
![]()
**LlamaIndex (opens new window)**は、大規模言語モデル(LLM)を使用したアプリケーションを実装するためのデータフレームワークです。これにより、パース、保存、検索、さまざまなタイプのドキュメントデータの取得を簡素化し、LLMアプリケーションの機能を大幅に向上させることができます。このメカニズムは一般的にRetrieval-Augmented Generation(RAG)と呼ばれています。
この記事では、LlamaIndexを使用してこのメカニズムを実装する方法を理解するために、シンプルなドキュメントクエリエンジンを構築してプロセスをデモンストレーションします。
# MyScale
LlamaIndexはさまざまなタイプのソースデータを処理できますが、データの保存やインデックス作成は行いません。したがって、ストレージシステムが必要です。**MyScale (opens new window)**は、SQLをサポートし、使いやすいベクトルデータベースであり、無料版では最大500万のベクトルデータポイントをサポートしています。さらに、LlamaIndexはMyScaleベクトルデータベースをサポート (opens new window)しています。MyScaleVectorStoreとMyScaleReaderを使用してMyScaleデータベースに接続し、LlamaIndexを介して次のデータ操作を実行することができます。
| ベクトルストア | タイプ | メタデータフィルタリング | ハイブリッド検索 | 削除 | ドキュメントの保存 |
|---|---|---|---|---|---|
| MyScale | クラウド | ✓ | ✓ | ✓ | ✓ |
この一連の操作により、包括的な機能が提供されます。それでは、これらの操作を使用してLLMアプリケーションを構築しましょう。
# 準備
注意:
この記事で言及されている関連するコードは、GitHubのリポジトリmyscale/llama_index_myscale (opens new window)で見つけることができます。
# データ
私たちは、公式のMyScaleドキュメント(MyScale Docs (opens new window))をMarkdown形式で使用しました。これらのファイルはGitHub (opens new window)で表示およびダウンロードすることもできます。
# 依存関係
- Python 3.8.18
- LlamaIndex 0.9.5
- MyScale
# プロセスフロー
Retrieval-Augmented Generation(RAG)アプリケーションの構築には、複数の処理ステップが関与します。以下の図は、まずオフラインで生データを処理する必要があります。これには、テキストデータ(フラットファイルに格納されている)を特定の基準またはルールに基づいてデータノードに分割することが含まれます。これが完了したら、各データノードのベクトル表現を計算する必要があります。最後に、データをデータベースに保存する必要があります。
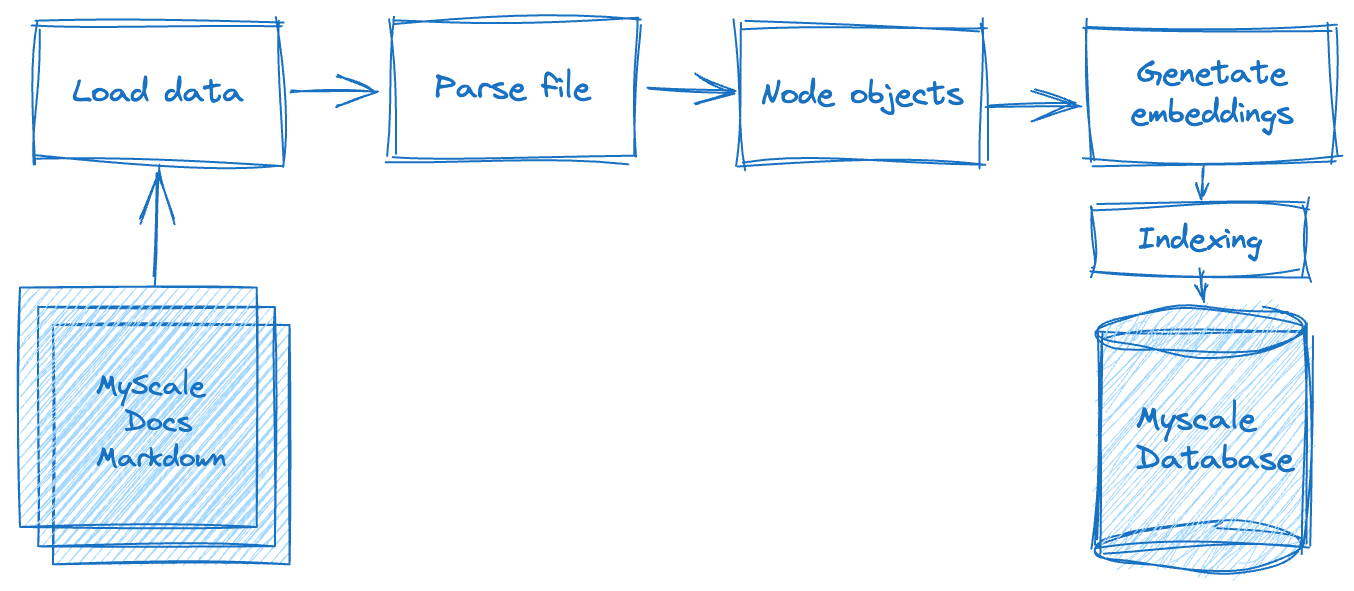
第2フェーズであるデータ検索フェーズでは、このクエリに基づいて関連するドキュメントデータをクエリし、マージします。このデータは、LLMシステムによって要求され、返され、期待される結果を返します。
それでは、LlamaIndexをMyScaleと統合してこれらのステップを実行する方法を見ていきましょう。
