
コントラスティブ学習 (opens new window)の前回の探求では、モデルが埋め込み空間で似たデータと異なるデータを区別する方法を明らかにしました。似たアイテムを近くに配置し、異なるアイテムを遠くに押し出すことで、モデルは学習します。SimCLR (opens new window)、MoCo (opens new window)、CLIP (opens new window)などの方法についても議論しました。これらの方法は、自己教師あり学習 (opens new window)を大幅に進化させました。
メトリック学習の探求を続ける中で、Triplet Lossについて話しましょう。Triplet Lossは、コントラスティブ学習の原則に基づいており、顔認識、画像検索、署名の検証など、微細な区別が必要なタスクで重要な役割を果たしています。
# メトリック学習
Triplet Lossに入る前に、メトリック学習を理解することが重要です。メトリック学習は、データポイント間の類似性を測定する距離関数(またはメトリック)を学習することに焦点を当てた機械学習の一種です。その核心的なアイデアは次のとおりです。
- 似たデータポイントは埋め込み空間で近くに配置されるべきです。
- 異なるデータポイントは遠くに配置されるべきです。
機械学習モデルを使用して埋め込みを生成し、同じカテゴリやラベルに属するデータポイント間の距離を最小化し、異なるカテゴリやラベルに属するデータポイント間の距離を最大化するようにモデルをトレーニングします。
# 一般的な距離メトリック
距離について話す際、距離の選択はユーザーに委ねられます。ユークリッド距離、マンハッタン距離、または一部の高度な距離尺度などが使用されます。一般的に使用される距離には次のものがあります。
- ミンコフスキー距離 - ミンコフスキー距離は、p-ノルムを計算することによって、ノルムベースの距離の一般化です。ここで、pは任意の正の整数です(p = 1および2の場合、それぞれマンハッタン距離とユークリッド距離に簡約されます)。
- コサイン類似度 - コサイン類似度はベクトルの内積に基づいています。平行なベクトルは類似度1(cos 0º)、直交するベクトルは類似度0(cos 90º)、対向するベクトルは類似度-1(cos 180º)を持つことを考慮しています。
- マンハッタン距離 - シティブロック距離またはL1距離とも呼ばれ、2つの点の座標の絶対値の差の合計を計算します。グリッド状のパスや対角線の移動が不可能な状況で特に有用です。
- ジャカード距離 - ジャカード距離は、2つのグループ(集合)間の類似性(または非類似性)を、一致する要素の数と総要素数の比率で測定します。
- マハラノビス距離 - マハラノビス距離は、データの分布を考慮したユニークな尺度です。次のように定義されます。
ここで、
# Triplet Lossとは?
では、メインのトピックに戻りましょう。Triplet Lossは、シンプルな原則に基づいて機能します。埋め込み空間でポイント(通常アンカーと呼ばれる)を選び、それぞれのポイントに対して正のポイントと負のポイントを選びます。必然的に、負のポイントとの距離を最大化し、正のポイントとの距離を最小化したいと考えます。
