
Retrieval-Augmented Generation(RAG)は、外部の知識ベースから取得した情報をLLMに統合することで、LLMを拡張するためのAIフレームワークです。そして、RAGが最近注目を集めていることからも、RAGはAI/NLP(人工知能/自然言語処理)エコシステムで注目されているトピックであると結論付けることは合理的です。したがって、セルフホストLLMと組み合わせた場合のRAGシステムから期待できることについて議論してみましょう。
「Retrieval Augmented Generationでパフォーマンスの向上を発見する (opens new window)」というブログ記事では、取得されるドキュメントの数がLLMの回答の品質を向上させる方法について調査しました。また、MyScale (opens new window)などのベクトルデータベースに格納されたMMLUデータセットに基づくベクトル化されたLLMは、文脈に関連する知識を統合し、データセットを微調整することなくより正確な応答を生成します。
したがって、重要なポイントは次のとおりです:
RAGは外部データを用いてプロンプトを拡張することで、知識のギャップを埋め、幻覚を減らします。
アプリケーションで外部のLLM APIを使用することは、データのセキュリティリスクを引き起こし、制御を減少させ、特にユーザー数が多い場合にはコストを大幅に増加させる可能性があります。したがって、疑問となるのは次のことです:
より大きなデータセキュリティを確保し、システムを制御する方法は何ですか?
簡潔な答えは、セルフホストLLMを使用することです。このアプローチは、データとモデルに対する優れた制御を提供するだけでなく、データのプライバシーとセキュリティを強化し、コスト効率を向上させます。
# セルフホストLLMの利点
クラウドベースのLarge Language Models-as-a-Service(OpenAIのChatGPTなど)は簡単にアクセスでき、即座かつ説明責任を持ってさまざまなアプリケーションドメインに価値を追加できます。ただし、パブリックなLLMプロバイダはデータのセキュリティとプライバシー、制御の問題、知識の漏洩、コスト効率に関する懸念があります。
注意:
これらの懸念のいずれかが共感される場合、セルフホストLLMを使用することは価値があります。
議論を続けるにあたり、以下の4つの重要な懸念について詳しく説明しましょう:
# 🔒 プライバシー
アプリケーションにLLM APIを統合する際には、プライバシーが最も重要な懸念事項となります。
なぜプライバシーが問題となるのでしょうか?
この質問の答えは、次のポイントで示されるように、いくつかの部分から成り立っています:
- LLMサービスプロバイダは、個人情報をトレーニングや分析に使用する可能性があり、プライバシーとセキュリティが危険にさらされる可能性があります。
- さらに、LLMプロバイダは、検索クエリを自身のトレーニングデータに組み込む可能性があります。
セルフホストLLMは、これらの問題を解決します。セキュリティが確保されており、あなたのデータは第三者のAPIに公開されることはありません。
# 🔧 制御
OpenAI GPT-3.5などのLLMサービスでは、暴力や医療アドバイスの要求などのトピックを一般的に検閲しています。どのコンテンツが検閲されるかについては制御することができません。しかし、独自の検閲モデル(およびルール)を開発したい場合があります。
要件を満たす検閲モデルを採用するにはどうすればよいですか?
大まかな理論的な答えは、カスタムフィルタを構築してLLMをカスタムファインチューニングすることが、プロンプトを使用するよりも安定したモデルになるということです。さらに、パブリックドメインのLLMに含まれるデフォルトの検閲を上書きしたり変更したりする自由を提供するため、セルフホストLLMは望ましいです。
# 📖 知識の漏洩
上記のように、知識の漏洩はサードパーティのLLMサーバを使用する際の懸念事項です、特にプロプライエタリなビジネス情報を含むクエリを実行する場合です。
注意:
知識の漏洩は、プロンプトからLLMへ、そしてクエリアプリケーションへと両方向に発生する可能性があります。
知識の漏洩を防ぐにはどうすればよいですか?