# データの読み込み
このフェーズでは、ダウンロードしたドキュメントファイルを読み込み、それらをMyScaleのドキュメントオブジェクトに変換し、Markdown、PDF、Wordドキュメント、PowerPointデッキ、画像、音声、ビデオなどのさまざまな形式のドキュメントを含む、LlamaIndexの豊富なドキュメント処理機能を利用する必要があります。.mdドキュメントの場合、以下のようにMarkdownReaderを使用します。
# utils.py
from llama_index import download_loader
from llama_index import Document
from typing import Dict, List, Union
from pathlib import Path
UnstructuredReader = download_loader("MarkdownReader")
loader = UnstructuredReader()
def load_and_parse_files(file_row: Dict[str, Path]) -> List[Dict[str, Document]]:
documents = []
file = file_row["path"]
if file.is_dir():
return []
# Skip all non-md files like png, jpg, etc., html.
if file.suffix.lower() == ".md":
loaded_doc = loader.load_data(file=file)
loaded_doc[0].extra_info = {"path": str(file)}
documents.extend(loaded_doc)
return [{"doc": doc} for doc in documents]
# ドキュメントのパース
これらのドキュメントからテキストセグメントを読み取った後、次のベクトル化操作のためにデータノードにカプセル化する必要があります。フォーマットの一貫性を確保するために、引き続きMarkdownNodeParserを使用します。この部分の処理フローは次のとおりです。
# utils.py
from llama_index.node_parser import MarkdownNodeParser
from llama_index.data_structs import Node
def convert_documents_into_nodes(documents: Dict[str, Document]) -> List[Dict[str, Node]]:
parser = MarkdownNodeParser()
document = documents["doc"]
nodes = parser.get_nodes_from_documents([document])
return [{"node": node} for node in nodes]
# ベクトル化
ベクトル化は重要で時間のかかるステップです。これには、前のステップで返されたデータノードのテキストコンテンツをベクトル化し、ベクトルをデータノードの「埋め込み」フィールドに保存する必要があります。sentence-transformers/all-mpnet-base-v2モデル (opens new window)を使用します。これはHugging Faceから入手できます。LlamaIndexは、これらの埋め込みをダウンロードして適用するために自動的にサポートしてくれます。
# utils.py
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
class EmbedNodes:
def __init__(self):
