
GPT-4、Gemini 1.5、Claude 3などの強力な大規模言語モデル(LLM)の台頭は、AIとテクノロジーにおいてゲームチェンジャーとなりました。これらのモデルのいくつかは100万トークン以上 (opens new window)を処理できる能力を持ち、長い文脈を扱う能力は本当に印象的です。しかし、以下の理由から、LLM単体では効果的に処理するには多くのデータ構造が複雑すぎて絶えず進化しており、コンテキストウィンドウ内での大規模で異種のエンタープライズデータの管理は単純に実用的ではありません。
検索支援生成(RAG)はこれらの問題に対処するのに役立ちますが、検索の精度はエンドツーエンドのパフォーマンスのボトルネックとなり、多くのベクトルデータベースは複雑なユースケースにはスケーリングしづらいです。LLMとビッグデータを高度なSQLベクトルデータベースを介して統合することは、LLMをより効果的にするだけでなく、人々がビッグデータからより良いインテリジェンスを得ることを可能にします。さらに、モデルの幻想を減らしながらデータの透明性と信頼性を提供します。
# ベクトルデータベースの現状
RAGシステムの基盤であるベクトルデータベースは、過去1年間で急速に発展してきました。一般的には、次の3つのタイプに分類されます:専用のベクトルデータベース、キーワードとベクトル検索システム、SQLベクトルデータベース。それぞれに利点と制限があります。
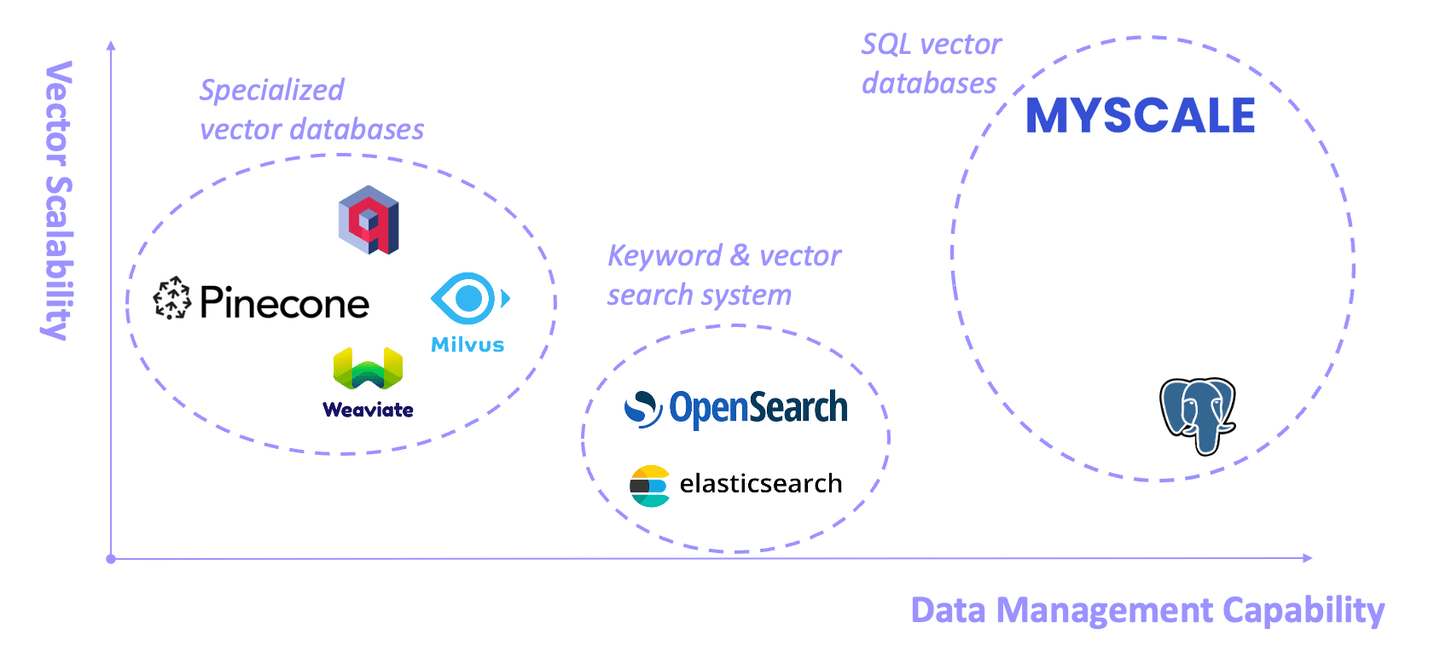
# 専用のベクトルデータベース
Pinecone、Weaviate、Milvusなどの一部のベクトルデータベースは、ベクトル検索を専門に設計されています。この領域でのパフォーマンスは良好ですが、一般的なデータ管理機能にはやや制限があります (opens new window)。