まとめると、プロプライエタリなビジネス知識ベースは、パブリックドメインのLLMではなく、セルフホストLLMを使用します。なぜなら、それが最も貴重な資産の1つだからです。
# 💰 コスト効率
セルフホストLLMがクラウドホストLLMと比較してコスト効率的かどうかは議論の余地があります。記事「How continuous batching enables 23x throughput in LLM inference while reducing p50 latency (opens new window)」で説明されている研究によると、適切にバランスの取れた高度なcontinuous batching (opens new window)戦略により、セルフホストLLMはよりコスト効率的です。
注意:
この概念については、このテキストの後半で詳しく説明します。
# セルフホストLLMでRAGを最大限に活用する
![]()
LLMは計算リソースを大量に消費します。推論と応答の提供には膨大なリソースが必要です。RAGを追加すると、精度向上のために回答するために必要なトークンに2,000以上のトークンが追加されるため、これらの追加のトークンは追加のコストを発生させます。特にOpenAIのようなオープンソースのLLM APIとのインターフェースを持つ場合、これらの追加のコストは高額になる可能性があります。
これらの数字は、セルフホストLLMを使用し、行列やキーバリューキャッシュ (opens new window)、連続バッチング (opens new window)などの方法を使用して効率を改善することで改善する可能性があります。