self.embedding_model = HuggingFaceEmbeddings(
# Use all-mpnet-base-v2 Sentence_transformer.
# This is the default embedding model for LlamaIndex/Langchain.
model_name="sentence-transformers/all-mpnet-base-v2",
model_kwargs={},
# Use GPU for embedding and specify a large enough batch size to maximize GPU utilization.
# Remove the "device": "cuda" to use CPU instead.
encode_kwargs={"batch_size": 100}
)
def __call__(self, node_batch: Dict[str, List[Node]]) -> Dict[str, List[Node]]:
nodes = node_batch["node"]
text = [node.text for node in nodes]
embeddings = self.embedding_model.embed_documents(text)
assert len(nodes) == len(embeddings)
for node, embedding in zip(nodes, embeddings):
node.embedding = embedding
return {"embedded_nodes": nodes}
# ローカルでの実行とMyScaleへの保存
上記のプロセスでは、Markdownドキュメントのパースとベクトル化の主な操作を紹介しました。次に、データを出力し、インデックスを構築する必要があります。LlamaIndexでは、次のPythonスクリプトのように、これらの複雑でない操作を実行するためにMyScaleVectorStoreを使用できます。
注意:
このスクリプトには、データ処理フロー全体が含まれています。
# create_vector_index.py
import clickhouse_connect
import utils
from pathlib import Path
from llama_index import VectorStoreIndex
from llama_index.vector_stores import MyScaleVectorStore
from llama_index.storage import StorageContext
all_docs_gen = Path("./docs.myscale.com/").rglob("*")
all_docs = [{"path": doc.resolve()} for doc in all_docs_gen]
blog_nodes = {"embedded_nodes": []}
for docs in all_docs:
loaded_docs = utils.load_and_parse_files(docs)
for doc in loaded_docs:
nodes = utils.convert_documents_into_nodes(doc)
newNodes = {"node": []}
for node in nodes:
newNodes["node"].append(node["node"])
embedNodes = utils.EmbedNodes()
tmpNodes = embedNodes(newNodes)
blog_nodes["embedded_nodes"].extend(tmpNodes["embedded_nodes"])
client = clickhouse_connect.get_client(
host='{MYSCALE_CLUSTER_URL}',
port=443,
username='{YOUR_USERNAME}',
password='{YOUR_PASSWORD}'
)
vector_store = MyScaleVectorStore(myscale_client=client)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
VectorStoreIndex(blog_nodes["embedded_nodes"], storage_context=storage_context)
再利用性のために、load_and_parse_files、convert_documents_into_nodes、EmbedNodesという関数はutils.pyに配置されています。
# クエリサービスの構築
データがMyScaleに保存されたら、MyScaleVectorStoreとLLMのAPIを使用してユーザーのクエリを処理することができます。以下のスクリプトでこれを行います(query_myscale.py)。このスクリプトには、次の主要なステップが含まれています。
このスクリプトには、次の主要なステップが含まれています。
- ターミナルからユーザーの入力クエリを読み取り、クエリをベクトル化します。
llama_index.vector_stores.MyScaleVectorStoreを使用して、ハイブリッド検索モードを使用してクエリに関連するデータをクエリします。このモードでは、テキストとベクトルの距離の両方で一定の関連性が確保されます。- 前のステップで取得したドキュメントをLLMに送信して最終結果を生成し、応答を合成します。
# query_myscale.py
import clickhouse_connect
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from llama_index.schema import NodeWithScore
from llama_index.vector_stores import MyScaleVectorStore, VectorStoreQuery
from llama_index.vector_stores.types import VectorStoreQueryMode
# Add your OpenAI API Key here before running the script.
model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")
client = clickhouse_connect.get_client(
host='{MYSCALE_CLUSTER_URL}',
port=443,
username='{YOUR_USERNAME}',
password='{YOUR_PASSWORD}'
)
# input query
query = input("Query: ")
while len(query) == 0:
query = input("\nQuery: ")
# embedding query
embedded_query = model.embed_query(query)
# send query to myscale by using llama_index.vector_stores.MyScaleVectorStore
vector_store = MyScaleVectorStore(myscale_client=client)
vector_store_query = VectorStoreQuery(
query_embedding=embedded_query,
similarity_top_k=20,
mode=VectorStoreQueryMode.HYBRID
)
result = vector_store.query(vector_store_query)
scoreNodes = [NodeWithScore(node=result.nodes[i], score=result.similarities[i]) for i in range(len(result.nodes))]
# synthesize the response
from llama_index.response_synthesizers import (
get_response_synthesizer,
)
synthesizer = get_response_synthesizer()
response_obj = synthesizer.synthesize(query, scoreNodes)
print(f"Response: {str(response_obj.response)}")
注意:
{MYSCALE_CLUSTER_URL}、{YOUR_USERNAME}、{YOUR_PASSWORD}などのプレースホルダーを実際のMyScaleクラスタ情報に置き換えてください。

# スクリプトの実行
スクリプトを実行し、プロンプトに続いてクエリを入力すると、次のような応答が返されます。
$ python query_myscale.py
Query: MyScaleクラスタを作成する方法は?