ここで、
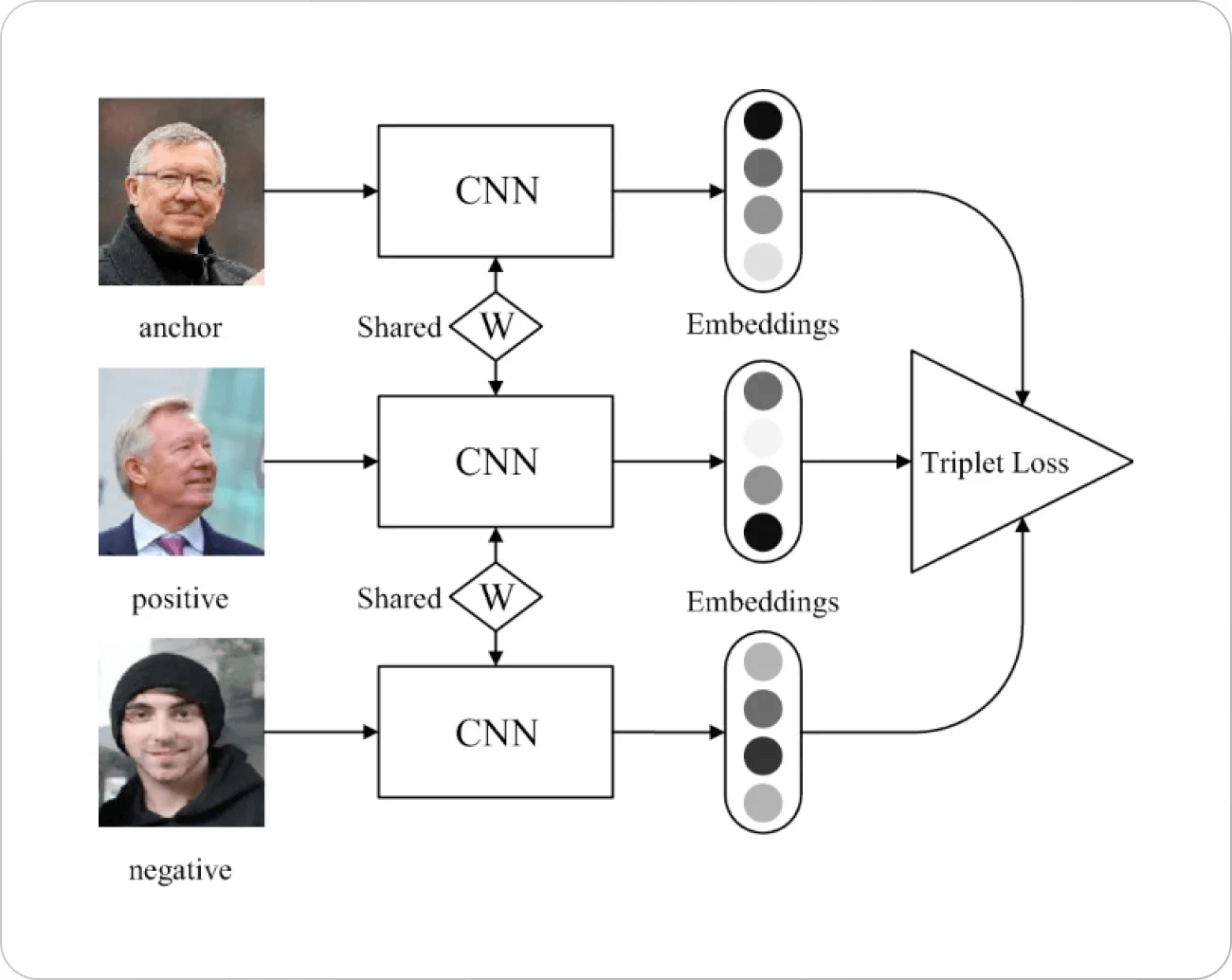
画像の出典: Springer Paper
Triplet Lossの動機にはいくつかの背景があります。顔認識のための以前の損失関数(主に
# Triplet Lossの動作原理
埋め込み空間にデータポイントをプロットすることを想像してください。Triplet Lossでは、次のようなことが行われます。
- アンカーとポジティブ(同じクラス)は近くに引き寄せられます。
- アンカーとネガティブ(異なるクラス)は遠くに押し出されます。
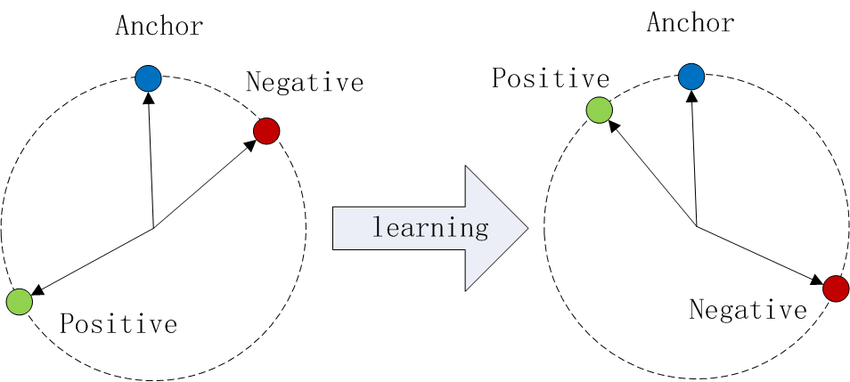
画像の出典: Wikipedia
このプロセスにより、各クラスには明確なクラスタが作成され、モデルのクラス間の区別能力が向上します。
# マージンα
マージンαは、アンカーと正のペアとアンカーと負のペアの間の最小望ましい距離を設定するハイパーパラメータです。これにより、モデルがすべての埋め込みを同じポイントに収束させることを防ぎ、クラス間に意味のある分離を促します。
- αが小さすぎる場合:十分な分離を強制しない可能性があります。
- αが大きすぎる場合:損失が厳しすぎて収束が遅くなる可能性があります。
適切なマージンを選択することは、効果的なトレーニングにおいて重要です。
# Triplet Lossの利点
Triplet Lossは、特に次の場合に有用です。
- 微細な区別が重要な場合:顔認識などのタスクでは、微妙な違いを捉える必要があります。
- クラスの分布が不均衡な場合:埋め込み空間の絶対的な位置ではなく、相対的な距離に焦点を当てています。
- 識別的な特徴の学習:クラス間の差を区別する特徴にモデルが注意を向けるようにします。
# トリプレットマイニング
トリプレットロスは、すべてのポイントをすべての正のポイントと負のポイントと比較する必要があるため、コストがかかります。トレーニングデータが増えると、トレーニングが不可能になり、最悪の場合の計算量は
これを解決するために、ハードなポジティブとハードなネガティブを見つけるためのスマートな使用が行われます。たとえば、顔認識では、ハードなポジティブは同じ人物の写真ですが、照明、服装、ポーズなどがかなり異なる状況で撮影されたものであり、同様に、ハードなネガティブは似たような状況で撮影された異なる人物です。これらのハードなポジティブとハードなネガティブを見つけるプロセスは、マイニングと呼ばれます。他の多くのデータを使用するアルゴリズムと同様に、これはミニバッチで行われます。
# 課題
これらのハードなポジティブとネガティブを見つけることは確かな問題ですが、トレーニングの後半にはさらに大きな課題が生じます。
- 適切なバッチサイズの選択:例が少なすぎると、データの表現が不十分になり、効率的なハードな例が得られません。一方、バッチサイズが大きすぎると、計算リソースの制限(主にGPUメモリ制限)が発生します。
