
テキスト検索は一般的ですが、画像を使用して画像を検索 (opens new window)する場面もよくあります。例えば、似た写真を見つけたり、写真から製品を特定したりする場合です。このアプローチは、画像ベースの検索 (opens new window)または逆画像検索として知られ、オンラインショッピング(気に入ったものの写真を撮って購入先を見つける)、未知の植物やランドマークの識別など、さまざまな応用があります。私たちの視覚データが増えるにつれて、この分野はますます重要になっています。
明らかに、これは直接的なテキストクエリを持っていないため、困難です。代わりに、効果的に比較できる形式で画像を表現する方法が必要です。ここで、埋め込み (opens new window)が重要な役割を果たします。画像を高次元空間の数値ベクトルに変換することで、埋め込みは画像の特徴に基づいて画像の類似性を測定することができます。
このブログでは、いくつかの手法について説明します。埋め込みモデルが画像検索でどのように使用され、それらの背後にあるアルゴリズムを調査し、類似した画像を見つける方法を見ていきます。画像検索を実装したい開発者や、その仕組みに興味がある方にとって、この記事はいくつかのヒントを提供するでしょう。
# 古典的な手法
ディープラーニング (opens new window)の時代においても、検索エンジンで似た画像特徴を見つけるという概念は、ディープラーニング技術の広範な採用よりも前から存在していました。2009年には、Google Imagesが似た画像機能を組み込みました (opens new window)。その後間もなく、コンテンツベースの画像検索(CBIR) (opens new window)システムが導入されました。これにより、最新のディープラーニングモデルに依存せずにこれらの画像検索を可能にした手法はどのようなものだったのでしょうか?
# SIFT
**スケール不変特徴変換(SIFT) (opens new window)**は、ディープラーニングアーキテクチャが普及する前に、非常に効率的で使いやすいアルゴリズムでした。SIFTは、スケーリング、回転、一部のアフィン変形や照明変化に対して不変な画像の興味深いポイントを特定します。これらのキーポイントを検出した後、SIFTは各ポイント周りの局所的な勾配情報を分析して特徴記述子を計算します。これらの記述子は通常、画像の局所的な構造を効果的に捉える128次元ベクトルです。これらは、画像のマッチングや検索など、さまざまなアプリケーションで埋め込みとして使用できます。
SIFTには批判もあります。小さな画像に対して効率が低く、多くのメモリを使用します(数千のキーポイントの128次元ベクトルを想像してください)、照明に敏感です。さらに、2020年に特許が取得されたため、他の手法と比べてコミュニティでの人気はあまりありませんでした。
# SURF
SIFTの計算量の批判に対処するために、**高速ロバスト特徴(SURF) (opens new window)**が高速な代替手法として導入されました。SURFは、計算速度を向上させるために、一次の画像導関数(勾配)ではなく、二次の近似導関数(ヘッシアン行列)を使用します。SURFによって生成される特徴記述子は通常、64次元ベクトルまたは拡張版では128次元ベクトルであり、画像検索タスクの埋め込み表現に適しています。
これらに加えて、方向勾配ヒストグラム(HOG)、**Oriented FAST and Rotated BRIEF(ORB)**などの他の手法もあります。
# 実装
SIFTとSURFは、OpenCV (opens new window)パッケージを使用して簡単に実装できます。OpenCV(4.4.0以降)には、SIFT_create()関数が用意されており、SIFTオブジェクトを初期化するために使用できます。これらのオブジェクトは、グレースケールイメージからキーポイントとその記述子(埋め込みベクトル)を検出および計算するためにさらに使用できます。
import cv
image = cv2.imread('AdventureKKH/15.jpg')