一方で、クラウドベースのコアGPUコンピューティングプラットフォーム(RunPod (opens new window)など)の場合、実行時間ではなくトークンのスループットで請求されるため、セルフホストRAGシステムにとっては良いニュースであり、プロンプトトークンあたりのコスト率が低くなります。
次の表は、セルフホストLLMとRAGを組み合わせることで、コスト効率と精度を提供することを示しています。要約すると:
- 最大限に活用した場合、コストは
gpt-3.5-turboのわずか10%になります。 - 10のコンテキストを持つ
llama-2-13b-chatRAGパイプラインは、1840トークンに対してわずか$0.04のコストで、コンテキストなしのgpt-3.5-turboのコストの1/3です。
注意:
RAGによるパフォーマンスの向上の詳細については、最初のRAGブログ記事 (opens new window)をご覧ください。
表:合計コストの比較(米セント)
| # コンテキスト | 平均トークン数 | LLaMA-2-13Bの精度向上 | 1スレッドのllama-2-13b-chat | 8スレッドのllama-2-13b-chat | 32スレッドのllama-2-13b-chat | gpt-3.5-turbo |
|---|---|---|---|---|---|---|
| 0 | 417 | +0.00% | 0.3090 | 0.0423 | 0.0143 | 0.1225 |
| 1 | 554 | +4.83% | 0.3151 | 0.0450 | 0.0166 | 0.1431 |
| 3 | 737 | +6.80% | 0.3366 | 0.0514 | 0.0201 | 0.1705 |
