
大規模言語モデル(LLM)は、さまざまな質問に答えることができる高度なAIシステムです。彼らは知っているトピックに関して情報を提供しますが、未知のトピックについては常に正確ではありません。この現象は幻覚として知られています。
![]()
# 幻覚とは何ですか?
LLMの幻覚の例を見る前に、Wikipedia.com (opens new window)で説明されている「幻覚」という用語の定義を考えてみましょう。
「幻覚とは、外部の刺激がない状態での、実在の知覚の特性を持つ知覚です。」
さらに:
「幻覚は鮮明で実体的であり、外部の客観的な空間に存在すると知覚されます。」
つまり、幻覚とは、何か実在または具体的なものに対する誤った知覚または虚構です。例えば、有名な大規模言語モデルであるChatGPTにLLMの幻覚について尋ねたところ、次のような回答がありました:

したがって、疑問が浮かびます。この結果を改善するにはどうすればよいのでしょうか?簡潔な答えは、質問の前後にLLMの定義などの事実を追加することです。
例えば:
LLMは大規模言語モデルであり、人間の話し方や書き方をモデル化した人工ニューラルネットワークです。LLMの幻覚とは何ですか、教えてください。
この質問に対するChatGPTによるパブリックドメインの回答は次のとおりです:

注意:
最初の文「以前の回答での混乱をお詫び申し上げます」というのは、最初の質問「LLMの幻覚とは何ですか」をChatGPTに尋ねた後に、2番目のプロンプト「LLMは...」を与えたためです。
これらの追加により、回答の品質が向上しました。少なくとも、LLMがLLMの幻覚を「Late-Life Migraine Accompaniment(後期の片頭痛の伴奏)」と思わなくなりました 😆
# 外部の知識が幻覚を軽減する
この時点で非常に重要なことは、LLMが全知全能ではなく、すべての知識の究極の権威ではないということです。LLMは大量のデータでトレーニングされ、言語のパターンを学習しますが、常に最新の情報にアクセスできるわけではなく、複雑なトピックについて包括的な理解を持っているわけでもありません。
では、どうすればLLMの幻覚を軽減する可能性を高めることができるのでしょうか?
この問題の解決策は、LLMがより正確で情報豊かな回答に向かうように、クエリ(またはプロンプト)にサポートドキュメントを含めることです。人間と同様に、LLMはこれらのドキュメントから学習して、正確かつ正確に質問に答える必要があります。
役立つドキュメントは、GoogleやBingなどの検索エンジンやArxivなどのデジタルライブラリなど、さまざまなソースから取得できます。データベースを使用することも良い選択肢であり、より柔軟でプライベートなクエリインターフェースを提供します。
ソースから取得した知識は、質問/プロンプトに関連する必要があります。キーワードベースの検索、つまりテキスト内のキーワードの検索(用語の完全一致に適しています)、ベクトル検索ベースの検索、つまり埋め込みに近いレコードの検索(適切な言い換えや一般的なドキュメントの検索に役立ちます)など、さまざまな方法で関連するドキュメントを取得することができます。
最近では、ベクトル検索が人気です。なぜなら、それらは言い換えの問題を解決し、段落の意味を計算することができるからです。ベクトル検索は一つのサイズがすべての解決策ではありません。特に大量のレコードを検索する場合は、パフォーマンスを維持するために特定のフィルタと組み合わせる必要があります。たとえば、物理学に関する知識のみを取得したい場合、他の科目の情報をすべてフィルタリングする必要があります。これにより、LLMは他の学問の知識に混乱することはありません。
# SQLとベクトル検索でプロセス全体を自動化する
LLMは、質問に答える前にデータソースからデータをクエリする方法を学ぶ必要があります。これにより、プロセス全体を自動化することができます。実際、LLMは既にSQLクエリを作成し、指示に従うことができます。
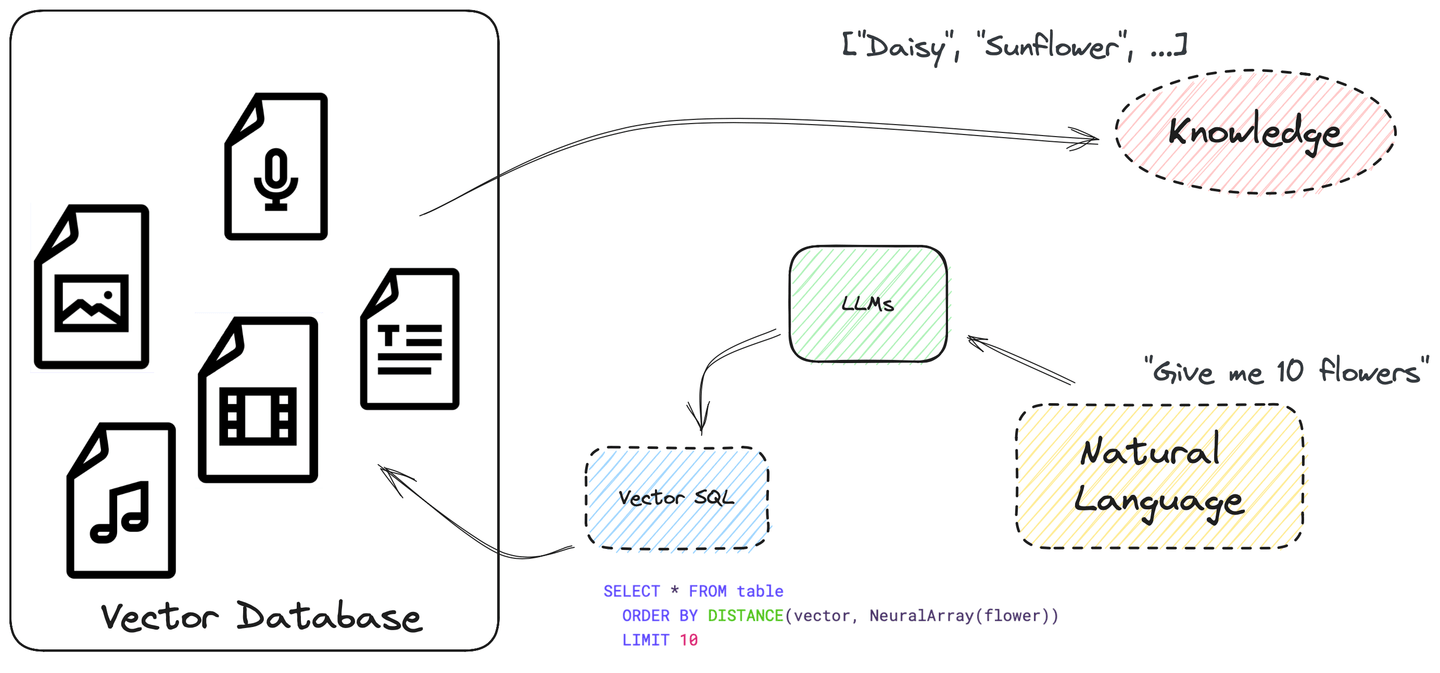
SQLは強力で、複雑な検索クエリを構築するために使用することができます。さまざまなデータ型と関数をサポートしています。また、ORDER BYとLIMITを使用して、埋め込み間の類似度スコアをdistanceという列として扱い、SQLでベクトル検索を記述することもできます。非常にシンプルですね。
ベクトルSQLの構造についての詳細は、次のセクション「ベクトルSQLの見た目」を参照してください。
ベクトルSQLを使用して複雑な検索クエリを構築することには、次のような重要な利点があります:
- データ型と関数のサポートの柔軟性が向上します
- SQLは高度に最適化されており、データベース内で実行されるため、効率が向上します
- 標準SQLの拡張であるため、人間が読みやすく学びやすいです