- ハードさの程度:特にハードなネガティブを最初に提示すると、トレーニングが不十分になる[1]ため、ハードな例を提示することは望ましくありません。その結果、いくつかのネガティブな例が検索され、次の不等式が成り立つようになります。
言い換えると、完全にハードではない(不等式によって、それらが正の例の周辺にあることが保証されている)が、十分にハードなネガティブなサンプル
注意:
カリキュラム学習の概念は、適切なハードさの度合いを選択する点で非常に関連しています。このテクニックは、その名前が示すように、学校での学習に触発されています。このテクニックを使用すると、最初に最も簡単な例(黒と白の対比のあるサンプルなど)をモデルに提示し、徐々に難易度を上げていきます。逆カリキュラム学習は、最初に最も難しい例を提示し、徐々に緩和する方法です。2021年、研究者たちは[3]で、カリキュラム学習がノイズのあるデータや限られたトレーニング時間の場合に有効であることがわかるまで、広範な研究を行いました。
- オンライン生成するかどうか:もう1つの選択肢は、トリプレットを事前にすべて生成するか(オフライン)、または動的に生成するかです。両方のオプションにはそれぞれ利点と欠点があります。オフライン生成では通常通りにバッチを生成することができますが、オンライン生成は適応的です。ハードな例を生成するためのオーバーヘッドが発生する場合があります。
# Triplet Lossとコントラスティブ学習
Triplet Lossとコントラスティブ学習の両方は、埋め込みを所望のクラスに近づける(つまり、距離を小さくする)ことと、外れ値から遠ざけることを目的としているため、しばしば同じように見えます。目的は同じですが、コントラスティブロスは各サンプルを一括で正のサンプルと負のサンプルと対比し、トリプレットロスは(理論的には)すべての可能なトリプレットに対して行います。
コントラスティブ学習はすべてのトリプレット(またはペア)を作成する必要がないため、トリプレットロスの実装よりも計算時間がはるかに短くなります。一方、トリプレットロスはほとんどの場合でより高い精度を持っています。
# コントラスティブ学習とトリプレットロスの違い
データのグループ化:
- コントラスティブ学習:サンプルのペア(正のペアまたは負のペア)で操作します。
- トリプレットロス:サンプルのトリプレット(アンカー、ポジティブ、ネガティブ)で操作します。
損失のメカニズム:
- コントラスティブ学習:ペアが類似しているか異なっているかのバイナリの判断を使用します。
- トリプレットロス:アンカー-ポジティブとアンカー-ネガティブの相対距離に焦点を当て、正の例がアンカーよりもネガティブな例に近いことを保証します。
柔軟性:
- コントラスティブ学習:ペアのみが関与するため、計算上はよりシンプルですが、複数のネガティブな例がアンカーに近い複雑な場合には効果が低下する場合があります。