grayScaleImage = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
sift = cv2.SIFT_create()
keypoints, descriptors = sift.detectAndCompute(grayScaleImage, None)
画像には多くのキーポイントが存在する場合があります。見つかったら、単純にそれらを描画することができます。
import matplotlib.pyplot as plt
image_with_keypoints = cv2.drawKeypoints(image, keypoints, None)
plt.imshow(cv2.cvtColor(image_with_keypoints, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.show()

ご覧の通り、これらのキーポイントは非常に多く(正確には6433個)ありますが、画像との対比が低いため、ほとんどのキーポイントは識別できません。より良い代替手法として、flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTSを設定して、少し見やすくすることができます。

特徴(descriptors)もDataFrameを使用してより良い方法で視覚化することができます。ご覧の通り、SIFTポイント(keypoints)ごとに行があり、各ポイントの特徴は128次元です。
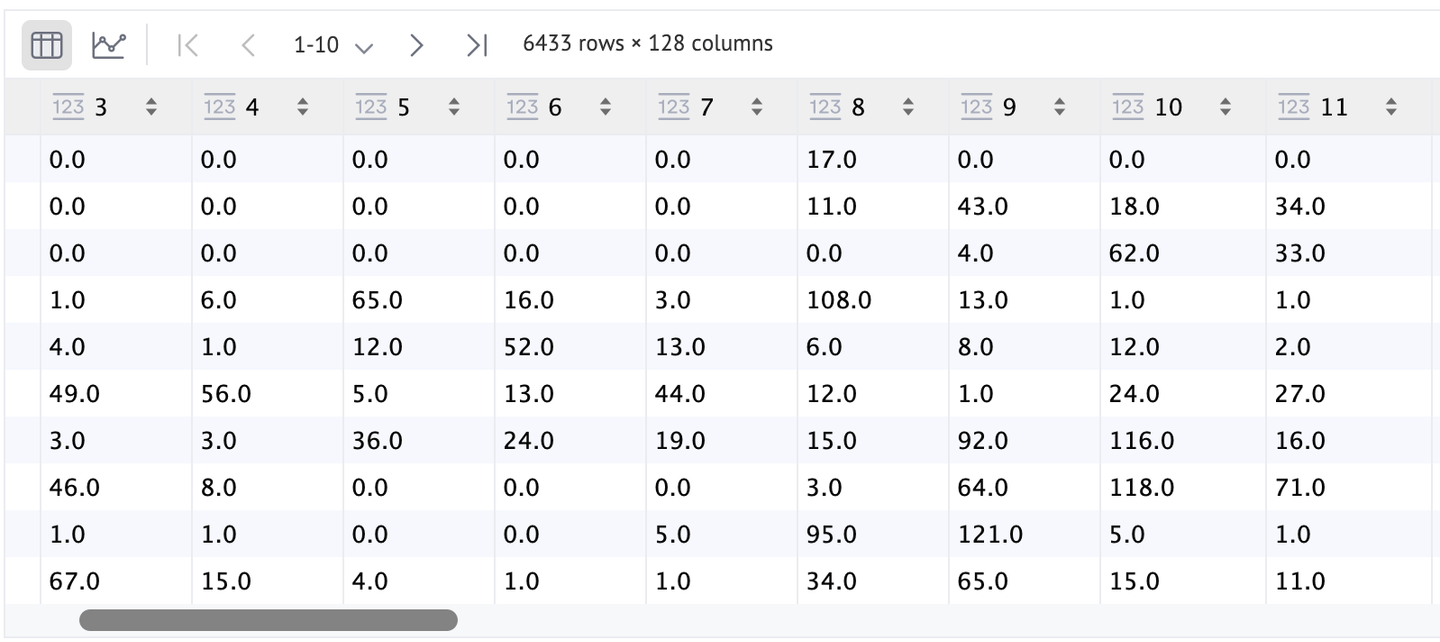
SURFは特許されているアルゴリズムなので、OpenCVから直接使用することは許可されていません。では、より一般的なディープアーキテクチャベースのモデルに焦点を当てましょう。
# ディープアーキテクチャベースの埋め込み
SIFTやSURFのような従来の手法は、画像から局所的な特徴を抽出することに焦点を当てていますが、ディープラーニングモデルは画像表現により強力なアプローチを提供します。これらのモデルはデータから階層的な特徴を学習し、手作業で特定するのが難しい複雑なパターンや構造を捉えることができます。この進歩により、より堅牢で識別力のある埋め込みが可能となり、画像検索や検索などのタスクが向上します。
VGG、ResNets、Inception、MobileNetなど、いくつかの事前学習済みモデルがあります。これらの畳み込みニューラルネットワーク(CNN)はImageNetなどの大規模なデータセットでトレーニングされており、画像から豊富で多様な特徴を抽出することができます。従来のアルゴリズムとは異なり、ディープラーニングモデルはエッジやテクスチャなどの低レベルの特徴だけでなく、オブジェクトやシーンなどの高レベルの概念も捉えることができます。
これらのモデルを使用して埋め込みを計算することは比較的簡単です。事前学習済みモデルを使用し、最終分類層の出力ではなく、通常は分類層の直前の層 (opens new window)から出力を抽出します。この出力は、数値形式で画像を効果的に表現する埋め込みとして機能する高次元の特徴ベクトルです。
例えば、人気のあるディープラーニングモデルであるResNet-50を使用して、与えられたimageの埋め込みを取得することができます。ResNet-50は、より深いネットワークの効果的なトレーニングを支援する残差接続で知られています。最後の層を削除することで、与えられたimageの埋め込みを取得できます。
import torch
import torchvision.models as models
model = models.resnet50(pretrained=True)
model = torch.nn.Sequential(*(list(model.children())[:-1]))
with torch.no_grad():
embedding = model(image.unsqueeze(0))