- LLMにとっても使いやすいです
注意:
インターネット上には多くのSQLの例やチュートリアルがあります。LLMは標準SQLおよびその方言の一部にも精通しています。
MyScale以外にも、ClickhouseやPostgreSQLなどの多くのSQLデータベースソリューションが既存の機能にベクトル検索を追加しており、ユーザーはベクトルSQLとLLMを使用して複雑なトピックに関する質問に答えることができます。同様に、増えているアプリケーション開発者もSQLとベクトル検索を統合し始めています。
# ベクトルSQLの見た目
ベクトル構造化クエリ言語(Vector SQL)は、LLMにベクトルSQLデータベースのクエリ方法を教えるために設計されており、次の追加関数を含んでいます:
DISTANCE(column, query_vector): この関数は、ベクトルの列とクエリベクトルの間の距離を正確または近似的に比較します。NeuralArray(entity): この関数は、エンティティ(例: 画像やテキスト)を埋め込みに変換します。
これらの2つの関数を使用することで、ベクトル検索のための標準SQLを拡張することができます。たとえば、単語「flower」に関連する10件のレコードを検索したい場合、次のSQL文を使用できます:
SELECT * FROM table
ORDER BY DISTANCE(vector, NeuralArray(flower))
LIMIT 10
DISTANCE関数は以下のように構成されています:
- 内部関数である
NeuralArray(flower)は、単語flowerを埋め込みに変換します。 - この埋め込みはシリアライズされ、
DISTANCE関数に注入されます。
Vector SQLは、使用されるベクトルデータベースに基づいてさらなる翻訳が必要なSQLの拡張バージョンです。たとえば、多くの実装ではDISTANCE関数に異なる名前が付けられています。MyScaleではdistanceと呼ばれ、ClickhouseではL2DistanceまたはCosineDistanceと呼ばれます。また、データベースによっては、この関数名が異なるように翻訳されます。
# LLMにVector SQLの書き方を教える方法
ベクトルSQLの基本原則とその固有の関数を理解したので、LLMを使用してベクトルSQLクエリを書くのを支援しましょう。
# 1. LLMに標準のVector SQLを教える
まず、LLMに標準のVector SQLを教える必要があります。LLMがベクトルSQLクエリを書く際に、以下の3つのことを自発的に行うようにすることを目指します:
- 質問/プロンプトからキーワードを抽出します。オブジェクト、概念、またはトピックなどが該当します。
- 類似性検索を実行するために使用する列を決定します。類似性のために常にベクトル列を選択する必要があります。
- 質問の制約を有効なSQLに変換します。
# 2. LLMのプロンプトを設計する
LLMがベクトルSQLクエリを構築するために必要な情報を正確に把握した後、次のようにプロンプトを設計できます:
# ベクトルSQLのプロンプトの例です
_prompt = f"""あなたはMyScaleの専門家です。入力された質問に対して、まず構文的に正しいMyScaleクエリを作成し、クエリの結果を確認して入力された質問の回答を返します。
MyScaleクエリには、ユーザーの質問の関連性を計算し、特徴配列の列を関連性に基づいてソートするためのベクトル距離関数`DISTANCE(column, array)`があります。
クエリが{top_k}個の最も近い行を要求している場合、この距離関数を使用してベクトル列上のエンティティの配列との距離を計算し、距離に基づいて関連する行を取得する必要があります。
*注意*: `DISTANCE(column, array)`は、最初の引数として配列列を、第二引数として`NeuralArray(entity)`を受け入れます。また、エンティティの配列を取得するために`NeuralArray(entity)`というユーザー定義関数が必要です。
質問で明示的に例の数を指定しない限り、MyScaleのLIMIT句を使用して最大{top_k}件の結果をクエリしてください。距離関数に基づいてのみ順序付けを行ってください。
テーブルからすべての列をクエリしないでください。質問に答えるために必要な列のみをクエリしてください。各列名を二重引用符(")で囲んで区別された識別子として示してください。
テーブルスキーマのコメントに注意してください。
以下の形式を使用してください:
======== テーブル情報 ========
<いくつかのテーブル情報>
質問: "ここに質問"
SQLクエリ: "実行するSQLクエリ"
さあ始めましょう:
======== テーブル情報 ========
{table_info}
質問: {input}