- トリプレットロス:より複雑ですが、埋め込み空間に対するより良い制御を提供します。なぜなら、相対距離を直接最適化するからです。
トレーニングの複雑さ:
- コントラスティブ学習:ペアのみが必要なため、一般的に実装がより簡単です。
- トリプレットロス:ハードなネガティブを慎重に選択する必要があるため、より複雑です(パフォーマンスを向上させるためにハードなネガティブが使用されることが多い)。
# 実装
アンカー(参照点)と正のサンプル、ネガティブなサンプルを取ることで実装することができます。ここでは、ミンコフスキー距離を使用します。つまり、ノルムの順序の選択はユーザーに委ねられます。
import torch
import torch.nn as nn
class TripletLoss(nn.Module):
def __init__(self, margin=1.0):
super(TripletLoss, self).__init__()
self.margin = margin
def forward(self, anchor, positive, negative, norm_order):
pos_dist = torch.norm(anchor - positive, p=norm_order, dim=1)
neg_dist = torch.norm(anchor - negative, p=norm_order, dim=1)
loss = torch.mean(torch.clamp(pos_dist - neg_dist + self.margin, min=0.0))
return loss
# ベストプラクティス
Triplet Lossを使用する際のいくつかのベストプラクティスは次のとおりです。
- 通常、通常のユークリッド距離の方が二乗ユークリッド距離よりも良い結果が得られます。
- 正規化(バッチ正規化やレイヤー正規化など)は通常、トレーニングに役立ちません。
- 最適なバッチサイズ([1]ではほとんどの実験で約1800を使用)。

# 結論
Triplet Lossは、相対的な距離に焦点を当てることで、モデルが似たデータポイントと異なるデータポイントを区別する能力を向上させるメトリック学習の貴重なツールです。コントラスティブ学習のアイデアを基にしており、クラス間の微妙な区別が必要なタスクに特に有用です。
Triplet Lossをモデルに組み込むことで、より洗練されたパターン認識を教える能力を得ることができ、コンピュータビジョン、言語処理などの分野での応用の可能性が広がります。
# 参考文献
- Schroff, et al (CVPR 2015) FaceNet: A Unified Embedding for Face Recognition and Clustering
- Hermans, et al (2017), In Defense of the Triplet Loss for Person Re-Identification
- Wu, et al. (ICLR 2021), When Do Curricula Work?