| 5 | 1159 | +9.07% | 0.3627 | 0.0575 | 0.0271 | 0.2339 |
| 10 | 1840 | +8.77% | 0.4207 | 0.0717 | 0.0400 | 0.3360 |
# 私たちの方法論
この記事のすべての評価には、量子化されていないllama-2-13b-chatモデルをtext-generation-inference (opens new window)を使用して実行しました。また、1x NVIDIA A100 80GBを搭載したクラウドポッドを1時間あたり1.99ドルでレンタルしました。このサイズのポッドではllama-2-13b-chatをデプロイすることができます。特筆すべきは、各図は第1四分位数を下限、第3四分位数を上限として使用し、ボックスプロットを用いてデータの分布を視覚的に表現しています。
注意:
70Bのモデルをデプロイするには、より多くのGPUメモリが必要です。
# LLMスループットの限界に挑む
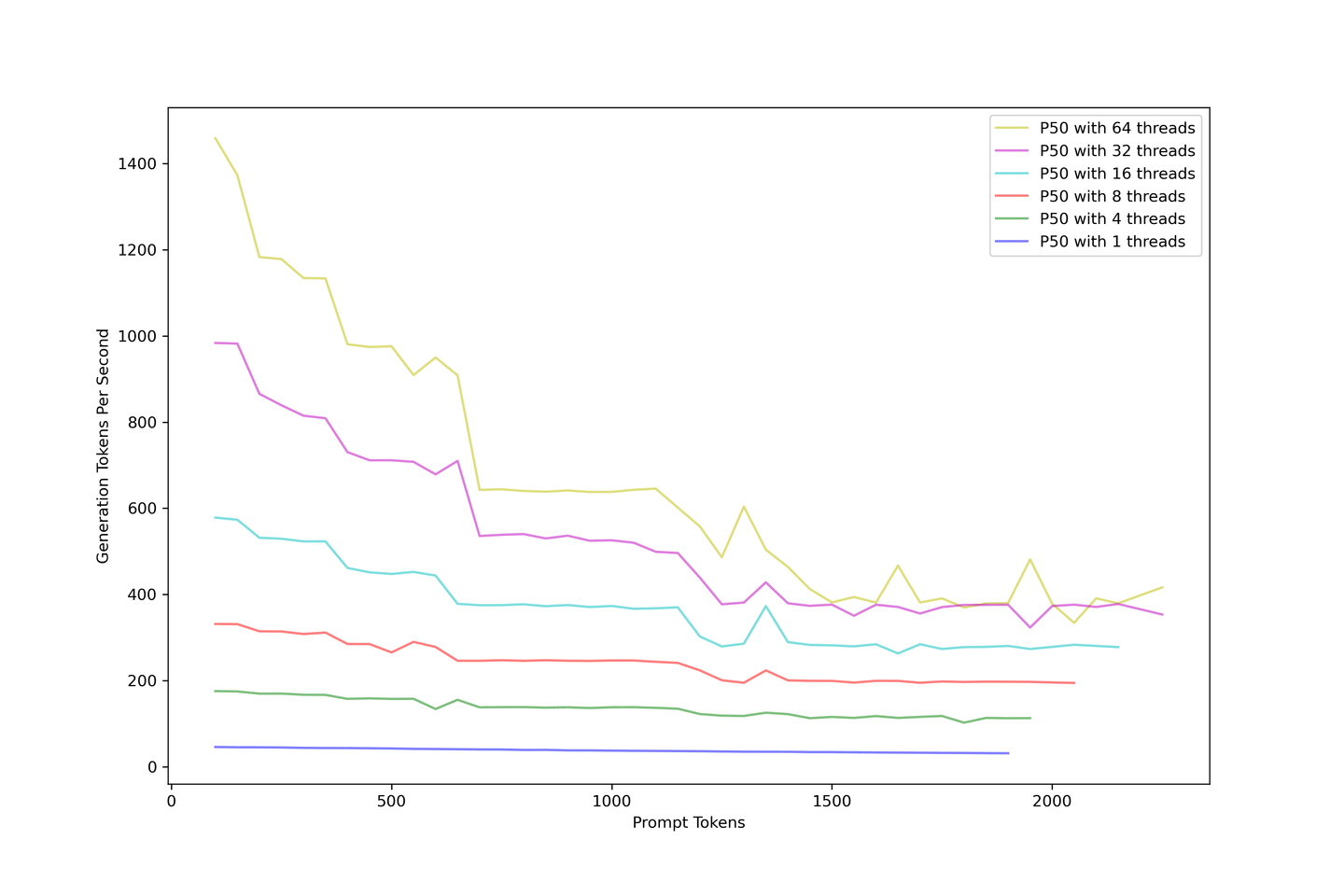
まず考慮すべきは全体のスループットです。1から64スレッドまでLLMを過負荷にして、多数の同時発生クエリをシミュレートしました。以下の画像は、プロンプトが大きくなるにつれて生成スループットがどのように落ちるかを説明しています。生成スループットは、どのように並行性を高めても、秒間約400トークンで収束します。
プロンプトを追加するとスループットが減少します。解決策として、精度とスループットのバランスを取るために、10以下のコンテキストを持つRAGの使用をお勧めします。