# キーワードとベクトル検索システム
ElasticsearchやOpenSearchなどを代表とするこれらのシステムは、包括的なキーワードベースの検索機能を持つため、実稼働環境で広く使用されています。しかし、これらのシステムはシステムリソースを多く消費し、キーワードとベクトルのハイブリッドクエリの精度とパフォーマンスはしばしば満足のいくものではありません (opens new window)。
# SQLベクトルデータベース
SQLベクトルデータベース (opens new window)は、従来のSQLデータベースの機能とベクトルデータベースの機能を組み合わせた特殊なタイプのデータベースです。SQLの助けを借りて、高次元ベクトルの効率的な格納とクエリが可能です。
上記の図には、2つの主要なSQLベクトルデータベースが示されています:pgvectorとMyScaleDBです。pgvectorはPostgreSQLのベクトル検索プラグインです。初めて使用するのが簡単で、小規模なデータセットの管理に便利です。ただし、Postgresの行ストレージの欠点とベクトルアルゴリズムの制限により、pgvectorは大規模で複雑なベクトルクエリに対して精度とパフォーマンスが低下する傾向があります。
MyScaleDB (opens new window)は、ClickHouse(カラムストアSQLデータベース)上に構築されたオープンソースのSQLベクトルデータベースです。GenAIアプリケーションの高性能かつ費用効果の高いデータ基盤を提供するように設計されています。MyScaleDBはまた、専門のベクトルデータベースを上回るパフォーマンスとコスト効率性 (opens new window)を実現した最初のSQLベクトルデータベースです。

