
最近、大規模言語モデル(LLM) (opens new window)とそのさまざまな用途について注目が集まっています。チャットボット (opens new window)からコンテンツ生成まで、LLMは多くの応用が可能です。しかし、これらのモデルは実際の展開において重要な課題に直面しており、特に異なるハードウェアデバイス上での効率的な実行に関してはさらなる困難が伴います。これらのモデルは計算量が多く、大量のメモリを必要とするため、スマートフォンやタブレットなどの処理能力に制約のあるデバイスでの実行は困難です。この制約は、LLMの普及を妨げる可能性があります。
これらの課題に対処するため、研究者たちは量子化を有効な解決策として提案しています。量子化は、高精度のパラメータを低精度の形式に変換することで、モデルのメモリ使用量とサイズを削減し、パフォーマンスを犠牲にすることなくさまざまなデバイス上で実行可能にします。
本記事では、LLMの原則、NLPタスクへの変革的な影響、さまざまなハードウェアプラットフォームにおけるこれらのモデルの最適化の重要性について詳しく説明します。また、最適化の課題に取り組み、量子化をさまざまなデバイス上でLLMを展開するための強力な手法として紹介します。
# LLMの動作と量子化の必要性
LLMは、書籍、記事、ウェブコンテンツなどの大規模なデータセットでトレーニングされることで動作します。これらのモデルは、予測エラーを最小化するためにトレーニング中に微調整されるモデルの重みである数百万または数十億のパラメータを調整することで、人間の言語を理解し生成することを学習します。これらの重みは大量のメモリを占有し、計算リソースに制約のあるデバイスでは大きな課題となります。
たとえば、50億のパラメータを持つモデルは、16ビット精度を使用する場合には約10 GBのメモリを必要とします。これは、計算能力に制約のあるスマートフォンやタブレットなどのデバイスでの実行は実用的ではありません。ここで、量子化が重要な役割を果たします。量子化は、モデルのパラメータの精度を低下させることで、メモリ使用量と計算負荷を減らし、パフォーマンスを大幅に損なうことなく実行可能にします。このプロセスでは、高精度の重みと活性化(たとえば、16ビット浮動小数点数または32ビット浮動小数点数)を低精度(たとえば、8ビット整数)に変換することが含まれます。
# 量子化の概要:
量子化は、さまざまなハードウェアプラットフォーム上でLLMを効率的に展開するために重要です。これにより、高精度の重みと活性化(たとえば、32ビット浮動小数点数)を低精度(たとえば、8ビット整数)に変換することで、モデルのサイズと計算要件を削減します。精度の低下により、モデルのサイズが小さくなり、計算が高速化され、メモリ使用量が低下し、スマートフォンやIoTデバイスなどのエッジデバイスでモデルを実行することが可能になります。これにより、精度の大幅な低下を伴わずにモデルを実行できます。
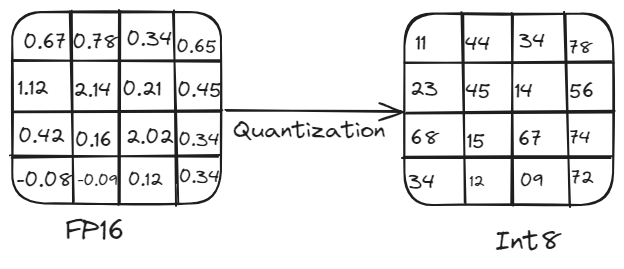
量子化プロセス
# 量子化の方法
量子化は、対称量子化と非対称量子化の2つの主要な方法を使用して行うことができます。
# 対称量子化
この方法では、正の値と負の値をゼロを中心に対称的にスケーリングします。すべての値に同じスケールファクタが使用されるため、計算が簡素化されますが、スケーラブルな分布を持つ値に対しては効率的な表現が得られない場合があります。
-6から5までの浮動小数点数の範囲があるとします。これらの値を量子化するために、最大絶対値を見つけます。この場合、最大絶対値は6です。この値を使用して範囲全体をスケーリングします。8ビット表現では、範囲は-128から127までです。したがって、-6は-128に、0は0に、5は約106にマッピングされます。このように、スケーリングはゼロを中心に対称的に行われます。
Q=round(SX)
ここで、Sはスケールファクタ(たとえば、6/128)です。
# 非対称量子化
この方法では、異なる範囲の値に対して異なるスケールファクタを使用します。これにより、より柔軟な表現が可能になり、モデルのパフォーマンスが向上することがありますが、実装がより複雑になる場合があります。
0から10までの浮動小数点数の範囲があるとします。8ビット表現では、この範囲を0から255に直接マッピングすることができ、量子化された値の範囲全体を効率的に使用することができます。ここで、ゼロポイントは範囲を適切に整列させるために使用され、範囲全体が効率的に使用されるようにします。
