
生成AI(GenAI)の反復速度は指数関数的に成長しています。その結果、大規模言語モデル(LLM)が一度に使用できるトークンの数であるコンテキストウィンドウも急速に拡大しています。
2024年2月にリリースされたGoogle Gemini 1.5 Proは、最長のコンテキストウィンドウの記録を樹立しました。これは100万トークンで、1時間のビデオまたは70万語に相当します。Geminiの長いコンテキストを処理する優れたパフォーマンスにより、「検索支援型生成(RAG)は終わった」とする人々も現れました。既存のLLMは非常に強力な検索モデルであるため、弱い検索モデルを構築し、チャンキング、埋め込み、インデックスなどのRAG関連の問題に対処する必要はないと述べました。
コンテキストウィンドウの拡大は、これらの改善により、RAGはまだ必要か、それともすぐに時代遅れになる可能性があるのかという議論を引き起こしました。
# RAGの仕組み
LLMは機械が理解し達成できる範囲を常に広げていますが、未知のデータに正確に応答する難しさや最新情報に追いつく難しさなどの問題に制約されてきました。これらの問題に対処するためにRAGが開発されました (opens new window)。
RAGは、LLMのパワーと外部の知識源を組み合わせて、より情報豊かで正確な応答を生成します。ユーザーのクエリが受信されると、RAGシステムはまずテキストを処理してそのコンテキストと意図を理解します。次に、ユーザーのクエリに関連するデータを知識ベース (opens new window)から取得し、クエリとともにLLMにコンテキストとして渡します。知識ベース全体を渡すのではなく、LLMは一度に考慮または理解できるテキストの量であるコンテキスト制限 (opens new window)により、関連するデータのみを渡します。
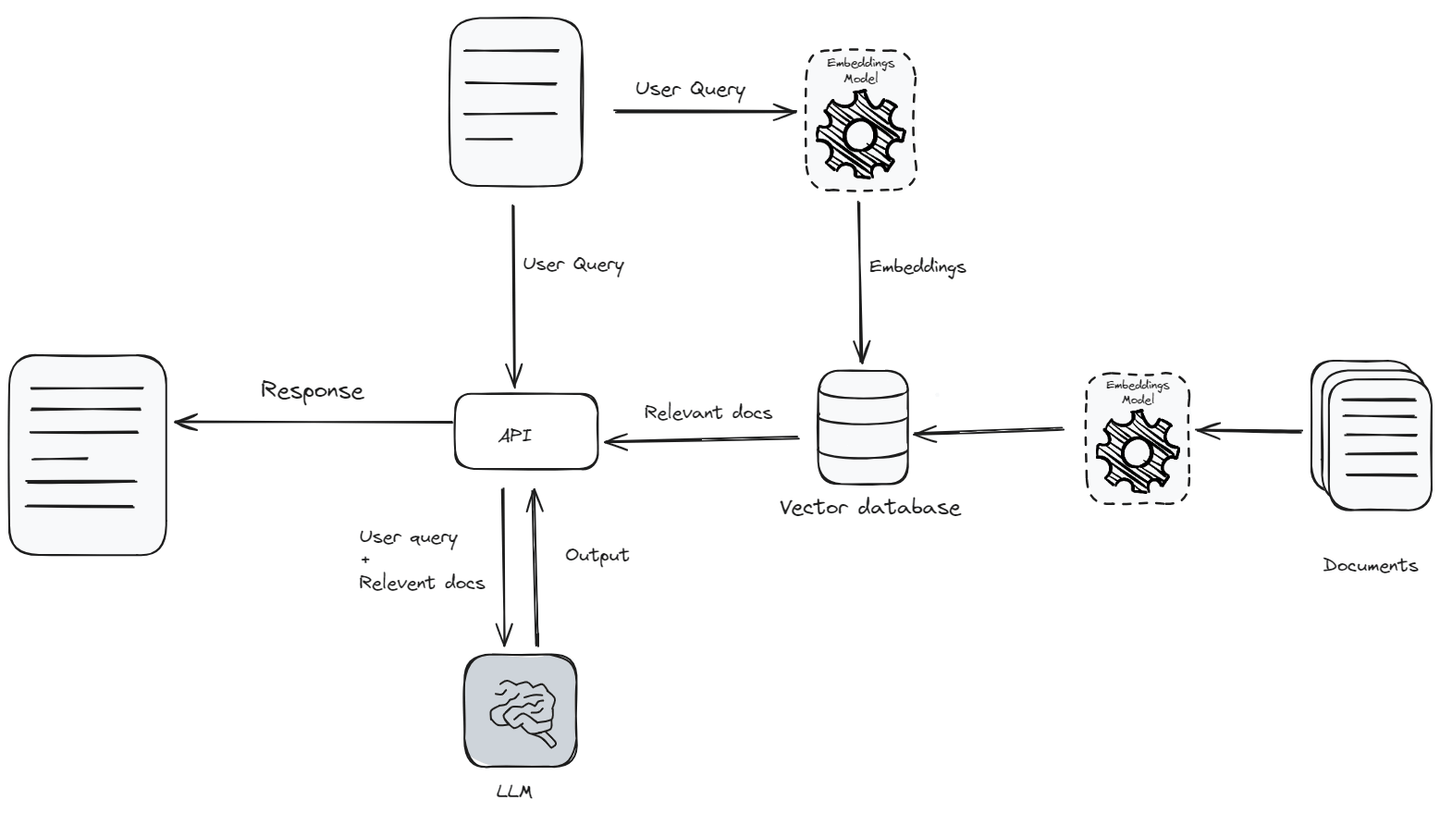
まず、クエリ (opens new window)はベクトル埋め込み (opens new window)を使用して埋め込まれます。この埋め込みベクトルは、ドキュメントベクトルのデータベースと比較され、最も関連性の高いドキュメントが特定されます。これらの関連するドキュメントは取得され、元のクエリと組み合わされ、LLMがより正確な応答を生成するための豊かなコンテキストを提供します。このハイブリッドアプローチにより、モデルは外部ソースの最新情報を使用することができ、LLMがより情報豊かで正確な応答を生成することができます。
# 長いコンテキストウィンドウがRAGの終わりになる理由
LLMのコンテキストウィンドウの持続的な拡大は、これらのモデルが情報を取り込み、応答を生成する方法に直接影響を与えます。テキストの処理量を増やすことで、これらの拡張されたコンテキストウィンドウは、モデルがより包括的な物語や複雑なアイデアを理解する能力を向上させ、生成される応答の全体的な品質と関連性を向上させます。これにより、LLMはより長いテキストを追跡し、コンテキストとその細部をより効果的に把握することができるようになります。その結果、LLMが広範なコンテキストを処理し統合する能力が向上するにつれて、応答の正確さと関連性を向上させるためのRAGへの依存度は低下する可能性があります。
# 正確性
RAGは、類似性スコア (opens new window)に基づいてコンテキストとして関連するドキュメントを提供することで、モデルの能力を向上させます。しかし、RAGはコンテキストをリアルタイムで適応または学習しません。代わりに、ユーザーのクエリに似たドキュメントを取得し、それが常に最も文脈的に適切なものではない場合があり、正確性の低下を引き起こす可能性があります。
一方、LLMの長いコンテキストウィンドウを利用して、すべてのデータを内部に詰め込むことで、LLMの注意機構 (opens new window)はより良い回答を生成することができます。言語モデル内の注意機構は、提供されたコンテキストの異なる部分に焦点を当て、正確な応答を生成します。さらに、このメカニズムは微調整 (opens new window)することができます。LLMモデルを調整して損失を減らすことで、徐々に改善され、より正確で文脈的に関連性のある応答が生成されます。