出典: https://myscale.github.io/benchmark (opens new window)
# SQLとベクトルの結合データモデリングの力
NoSQLやビッグデータ技術の登場にもかかわらず、SQLデータベースはSQLの創始から半世紀後もデータ管理市場を席巻し続けています。ElasticsearchやSparkなどのシステムでもSQLインターフェースが追加されています。SQLをサポートするMyScaleDBというSQLベクトルデータベースは、ベクトル検索と分析の高パフォーマンス (opens new window)を実現します。
実世界のAIアプリケーションでは、SQLとベクトルを統合することでデータモデリングの柔軟性が向上し、開発が簡素化されます。たとえば、大規模な学術製品では、MyScaleDBを使用して大量の科学文献データに対するインテリジェントなQ&Aを行っています。主要なSQLスキーマには、ベクトルとキーワードベースの逆インデックス構造を持つテーブルが10以上含まれており、主キーと外部キーで接続されています。システムは、構造化データ、ベクトルデータ、キーワードデータを含む複雑なクエリや複数のテーブルをまたがる結合クエリを処理します。これは、専門のベクトルデータベースにとっては難しいタスクであり、しばしば反復が遅く、クエリが効率的でなく、メンテナンスコストが高くなります。
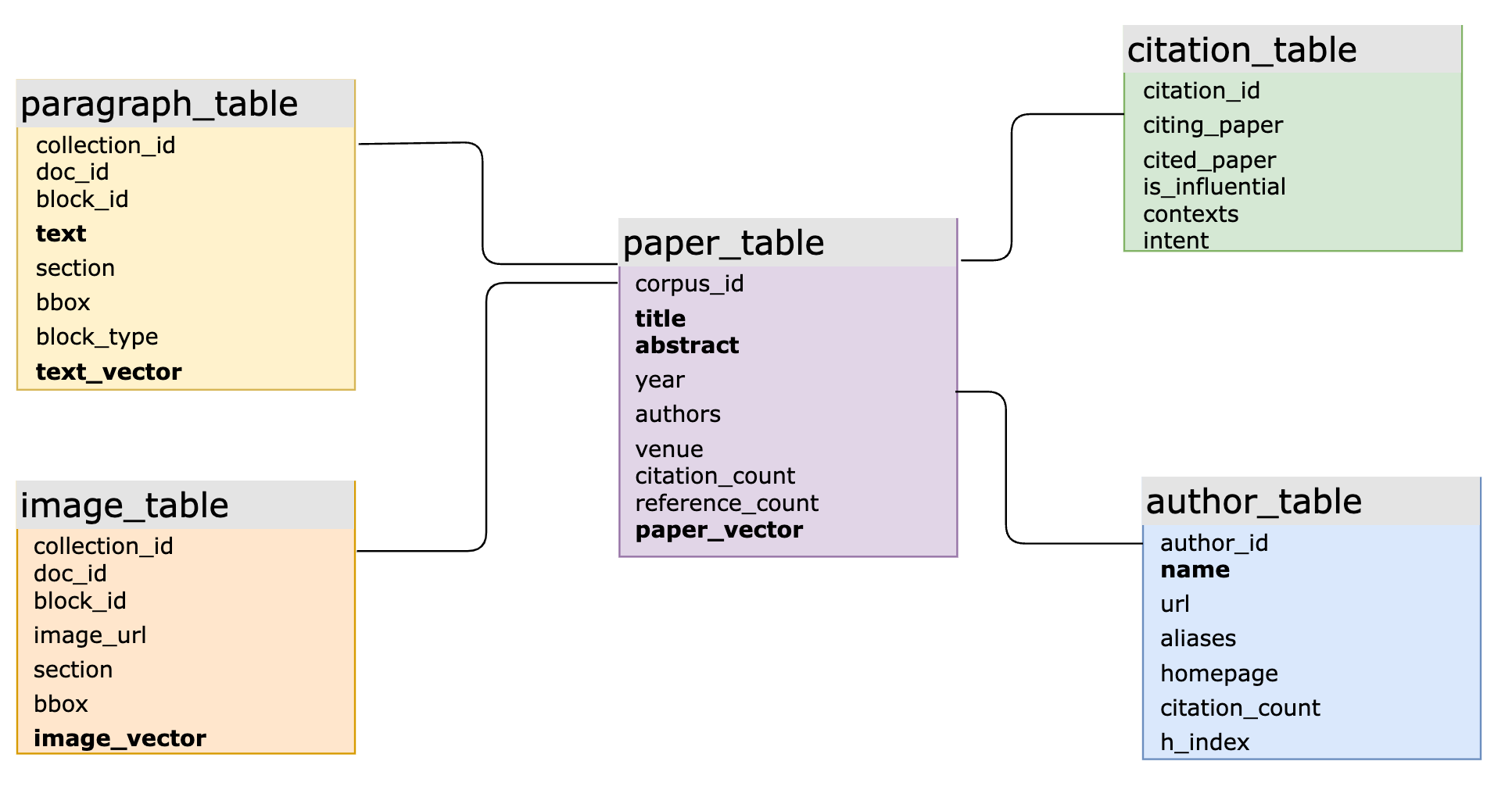
MyScaleによってサポートされる大規模な学術製品の主要なSQLベクトルデータベーススキーマ(太字の列には関連するベクトルインデックスまたは逆インデックスがあります)
# RAGの精度とコスト効率の向上
実世界のRAGシステムでは、検索の精度(および関連するパフォーマンスのボトルネック)を克服するために、構造化データ、ベクトルデータ、キーワードデータのクエリを効率的に組み合わせる方法が必要です。
