
MyScaleは最近、EmbedText (opens new window)関数を導入しました。この強力な機能は、SQLクエリとテキストベクトル化の機能を統合し、テキストを数値ベクトルに変換します。これらのベクトルは、人間が認識する意味的な類似性をベクトル空間内の近接性に効果的にマッピングします。SQLのなじみのある構文を使用することで、EmbedTextはベクトル化プロセスを簡素化し、アクセス性を向上させ、OpenAI (opens new window)、Jina AI (opens new window)、Amazon Bedrock (opens new window)などのプロバイダと組み合わせて、リアルタイムおよびバッチ処理のシナリオで効率的にテキストベクトル化を実行できるようにします。さらに、自動バッチ処理を活用することで、大量のデータの処理性能が大幅に向上します。この統合により、外部ツールや複雑なプログラミングの必要性がなくなり、MyScaleデータベース環境内でのベクトル化プロセスが効率化されます。
# はじめに
EmbedText関数は、EmbedText(text, provider, base_url, api_key, others)と定義され、リアルタイム検索およびバッチ処理の両方に対応する高度に設定可能な機能です。
注意:
この関数の詳細なパラメータは、ドキュメント (opens new window)でご確認いただけます。
次の表に示すように、EmbedText関数は以下の8つのプロバイダをサポートしており、それぞれに独自の利点があります。
| プロバイダ | サポート | プロバイダ | サポート |
|---|---|---|---|
| OpenAI | ✔ | Amazon Bedrock | ✔ |
| HuggingFace | ✔ | Amazon SageMaker | ✔ |
| Cohere | ✔ | Jina AI | ✔ |
| Voyage AI | ✔ | Gemini | ✔ |
たとえば、OpenAIのtext-embedding-ada-002モデル (opens new window)は、その堅牢なパフォーマンスで知られています。以下のSQLコマンドを使用して、MyScaleで利用することができます。
SELECT EmbedText('YOUR_TEXT', 'OpenAI', '', 'API_KEY', '{"model":"text-embedding-ada-002"}')
Jina AIのjina-embeddings-v2-base-enモデル (opens new window)は、最大8kのシーケンス長をサポートし、コスト効果の高いコンパクトな埋め込み次元の代替手段を提供しています。このモデルの使用方法は次のとおりです。
SELECT EmbedText('YOUR_TEXT', 'Jina', '', 'API_KEY', '{"model":"jina-embeddings-v2-base-en"}')
注意:
このモデルは現在、英語のテキストに限定されています。
Amazon Bedrock Titan (opens new window)は、OpenAIモデルと互換性があり、AWSの統合およびセキュリティ機能に優れており、次のコードスニペットに示すように、AWSユーザーに包括的なソリューションを提供します。
SELECT EmbedText('YOUR_TEXT', 'Bedrock', '', 'SECRET_ACCESS_KEY', '{"model":"amazon.titan-embed-text-v1", "region_name":"us-east-1", "access_key_id":"ACCESS_KEY_ID"}')
# 専用の関数の作成
利便性のために、各プロバイダに専用の関数を作成することができます。たとえば、OpenAIのtext-embedding-ada-002モデルを使用する次の関数を定義できます。
CREATE FUNCTION OpenAIEmbedText ON CLUSTER '{cluster}'
AS (x) -> EmbedText(x, 'OpenAI', '', 'API_KEY', '{"model":"text-embedding-ada-002"}')
次に、OpenAIEmbedText関数を次のように簡略化できます。
SELECT OpenAIEmbedText('YOUR_TEXT')
