
大規模言語モデル(LLM)や高度なチャットモデルのリリース以来、これらのAIシステムから目的の出力を抽出するためにさまざまな技術が使用されています。これらの方法のいくつかは、モデルの振る舞いを変更して私たちの期待により合わせることに焦点を当てていますが、他の方法は、LLMをクエリする方法を改善して、より正確で関連性のある情報を抽出することに重点を置いています。
Retrieval Augmented Generation(RAG) (opens new window)、プロンプトエンジニアリング (opens new window)、ファインチューニング (opens new window)などの技術が最も広く使用されています。MyScaleでは、すでにRAG (opens new window)とファインチューニングについて詳しく説明しています。ファインチューニングでは、openaiを使用したファインチューニング (opens new window)とhugging faceを使用したファインチューニング (opens new window)の2つの技術について説明しました。
注意:
RAGとファインチューニングのブログをまだ読んでいない場合は、この記事を始める前に、まずそれらを読むことを強くお勧めします。
今日の議論は少し異なります。私たちは探索から比較に移ります。各技術の利点と欠点について見ていきます。これは、これらの技術を効果的に使用するためのタイミングと方法を理解するのに役立ちます。それでは、比較を始めて、それぞれの方法がどのようにユニークなのかを見てみましょう。
# プロンプトエンジニアリング
プロンプトエンジニアリングは、どの大規模言語モデルとも対話する最も基本的な方法です。これは指示を与えることのようなものです。プロンプト (opens new window)を使用すると、モデルにどのような情報を提供してほしいかを伝えることになります。これはプロンプトエンジニアリングとも呼ばれます。最適な回答を得るために正しい質問をする方法を学ぶことに似ています。ただし、それには限界があります。なぜなら、モデルはそのトレーニング (opens new window)で既に知っていることしか返すことができないからです。
プロンプトエンジニアリングの特徴は、非常にわかりやすいということです。それを行うためには、テクニカルな専門知識は必要ありません。これはほとんどの人にとって非常に便利です。ただし、モデルの元々の学習に大きく依存しているため、常に最新の情報や必要な詳細な情報を提供するわけではありません。一般的なトピックで作業している場合や、詳細には立ち入らずに素早い回答が必要な場合に最適です。
# 利点:
- 使いやすさ: プロンプトエンジニアリングはユーザーフレンドリーで、高度な技術スキルは必要ありません。幅広いユーザーにアクセス可能です。
- コスト効率: 事前学習済みモデルを利用するため、ファインチューニングに比べて計算コストが最小限です。
- 柔軟性: モデルを再トレーニングする必要なく、プロンプトを素早く調整して異なる出力を試すことができます。
# 欠点
- 一貫性: モデルの応答の品質と関連性は、プロンプトのフレーズによって大きく異なる場合があります。
- 限られたカスタマイズ: モデルの応答をカスタマイズする能力は、効果的なプロンプトの作成における創造性とスキルに制限されます。
- モデルの知識に依存: 出力は、モデルが初期のトレーニング中に学んだことに制限されており、高度な専門知識や最新の情報にはあまり効果的ではありません。
# ファインチューニング
ファインチューニングとは、言語モデルを新しいことや特別なことを学習させることです。これは、より良い機能を得るためにスマートフォンのアプリを更新するのと似ています。ただし、この場合、アプリ(モデル)には多くの新しい情報と時間が必要で、すべてを適切に学習するためには学校に戻る必要があります。
ファインチューニングには多くのコンピュータのパワーと時間が必要なため、費用がかかる場合があります。ただし、特定のトピックを非常によく理解するために言語モデルが必要な場合は、ファインチューニングが価値があります。自分が興味を持っていることについてモデルに専門家になってもらうようなものです。ファインチューニング後、モデルはより正確で求めているものに近い回答を提供することができます。
# 利点:
- カスタマイズ: 特定のドメインやスタイルに合わせてモデルの応答をカスタマイズすることができます。