# ViTベースの埋め込み
CNNは画像処理タスクの標準でしたが、**Vision Transformers(ViT)**は、トランスフォーマーアーキテクチャを画像データに適用することで異なるアプローチを提供します。ViTは画像をパッチのシーケンスとして扱い、自然言語処理のシーケンスをトランスフォーマーが処理する方法と似た方法で処理します。この方法により、モデルは画像内のグローバルな関係をより効果的に捉えることができます。
ViTとCNNの間のアーキテクチャの違いにより、ViTからの埋め込みは、トランスフォーマーエンコーダの出力トークンを平均化することで抽出されます。便宜上、Hugging Faceを介して利用可能な事前学習済みのViTモデルを使用できます。
from transformers import ViTModel, ViTFeatureExtractor
import torch
model = ViTModel.from_pretrained('google/vit-base-patch16-224-in21k')
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224-in21k')
image = Image.open('AdventureKKH/15.jpg')
inputs = feature_extractor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
embedding = outputs.last_hidden_state.mean(dim=1)
print(embedding)
デフォルトのViTアーキテクチャ(元の論文[1]で使用されるアーキテクチャ)を使用しているため、埋め込みベクトルは768次元になります。もっと高い解像度が必要な場合は、ViT-LargeやViT-Huge(それぞれ1024と1280の長さ)に切り替えることができます。

# ファインチューニング
モデルのファインチューニングが必要な特殊な画像タイプで作業する場合、CNNまたはVision Transformer(ViT)を使用する場合は、通常、モデルの最終層以外をすべて凍結することが有益です。このアプローチにより、前の層の学習済みの特徴を変更せずに、最後の層のファインチューニングが可能になります。
ファインチューニングプロセスが完了したら、前の手順と同様に最後の層を削除することができます。変更されたモデルを使用して、画像を順方向に渡すことで、必要な埋め込みを生成することができます。この方法により、モデルは基本的な理解を保持しながら、特定の画像データのニュアンスに適応することができます。
# 自己教師ありの手法
自分の写真フォルダをチェックして、注釈を付け始めてみてください。50枚や100枚終わる頃には、明らかに疲れてしまうでしょう。ファインチューニングには多くのラベル付きデータが必要であり、それが簡単に利用できるわけでも、時間を費やす価値があるわけでもありません。そのため、自己教師あり学習を使用するのがより良い解決策です。自己教師あり学習には、次のようないくつかの手法があります。
SimCLRとMoCoは、入力画像とその埋め込みの2つのコピーを生成します。その後、基礎となるアーキテクチャ(通常はResNet)は、対比損失が最小になるようにトレーニングされます。
一方、CLIPは画像とそのテキストの説明の埋め込みを使用してモデルをトレーニングします。この手法は、その後も同様の手法がいくつか登場しているため、有名になりました。例としては、BEiT(BErt pre-training of image Transformers)、VisualBERT、ViLBERTなどがあります。
注意:CLIPについて詳しくは、CLIPによるゼロショット分類 (opens new window)のブログを読むことができます。
ここでは、Moco(v2)を使用して画像の埋め込みを計算します。
import torch
import torch.nn as nn
from torchvision import models
class MoCoResNet(nn.Module):