Response: MyScaleクラスタを作成するには、次の手順に従ってください:
1. クラスタページに移動します。
2. 「+ 新しいクラスタ」ボタンをクリックします。
3. クラスタに名前を付けます。
4. クラスタを実行するために「起動」をクリックします。
クラスタが作成されると、自動的に開始されます。クラスタに7日間アクティビティがない場合、クラスタは終了され、クラスタ内のすべてのデータが削除されます。
MyScaleに関連するさまざまな質問を入力することができます。このアプリケーションは、有益な回答を提供するように設計されています。
# さらに進む
MyScaleとLlamaIndexを使用して完全に機能するLLMアプリケーションを構築し、その効果的なパフォーマンスを実証しました。10万件、100万件のドキュメントデータに対応するために埋め込み処理を高速化するにはどうすればよいでしょうか?
幸いなことに、Rayという機械学習向けのフレームワークを使用して、LlamaIndexとMyScaleと組み合わせて分散処理を行い、データ処理の効率を向上させることができます。ローカルまたはKubernetesベースのクラスタを構築するために、Ray公式ドキュメントのInstalling Ray (opens new window)やRay on Kubernetes (opens new window)を参照してください。
すでにローカルホストにRayCluster Headを持っているか、KubernetesクラスタでRayCluster Headのポストフォワードを有効にしていると仮定します。次のコードを使用して、並列計算を使用した埋め込み処理の高速化を行い、データ処理の速度と効率を大幅に向上させることができます。
# create_vector_index_by_ray.py
import clickhouse_connect
import utils
import ray
from pathlib import Path
from llama_index import VectorStoreIndex
from llama_index.vector_stores import MyScaleVectorStore
from llama_index.storage import StorageContext
from ray.data import ActorPoolStrategy
all_docs_gen = Path("./docs.myscale.com/").rglob("*")
all_docs = [{"path": doc.resolve()} for doc in all_docs_gen]
ds = ray.data.from_items(all_docs)
loaded_docs = ds.flat_map(utils.load_and_parse_files)
nodes = loaded_docs.flat_map(utils.convert_documents_into_nodes)
embedded_nodes = nodes.map_batches(
utils.EmbedNodes,
batch_size=100,
compute=ActorPoolStrategy(size=4),
num_gpus=0)
blogs_nodes = []
for row in embedded_nodes.iter_rows():
node = row["embedded_nodes"]
assert node.embedding is not None
blogs_nodes.append(node)
client = clickhouse_connect.get_client(
host='{MYSCALE_CLUSTER_URL}',
port=443,
username='{YOUR_USERNAME}',
password='{YOUR_PASSWORD}'
)
vector_store = MyScaleVectorStore(myscale_client=client)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
VectorStoreIndex(blogs_nodes, storage_context=storage_context)
これらのプロセスは、ローカルでの実行とMyScaleへの保存セクションで説明した入力と出力と同じものを使用して、MyScaleデータベースに保存されている関連するベクトルデータをクエリすることもできます。query_myscale.pyを使用してクエリを実行できます。
# まとめ
MyScaleとLlamaIndexは、LLM処理に優れたツールです。これらを使用すると、迅速にLLMアプリケーションを構築することができます。データスケールの問題に直面した場合、分散処理のためにRayを使用し、LlamaIndexとMyScaleと組み合わせることで、開発の容易さを大幅に向上させることができます。
最後に、大規模なRAGアプリケーションについては、遅延なくクラスタをセットアップするためにmyscale.com (opens new window)を訪れてください!