- 精度の向上: 専門のデータセットでトレーニングすることにより、モデルはより正確で関連性のある応答を生成することができます。
- 適応性: ファインチューニングされたモデルは、元のトレーニングではカバーされていないニッチなトピックや最新の情報をよりうまく扱うことができます。
# 欠点:
- コスト: ファインチューニングには膨大な計算リソースが必要であり、プロンプトエンジニアリングよりも高価です。
- 技術スキル: このアプローチには、機械学習 (opens new window)と言語モデルのアーキテクチャ (opens new window)のより深い理解が必要です。
- データの要件: 効果的なファインチューニングには、大規模で適切に整理されたデータセットが必要であり、これは困難な作業です。
関連記事: レコメンデーションシステムの構築方法 (opens new window)
# Retrieval Augmented Generation(RAG)
Retrieval Augmented Generation(RAG)は、通常の言語モデルの機能とナレッジベース (opens new window)のようなものを組み合わせたものです。モデルが質問に答える必要がある場合、まずナレッジベースから関連する情報を検索して収集し、その情報に基づいて質問に答えます。モデルは、最適な回答を提供するために情報のライブラリのクイックチェックを行うようなものです。
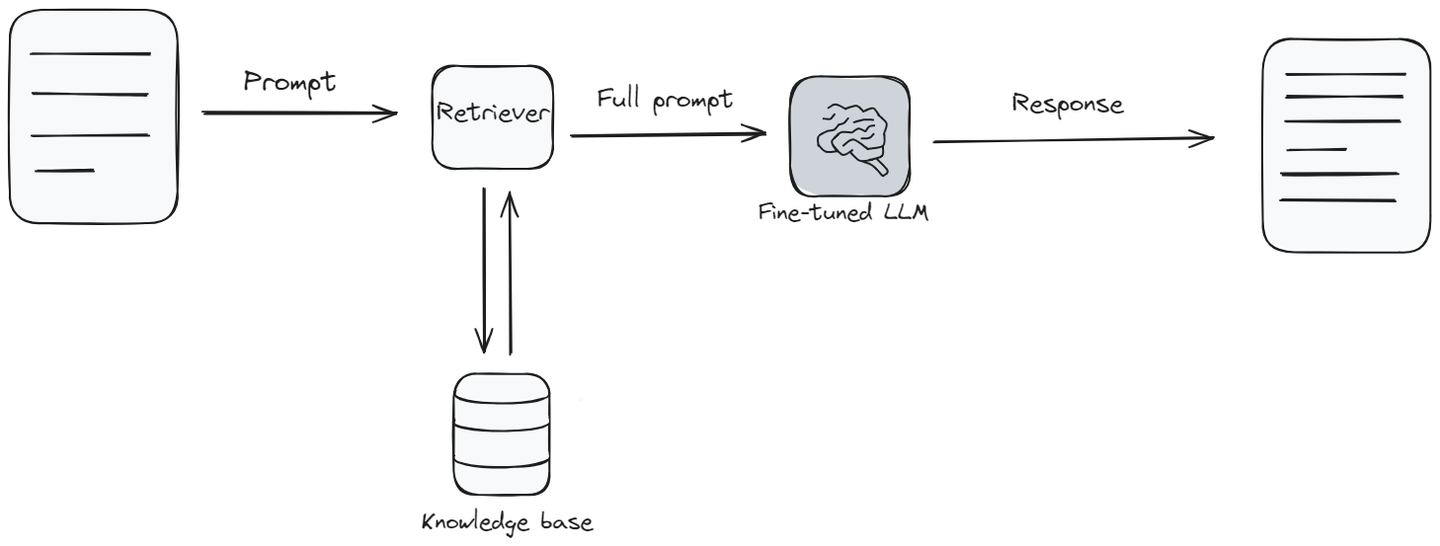
RAGは、モデルが元々学習した内容よりも最新の情報が必要な場合や、より広範なトピックを含む回答が必要な場合に特に有用です。セットアップの難易度とコストの面では中間の位置にあります。言語モデルが新鮮で詳細な回答を提供するのに役立ちます。ただし、ファインチューニングと同様に、うまく機能するためには追加のツールと情報が必要です。
RAGシステムのコスト、速度、応答品質は、ベクトルデータベースに大きく依存しており、RAGシステムの非常に重要な部分です。MyScale (opens new window)は、他のベクトルデータベースと比較してほぼ半分の料金で提供され、パフォーマンスが3倍向上します。ベンチマーク (opens new window)はこちらでご覧いただけます。さらに重要なことは、MyScaleにアクセスするために外部のツールや言語を学ぶ必要がなく、シンプルなSQL構文を介してアクセスできるため、開発者にとって完璧な選択肢です。
# 利点:
- 動的な情報: 外部データソースを活用することで、RAGは最新かつ関連性の高い情報を提供することができます。
- バランス: プロンプトエンジニアリングの簡単さとファインチューニングのカスタマイズ性の中間を提供します。
- 文脈に即した関連性: 外部情報を追加することで、モデルの応答をより情報豊かでニュアンスのあるものにします。
# 欠点:
- 複雑さ: RAGの実装は複雑であり、言語モデルと検索システムの統合が必要です。
- リソースの消費: ファインチューニングよりはリソースを消費しませんが、RAGは相当な計算パワーを要求します。
- データの依存性: 出力の品質は、取得した情報の関連性と正確性に大きく依存します。
# プロンプトエンジニアリング vs ファインチューニング vs RAG
次に、プロンプトエンジニアリング、ファインチューニング、およびRetrieval Augmented Generation(RAG)の比較を並べてみましょう。この表は、違いを見るのに役立ち、必要に応じてどの方法が最適かを判断するのに役立ちます。
| 特徴 | プロンプトエンジニアリング | ファインチューニング | RAG |
|---|---|---|---|
| 必要なスキルレベル | 低: プロンプトの構築方法の基本的な理解が必要です。 | 中程度から高: 機械学習の原則とモデルのアーキテクチャの知識が必要です。 | 中程度: 機械学習と情報検索システムの両方の理解が必要です。 |
| 価格とリソース | 低: 既存のモデルを使用し、計算コストが最小限です。 | 高: トレーニングには膨大な計算リソースが必要です。 | 中程度: 検索システムとモデルの相互作用の両方にリソースが必要ですが、ファインチューニングよりは少ないです。 |