この方法により、埋め込みプロセスが簡素化され、APIキーなどの共通のパラメータの繰り返し入力が減少します。
# EmbedTextによるベクトル処理
EmbedTextは、ベクトル検索やデータ変換において、MyScaleでのベクトル処理を革新します。この関数は、検索クエリやデータベースの列を数値ベクトルに変換する重要なステップであり、ベクトル検索やデータ管理において不可欠です。
# ベクトル検索の向上
ベクトルの類似性検索では、従来のアプローチではユーザーがSQLでクエリベクトルを手動で入力する必要があります(ベクトル検索ガイド (opens new window)に詳細が記載されています)。次のコードスニペットに示すように、EmbedTextを使用することで、ベクトル検索プロセスが簡素化され、直感的になり、ユーザーエクスペリエンスが大幅に向上し、ベクトルの作成方法ではなくクエリの形成に焦点が当てられます。
SELECT id, distance(vector, [0.123, 0.234, ...]) AS dist
FROM test_embedding ORDER BY dist LIMIT 10
次のコードスニペットに示すように、EmbedTextを使用することで、ベクトル検索プロセスが簡素化され、直感的になり、ユーザーエクスペリエンスが大幅に向上し、ベクトルの作成方法ではなくクエリの形成に焦点が当てられます。
SELECT id, distance(vector, OpenAIEmbedText('the text query')) AS dist
FROM test_embedding ORDER BY dist LIMIT 10
# バッチ変換の効率化
この図に基づくと、バッチ変換の典型的なワークフローは、テキストデータを前処理し、構造化された形式で保存することを含みます。
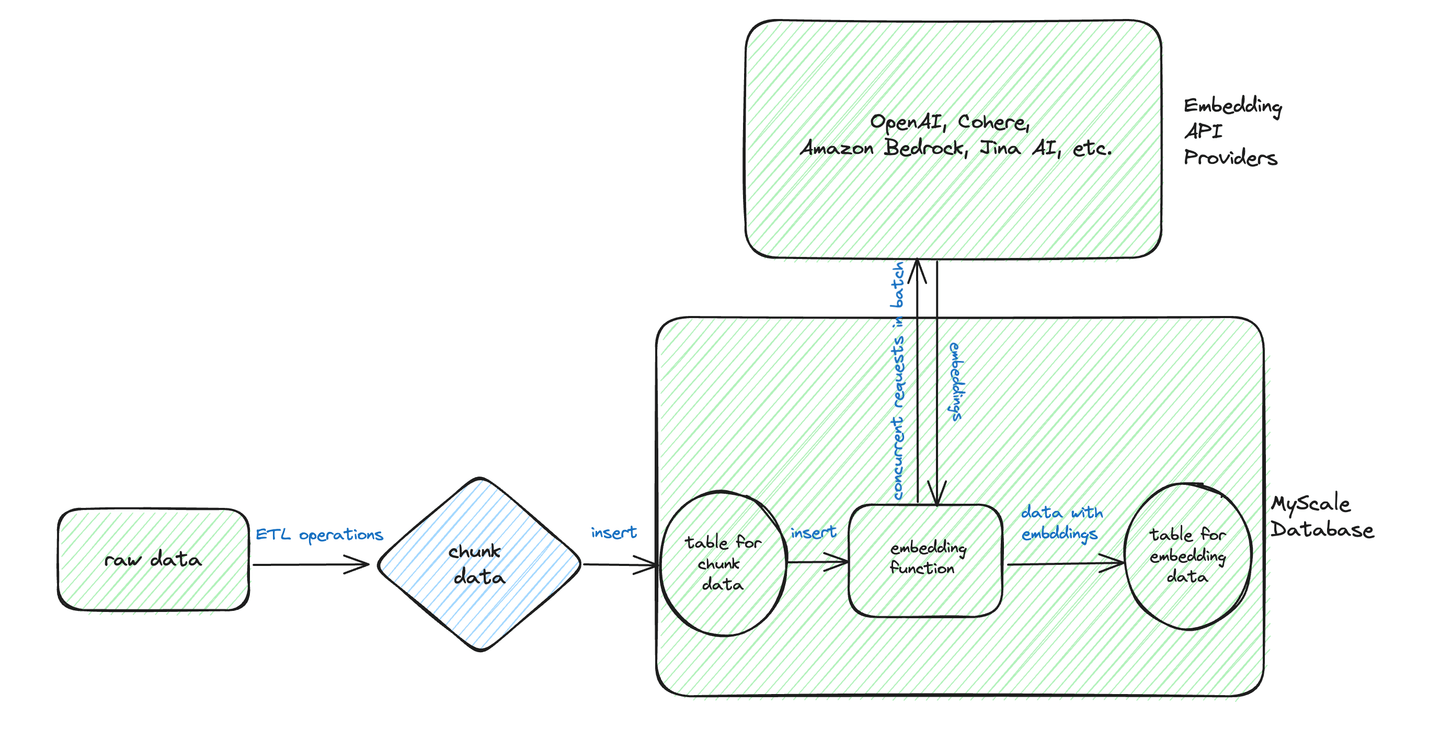
次のような生データを含むchunk_dataテーブルがあるとします。
CREATE TABLE chunk_data
(
id UInt32,
chunk String,
) ENGINE = MergeTree ORDER BY id
INSERT INTO chunk_data VALUES (1, 'chunk1'), (2, 'chunk2'), ...
次に、EmbedText関数を使用して作成されたベクトル埋め込みを保存するための2番目のテーブルであるtest_embeddingテーブルを作成します。
CREATE TABLE test_embedding
(
id UInt32,
paragraph String,
vector Array(Float32) DEFAULT OpenAIEmbedText(paragraph),
CONSTRAINT check_length CHECK length(vector) = 1536,
) ENGINE = MergeTree ORDER BY id
データをtest_embeddingに挿入することは簡単です。
INSERT INTO test_embedding (id, paragraph) SELECT id, chunk FROM chunk_data
または、挿入時に明示的にEmbedTextを適用することもできます。
INSERT INTO test_embedding (id, paragraph, vector) SELECT id, chunk, OpenAIEmbedText(chunk) FROM chunk_data
上記のように、EmbedTextには、複数のテキストを処理する際の効率性を大幅に向上させる自動バッチ処理機能が含まれています。この機能により、データを埋め込みAPIに送信する前に、内部でバッチ処理が管理され、効率的なデータ処理ワークフローが確保されます。NVIDIA A10G GPU上でのBAAI/bge-small-enモデル (opens new window)による効率性の例として、最大1200リクエスト/秒を達成しています。

# 結論
MyScaleのEmbedText関数は、複雑なプロセスを簡素化し、高度なベクトル検索とデータ変換を民主化する、実用的で効率的なテキストベクトル化ツールです。私たちのビジョンは、このイノベーションを日常のデータベース操作にシームレスに統合し、AI/LLM関連のデータ処理において幅広いユーザーに力を与えることです。