# 長いプロンプトの起動時間を測定
モデルの応答性は私たちにとって重要です。また、一般的な言語モデリングの生成プロセスが反復的であることも知っています。モデルの応答時間を改善するために、KVキャッシュを使用して以前の生成からの結果をキャッシュし、計算時間を削減しました。KVキャッシュを使用してLLMを生成するこのプロセスを「ブート」と呼んでいます。
注意:
プロセスの最初にすべての入力プロンプトのキーと値を計算する必要があります。

プロンプトの長さを増やしながら、モデルのブート時間を引き続き評価しました。以下のチャートは、ブート時間を対数スケールで示しています。
このチャートに関連するポイントは以下の通りです:
- 32スレッド以下では、ブート時間は許容範囲内です。
- ほとんどのサンプルのブート時間は1000ms以下です。
- 並行性を高めるとブート時間が急激に上昇します。
- 64スレッドを使用した例では、1000ms以上でスタートし、約10秒で終了します。
- これはユーザーが待つには長すぎます。
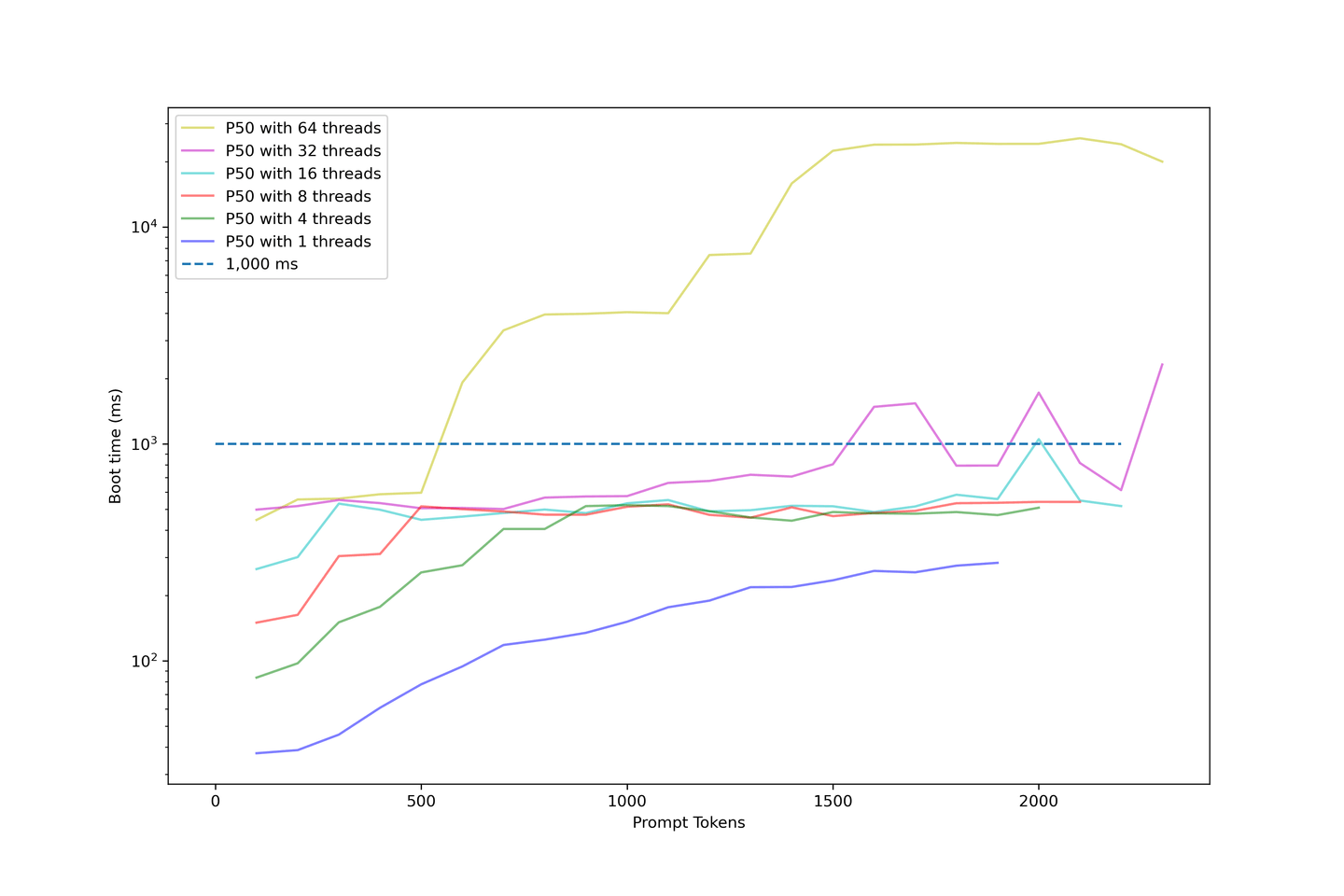
私たちのセットアップでは、32スレッド以下の並行性で平均ブート時間は約1000msであることが分かります。したがって、LLMを過度に負荷させることはお勧めできません。ブート時間が非常に長くなるからです。
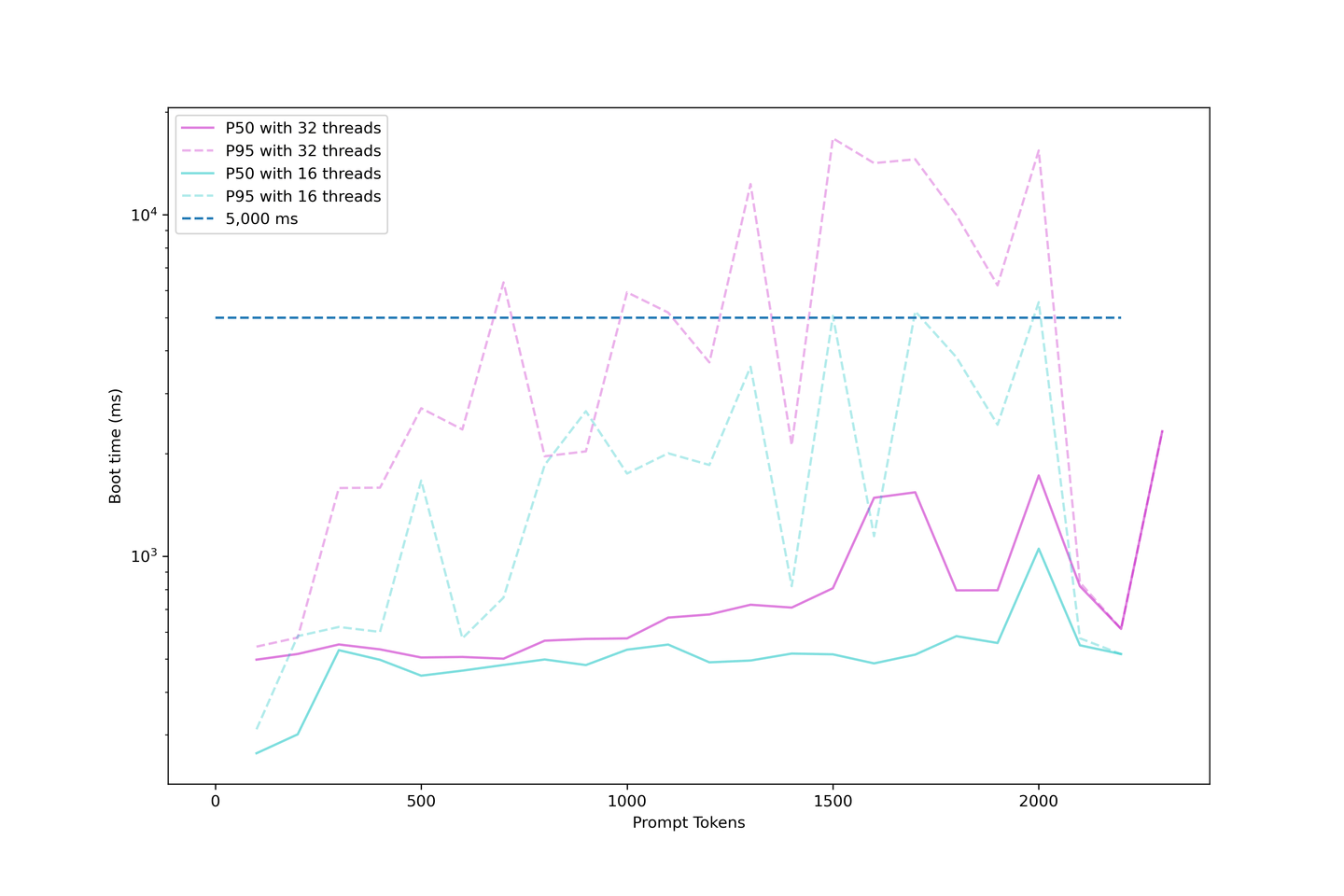
# 生成遅延の評価
KVキャッシュを使用したLLM生成は、ブート時間と生成時間に分けることができます。アプリケーション内で次のトークンが表示されるまでユーザーが待つ時間、つまり実際の生成遅延を評価することができます。
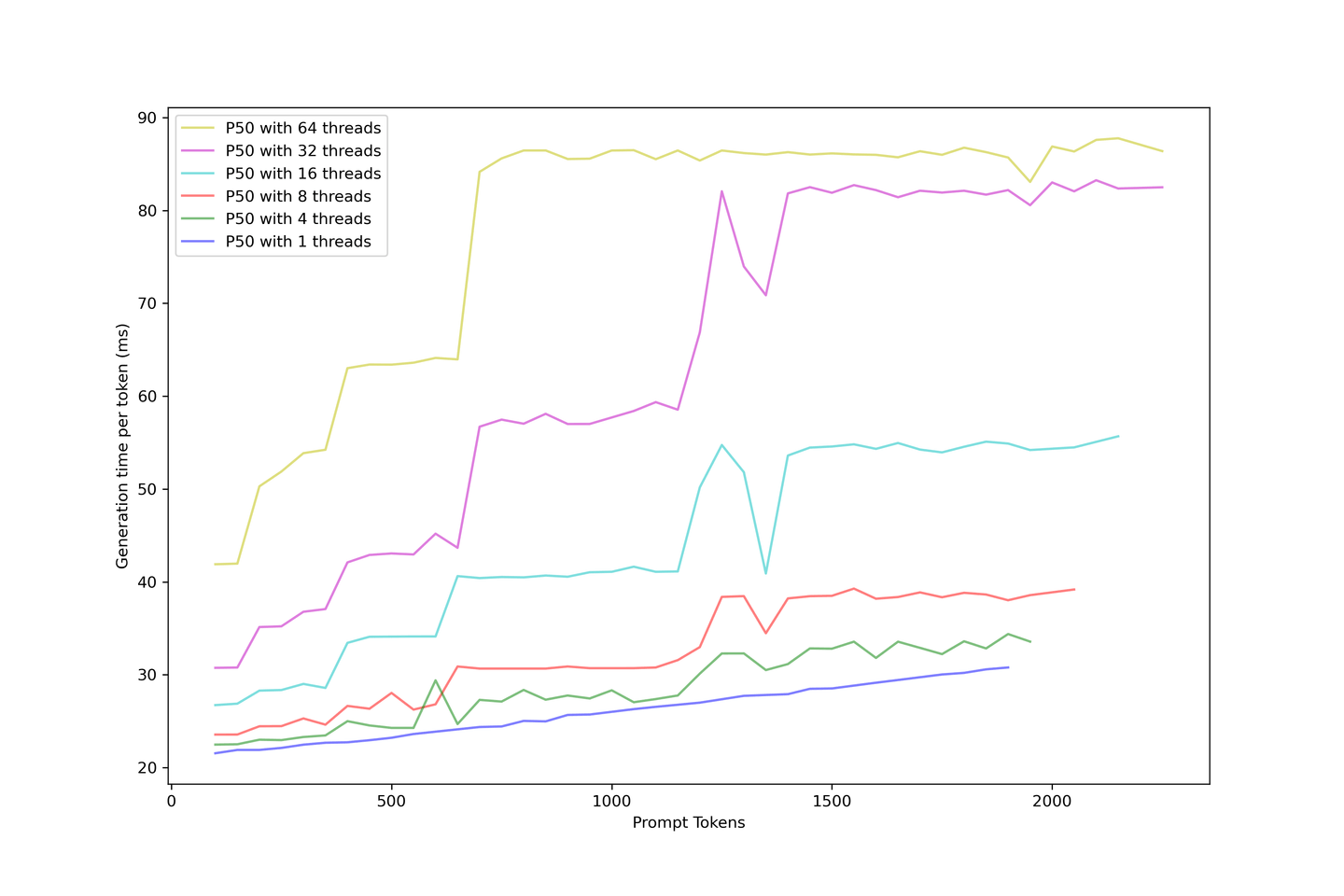