# 情報検索
LLMの応答を向上させるために知識ベースから情報を取得する際、コンテキストウィンドウのために完全で関連性のあるデータを見つけることは常に困難です。取得したデータがユーザーのクエリに完全に答えているかどうかについては常に不確実性があります。この状況では、情報が十分でなく、会話の文脈やユーザーの実際の意図と一致しない場合、効率が低下しエラーが発生する可能性があります。
# 外部ストレージ
従来、LLMは処理できるコンテキストの量に制約があったため、大量の情報を同時に処理することはできませんでした。しかし、新たな能力により、LLMは直接大量のデータを処理できるようになり、クエリごとの別個のストレージの必要性がなくなりました。これにより、アーキテクチャが合理化され、外部データベースへのアクセスが高速化され、AIの効率が向上します。
# RAGが残り続ける理由
LLMの拡張されたコンテキストウィンドウは、モデルにより深い洞察を提供するかもしれませんが、高い計算コストと効率などの課題ももたらします。RAGは、最も関連性の高い情報のみを選択的に取得することにより、パフォーマンスと正確性を最適化するのに役立ちます。
# 複雑なRAGは継続します
データが固定長のドキュメントにチャンク分けされ、類似性に基づいて取得される単純なRAGは確かに衰退しています。しかし、複雑なRAGシステムはただ消えていくのではなく、大きく進化しています。
複雑なRAGには、クエリの書き換え (opens new window)、データのクリーニング (opens new window)、反射 (opens new window)、最適化されたベクトル検索 (opens new window)、グラフ検索 (opens new window)、再ランキング (opens new window)など、より洗練されたチャンキング技術など、さまざまな機能が含まれています。これらの改良は、RAGの機能を洗練させるだけでなく、その能力を拡大しています。
# コンテキストの長さを超えたパフォーマンス
LLMのコンテキストウィンドウを数百万のトークンに拡大することは有望に見えますが、実際の実装は時間、効率、コストなどの要素により疑問視されています。
時間: コンテキストウィンドウのサイズが拡大すると、応答時間の遅延が増加します。コンテキストウィンドウのサイズを拡大すると、LLMはより多くのトークンを処理するためにより多くの時間を要し、遅延とレイテンシが増加します。多くのLLMアプリケーションでは、迅速な応答が必要です。より大きなテキストブロックの処理による追加の遅延は、リアルタイムシナリオでのLLMのパフォーマンスに大きなボトルネックを作り出す可能性があります。
効率: 研究によると、LLMは多くのフィルタリングされていないデータよりも少ないが関連性の高いドキュメントを提供された場合により良い結果を得ることができます。最近のStanfordの研究 (opens new window)では、最先端のLLMは、広範なコンテキストウィンドウから価値のある情報を抽出するのに苦労することが多いことがわかりました。特に重要なデータが大きなテキストブロックの中に埋もれている場合、LLMは重要な詳細を見落とし、効率の低いデータ処理を引き起こす可能性があります。
コスト: LLMのコンテキストウィンドウのサイズを拡大すると、計算コストが増加します。より多くの入力トークンを処理するには、より多くのリソースが必要です。たとえば、ChatGPTなどのシステムでは、コストを管理するために処理するトークンの数を制限することに焦点が当てられています。
RAGは、これらの3つの要素を直接最適化します。すべてを詰め込むのではなく、類似または関連するドキュメントのみをコンテキストとして渡すことにより、LLMは情報をより迅速に処理するため、レイテンシが低下し、応答の品質が向上し、コストが低下します。
