
科学文献の膨大な量の成長は、研究者が効率的に知識を発見する能力を妨げる大きな障害となっています。米国国立科学財団によると、研究者は研究時間の51%を研究資料の検索と消化に費やしています。
Science Navigator (opens new window)は、北京のAI for Science Institute(AISI)によって開発されたAIパワードプラットフォームで、効率的で正確な文献レビューを提供するためのものです。本記事では、サイエンスナビゲーターの具体的な要件、基礎としてのMyScale (opens new window)の選択の理由、およびプラットフォームにもたらす具体的な利点について探っていきます。
# サイエンスナビゲーター:科学文献レビューのパラダイムシフト
科学研究において、文献レビューは重要なステップです。ブラウジングや検索ベースの検索は主流の手法ですが、大規模言語モデル(LLM)の急速な発展により、より多くの研究者がAIの手法を文献レビューに使用するようになりました。AI for Scienceインフラストラクチャ内の革新的なプロジェクトであるサイエンスナビゲーター1.0は、文献データベースや知識ベースの代替として機能します。サイエンスナビゲーターは、研究者の効率を大幅に向上させるだけでなく、科学的探求の新たな道を切り拓きます。

科学研究の実践的なニーズに基づいて、多くの要求が未満たされていることがわかりました。例えば、異分野間の研究が当たり前になっており、異なるコンテンツの横断的な検索の要求がより緊急となっています。従来のキーワードベースの検索方法とは異なり、コンテンツの横断的な検索に対する要件は高くなっています。
現在のLLMは、横断的な検索の能力を効果的に向上させることができますが、幻覚や関連のない回答などの問題も抱えています。科学研究の厳密さを考慮すると、コンテンツの追跡性への要求はますます強まっています。そのため、サイエンスナビゲーターは、1億以上の研究論文を効果的に管理し、さまざまなタイプのデータを効率的に保存およびインデックス化し、クエリの正確性を確保できる強力なデータベースを必要とします。さまざまなソリューションを評価した結果、MyScaleの利点が明らかになりました。これらの利点について詳しく見ていきましょう。
# ベクトルデータベースの要件
サイエンスナビゲーターは、研究者向けのRetrieval-Augmented Generation (RAG) (opens new window) パワードのナレッジベースQ&Aシステムであり、学術界、材料科学、化学工学、生物医学科学など、複数の分野で効率的な専門的な知識獲得サービスを提供し、研究効率を大幅に向上させます。
この目標を達成するために、ベクトルデータベースには以下の要件があります。
# データ管理
サイエンスナビゲーターには、複雑で多様なデータタイプを含む科学文献が含まれています。科学文献には、テキスト以外にも分子式、数式、グラフなど、豊かな人間の知恵を具現化した固有の科学的表現が含まれています。これらのさまざまなタイプと形式のデータを効果的に保存し、追跡可能性を確保することは、ベクトルデータベースの課題です。
# データクエリの正確性
サイエンスナビゲーターは、企業や研究機関の研究者にサービスを提供する際に、クエリ結果の正確性を確保する必要があります。同時に、システムは高い並行性の下で高性能な検索を維持する必要があり、研究者がいつでもどこでも情報にアクセスできるようにすることで、研究効率を向上させます。これには、システムのクエリの正確性とパフォーマンスに対する高い要求があります。
# マルチテナントデータの分離
最後に、サイエンスナビゲーターは、複数の業界や分野のユーザーグループをサポートするように設計されています。それぞれのユーザーのデータとサービスが独立(またはカプセル化)され、お互いに干渉しないようにする必要があります。これにより、異なる学術的背景を持つ研究者の個別のニーズによりよく対応できるようになります。これには、柔軟なマルチテナント管理機能を持つ基礎となるデータベースが必要です。
