
Retrieval-Augmented Generation (RAG) (opens new window)システムは、大規模言語モデル(LLM)の応答品質を向上させるために設計されました。ユーザーがクエリを送信すると、RAGシステムはベクトルデータベースから関連情報を抽出し、それをコンテキストとしてLLMに渡します。LLMはこのコンテキストを使用してユーザーのために応答を生成します。このプロセスにより、LLMの応答の品質が向上し、「幻覚」 (opens new window)が少なくなります。
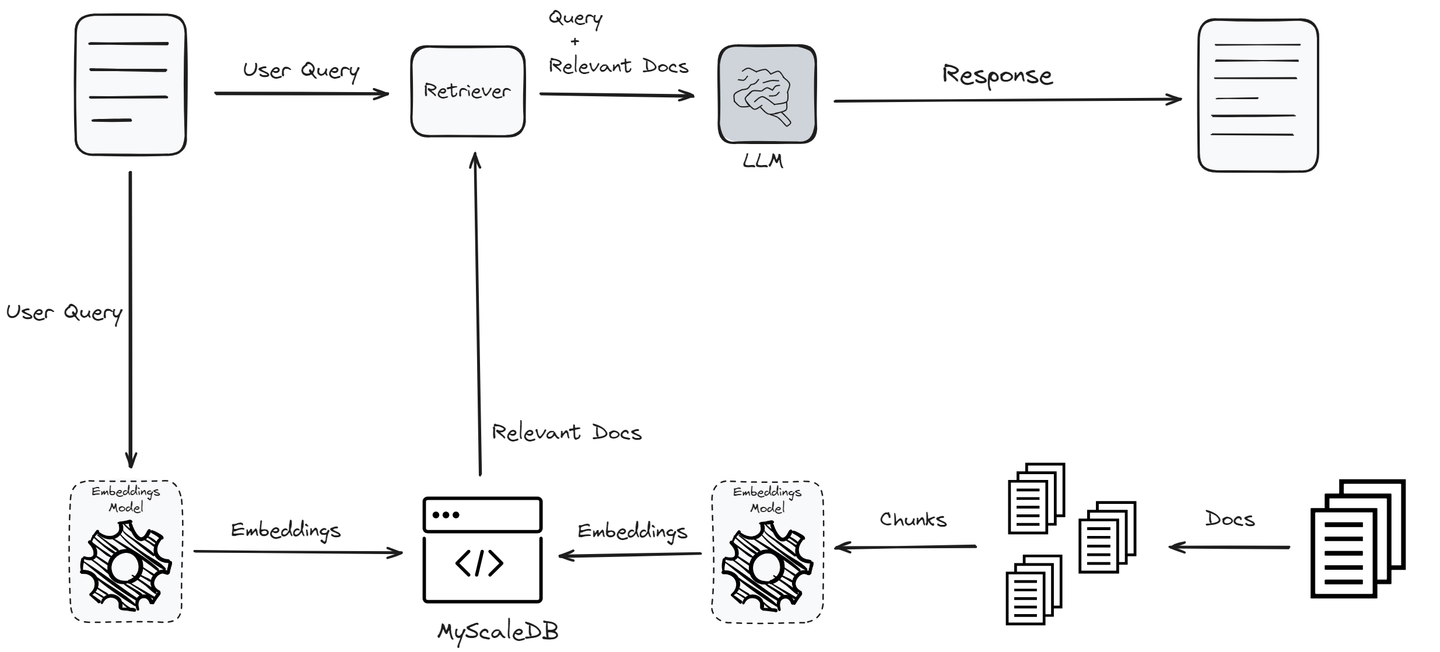
したがって、上記のワークフローでは、RAGシステムには2つの主要なコンポーネントがあります:
リトリーバー:類似検索の力を使って、ベクトルデータベースから最も関連性の高い情報を特定します。このステージは、最終的な出力の品質の基盤を築くため、どのRAGシステムにおいても最も重要な部分です。リトリーバーは、ユーザーのクエリに関連するドキュメントを検索するためにベクトルデータベースを検索します。クエリとドキュメントをベクトルにエンコードし、類似度の尺度を使用して最も近いマッチを見つけることが含まれます。
応答生成器:関連するドキュメントが取得されると、ユーザーのクエリと取得されたドキュメントはLLMモデルに渡され、一貫性のある、関連性の高い、情報豊富な応答が生成されます。ジェネレータ(LLM)は、リトリーバーによって提供されるコンテキストと元のクエリを使用して正確な応答を生成します。
RAGシステムの効果とパフォーマンスは、これら2つのコアコンポーネント、リトリーバーとジェネレータに大きく依存しています。リトリーバーは効率的に最も関連性の高いドキュメントを特定し、取得する必要があります。一方、ジェネレータは、取得した情報を使用して一貫性のある、関連性の高い、正確な応答を生成する必要があります。これらのコンポーネントの厳格な評価は、RAGモデルの展開前に最適なパフォーマンスと信頼性を確保するために重要です。
# RAGの評価
RAGシステムを評価するために、一般的に2種類の評価方法を使用します:
- リトリーバーの評価
- 応答の評価
伝統的な機械学習技術とは異なり、RAGシステムの評価はより複雑です。これは、RAGシステムによって生成される応答が構造化されていないテキストであるためであり、そのパフォーマンスを正確に評価するためには質的および量的な指標の組み合わせが必要です。
# TRIADフレームワーク
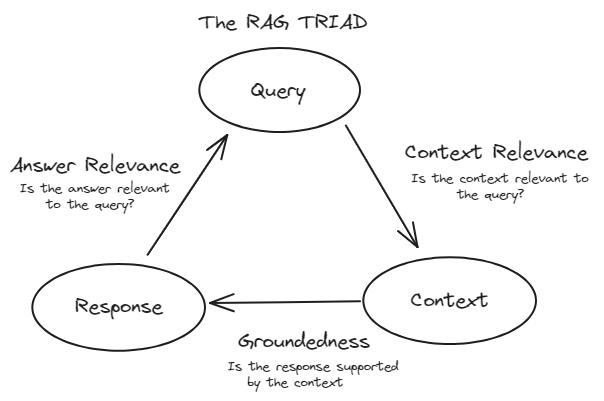
RAGシステムを効果的に評価するために、一般的にTRIADフレームワークに従います。このフレームワークは3つの主要なコンポーネントで構成されています:
コンテキストの関連性:これはRAGシステムのリトリーバー部分を評価します。大規模データセットからドキュメントが正確に取得されたかどうかを評価します。ここでは、精度、再現率、MRR、MAPなどの指標が使用されます。
信頼性(基盤性):これは応答の評価に属します。生成された応答が事実に基づいて正確であるかどうかを確認します。人間の評価、自動ファクトチェックツール、一貫性チェックなどの方法を使用して信頼性を評価します。