生成遅延はブート時間より安定しています。なぜなら、ブートプロセス内の大きなプロンプトは連続バッチ戦略に配置するのが難しいからです。そのため、同時に多くのリクエストがある場合、前のプロンプトがキャッシュされるまで待ってから、次のトークンが表示されます。
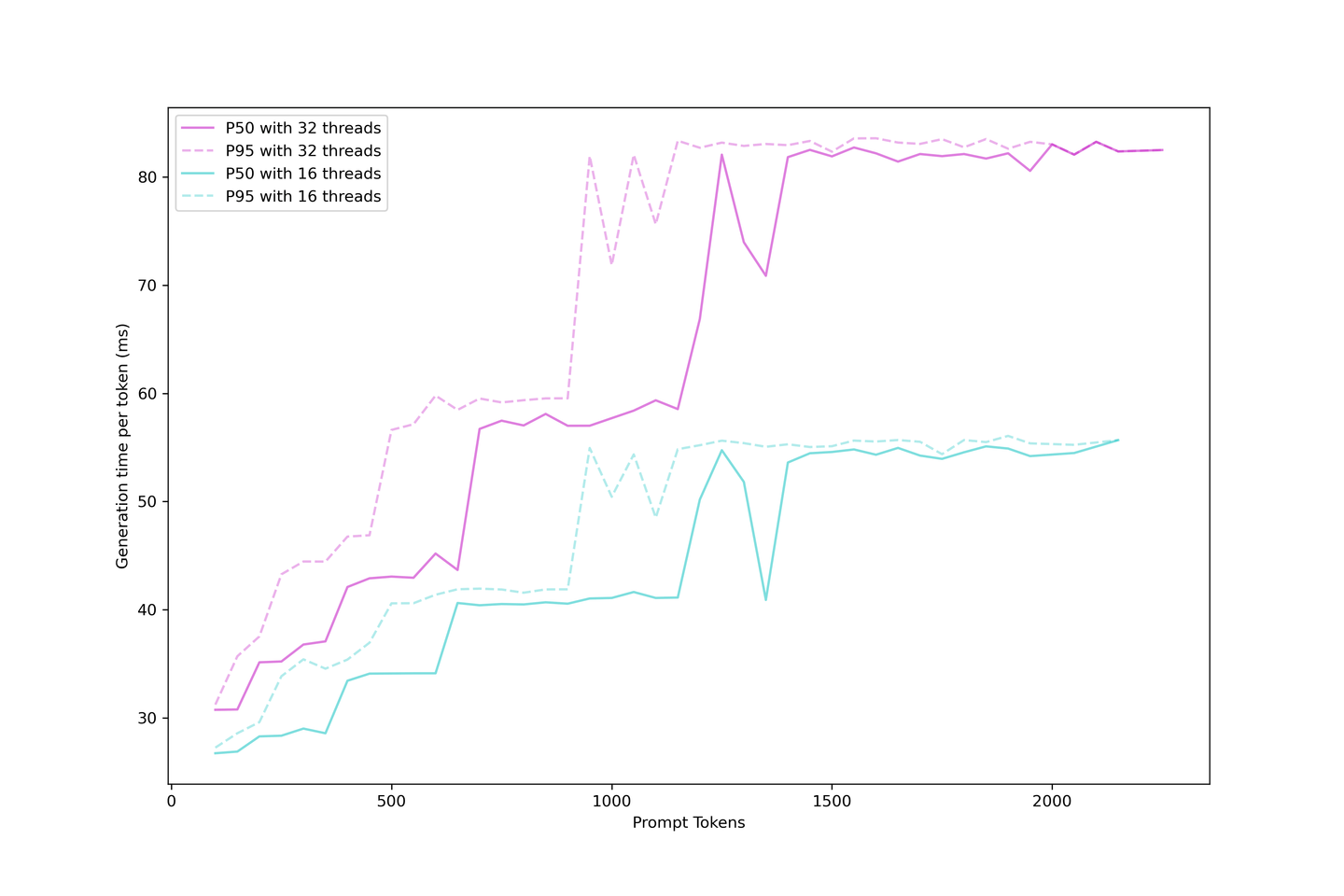
一方、キャッシュが構築されると、生成ははるかにシンプルになります。KVキャッシュは反復回数を減らし、バッチ内に場所ができたらすぐにスケジュールされます。遅延は異なる段階で上昇し、これらの段階はより大きなプロンプトで早く到達し、バッチが飽和します。より多くのリクエストはすぐにLLMを使い果たし、より多くのリクエストを処理しながら限界を高めます。
常に90ms以下の生成遅延を予想するのは妥当であり、コンテキストと並行性を強く押し付けなければ、60ms前後になることもあります。したがって、このセットアップでは32の並行性で5つのコンテキストをお勧めします。
# gpt-3.5-turboのコスト比較
このソリューションのコストに非常に興味があります。そこで、上記のデータを使用して、パイプラインのコストモデルを以下のように作成しました:
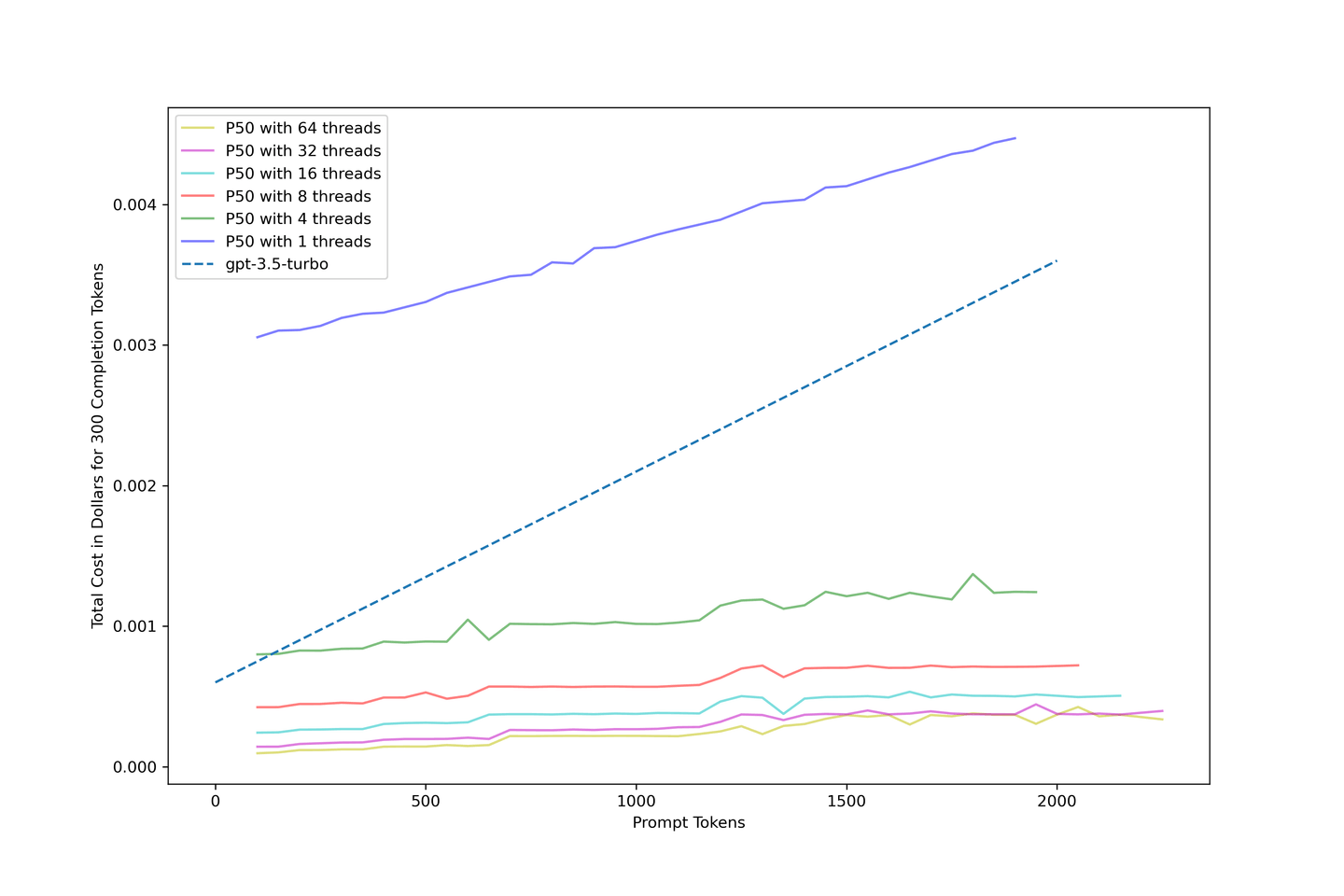
KVキャッシュと連続バッチ処理を使用すると、システムのコスト効率が向上し、適切なセットアップではgpt-3.5-turboのコストを10分の1に削減できる可能性があります。最適な結果を得るためには、32スレッドの並行性が推奨されます。
# 今後の展望
最後に私たちが尋ねる質問は:
これらのチャートから何を学び、ここからどこへ行くのか?