たとえば、金融アプリケーションでは、ユーザーがドキュメントデータベースに対して「2023年の<会社名>の収益はグローバルでいくらでしたか?」というクエリを行った場合、"<会社名>"や"2023"といった構造化メタデータは、意味的なベクトルにはキャプチャされず、連続したテキストにも存在しません。データベース全体でのベクトル検索はノイズの多い結果をもたらし、最終的な精度を低下させます。
しかし、会社名や年などの情報は、しばしばドキュメントのメタデータとして取得できます。ベクトルクエリのフィルタリング条件として「WHERE year=2023 AND company LIKE "%<会社名>%"」を使用することで、関連する情報を正確に特定することができ、システムの信頼性を大幅に向上させることができます。金融、製造、研究などの分野では、SQLベクトルデータモデリングと結合クエリによって、精度が60%から90%に向上することが観察されています。
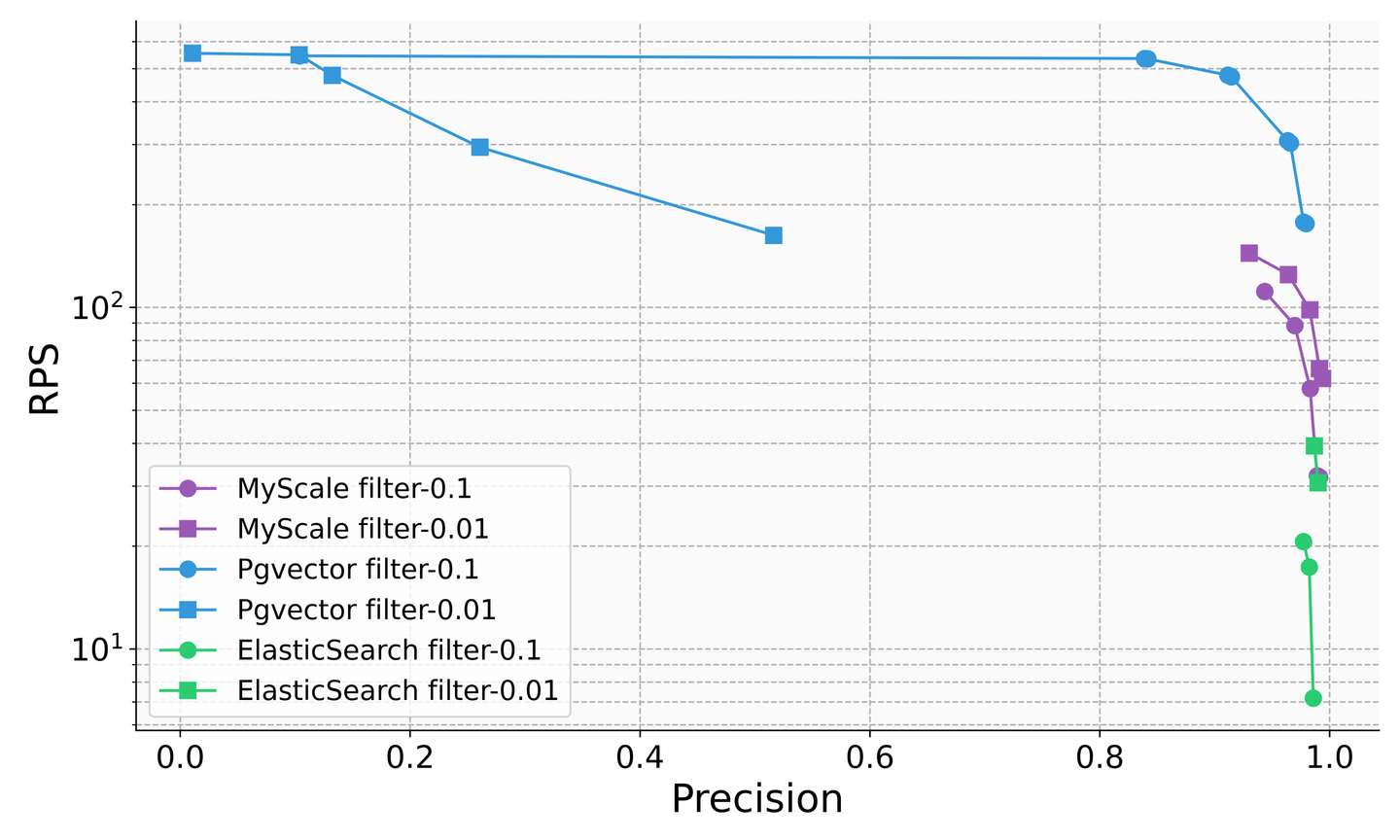
従来のデータベース製品は、LLM時代におけるベクトルクエリの重要性を認識し、ベクトルの機能を追加し始めていますが、結合クエリの精度にはまだ重大な問題があります。たとえば、フィルタ検索のシナリオでは、Elasticsearchのクエリ数(QPS)は、フィルタリング比率が0.1の場合に約5に低下し、pgvectorプラグインを備えたPostgreSQLは、フィルタリング比率が0.01の場合に約50%の精度しかありません。これは、不安定なクエリの精度とパフォーマンスであり、使用の制約が非常に大きいことを示しています。対照的に、SQLベクトルデータベースのMyScaleは、さまざまなフィルタリング比率のシナリオで100以上のQPSと98%の精度を実現し、pgvectorのコストの36%、Elasticsearchのコストの12%で利用できます。