回答の関連性:これも応答の評価の一部です。生成された応答がユーザーのクエリに適切に対応し、有用な情報を提供するかどうかを測定します。BLEU、ROUGE、METEOR、埋め込みベースの評価などの指標が使用されます。
# リトリーバーの評価
リトリーバーの評価は、通常ベクトルデータベースを使用するRAGシステムのリトリーバーコンポーネントに適用されます。これらの評価は、リトリーバーがユーザーのクエリに対して関連性の高いドキュメントを効果的に特定し、ランク付けするかどうかを測定します。リトリーバーの評価の主な目的は、コンテキストの関連性、つまり取得されたドキュメントがユーザーのクエリと適合しているかどうかを評価することです。これにより、ジェネレーションコンポーネントに提供されるコンテキストが適切で正確であることが保証されます。

各指標は、取得されたドキュメントの品質について独自の視点を提供し、コンテキストの関連性について包括的な理解に貢献します。
# 精度
精度は、取得されたドキュメントの正確さを測定します。これは、取得された関連ドキュメントの数を取得されたドキュメントの総数で割った比率です。以下のように定義されます:
これは、システムによって取得されたドキュメントのうち、実際にユーザーのクエリに関連するものがいくつあるかを評価します。例えば、リトリーバーが10のドキュメントを取得し、そのうち7が関連している場合、精度は**0.7または70%**になります。
精度は、「システムが取得したドキュメントのうち、実際に関連するものはいくつありましたか?」と評価します。
精度は、関連しない情報を提供することがネガティブな結果をもたらす場合に特に重要です。たとえば、医療情報検索システムでは、関連しない医療文書を提供することが誤情報や潜在的な有害な結果につながる可能性があるため、高い精度が重要です。
# 再現率
再現率は、取得されたドキュメントの包括性を測定します。これは、与えられたクエリに対してデータベース内の関連ドキュメントの総数を取得された関連ドキュメントの数で割った比率です。以下のように定義されます:
これは、データベース内に存在する関連ドキュメントのうち、システムが正常に取得したドキュメントの数を評価します。
再現率は、「データベース内に存在する関連ドキュメントのうち、システムがいくつ取得できましたか?」と評価します。
関連情報を見逃すことがコストのかかる状況では、再現率が重要です。たとえば、法的情報検索システムでは、関連する法的文書を取得できないと、不完全なケース研究になり、法的手続きの結果に影響を与える可能性があります。
# 精度と再現率のバランス
精度と再現率のバランスを取ることはしばしば必要です。一方を改善すると他方が低下することがあるためです。目標は、特定のアプリケーションの特定のニーズに適した最適なバランスを見つけることです。このバランスは、精度と再現率の調和平均であるF1スコアを使用して定量化されることがあります:
# 平均逆順位(MRR)
平均逆順位(MRR)は、検索システムの効果を評価する指標であり、最初の関連ドキュメントのランク位置を考慮します。最初の関連ドキュメントが見つかるランクの逆数を逆順位と呼びます。MRRは、複数のクエリにわたるこれらの逆順位の平均です。MRRの式は次のとおりです:
ここで、Qはクエリの数であり、
MRRは、「平均して、ユーザークエリに対する最初の関連ドキュメントがどれくらい速く取得されるか?」と評価します。