X=Q×S+Z
ここで、Sはスケールファクタ、Zはゼロポイントの調整です。
# 量子化のモード
量子化には、事後トレーニング量子化(PTQ)と量子化対応トレーニング(QAT)の2つの主要なモードがあります。
# 事後トレーニング量子化(PTQ)
この方法では、完全な精度(通常は32ビット浮動小数点数)でトレーニングされたモデルを取り、トレーニングが完了した後に低精度形式(たとえば、8ビット整数)に変換します。このプロセスは、モデルの再トレーニングを必要としないため、簡単かつ迅速です。ただし、元々のモデルがこの低精度で動作するようにトレーニングされていなかったため、精度がわずかに低下する可能性があります。これは、モデルの重みと活性化がより小さいビット表現に近似されるため、いくつかの量子化エラーが発生する可能性があるためです。
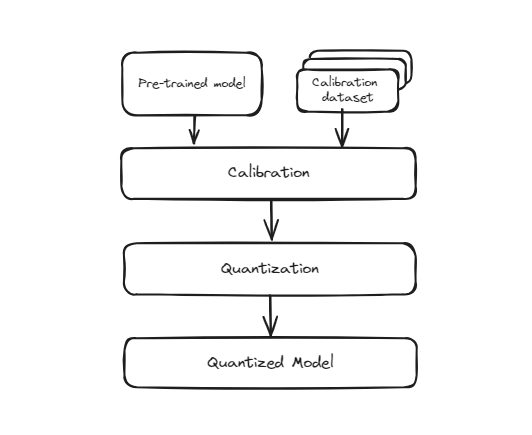
事前トレーニング量子化
ただし、この変換中に重みの精度が低下するため、数字の認識精度がわずかに低下する可能性があります。これは、モバイルアプリケーション、組み込みシステム、エッジコンピューティングなど、モデルのサイズと推論速度が重要なシナリオで特に有用です。精度のわずかな低下にもかかわらず、効率性とスケーラビリティの利点のために、これらのトレードオフはしばしば妥当なものです。
# 量子化対応トレーニング(QAT)
この技術は、ニューラルネットワークのトレーニングプロセスに直接量子化を組み込みます。トレーニングを最初に行い、それから低精度に変換するのではなく、QATはトレーニング中から低精度を考慮してモデルをトレーニングします。つまり、トレーニング中にモデルの重みと活性化を「フェイク量子化」して、低精度の効果をシミュレートします。これにより、モデルは量子化された値の制約内で効果的に動作する方法を学習し、実際に低精度に変換されたときにより良いパフォーマンスを発揮します。QATは、トレーニング中に追加のステップが必要なため、より多くの計算リソースと時間が必要ですが、通常は事後トレーニング量子化(PTQ)と比較して高い精度を実現します。
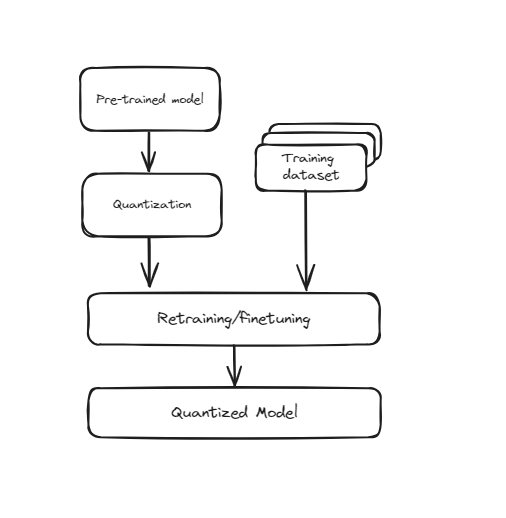
トレーニング対応量子化
これは、画像認識、自然言語処理、その他のAIタスクなど、高い精度を維持することが重要なアプリケーションに特に有用です。トレーニング時間とリソース要件が増加する一方で、低精度での改善されたパフォーマンスと精度は、リソースに制約のある環境で高性能なモデルを展開するための貴重な手法となります。
# 量子化の利点と欠点
利点:
- モデルのストレージスペースが少なくなり、配布と展開が容易になります。
- 低精度の計算は高速化され、リアルタイムのパフォーマンスが向上します。
- バッテリー駆動デバイスに最適です。
欠点:
- 量子化はエラーを導入する可能性があり、モデルの精度が低下する場合があります。
- 特に非対称量子化とQATの場合。
- すべてのハードウェアがすべてのタイプの量子化を効率的にサポートしているわけではありません。

# 量子化の実践的な例
この例では、transformersとtorchライブラリを使用して、事前にトレーニングされたDistilBERTモデルに対して動的な量子化を実行する方法を示します。これにより、モデルのサイズが削減され、計算リソースに制約のあるデバイスで展開することができるようになります。
まず、ターミナルで次のコマンドを実行して、量子化を実行するためにtransformersとtorchライブラリをインストールします。
pip install transformers torch
torchライブラリは、PyTorchモデルと量子化タスクの処理に使用され、transformersライブラリは、事前にトレーニングされたDistilBERTモデルとトークナイザをロードするために使用されます。また、osモジュールは、ファイルの読み書きなど、オペレーティングシステムとのやり取りに使用されます。
import torch
from transformers import DistilBertModel, DistilBertTokenizer
import os
次に、DistilBertModelクラスとDistilBertTokenizerクラスを使用して、事前にトレーニングされたDistilBERTモデルとトークナイザをロードします。モデル名にはdistilbert-base-uncasedを使用して、特定のバリアントのDistilBERTを指定します。