# MyScaleを選んだ理由
サイエンスナビゲーターの目標は、研究者が迅速に正確な研究文献を入手することです。そのため、自然言語クエリのサポートが重要な機能となります。自然言語クエリをサポートするために、Text2SQL (opens new window)やSelfQueryなどの技術に頼っています。MyScaleはClickHouse上に構築されており、完全なSQL構文をサポートし、LangChainに基づくSelfQueryRetriever (opens new window)を提供しています。これにより、構造化クエリと非構造化クエリを組み合わせることができ、要件を完璧に満たすことができます。
さらに、MyScaleは従来のリレーショナルデータベースのように構造化データを処理することができ、開発者は複雑なSQLクエリ、集計、分析を実行することができます。ユーザーは自然言語の質問も使用できるため、SQLに慣れていない人にとってもシステムの使いやすさが向上し、使用の敷居が下がります。
クエリの正確性と関連性を確保するためには、単独のベクトル検索に加えて、ベクトルと構造化データの結合検索が必要です。MyScaleのアーキテクチャは、構造化データと非構造化データの両方を保存し、ベクトル検索と構造化データのクエリをシームレスに統合することができます。結合検索機能により、非構造化データと関連するメタデータを処理し、クエリの意味をより豊かに理解し、より豊富な検索機能を提供することで、検索の関連性を向上させることができます。
さらに、MyScaleのマルチテナント管理機能 (opens new window)は、テーブルベースのマルチテナントやメタデータベースベースの管理戦略など、さまざまな戦略をサポートし、柔軟な要件を満たすことができます。
まとめると、専門のベクトルデータベースやベクトルプラグインを追加した従来のデータベースを調査した結果、サイエンスナビゲーターのすべての要件を満たすのはMyScaleだけであるため、その基礎データベースとして選ばれました。
# ソリューション
サイエンスナビゲーターは、革新的な学術論文検索および対話エージェントプラットフォームです。その中核の一つの利点は、MyScale AIデータベースの強力な機能をフルに活用していることです。MyScaleは、効率的なベクトル検索とBM25キーワード検索をサポートするだけでなく、包括的なSQLサポートも提供しており、サイエンスナビゲーターのデータ管理に大きな柔軟性と効率性をもたらしています。
# データの保存
プラットフォームのデータ基盤には、2億件の論文のメタデータと300万件のArXiv論文の全文コンテンツが含まれています。サイエンスナビゲーターは、特別に開発されたPDFパーサーツールを使用して、論文からテキスト、画像、表、数式を正確に抽出することができます。これらの構造化および非構造化データはすべてMyScaleに保存され、元の形式を保持しながらベクトル形式に変換され、効率的な検索をサポートします。
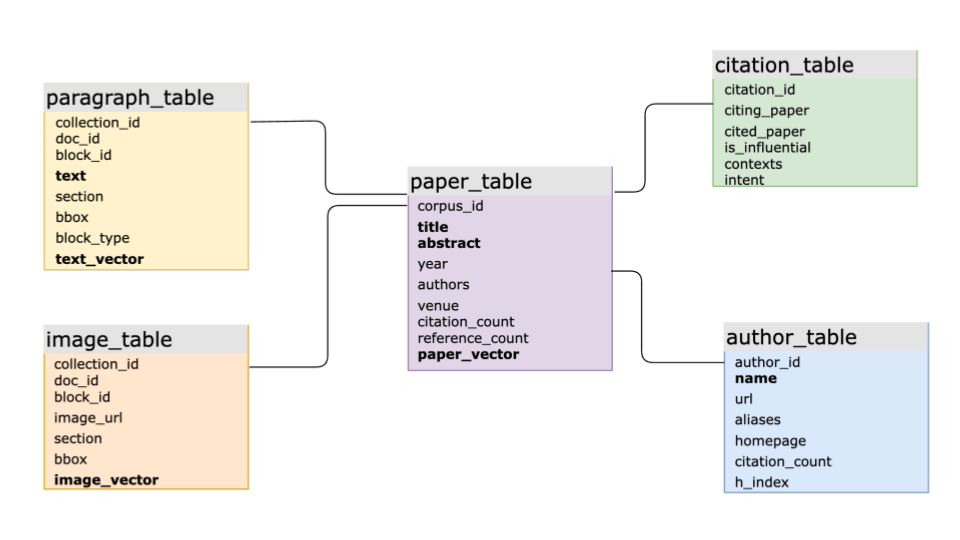
# データ管理と検索
MyScaleが提供する堅牢なSQLサポートにより、サイエンスナビゲーターは単一のデータベースシステム内でさまざまな複雑な論文メタデータを保存することができます。これには、論文間の引用関係、学術ジャーナルの詳細情報、著者と論文の関連付けなどが含まれます。この集中的なデータ保存アプローチにより、データ管理プロセスが大幅に簡素化され、クエリの効率が向上します。
上記の図に示されているように、サイエンスナビゲーターは、関連する論文データを複数のリレーショナルテーブルにMyScaleに保存しています。
- paper_tableは論文のメタデータを保存します。
- text_tableはPDFからパースされた全文データを保存します。
- テキストとそのベクトル表現のためにキーワード逆インデックスとベクトルインデックスが作成されます。
- PDFからパースされた画像の埋め込みはimage_tableに保存され、ベクトルインデックスが作成されます。
- 著者のメタデータはauthor_tableに保存され、著者名のキーワード逆インデックスのみが作成されます。
- 論文間の引用関係はcitation_tableリレーショナルテーブルに直接保存されます。
サイエンスナビゲーターの検索機能は、MyScaleのハイブリッド検索機能をフルに活用しています。ユーザーはベクトル検索とキーワード検索の両方を使用し、SQLクエリと組み合わせて、必要な学術リソースを正確に特定することができます。例えば、論文の内容の類似性、出版年、引用数などの要素に基づいた複雑なクエリを簡単に実装することができます。