たとえば、RAGベースの質問応答システムでは、MRRが重要です。なぜなら、正しい回答がより頻繁に上位に表示される場合、MRRの値が高くなり、より効果的な検索システムを示すからです。
# 平均適合率(MAP)
平均適合率(MAP)は、複数のクエリにわたる検索の適合率を評価する指標です。検索の適合率と取得されたドキュメントの順位の両方を考慮に入れます。MAPは、一連のクエリに対する平均適合率スコアの平均です。単一のクエリの平均適合率を計算するには、取得されたドキュメントのランク付けリストの各位置で適合率を計算し、上位Kの取得されたドキュメントのみを考慮して、各適合率を重み付けします。複数のクエリにわたるMAPの式は次のとおりです:
ここで、Qはクエリの数であり、
MAPは、「平均して、システムが複数のクエリに対して上位ランクのドキュメントをどれくらい正確に取得しているか?」と評価します。
たとえば、RAGベースの検索エンジンでは、MAPが重要です。なぜなら、検索の適合率を異なるランクで評価することで、関連ドキュメントが検索結果の上位に表示され、ユーザーエクスペリエンスが向上するからです。
# リトリーバーの評価の概要
- 精度:取得結果の品質。
- 再現率:取得結果の完全性。
- MRR:最初の関連ドキュメントがどれくらい速く取得されるか。
- MAP:適合するドキュメントの精度と順位を包括的に評価。
# 応答の評価
応答の評価は、システムの生成コンポーネントに適用されます。これらの評価は、取得されたドキュメントによって提供されるコンテキストに基づいてシステムがどれだけ効果的に応答を生成するかを測定します。応答の評価は、次の2つのタイプに分けられます:
- 信頼性(基盤性)
- 回答の関連性
# 信頼性(基盤性)
信頼性は、生成された応答が正確で取得されたドキュメントに基づいているかどうかを評価します。これにより、応答が幻覚や不正確な情報を含まないことが保証されます。この指標は重要であり、生成された応答をその出典に追跡し、情報が検証可能な真実に基づいていることを確認します。信頼性は、システムが見かけ上は正しく聞こえるが事実に反する応答を生成する「幻覚」を防ぐのに役立ちます。
信頼性を測定するためには、次の方法が一般的に使用されます:
- 人間の評価:専門家が生成された応答が事実に基づいており、取得されたドキュメントから正確に参照されているかどうかを手動で評価します。このプロセスでは、各応答をソースドキュメントと照らし合わせて、すべての主張が裏付けられていることを確認します。
- 自動ファクトチェックツール:これらのツールは、生成された応答を検証済みの事実のデータベースと比較して、不正確さを特定します。これにより、人間の介入なしで情報の妥当性を確認することができます。
- 一貫性チェック:このチェックでは、モデルが異なるクエリに対して一貫して同じ事実情報を提供するかどうかを評価します。これにより、モデルが信頼性があり、矛盾した情報を生成しないことが保証されます。
# 回答の関連性
回答の関連性は、生成された応答がユーザーのクエリに適切に対応し、有用な情報を提供するかどうかを測定します。
