
伝統的に、機械学習(ML) (opens new window)は大まかに分けて、教師あり学習と教師なし学習 (opens new window)の2つに分類されます。教師あり学習では、ラベル付きのデータを使用してモデルを訓練します。例えば、異なるオブジェクトの(ラベル付きの)画像を使用して画像分類器を訓練することがあります。
一方、教師なし学習では、ラベル付けは必要とせず、事前の情報なしでパターンを探索します。これは困難ですが、魅力的でもあります。大量のデータが利用可能であり(そして毎日新しいデータが生成されています)、データを取得することは常に簡単ですが、ラベル付けには多くの時間とお金がかかります。
私たちの周りにある膨大なデータを活用するために、自己教師あり学習という高度な学習戦略があります。自己教師あり学習では、ラベルがないデータを取り、教師あり学習を「模倣」します。
# 自己教師あり学習(SSL)
自己教師あり学習では、データを正例と負例のサンプルに分割します。これはバイナリ(教師あり)分類と同様です。対象となるオブジェクトを正の例とし、他のすべてのサンプルを負の例として扱います。
自己教師あり学習の方法は、共通の埋め込みを学習し、大まかに2つのタイプに分類できます。
- 対照的な方法
- 非対照的な方法
対照的な方法では、同じデータの異なるサンプル(例えば、同じ画像の異なるビュー)を取り、それらの類似度スコアを最大化し、他のサンプル/画像に対しては最小化しようとします。一方、非対照的な方法では、負のサンプルを考慮しません。BYOLやDINOなどの有名なSSLの方法は、非対照的な方法の良い例です。一方、SimCLRやMoCoは負の例も使用し、対照的な方法の良い例です。
# 対照的学習(CL)
対照的学習は、正のデータペア間の類似性を最大化し、負のペアに対しては最小化する表現を選択するという単純なコンセプトに基づいています。例えば、マンゴーの画像を入力し、その目標は、マンゴーの画像間の類似性を最大化し、他の画像に対しては最小化することです。
最も単純な設定では、各データポイント(考慮する場合)を正のデータポイントとして考え、他のすべてを負のポイントとして考えます。ポイントを
# 訓練
データポイントの各ペア
訓練をより実用的にするために、バッチで行い、例えば32枚の画像のバッチがある場合、1枚の画像(それ自体)は最大化された類似度スコアを持つ必要があり、他の31枚の画像はできるだけ最小化された類似度スコアを持つ必要があります。
ただし、単一の正の例と複数の負の例を持つことは、識別的な特徴を学習するのが非常に困難になるため、同じデータポイントの複数のコピーを作成するなど、データ拡張といったスマートな技術を使用します。
# CLの例
対照的学習は以前から存在しています。過去10年間で、それは通常のCNNベースの (opens new window)画像識別(SIFTを上回るだけで十分でした)からCLIPまで、長い道のりを歩んできました。いくつかの現代的なCLアルゴリズムは次のとおりです。
- 対照的予測符号化(CPC)
- 視覚表現の対照的学習のためのシンプルなフレームワーク(SimCLR)
- モメンタム対照法(MoCo)
- 対照的言語-画像事前学習(CLIP)
これらを簡単に説明して、対照的学習が実際にどのように使用されているかをより良く理解しましょう。
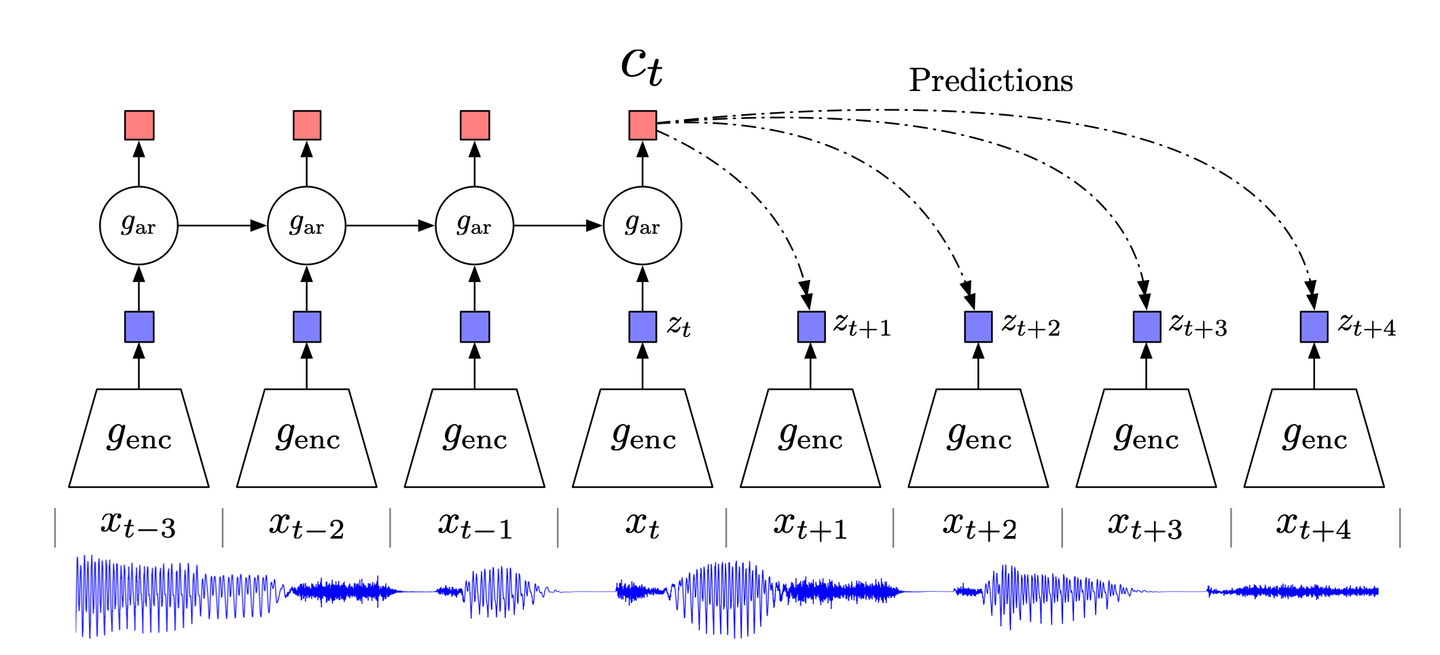
# 対照的予測符号化(CPC)
古典的なデータ圧縮技術である予測符号化とその神経科学への適応に触発され、CPC(対照的予測符号化) (opens new window)はデータの高レベルな情報に焦点を当て、低レベル/ノイズを無視することを試みます。
CPCは次のように機能します。
- 高次元データを適切な潜在埋め込み空間に圧縮します。この圧縮により、データのモデリングが容易になり、それに応じて予測が行われます。
- 選択した埋め込み空間で予測が行われます。
- モデルはノイズ対照的推定(NCE)損失関数を使用して訓練されます。
# SimCLR
コンピュータビジョンのための高度な対照的学習技術であるSimCLRは、事前拡張や特殊なアーキテクチャを必要としません。
- ランダムに画像を選択し、異なる拡張技術(ランダムクロッピング、ランダムな色の歪み、ガウシアンぼかし)を使用してそのビュー(元の実装では2つ)を生成します。
- ResNetベースのCNNを使用して画像の表現/埋め込みを計算します。
- この表現は、MLPを使用して(非線形の)射影にさらに変換されます。
- CNNとMLPの両方が対照的損失関数を最小化するように訓練されます。
これまで、教師なし学習の必要性について話してきましたが、利用可能なラベル付きデータもあります。最終的に、ラベル付きの画像でCNNを微調整すると、パフォーマンスが向上し、さまざまな(下流の)タスクでの汎化性能が向上します。
対照的学習の仕組みに関するいくつかの洞察
SimCLRは非常に良いパフォーマンスを持つ新しいモデルを紹介しただけでなく、その著者たちはほとんどの対照的学習方法にとって有用ないくつかの新しい洞察を提供しました。以下にそれらを共有する価値があると考えました。
複数の拡張技術の組み合わせが重要です: ランダムクロッピングと色の歪みは、個別に使用した場合には目立った結果を示しませんでしたが、併用すると最良の結果が得られます。
非線形射影は重要です: ニューラルネットワークと対照的損失関数の複雑な性質からは、裏で何が起こっているのかを理解するのは難しいですが、経験的には非線形射影(MLPによるもの)が有用であり、パフォーマンスを最大10%向上させることが明らかになっています。この事実は、MoCov2の論文でも独立して観察されます。
スケーリングアップはパフォーマンスを向上させます: いくつかの観察結果はSimCLRに特有のものですが、対照的学習全体に適用されるものです。モデルの容量を増やす(幅または深さ)、バッチサイズを増やす、エポック数を増やすなど、パフォーマンスが向上します。
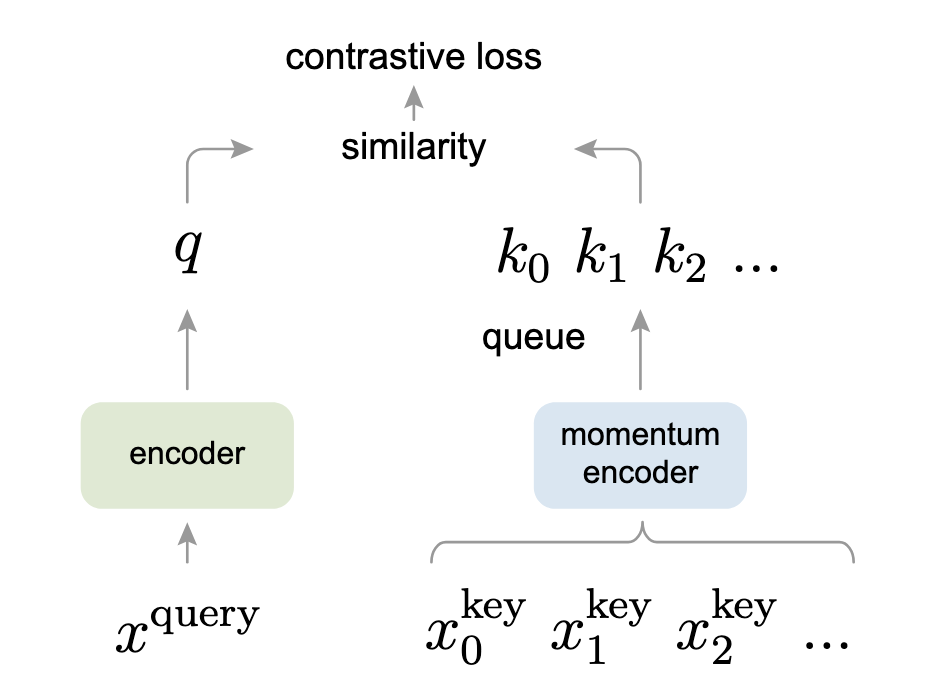
# モメンタム対照法(MoCo)
モメンタム対照法(MoCo)は、対照的学習を辞書の検索として捉える別の視点を持っています。この興味深い視点は、トランスフォーマーモデルといくつかの類似点があります。
- データ拡張は、2つのコピー
- クエリエンコーダ(画像の左側のエンコーダ)は
- モメンタムエンコーダは、他の拡張されたコピー
関連性を持たせるために、これはキューとして実装され、
- エンコードされたクエリ
- 両方のエンコーダは、この対照的損失を最小化するように共同で訓練されます。
もしトランスフォーマーに詳しい場合、InfoNCE損失はトランスフォーマーでのアテンションの計算方法にかなり似ていることがわかるでしょう。
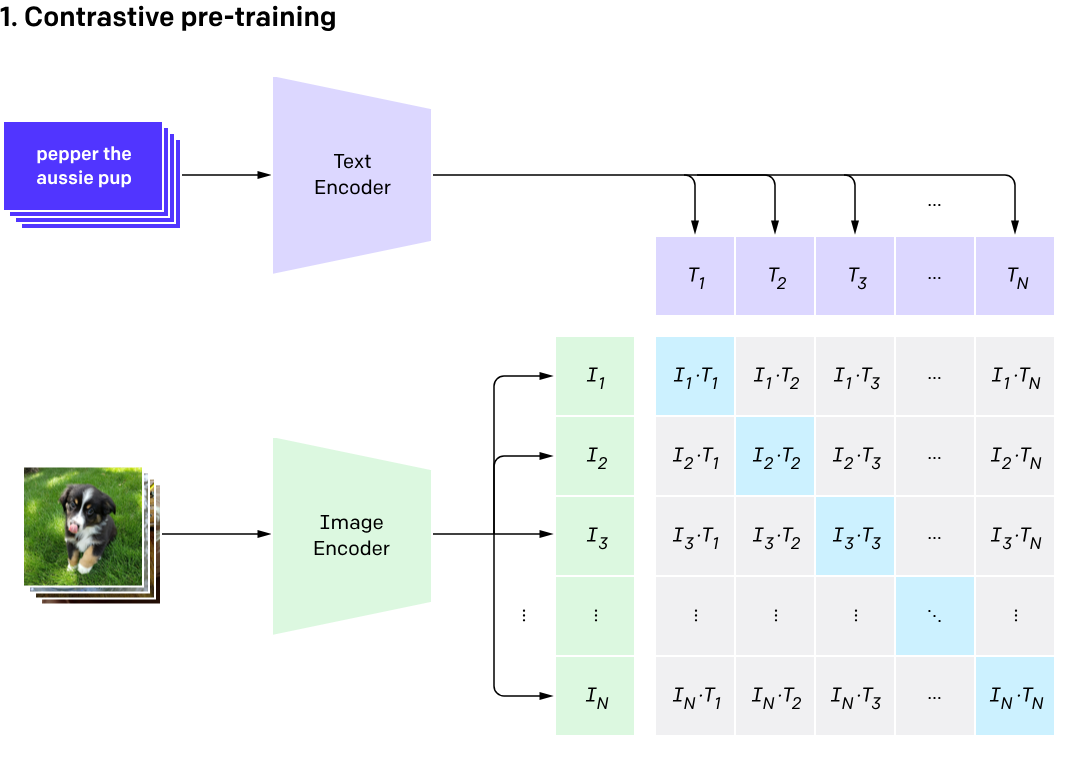
# CLIP
2021年に導入されたCLIPは、画像とそのキャプションの両方を組み合わせています。モメンタムベースの平均化の方法ではありませんが、テキストのエンコーダと画像のエンコーダの2つのエンコーダを使用します。以下はその簡単なワークフローです。
- 画像は画像エンコーダに入力され、キャプションはテキストエンコーダに入力されます。
- Vision Transformer(ViT)に基づく画像エンコーダは画像の埋め込みを取得し、テキストエンコーダはキャプションをトークン化してテキストの特徴を取得します。これらの特徴は埋め込み空間でペアとしてまとめられます。
- テキストエンコーダと画像エンコーダは、与えられたペア
- テスト時には、キャプションの辞書(モコの動的辞書とは異なる)と所望の画像を提供し、画像に基づいて最も確率が高いキャプションを返します。
注: CLIPの詳細については、こちらを読んでください (opens new window)。
# コード例
全体像を完全に理解するために、コード例を示します。ここでは、Meta ResearchによるMoCoの公式実装 (opens new window)を使用します。このコードは主にMocoクラスを中心に展開されています。
# コンストラクタ
MoCoクラスのコンストラクタは、K、m、Tなどの属性を初期化します。dimのデフォルト値は128、キューサイズKは16ビット(65,536)、モメンタム係数μは0.999(非常に遅い移動平均)です。ソフトマックスの温度τは、論文で指定されている通り0.07です。
また、SimCLRで最初に見たMLPの実装もここで見ることができます。
def __init__(self, base_encoder, dim=128, K=65536, m=0.999, T=0.07, mlp=False):
super(MoCo, self).__init__()
self.K = K
self.m = m
self.T = T
# create the encoders
# num_classes is the output fc dimension
self.encoder_q = base_encoder(num_classes=dim)
self.encoder_k = base_encoder(num_classes=dim)
if mlp: # hack: brute-force replacement
dim_mlp = self.encoder_q.fc.weight.shape[1]
self.encoder_q.fc = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.encoder_q.fc
)
self.encoder_k.fc = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.encoder_k.fc
)
for param_q, param_k in zip(
self.encoder_q.parameters(), self.encoder_k.parameters()
):
param_k.data.copy_(param_q.data) # initialize
param_k.requires_grad = False # not update by gradient
# create the queue
self.register_buffer("queue", torch.randn(dim, K))
self.queue = nn.functional.normalize(self.queue, dim=0)
self.register_buffer("queue_ptr", torch.zeros(1, dtype=torch.long))
# モメンタムエンコーダ
コア部分は非常にシンプルですが、非常に効果的です。モメンタムエンコーダでは、次の式をモメンタムベースの平均として実装しています。
@torch.no_grad()
def _momentum_update_key_encoder(self):
for param_q, param_k in zip(
self.encoder_q.parameters(), self.encoder_k.parameters()
):
param_k.data = param_k.data * self.m + param_q.data * (1.0 - self.m)
# キューの管理
最後に、キューを更新して古いバッチデータを削除します。これは次のように機能します。
- まず、キーを収集します。
- キューのポインタは、
keysの転置を指します。なぜ行ではなく列に対して行われるのか、私は興味があります。 - 最後に、ポインタが次のバッチに移動します(ここでのモジュラスは循環キューのためです)、これは属性(
self.queue_ptr)にも反映されます。
def _dequeue_and_enqueue(self, keys):
keys = concat_all_gather(keys)
batch_size = keys.shape[0]
ptr = int(self.queue_ptr)
assert self.K % batch_size == 0
self.queue[:, ptr : ptr + batch_size] = keys.T
ptr = (ptr + batch_size) % self.K
self.queue_ptr[0] = ptr
# 訓練
訓練パスでは、次のようにすべてを組み合わせます。
- クエリの特徴を計算する
- キーの特徴を計算する(モメンタムの更新を使用)
- ロジットを計算する(正と負の両方)
- 上記で説明した関数を使用してデキューとエンキューを行う
def forward(self, im_q, im_k):
"""
Input:
im_q: a batch of query images
im_k: a batch of key images
Output:
logits, targets
"""
# compute query features
q = self.encoder_q(im_q) # queries: NxC
q = nn.functional.normalize(q, dim=1)
# compute key features
with torch.no_grad(): # no gradient to keys
self._momentum_update_key_encoder() # update the key encoder
# shuffle for making use of BN
im_k, idx_unshuffle = self._batch_shuffle_ddp(im_k)
k = self.encoder_k(im_k) # keys: NxC
k = nn.functional.normalize(k, dim=1)
# undo shuffle
k = self._batch_unshuffle_ddp(k, idx_unshuffle)
# compute logits
# Einstein sum is more intuitive
# positive logits: Nx1
l_pos = torch.einsum("nc,nc->n", [q, k]).unsqueeze(-1)
# negative logits: NxK
l_neg = torch.einsum("nc,ck->nk", [q, self.queue.clone().detach()])
# logits: Nx(1+K)
logits = torch.cat([l_pos, l_neg], dim=1)
# apply temperature
logits /= self.T
# labels: positive key indicators
labels = torch.zeros(logits.shape[0], dtype=torch.long).cuda()
# dequeue and enqueue
self._dequeue_and_enqueue(k)
return logits, labels
ちなみに、これらのコメントは著者自身によって書かれており、明確な論文を書いただけでなく、理解しやすいコードも書いています。

# 対照的学習とベクトルデータベース
対照的学習は、入力データの埋め込みとその距離に焦点を当てているため、ベクトルデータベースと非常に関連しています。訓練されたCLモデルを使用すると、ユークリッド距離、コサイン類似度、
その結果、対照的学習をベクトルデータベースと組み合わせて、以下のような無数の応用が可能です。
- ゼロショット認識(それ自体が多くの応用があります)- CLIPを使用したゼロショット認識
- オンラインユーザー向けの推薦システム- ユーザーの履歴に基づいて、最も近い埋め込みを持つ製品を提案します。
- ドキュメント検索- ユーザーのクエリ埋め込みに最も近いドキュメントをデータベースから取得します。
- 異常検知- クレジットカードの新しいトランザクションが通常か不正かを、以前のトランザクションの埋め込みを使用して、このトランザクションとトランザクション履歴の「領域」との類似性(または非類似性)を見つけることで確認できます。
# 参考文献
- Dosovitskiy, et al., Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks, IEEE PAMI, 2016.
- Hjelm, et al., Learning Deep Representations by Mutual Information Estimation and Maximization, ICLR, 2019.
- Oord, et al., Representation Learning with Contrastive Predictive Coding, arXiv 2018.
- Chen, et al., A Simple Framework for Contrastive Learning of Visual Representations, ICML 2020.
- Radford, et al., Learning Transferable Visual Models From Natural Language Supervision, arXiv 2020
- He, et al., Momentum Contrast for Unsupervised Visual Representation Learning, arXiv 2020
- He, et al., Improved Baselines with Momentum Contrastive Learning, arXiv 2020