対話機能では、MyScaleのSQLサポートにより、サイエンスナビゲーターは迅速に関連情報を取得し、組み合わせて網羅的かつ正確な回答をユーザーに提供することができます。システムは論文の内容、著者情報、引用ネットワークなどを簡単に関連付けて、深い学術的洞察を生成することができます。
# システムの最適化とメンテナンス
サイエンスナビゲーターは、パフォーマンスを継続的に最適化するために、MyScaleを使用してユーザーのインタラクションデータを保存および分析しています。チャット履歴、大規模モデルの呼び出しトレースなどの情報はすべてMyScaleに記録されます。このデータをSQLを使用してクエリおよび分析することで、プラットフォームはユーザーの行動パターンを把握し、検索アルゴリズムや対話モデルを最適化することができます。
MyScaleが提供する堅牢なSQLサポートは、サイエンスナビゲーターに強力なデータ管理および分析機能を提供します。プラットフォームの管理者は、なじみのあるSQL構文を使用して、人気のある研究トピックの追跡、著者の協力ネットワークの分析、ジャーナルの影響因子の評価など、複雑なデータ操作と分析を実行することができます。
まとめると、MyScaleの包括的なSQLサポートとベクトル検索、キーワード検索の強みにより、サイエンスナビゲーターは強力で柔軟性のある効率的な学術研究アシスタントとなりました。高度な検索と対話機能を提供するだけでなく、学術エコシステム全体のデータ管理と分析を強力にサポートします。
# サイエンスナビゲーターにもたらすMyScaleの主な利点
MyScaleを統合することで、サイエンスナビゲーターはパフォーマンスと使いやすさを大幅に向上させるいくつかの高度な機能を活用しています。これらの主な利点は次のとおりです。
- 大規模なマルチモーダルデータの保存
サイエンスナビゲーターは、埋め込みベクトルを使用して、2億件の論文のメタデータと300万件のArXiv論文の全文コンテンツのセマンティック検索を実行できる、最初の論文検索システムです。
- 正確な大規模データの検索
サイエンスナビゲーターの強力な自然言語対話検索機能により、研究者が必要な情報を迅速に特定することができ、文献検索をこれまで以上に簡単かつ迅速に行うことができます。これは、MyScale AIデータベースをプラットフォームに統合することにより、大規模言語モデルの利点と組み合わせて、パラメータ数が3〜6倍のモデルと同等の効果を実現し、トレーニングおよび推論コストを大幅に削減します。
MyScaleは大規模モデルの効果的なメモリキャリアを提供し、研究文献の知識ベースの動的かつ迅速な更新の要件、および正確な出力結果のニーズを満たすことができます。これにより、モデルのスペースを占有せずに、低コストかつ高効率な情報の保存が可能となります。MyScaleの助けを借りて、サイエンスナビゲーターは10億規模のベクトルと大量の構造化データのミリ秒レベルの検索を実現し、研究者の平均文献検索時間を90%以上削減し、複雑なドメイン固有の問題に対して95%以上の質問応答の正確性を維持します。
- コスト効率
高い正確性と高い効率を確保しながら、MyScale AIデータベースは独自のMSTGベクトルインデックスアルゴリズムを採用し、元のベクトルをNVMe SSDに保存します。純粋なメモリベースのHNSWベクトルインデックスアルゴリズムと比較して、メモリ消費量は16倍減少し、総コストは90%以上削減されます。

# 結論
サイエンスナビゲーターは、研究者向けにカスタマイズされたAIプラットフォーム以上のものです。知識抽出や最新の進展の追跡からアイデアの生成、文献レビューの執筆まで、幅広いツールを提供しています。ほとんどの機能にAPIインターフェースを公開することで、サイエンスナビゲーターはユーザーが独自のアプリケーションやインテリジェントエージェントをプラットフォーム上に構築できるようにし、科学研究の複雑で個別のニーズに対応します。
今後もMyScaleの継続的なサポートを受けながら、サイエンスナビゲーターはさまざまな業界の高品質な研究文献を含めるように拡大し、システムのパフォーマンスを継続的に最適化し、研究者にとって強力で使いやすい研究文献ナビゲーターとしての地位を確立していきます。



