWアルゴリズムはパフォーマンスが低下し、数秒かかります。
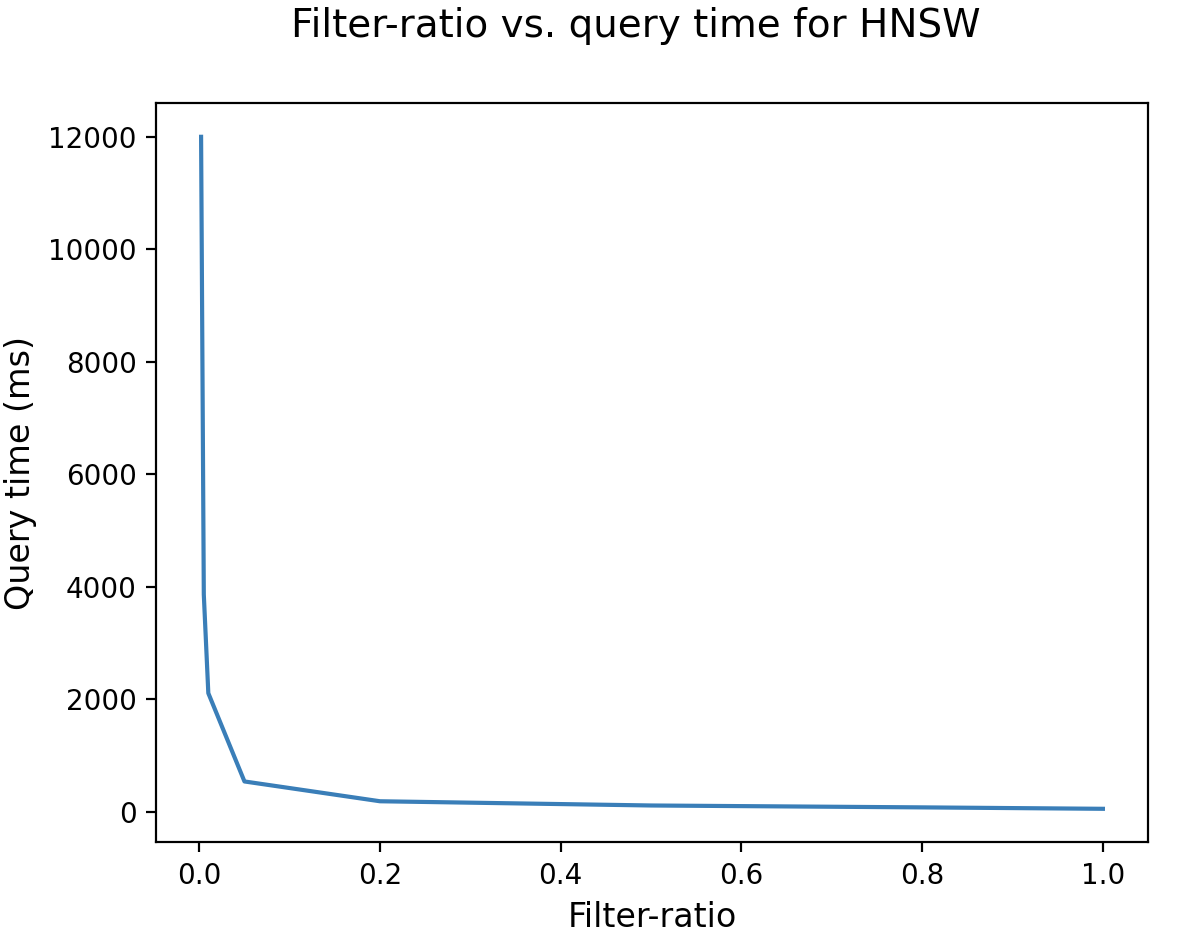
フィルタ比率が低い場合、インデックスは十分な数のトップ候補を特定することに関して大きな課題を抱えます。この制約により、ノードのトラバーサルが広範囲にわたります。さらに、グラフを効率的にトラバースしてフィルタリングされた最近傍ノードを特定することは困難であるため、この課題は複雑さを増します。
HNSWを使用したフィルタリングされたベクトル検索の一般的な最適化技術は、フィルタ比率が特定の閾値を下回った場合にブルートフォース検索に切り替えることです。しかし、これは大規模なベクトル(数億または数十億のベクトルを含むデータベースなど)には実用的ではないため、おすすめできません。このような状況では、1%のフィルタ比率でも、データベース内の数百万のベクトルとの距離を計算する必要があります。
# MyScaleにおける高度なフィルタリングされたベクトル検索
問題を特定したので、解決策に向けて取り組みましょう。MyScaleは、高速なSQL実行エンジン(ClickHouseベース)と、高速なフィルタリングのためのプロプライエタリなMSTGアルゴリズムを組み合わせたSQLベクトルデータベースです。このセクションでは、ClickHouseという最速のオープンソースの分析データベースを基盤としてMyScaleを構築する理由と、効率的なフィルタリングされた検索のためのベクトルアルゴリズムの改善について説明します。これらの最適化により、MyScaleは高性能で柔軟性のある堅牢なフィルタリングされたベクトル検索機能を提供しています。
注意:
MyScaleは、完全なSQLサポートを備えた統合ベクトルデータベースです。
# ClickHouseを活用したフィルタリングされたベクトル検索
MyScaleの基盤としてClickHouseを選択した理由は、大規模なデータの処理におけるその効率が証明されているからです。ClickHouseの優れたデータスキャン速度は、パフォーマンスの高いフィルタリングされたベクトル検索にとって重要です。以下の設計が効率の向上に大きく貢献しています。
- 列指向ストレージ: 伝統的な行指向データベースとは異なり、ClickHouseはデータを列単位で格納するため、データの読み取りと処理が高速化されます。この設計は、集計関数やフィルタのような操作に特に有利であり、必要な列のみを効率的にディスクから読み取り、I/O操作を減らします。
- ベクトル化されたクエリの実行: ClickHouseはデータをバッチ単位で処理し、行単位ではなくベクトル単位で操作を行います。このベクトル化されたアプローチにより、複数のデータポイントに対して同時に操作を行うことができ、クエリの実行を大幅に高速化することができます。これは特に大規模なデータセットにおけるフィルタリングされたベクトル検索にとって有利です。
- 高度なインデックス: ClickHouseはスキップインデックスなどの高度なインデックス技術を使用しています。データベースはクエリ中に関連しないデータブロックを素早くスキップするため、関連しないデータのスキャンにかかる時間が短縮され、フィルタリングが高速化されます。