model_name = 'distilbert-base-uncased'
model = DistilBertModel.from_pretrained(model_name)
tokenizer = DistilBertTokenizer.from_pretrained(model_name)
次に、モデルに動的な量子化を実行するquantize_model関数を定義します。torch.quantization.quantize_dynamic関数を使用して、モデルを量子化バージョンに変換します。この際には、torch.nn.Linearレイヤーをターゲットにし、8ビット整数(qint8)精度を使用します。
def quantize_model(model):
quantized_model = torch.quantization.quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.qint8
)
return quantized_model
次に、DistilBERTモデルにquantize_model関数を適用し、モデルの量子化バージョンを取得します。
quantized_model = quantize_model(model)
最後に、print_model_size関数を定義して、元のモデルと量子化されたモデルのサイズをチェックして表示します。torch.save関数を使用して、モデルの状態辞書をファイルに保存し、os.path.getsize関数を使用してファイルサイズ(メガバイト単位)を取得します。
def print_model_size(model, model_name):
torch.save(model.state_dict(), f'{model_name}.pt')
print(f'Size of {model_name}: {os.path.getsize(f"{model_name}.pt") / 1e6} MB')
この関数を使用して、元のDistilBERTモデルと量子化されたモデルのサイズを表示します。
print_model_size(model, 'original_distilbert')
print_model_size(quantized_model, 'quantized_distilbert')
コードの最終的な出力は次のようになります。
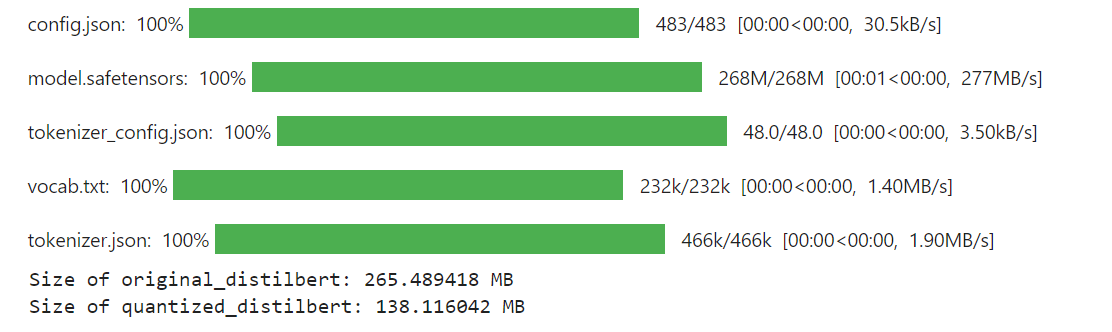
結果
この例では、DistilBERTモデルに量子化を適用することで、元のモデルのサイズが265 MBから138 MBに大幅に削減されました。
# 量子化がRAGシステムの構築にどのように役立つか
量子化により、サイズが大きいモデルを効果的に使用することができ、パフォーマンスの低下をほとんど伴わずにサイズを削減することができます。LLMは、サイズが大きくなるにつれて自然により優れた機能を持ちますが、計算リソースも必要とします。量子化により、これらの大規模モデルを縮小することができるため、リソースに制約のある環境に展開することができますが、拡張された機能を享受することができます。
ベクトルデータベースは、量子化技術と統合することで、効率性とスケーラビリティを向上させることができ、RAGシステムを大幅に強化することができます。量子化された埋め込みを保存して検索することで、ベクトルデータベースは高速な検索、メモリ使用量の削減、および低い計算コストを実現します。これにより、RAGシステムはより大きなデータセットを処理し、より迅速に応答することができますが、受け入れ可能な精度を維持します。量子化LLMとの互換性により、パイプライン全体での一貫性が確保され、全体的なパフォーマンスが向上する可能性があります。MyScaleDB (opens new window)は、効率的で正確なデータの取得を提供することで、RAGのパフォーマンスをさらに向上させます。使い慣れたSQLインターフェースを備えたMyScaleDBは、開発者にとって使いやすく、手頃な価格で高速かつ本番レベルのRAGアプリケーションに最適です。
ご意見やご提案がありましたら、Twitter (opens new window)またはDiscord (opens new window)でお知らせください。