# レイテンシーとスループットのバランス
レイテンシーとスループットの間には常にトレードオフがあります。日々の使用量とユーザーのレイテンシー許容度を見積もることが良いスタート地点です。ドル当たりのパフォーマンスを最大化するために、1x NVIDIA A100 80GBで32の同時性を持つllama-2-13bまたは類似のモデルを想定することをお勧めします。これにより、最良のスループット、比較的低いレイテンシー、そして合理的な予算を実現できます。常に使用状況を見積もることを忘れずに、決断はいつでも変更できます。
# モデルのファインチューニング:長くて強い
RAGシステムでモデルをファインチューニングできるようになりました。これにより、モデルは長いコンテキストに慣れることができます。長い入力長のためにLLMをチューニングするオープンソースのリポジトリがあります。例えば、Long-LLaMA (opens new window)があります。長いコンテキストでファインチューニングされたモデルは、コンテキスト内での学習が得意で、RoPEリスケーリング (opens new window)によって伸ばされたモデルよりも優れています。
# MyScaleをRAGシステムと組み合わせる:推論とデータベースのコスト分析
MyScaleとRunPodの10 A100 GPUをMyScale(ベクトルデータベース)と組み合わせることで、最大100人の同時ユーザーに対応するLlama2-13B + Wikipedia知識ベースRAGシステムを簡単に構築できます。
この議論を終える前に、このようなシステムを運用するための簡単なコスト分析を考慮しましょう:
| 推奨される製品 | 推奨されるスペック | 1ヶ月あたりの推定コスト(USD) |
|---|---|---|
| RunPod | 10 A100 GPU | $14,000 |
| MyScale | 4000万ベクトル(レコード)x 2レプリカ | $2,000 |
| 合計 | $16,000 |
注意:
- これらのコストは、上記で強調されたコスト計算に基づいた概算です。
- 大規模なRAGシステムは、ベクトルデータベースサービスの追加コスト15%未満でLLMのパフォーマンスを大幅に向上させます。
- ユーザー数が増えると、ベクトルデータベースの償却コストはさらに低くなります。

# 結論...
RAGでの追加プロンプトはコストがかかり、速度が遅くなると直感的に思われます。しかし、私たちの評価によると、これは現実世界のアプリケーションに対して実行可能なソリューションであることが示されています。この評価では、自己ホスト型LLMから期待できることを検証し、このソリューションのコストと全体的なパフォーマンスを評価し、外部知識ベースを用いたLLMのデプロイ時にコストモデルを構築する際の助けとなります。
最終的に、MyScaleのコスト効率がRAGシステムをよりスケーラブルにすることがわかります!
そのため、RAGパイプラインのQAパフォーマンスを評価することに興味がある場合は、discord (opens new window)やTwitter (opens new window)で私たちに参加してください。また、RQABenchmark (opens new window)を使って、自分自身のRAGパイプラインを評価することもできます!
私たちは、LLMやベクトルデータベースに関する最新の発見をお伝えし続けます!