- 並列処理: ClickHouseのアーキテクチャは並列処理をサポートしており、ワークロードを複数のコアやノードに分散することができます。この並列化は、大規模なクエリやフィルタを効率的に処理するために重要であり、大規模で複雑なデータセットでも高いパフォーマンスを確保します。
これらの機能により、ClickHouseは高速かつ効率的なフィルタリングされたベクトル検索の実装に理想的なプラットフォームとなっています。この統合により、ClickHouseの強力な分析機能と、複雑なメタデータを持つベクトルデータを処理するために必要な微妙なベクトルデータベースの機能が組み合わさっています。
# Multi-Scale Tree Graphアルゴリズム
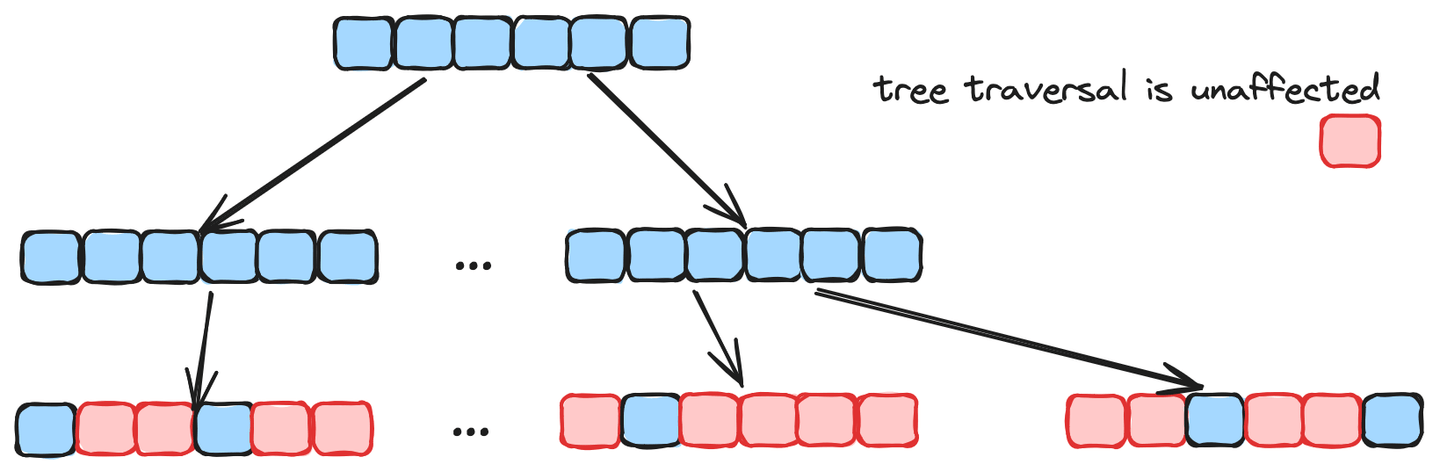
Multi-Scale Tree Graph(MSTG)は、MyScaleが開発した新しいベクトルインデックスです。HNSWなどの人気のあるアルゴリズムは、階層的なグラフにのみ依存しており、IVF(Inverted File Index)は2層のツリーと見なすことができますが、MSTGはその設計において階層的なグラフとツリー構造の両方の良い部分を組み合わせています。
グラフアルゴリズムは初期収束に優れており、通常はフィルタリングされていない検索においても高速です。しかし、フィルタリングされた検索においては効率が著しく低下します。一方、ツリーアルゴリズムはフィルタリングされていない検索においては遅く、精度も低いですが、ツリートラバーサルはフィルタリングされた要素に影響を受けず、フィルタリングされた検索においてもパフォーマンスを維持します。以下の図に示すように、MSTGではこれらの2つのアルゴリズムを組み合わせることで、両方のケースにおいて高いパフォーマンスと高い精度を実現し、高速なインデックス構築時間を実現しています。さらに、MSTGはプリフィルタリングとベクトル距離計算の両方をSIMD(Single Instruction, Multiple Data)で高速化しており、モダンなCPU上での計算スループットを大幅に向上させています。

# 結論
ベクトル検索は、ベクトル表現に基づいてデータポイントを検索するものですが、現実のシナリオでは純粋なベクトル検索だけでは十分ではありません。ベクトルにはメタデータが付属していることが多く、複雑な検索シナリオにおいてはフィルタリングされたベクトル検索が必要不可欠です。
MyScaleのフィルタリングされたベクトル検索への革新的なアプローチは、ClickHouseの強力な分析機能とプロプライエタリなMSTGアルゴリズムの長所を組み合わせたものであり、複雑な大規模ベクトル検索において速度と精度の両方を提供します。これにより、MyScaleはベクトルデータベース技術のリーダーとなっています。
以下のコンテンツで、MyScaleと他の競合他社とのベンチマークレポートを見つけることができます:



