
大規模言語モデル(LLM)は、チャットボット作成、言語翻訳、テキスト要約など、多くのタスクを容易にするようになりました。過去には、さまざまなタスクのためにモデルを作成し、そのパフォーマンスの問題が常に存在しました。今では、LLMの助けを借りて、ほとんどのタスクを簡単に実行することができます。ただし、LLMは実世界のユースケースに適用する際にいくつかの制限があります。彼らは特定または最新の情報が不足しており、モデルが誤ったまたは予測不可能な結果を生成する幻覚 (opens new window)と呼ばれる現象につながっています。
ベクトルデータベース (opens new window)は、LLMの幻覚問題を軽減するために非常に役立ちます。モデルが参照できるドメイン固有のデータベースを提供することで、不正確なまたは意味のない応答の発生を減らします。
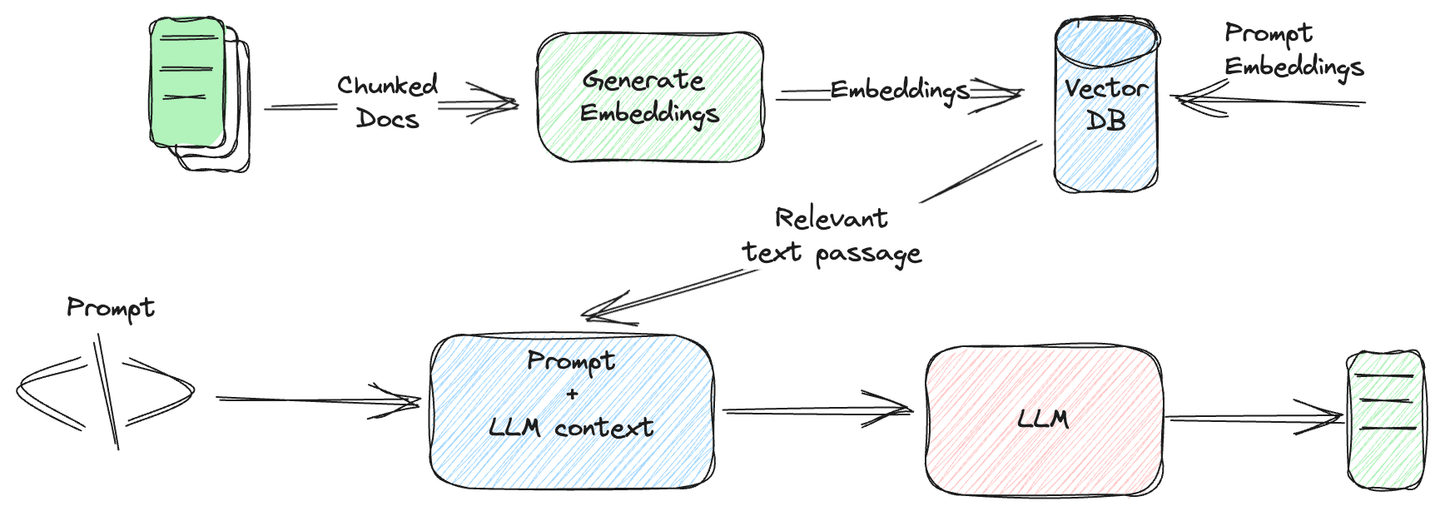
このブログ記事では、ベクトルデータベースとSQLの統合がビジネスにとってどのように生活を簡単にしたかについて見ていきます。従来のデータベースの制限と、この新しい統合であるSQLベクトルデータベースが生まれた背景についても取り上げます。記事の最後では、これらのデータベースがどのように機能し、ベクトルデータベースを選ぶ際になぜMyScale (opens new window)が最初の選択肢になるのかについても見ていきます。
# SQLベクトルデータベースとは
SQLベクトルデータベースは、従来のSQLデータベースの機能とベクトルデータベースの機能を組み合わせた特殊なタイプのデータベースです。SQLの助けを借りて、高次元ベクトルを効率的に格納およびクエリすることができます。
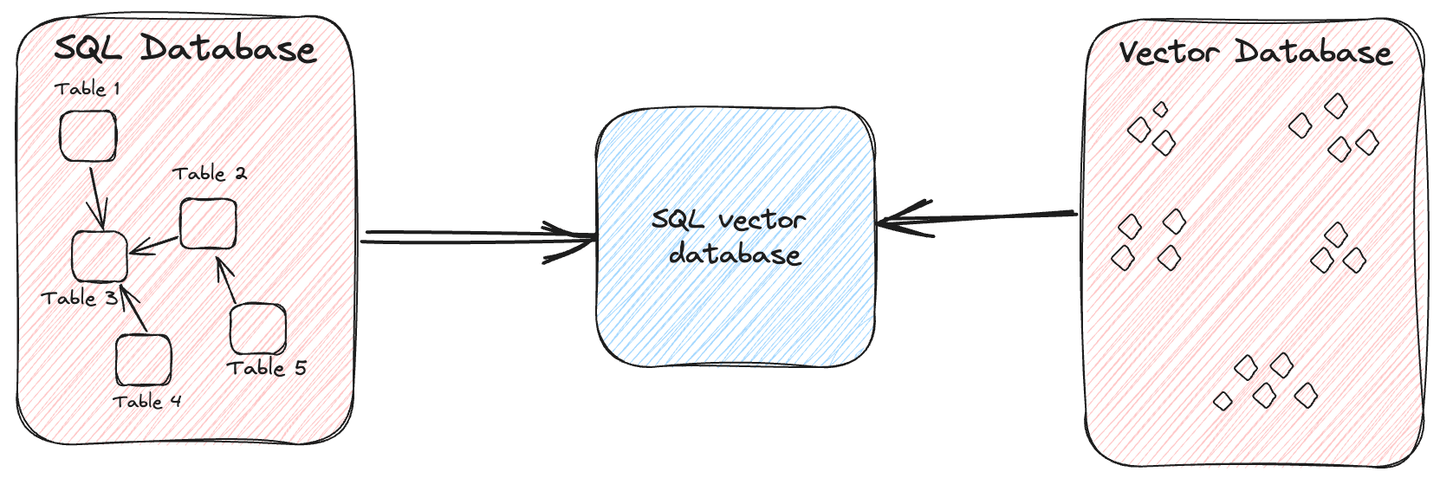
簡単に言えば、構造化データと非構造化データの両方を格納できる通常のデータベースのようなものですが、画像、ビデオ、音声、テキストなどのさまざまなデータ型を含むデータの迅速なクエリを実行するための追加機能があります。この効率性の背後には、データのベクトル化があり、類似のエントリを迅速に特定することが容易になります。
それでは、SQLベクトルデータベースの基本的な概念を理解してみましょう。これにより、なぜSQLベクトルデータベースが必要なのかがわかるでしょう。
# SQLベクトルデータベースの主要な概念
SQLベクトルデータベースでは、非構造化データや高次元データの文脈で、データの検索と分析を大幅に向上させる革新的な概念が導入されています。いくつかの概念を見てみましょう。
- 非構造化データの処理: データのベクトル表現により、非構造化データ(テキスト、画像、音声など)のANN(Approximate Nearest Neighbor)検索を実行することができます。テキスト、画像、音声などの非構造化データの埋め込みを見つけると、意味的な意味を捉えることができ、元のデータ形式に関係なくベクトル間の距離を測定して最も近い隣接データを見つけることができます。
- ANN検索: SQLベクトルデータベースはデータをベクトルとして格納し、類似検索と呼ばれるタイプの検索を実行します。これは単一の行ではなく、与えられたクエリベクトルに最も近いベクトルを特定する近似最近傍(ANN)検索を行います。このプロセスでは、クエリベクトルの特性と最もよく一致するベクトルを特定します。
- ベクトルインデックス: ベクトルインデックスは、大量のベクトルデータを効率的に組織化してクエリを実行するために使用される専用のデータ構造とアルゴリズムを指します。ベクトルデータベースは、データの検索と管理を最適化するためにさまざまなベクトルインデックス戦略を使用します。一部のベクトルデータベースは、検索パフォーマンスを高速化するために階層グラフアルゴリズムを使用します。一部のベンダーは独自のインデックスアルゴリズムを開発する場合もあります。たとえば、MyScaleは、既存の手法を大幅に上回る (opens new window)という革新的な手法であるMulti-Scale Tree Graph(MSTG)を開発しました。
注意:
ベクトルインデックスの目的は、高次元ベクトル全体にわたる近似最近傍の類似検索などの操作を実行する際の検索速度と精度を最適化することです。
# SQLベクトルデータベースが必要な理由
では、なぜSQLベクトルデータベースが必要なのでしょうか?MySQL、PostgreSQL、Oracleなどの従来のデータベースは長い間うまく機能しており、データを整理するために必要なすべての機能を備えています。インデックスの作成方法が速く、トラブルなく必要なデータを取得できます。なぜSQLベクトルデータベースが必要なのでしょうか?
確かに、従来のデータベースは素晴らしいですが、データが膨大で非構造化になるといくつかの制限があります。以下をご覧ください。
- 高速性と意味理解の欠如: 従来のデータベースは、データの取得に正確なキーワードマッチングとインデックスを依存しています。しかし、ソーシャルメディアやセンサーなどからの非構造化データの指数関数的な成長により、従来のデータベースはデータの意味を理解できません。データを迅速に取得するだけでなく、クエリのコンテキストと意味を理解することができるデータベースが必要です。たとえば、自然言語クエリや複雑なデータ関係を扱う場合、従来の方法では迅速かつ関連性のある結果を提供するのが難しいです。
- 高次元データの問題: リレーショナルデータベースは、データを行と列の形式で格納します。列数や次元数が増えると、クエリのパフォーマンスが低下し、「次元の呪い」と呼ばれる現象が発生します。そのため、次元の問題を解決しつつクエリのパフォーマンスを損なうことなくデータベースが必要です。
- 非構造化データ: リレーショナルデータベースでは、構造化データをテーブルの行と列に変換して格納する必要があります。しかし、今日の貴重なデータの増加には、画像、ビデオ、音声、テキストドキュメントなどの非構造化データが含まれており、これらをリレーショナルデータベースに格納するのは非常に困難です。
- スケーラビリティの問題: スケーラビリティは、特に大量のデータを扱う場合に従来のデータベースにとって課題となります。大規模なデータセットを扱う組織にとって問題となり、データの処理と分析に問題を引き起こします。そのため、大量のデータを処理しながら同じ速度と効率性を維持できるデータベースが必要です。
これらの課題に対処するために、SQLベクトルデータベースの開発が進み、従来のデータベースに比べて優れた代替手段が提供されるようになりました。
# SQLベクトルデータベースが従来のデータベースを凌駕する理由
SQLとベクトルを組み合わせることにより、多くの利点がもたらされますが、特に以下の利点が顕著です。
- 高速なパフォーマンスと意味検索: ベクトル表現により、データベースは格納されたデータから意味的な意味を抽出することができます。また、ベクトルの類似性を見つけるため、プロセスはさらに高速化されます。これは、セマンティックな関係がデータ間でより重要な場合、レコメンデーションシステムなどの多くのアプリケーションに役立ちます。
- 効率的なデータの取得: SQLベクトルデータベースは、近似最近傍(ANN)の技術を使用して一致するレコードを見つけます。クエリとデータセットのベクトル間のコサイン類似度を計算することで、最も関連性の高い上位K件の結果を効率的に返します。
- 構造化データと非構造化データの両方のサポート: ベクトルデータベースにSQLを導入することで、非構造化データをベクトルで表現し、意味的な意味を格納することができます。これにより、任意の構造化または非構造化データを簡単にクエリできます。
- 馴染みのあるSQLインターフェース: SQLベクトルデータベースの最大の利点の1つは、データのクエリに馴染みのあるSQLインターフェースを提供することです。ベクトルの機能を採用する際の学習コストを最小限に抑えるため、SQLのスキルを活用することができます。クエリは標準のSQL構文を使用して記述することができます。
# SQLベクトルデータベースの動作原理
SQLとベクトルデータベースの統合では、SQLを使用して高次元ベクトルを効率的にクエリできるように、高次元ベクトルを格納し、インデックスを作成する必要があります。このプロセスにはいくつかのステップがあります。
注意:
このプロジェクトでは、初期実装にはSQLベースのベクトルデータベースであるMyScaleを使用しています。ただし、異なるSQLベクトルデータベースは異なる方法で動作する場合があります。
# ステップ1: データベースの設定
まず、SQLとベクトル操作の両方をサポートするデータベースを設定する必要があります。一部のモダンなデータベースはベクトルを組み込んだサポートを備えていますが、他のデータベースはカスタムデータ型や関数を使用して拡張する必要があります。
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(100),
description TEXT,
vector Array(Float32),
CONSTRAINT check_length CHECK length(vector) = 1536,
);
この例では、1536次元のvector列を持つproductsテーブルを作成しています。
# ステップ2: データの挿入
データを挿入する際には、構造化属性と非構造化データのベクトル表現の両方を格納します。
INSERT INTO products (id, name, description, vector)
VALUES (1, 'スマートフォン', '優れたカメラを搭載したハイエンドスマートフォン。', ARRAY[0.13, 0.67, 0.29, ...]);
このSQL文では、新しい製品レコードとそのベクトルを挿入しています。
注意:
非構造化データのベクトル表現を取得するには、GPT-4やBERTなどのモデルを使用できます。
# ステップ3: ベクトルのインデックス作成
次に、ベクトルインデックスを作成します。これは、データベースが類似検索を適用する速度を定義する技術です。多くのベクトルデータベースでは、KDツリーやRツリー、反転インデックス構造などの専用のインデックス技術を使用してこれらの操作を最適化しています。
ALTER TABLE products ADD VECTOR INDEX idx vector TYPE MSTG
ここでは、多次元データのインデックス作成に適したMSTGインデックスを作成しています。
注意:
MSTGアルゴリズムは、MyScaleチームによって作成されたもので、多くのベクトルデータベース (opens new window)で使用されている主要なベクトル検索インデックスを大幅に上回る性能とコスト効率を提供しています。
# ステップ4: データのクエリ
データをクエリするには、従来のSQLクエリとベクトル操作を組み合わせるだけです。たとえば、クエリベクトルに類似した製品を見つけたい場合、ベクトルのdistance関数を使用できます。
SELECT name, description, distance(vector, query_vector) as dist
FROM products
ORDER BY dist LIMIT 5;
このクエリは、ベクトル列のベクトル表現とquery_vectorの間の距離を見つけます。その後、距離に関して結果を昇順で並べ替えます。

# 理想的なソリューション:MyScale - SQLベクトルデータベース
これが、リレーショナルデータベースとベクトルデータベースを組み合わせたソリューションであるMyScaleの出番です。オープンソースのSQLデータベースClickHouseをベースに構築されたMyScaleは、標準のSQL構文を使用して直接高度なベクトルクエリを実行できます。これにより、別々のリレーショナルデータベースとベクトルデータベースを統合する手間が省けます。PineconeやMilvus、Qdrantなどの他のベクトルデータベースとは異なり、MyScaleはベクトル検索のための単一のSQLインターフェースを提供します。スカラーとベクトルデータを1つのデータベース内に格納することができます。これにより、おなじみのSQLを使用して直接高速なベクトル結果を取得できます。
リレーショナルデータベースはベクトルデータベースと同等のパフォーマンスを提供できないと広く考えられていますが、MyScaleはこの考えを覆しています。直接比較した結果、MyScaleはpgvectorを大幅に上回る (opens new window)検索精度とクエリ処理速度を示し、Pineconeなどの専門のベクトルデータベースよりも優れた性能を発揮 (opens new window)し、特にコスト効率とインデックスの構築時間において優位性を示しています。この優れたパフォーマンスとSQLのシンプルさにより、MyScaleはビジネスにとって最初の選択肢となります。
もし質問がある場合や当社の提供に興味がある場合は、Discord (opens new window)でお気軽にお問い合わせください。または、MyScaleのTwitter (opens new window)をフォローしてください。