def __init__(self, base_encoder=models.resnet50, feature_dim=128):
super(MoCoResNet, self).__init__()
self.encoder_q = base_encoder(pretrained=False)
self.encoder_q.fc = nn.Identity() # Removing final layer
def forward(self, x):
return self.encoder_q(x)
model = MoCoResNet()
checkpoint = torch.load('/Users/talha/Downloads/moco_v2_800ep_pretrain.tar', map_location='mps', weights_only=True)
model.load_state_dict(checkpoint['state_dict'])
画像の埋め込みは、先ほどの事前学習済みの通常のCNNモデルと同様に計算することができます。
with torch.no_grad():
embedding = model(image.unsqueeze(0))
これも2048次元のベクトルを返します。

# アプリケーション
これらの画像の埋め込みは、いくつかの画像検索アプリケーションで非常に役立ちます。例えば:
- Eコマース:すでに述べたように、オンラインショッピングに非常に役立ちます。さまざまな方法で使用できます。また、CBIRの数多くの用途の1つです。
- 画像分類:これらの埋め込みを使用してCNNやViTをトレーニングすることもできます。
- 画像キャプション:テキストの埋め込みも使用すると、画像キャプションシステムを作成することができます。CLIPは非常に良い例です。
# 比較
各モデルの比較分析を提供すると良いでしょう。
| アルゴリズム | 速度 | 利点 | 欠点 |
|---|---|---|---|
| SIFT | 中程度 | 少ないデータでも動作可能 | スケーラブルではない、非DL手法のため遅い |
| SURF | 高速 | 高速 | 他の手法ほど堅牢ではない |
| 事前学習済みCNN | 高速 | 選択肢が多く、堅牢 | あまり特化していない |
| 事前学習済みViT | 中程度から高速 | 堅牢 | 特に目立った欠点はない |
| ファインチューニングモデル | 遅い(推論は高速ですが、トレーニングには多くの時間がかかる場合があります) | ターゲットデータに適応しやすく、最良の結果を得ることができる | 多くの注釈付き画像とトレーニングリソースが必要 |
| 自己教師ありモデル | トレーニングセットによるが通常は遅い | 注釈付き画像が不要で、かなり良い結果が得られる | トレーニングリソースが必要 |
# 結論
埋め込み手法は画像検索を変革し、前例のない速度と精度で視覚的なものを特定することができるようにしました。SIFTやSURFから始まり、ディープラーニングアーキテクチャまでの進化により、この変革が可能になりました。
画像の埋め込みの未来はさらにエキサイティングであり、テキスト、画像、音声データを組み合わせたマルチモーダルな埋め込み (opens new window)や、大規模なラベル付きデータに依存しない自己教師あり手法などのトレンドがあります。MyScale (opens new window)のようなデータベースを使用すると、SQLとベクトル検索を組み合わせることで、高度な画像検索 (opens new window)アプリケーションを簡単に構築できます。MyScaleは強力な画像の埋め込みとベクトルインデックスを通じて高速な検索をサポートし、画像検索の将来のイノベーションの堅固な基盤を提供します。
研究が進むにつれて、さらに高速で正確でスマートな画像検索機能が開発されることが予想されます。これらの進歩により、プラットフォーム全体でユーザーエクスペリエンスが向上し、オンラインでの視覚情報の利用方法が再定義されます。画像検索は、テキスト検索と同様に自然で効率的なものになります。