SQLクエリ:
このプロンプトは役立つはずです。ただし、できるだけ多くの例を追加するほど、ベクトルSQLクエリを正しく構築するLLMのプロセスが改善されます。
最後に、プロンプトを設計する際のいくつかの追加のヒントを紹介します:
- 質問される可能性のあるすべての関数を網羅してください。
- 単調な質問を避けてください。
- テーブルスキーマを変更してください(名前やデータ型の追加/削除/変更など)。
- プロンプトの形式を整えてください。

# 実際の例:MyScaleの使用
次に、以下の手順で実際の例 (opens new window)を構築しましょう。

# データベースの準備
クエリを実行できる準備が整った、200万以上の論文が含まれるプレイグラウンドを用意しました。以下のPythonコードをアプリに追加することで、このデータにアクセスできます。
from sqlalchemy import create_engine
MYSCALE_HOST = "msc-950b9f1f.us-east-1.aws.myscale.com"
MYSCALE_PORT = 443
MYSCALE_USER = "chatdata"
MYSCALE_PASSWORD = "myscale_rocks"
engine = create_engine(f'clickhouse://{MYSCALE_USER}:{MYSCALE_PASSWORD}@{MYSCALE_HOST}:{MYSCALE_PORT}/default?protocol=https')
もしよければ、以下のステップをスキップして、MyScaleコンソールを使用してテーブルを作成し、データを挿入する部分にジャンプし、ベクトルSQLを試したり、データベースをクエリするためのSQLDatabaseChain を作成する部分に進むことができます。
データベーステーブルの作成:
CREATE TABLE default.ChatArXiv (
`abstract` String,
`id` String,
`vector` Array(Float32),
`metadata` Object('JSON'),
`pubdate` DateTime,
`title` String,
`categories` Array(String),
`authors` Array(String),
`comment` String,
`primary_category` String,
CONSTRAINT vec_len CHECK length(vector) = 768)
ENGINE = ReplacingMergeTree ORDER BY id SETTINGS index_granularity = 8192
データの挿入:
INSERT INTO ChatArXiv
SELECT
abstract, id, vector, metadata,
parseDateTimeBestEffort(JSONExtractString(toJSONString(metadata), 'pubdate')) AS pubdate,
JSONExtractString(toJSONString(metadata), 'title') AS title,
arrayMap(x->trim(BOTH '"' FROM x), JSONExtractArrayRaw(toJSONString(metadata), 'categories')) AS categories,
arrayMap(x->trim(BOTH '"' FROM x), JSONExtractArrayRaw(toJSONString(metadata), 'authors')) AS authors,
JSONExtractString(toJSONString(metadata), 'comment') AS comment,
JSONExtractString(toJSONString(metadata), 'primary_category') AS primary_category
FROM
s3(
'https://myscale-demo.s3.ap-southeast-1.amazonaws.com/chat_arxiv/data.part*.zst',
'JSONEachRow',
'abstract String, id String, vector Array(Float32), metadata Object(''JSON'')',
'zstd'
);
ALTER TABLE ChatArXiv ADD VECTOR INDEX vec_idx vector TYPE MSTG('metric_type=Cosine');
# VectorSQLDatabaseChainの作成
VectorSQLDatabaseChainには、LangChainの実験的なパッケージが必要です。以下のインストールスクリプトを実行することで、それをインストールできます。