# BLEU(バイリンガル評価アンダースタディ)
BLEUは、生成された応答と参照応答の一連の重複部分を測定し、n-gramの精度に焦点を当てた指標です。BLEUスコアは、生成された応答と参照応答のn-gram(連続するn個の単語)の重複を測定することによって計算されます。BLEUスコアの式は次のとおりです:
ここで、BPは短い応答にペナルティを与えるための簡潔さペナルティ、
# ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
ROUGEは、生成された応答と参照応答のn-gram、単語シーケンス、単語ペアの重複を測定し、再現率と精度の両方を考慮に入れます。最も一般的なバリアントであるROUGE-Nは、生成された応答と参照応答のn-gramの重複を測定します。ROUGE-Nの式は次のとおりです:
ROUGEは、適合率と再現率の両方を評価し、参照からの関連するコンテンツの量をバランスよく評価する指標です。
# METEOR(Metric for Evaluation of Translation with Explicit ORdering)
METEORは、生成された応答と参照応答の類似性を評価するために、同義語、語幹、単語の順序を考慮します。METEORスコアの式は次のとおりです:
ここで、
# 埋め込みベースの評価
この方法では、単語のベクトル表現(埋め込み)を使用して、生成された応答と参照応答の意味的類似性を測定します。コサイン類似度などの技術を使用して埋め込みを比較し、単語の正確な一致ではなく意味に基づいた評価を提供します。

# RAGシステムの最適化のためのヒントとトリック
RAGシステムを最適化するために使用できるいくつかの基本的なヒントとトリックがあります:
- 再ランキングの技術の使用:再ランキングは、どのRAGシステムのパフォーマンスを最適化するために最も広く使用されている技術です。初期の取得ドキュメントセットを取り、類似性に基づいて最も関連性の高いものをさらにランク付けします。クロスエンコーダやBERTベースの再ランカーなどの技術を使用して、より正確なドキュメントの関連性を評価することができます。これにより、コンテキストが豊かで関連性の高いドキュメントがジェネレータに提供され、より良い応答が生成されます。
- ハイパーパラメータの調整:チャンクサイズ、オーバーラップ、トップ取得ドキュメントの数などのハイパーパラメータを定期的に調整することで、リトリーバーコンポーネントのパフォーマンスを最適化することができます。異なる設定で実験し、リトリーバル品質に与える影響を評価することで、RAGシステム全体のパフォーマンスを向上させることができます。
- 埋め込みモデル:適切な埋め込みモデルを選択することは、RAGシステムのリトリーバーコンポーネントの最適化に重要です。一般的な用途向けのモデルやドメイン固有のモデルなど、特定のユースケースに合わせた適切なモデルを選択することで、類似検索の精度を向上させ、RAGシステム全体のパフォーマンスを向上させることができます。モデルのトレーニングデータ、次元数、パフォーマンスメトリックなどの要素を考慮して選択することが重要です。
- チャンキング戦略:チャンクサイズとオーバーラップをカスタマイズすることで、RAGシステムのパフォーマンスを大幅に向上させることができます。これにより、LLMのためのより関連性の高い情報がキャプチャされます。たとえば、Langchainのセマンティックチャンキングは、文脈的に整合性のあるチャンクに基づいてドキュメントを分割します。PDF、テーブル、画像などのドキュメントタイプに基づいて変化する適応的なチャンキング戦略は、文脈に適した情報を保持するのに役立ちます。