# ファインチューニングではない理由
大規模なコンテキストウィンドウの使用に加えて、RAGの代替手段としてのもう1つの選択肢はファインチューニングです。しかし、ファインチューニングは費用がかかり、手間がかかります。新しい情報が入ってくるたびにLLMを更新して最新の情報にすることは難しいです。ファインチューニングに関連する他の問題には以下があります。
- トレーニングデータの制約: LLMの進歩に関わらず、トレーニング時に利用できなかったコンテキストや関連性のないコンテキストが常に存在します。
- 計算リソース: LLMをデータセットでファインチューニングし、特定のタスクに合わせて調整するには、高い計算リソースが必要です。
- 専門知識の必要性: 最先端のAIを開発・維持することは容易なことではありません。専門的なスキルと知識が必要であり、それらを獲得するのは困難な場合があります。
その他の問題には、データの収集、品質が十分に良いことの確認、モデルの展開などがあります。
# RAG vs ファインチューニングまたは長いコンテキストウィンドウの比較
以下は、RAGとファインチューニングまたは長いコンテキストウィンドウの技術(後者2つは類似した特性を持つため、このチャートで組み合わせました)の比較概要です。コスト、データのタイムリネス、スケーラビリティなどの重要な側面を強調しています。
| 特徴 | RAG | ファインチューニング / 長いコンテキストウィンドウ |
| コスト | 最小限、トレーニング不要 | 高い、広範なトレーニングと更新が必要 |
| データのタイムリネス | データは必要に応じて取得され、最新の状態が保たれる | データはすぐに古くなる可能性がある |
| 透明性 | 高い、取得されたドキュメントが表示される | 低い、データが結果にどのように影響するかが不明瞭 |
| スケーラビリティ | 高い、さまざまなデータソースと簡単に統合できる | 制約があり、スケーリングには大きなリソースが必要 |
| パフォーマンス | 選択的なデータの取得がパフォーマンスを向上させる | コンテキストのサイズが大きくなるとパフォーマンスが低下する可能性がある |
| 適応性 | 再トレーニングなしで特定のタスクに合わせることができる | 大幅な適応には再トレーニングが必要 |

# ベクトルデータベースを使用したRAGシステムの最適化
最先端のLLMは、数百万のトークンを同時に処理できますが、複雑なデータ構造の複雑さと絶えず進化する性質により、LLMは異種のエンタープライズデータを効果的に管理することは困難です。RAGはこれらの課題に対処していますが、検索の精度はエンドツーエンドのパフォーマンスにおいて依然として主要なボトルネックです。大規模なコンテキストウィンドウのLLMまたはRAGであれ、ビッグデータを最大限に活用し、大規模なデータ処理の高効率を確保することが目標です。
MyScaleDB (opens new window)のような高度なSQLベクトルデータベースを使用して、LLMとビッグデータを統合 (opens new window)することで、LLMの効果を高め、ビッグデータからより良いインテリジェンスを抽出することができます。さらに、モデルの幻覚を軽減し、データの透明性を提供し、信頼性を向上させます。MyScaleDBは、大規模なAI/RAGアプリケーションに特化したオープンソースのSQLベクトルデータベースで、ClickHouseをベースにしており、独自のMSTGアルゴリズムを特徴としています。MyScaleDBは、他のベクトルデータベースと比較して、大規模なデータの管理において優れたパフォーマンスを発揮 (opens new window)します。
LLM技術は世界を変えつつあり、長期的なメモリの重要性は続きます。大企業が生成AIを本番環境に導入する際には、クエリの品質をコスト管理しながら維持する必要があります。RAGとベクトルデータベースは、この目標を達成するための重要なツールです。
GitHub (opens new window)でMyScaleDBを詳しく見るか、Discord (opens new window)でLLMやRAGについてさらに議論することができます。