python3 -m venv .venv
source .venv/bin/activate
pip3 install langchain langchain-experimental --upgrade
Once you have installed this feature, the next step is to use it to query the database, as the following Python code demonstrates:
from sqlalchemy import create_engine
MYSCALE_HOST = "msc-950b9f1f.us-east-1.aws.myscale.com"
MYSCALE_PORT = 443
MYSCALE_USER = "chatdata"
MYSCALE_PASSWORD = "myscale_rocks"
# create connection to database
engine = create_engine(f'clickhouse://{MYSCALE_USER}:{MYSCALE_PASSWORD}@{MYSCALE_HOST}:{MYSCALE_PORT}/default?protocol=https')
from langchain.embeddings import HuggingFaceInstructEmbeddings
from langchain.callbacks import StdOutCallbackHandler
from langchain.llms import OpenAI
from langchain.utilities.sql_database import SQLDatabase
from langchain_experimental.sql.prompt import MYSCALE_PROMPT
from langchain_experimental.sql.vector_sql import VectorSQLDatabaseChain
from langchain_experimental.sql.vector_sql import VectorSQLRetrieveAllOutputParser
# this parser converts `NeuralArray()` into embeddings
output_parser = VectorSQLRetrieveAllOutputParser(
model=HuggingFaceInstructEmbeddings(model_name='hkunlp/instructor-xl')
)
# use the prompt above
PROMPT = PromptTemplate(
input_variables=["input", "table_info", "top_k"],
template=_prompt,
)
# bind the metadata to SqlAlchemy engine
metadata = MetaData(bind=engine)
# create SQLDatabaseChain
query_chain = VectorSQLDatabaseChain.from_llm(
# GPT-3.5 generates valid SQL better
llm=OpenAI(openai_api_key=OPENAI_API_KEY, temperature=0),
# use the predefined prompt, change it to your own prompt
prompt=PROMPT,
# returns top 10 relevant documents
top_k=10,
# use result directly from DB
return_direct=True,
# use our database for retreival
db=SQLDatabase(engine, None, metadata),
# convert `NeuralArray()` into embeddings
sql_cmd_parser=output_parser)
# launch the chain!! And trace all chain calls in standard output
query_chain.run("Introduce some papers that uses Generative Adversarial Networks published around 2019.",
callbacks=[StdOutCallbackHandler()])