# ベクトルデータベースの役割
ベクトルデータベースは、RAGシステムのパフォーマンスにおいて重要な役割を果たしています。ユーザーがクエリを送信すると、RAGシステムのリトリーバーコンポーネントはベクトルデータベースを活用してベクトルの類似性に基づいて最も関連性の高いドキュメントを見つけます。このプロセスは、正確で関連性の高い応答を生成するために言語モデルに適切なコンテキストを提供するために重要です。堅牢なベクトルデータベースは、高速かつ正確な検索を保証し、RAGシステムの全体的な効果と応答性に直接影響を与えます。
MyScaleDB (opens new window)は、高性能なClickHouse (opens new window)データベース上に構築されたSQLベクトルデータベースです。ClickHouseは、列指向ストレージやベクトル化されたクエリの実行などの高度なデータ処理機能を提供します。MyScaleのMulti-Scale Tree Graph (MSTG) (opens new window)アルゴリズムは、他のインデックスメソッドよりも優れた性能を発揮し、LAION 5Mデータセットで390 QPS(クエリ数/秒)、95%の再現率を達成し、s1.x1ポッドでの平均クエリ待ち時間を18msに維持しています。このユニークなアルゴリズムは、階層的なツリークラスタリングとグラフトラバーサルの技術を組み合わせることで、インデックス化と検索の効率を向上させます。MSTGは、従来のHNSW(Hierarchical Navigable Small World)やIVF(Inverted File)などの方法と比較して、リソースの使用を削減し、検索操作を高速化します。さらに、MyScaleDBはSQLとベクトルの結合クエリに対する互換性があり、既存のワークフローに簡単に統合することができます。
# 結論
RAGシステムの開発自体は困難ではありませんが、RAGシステムの評価は、パフォーマンスの測定、継続的な改善、ビジネス目標との整合、コストのバランス、信頼性の確保、新しい手法への適応に不可欠です。この包括的な評価プロセスにより、堅牢で効率的でユーザーセントリックなRAGシステムを構築することができます。
これらの重要な側面に対処することで、ベクトルデータベースは高性能なRAGシステムの基盤となり、正確で関連性の高いタイムリーな応答を提供すると同時に、大規模で複雑なデータを効率的に管理します。MyScaleDBは、独自のMSTGアルゴリズム、SQLとベクトルの結合クエリを備えており、RAGシステムのパフォーマンスを大幅に向上させることができます。MyScaleDBは、LAION 5Mデータセットで390 QPS(クエリ数/秒)、95%の再現率を達成し、s1.x1ポッドでの平均クエリ待ち時間を18msに維持しています。このユニークなアルゴリズムは、階層的なツリークラスタリングとグラフトラバーサルの技術を組み合わせることで、インデックス化と検索の効率を向上させます。また、MyScaleDBはSQLとの互換性があり、既存のワークフローに簡単に統合することができます。