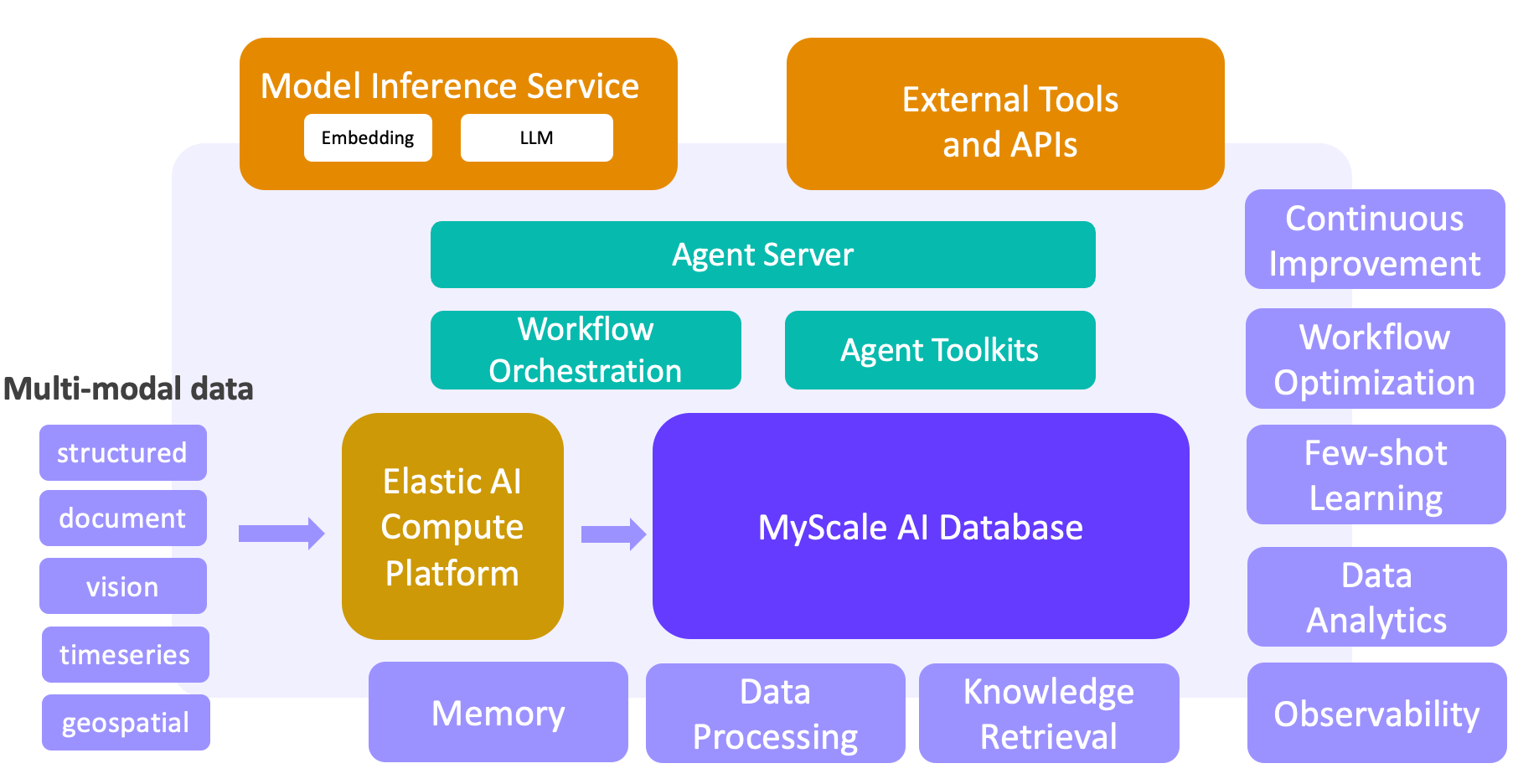
# LLM + ビッグデータ:次世代のエージェントプラットフォームの構築
機械学習とビッグデータは、Webやモバイルアプリの成功を支えてきました。しかし、LLMの台頭により、私たちはLLM + ビッグデータソリューションの新しい世代を構築する方向に舵を切っています。高性能なSQLベクトルデータベースであるMyScaleDBを活用したこれらのソリューションは、大規模データ処理、知識検索、観測性、データ分析、フューショット学習などの重要な機能を解き放ちます。MyScaleDBを基盤としたデータとAIのクローズドループが作成され、次世代のLLM + ビッグデータエージェントプラットフォームの基盤となります。このパラダイムシフトは、科学研究、金融、産業、医療などの分野で既に進行中です。
技術の急速な発展に伴い、人工汎用知能(AGI)の形態が今後5〜10年以内に出現することが予想されています。この問題については、静的な仮想モデルが必要なのか、より包括的な解決策が必要なのかを考える必要があります。データは、間違いなくLLM、ユーザー、世界をつなぐ重要なリンクです。私たちのビジョンは、LLMとビッグデータを有機的に統合し、より専門的でリアルタイムかつ協調的なAIシステムを作り出すことです。それはまた、人間の温かさと価値に満ちたものです。
イノベーティブで本格的なAIアプリケーションを構築するために、GitHub (opens new window)でオープンソースのMyScaleDBリポジトリを探索し、SQLとベクトルを活用してください。