# RetrievalQAwithSourcesChainを使用して質問する
このVectorSQLDatabaseChainは、Retrieverとしても使用することができます。LangChainの他のRetrieverと同様に、いくつかの検索QAチェーンにプラグインすることができます。
from langchain_experimental.retrievers.vector_sql_database \
import VectorSQLDatabaseChainRetriever
from langchain.chains.qa_with_sources.map_reduce_prompt import combine_prompt_template
OPENAI_API_KEY = "sk-***"
# データベースからの構造化データをどのようにシリアライズするかを定義します
document_with_metadata_prompt = PromptTemplate(
input_variables=["page_content", "id", "title", "authors", "pubdate", "categories"],
template="Content:\n\tTitle: {title}\n\tAbstract: {page_content}\n\t" +
"Authors: {authors}\n\tDate of Publication: {pubdate}\n\tCategories: {categories}\nSOURCE: {id}"
)
# LLMに尋ねるためのプロンプトを定義します
COMBINE_PROMPT = PromptTemplate(
template=combine_prompt_template, input_variables=["summaries", "question"])
# SQLDatabaseChainを使用したRetrieverを定義します
retriever = VectorSQLDatabaseChainRetriever(
sql_db_chain=query_chain, page_content_key="abstract")
# 最後に、これらすべてを組織するaskチェーンを定義します
ask_chain = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(model_name='gpt-3.5-turbo-16k',
openai_api_key=OPENAI_API_KEY, temperature=0.6),
retriever=retriever,
chain_type='stuff',
chain_type_kwargs={
'prompt': COMBINE_PROMPT,
'document_prompt': document_with_metadata_prompt,
}, return_source_documents=True)
# チェーンを実行し、LLMから結果を取得します
ask_chain("2019年頃に発表された、Generative Adversarial Networksを使用した論文を紹介してください。",
callbacks=[StdOutCallbackHandler()])
また、huggingface (opens new window)でライブデモを提供しており、コードはGitHub (opens new window)で利用可能です!私たちはカスタマイズされたRetrieval QAチェーン (opens new window)を使用して、LangChainとの検索と質問のパフォーマンスを最大化しました!
# まとめ
実際のところ、ほとんどのLLMは幻想を見せます。その外見を減らすための最も実用的な方法は、質問に追加の事実(外部知識)を追加することです。外部知識は、LLMシステムのパフォーマンスを向上させるために重要であり、効率的かつ正確な回答の検索を可能にします。すべての単語が重要であり、不正確なクエリによって取得される未使用の情報にお金を無駄にすることは避けたいです。
どうすればいいのでしょうか?
それがVector SQLの登場です。必要な情報をターゲットにして取得するために、細かく精緻なベクトル検索を実行することができます。
Vector SQLは、人間と機械の両方にとって強力で学習しやすいです。多くのデータ型や関数を使用して複雑なクエリを作成することができます。LLMもVector SQLが好きです。なぜなら、トレーニングデータセットには多くの参照が含まれているからです。
最後に、さまざまな埋め込みモデルを使用してVector SQLを多くのベクトルデータベースに変換することも可能です。私たちはそれがベクトルデータベースの未来だと考えています。
私たちの取り組みに興味がありますか?今すぐdiscord (opens new window)に参加してください!