| カスタマイズ | 低: モデルの事前学習の知識と効果的なプロンプトの作成能力に制限があります。 | 高: 特定のドメインやスタイルに広範なカスタマイズが可能です。 | 中程度: 外部データソースを介してカスタマイズ可能ですが、その品質と関連性に依存します。 |
| データの要件 | なし: 追加のデータなしで事前学習済みモデルを使用します。 | 高: 効果的なファインチューニングには大規模で関連性のあるデータセットが必要です。 | 中程度: 関連する外部データベースや情報源にアクセスする必要があります。 |
| 更新頻度 | 低: 基になるモデルの再トレーニングに依存します。 | 可変: モデルが新しいデータで再トレーニングされるタイミングに依存します。 | 高: 最新の情報を組み込むことができます。 |
| 品質 | 可変: プロンプトの作成スキルに大きく依存します。 | 高: 特定のデータセットに合わせてカスタマイズされており、関連性の高い正確な応答を提供します。 | 高: 文脈に即した外部情報で応答を強化します。 |
| 使用例 | 一般的な問い合わせ、広範なトピック、教育目的。 | 特定のアプリケーション、業界固有のニーズ、カスタマイズされたタスク。 | 最新の情報が必要な状況、文脈を含む複雑なクエリ。 |
| 実装の容易さ | 高: 既存のツールとインターフェースを使用して簡単に実装できます。 | 低: セットアップとトレーニングプロセスを深く理解する必要があります。 | 中程度: 言語モデルと検索システムを統合する必要があります。 |
この表は、プロンプトエンジニアリング、ファインチューニング、RAGの主要なポイントを分解しています。さまざまな状況に最適なものを選択するための参考になるはずです。次のタスクに適した適切なツールを選ぶのにこの比較が役立つことを願っています。
関連記事: RAGの仕組み (opens new window)

# RAG - AIアプリケーションを強化するための最良の選択肢
RAGは、従来の言語モデルのパワーと外部ナレッジベースの精度を組み合わせたユニークなアプローチです。この方法はいくつかの理由で特に優れており、特定のコンテキストで単にプロンプトエンジニアリングやファインチューニングだけよりも有利です。
まず第一に、RAGは外部データをリアルタイムで取得することで、提供される情報が最新かつ関連性のあるものであることを保証します。これは、ニュースに関連するクエリや急速に進化する分野など、最新の情報が重要なアプリケーションにとって重要です。
第二に、RAGはカスタマイズとリソース要件のバランスの取れたアプローチを提供します。完全なファインチューニングに比べて計算リソースをより柔軟かつ効率的に使用できるため、より幅広いユーザーや開発者にアクセス可能です。
最後に、RAGのハイブリッドな性質は、LLMの広範な生成能力とナレッジベースで利用可能な具体的で詳細な情報とのギャップを埋めるものです。これにより、関連性の高い詳細な応答だけでなく、文脈に即した応答が可能になります。
最適化されたスケーラブルでコスト効果の高いベクトルデータベースソリューションは、RAGアプリケーションのパフォーマンスと機能性を大幅に向上させることができます。それがMyScale (opens new window)です。SQLベースのベクトルデータベースであり、OpenAI、Langchain、Langchain JS/TS、LlamaIndexなどの主要なAIフレームワークと言語モデルプラットフォームとのスムーズな統合を提供します。MyScaleを使用すると、RAGはより速く、より正確 (opens new window)になります。
# 結論
まとめると、プロンプトエンジニアリング、ファインチューニング、Retrieval Augmented Generation(RAG)のいずれを選択するかは、プロジェクトの具体的な要件、利用可能なリソース、および目標によって異なります。それぞれの方法には独自の利点と制限があります。プロンプトエンジニアリングはアクセスしやすくコスト効果がありますが、カスタマイズ性は低いです。ファインチューニングは高いカスタマイズ性を提供しますが、コストと複雑さが高くなります。RAGはバランスを取り、最新のドメイン固有の情報を提供することができます。
もしもっと詳しく話し合いたい場合は、MyScaleのDiscord (opens new window)に参加して、ご意見やフィードバックを共有してください。




