
AIの台頭に伴い、ベクトルデータベースは大規模で高次元のデータを効率的に格納、管理、検索する能力から注目を集めています。この能力は、テキスト、画像、動画などの非構造化データを扱うAIおよび生成AI(GenAI)アプリケーションにとって重要です。
ベクトルデータベースの主な目的は、従来のデータベースが提供するキーワード検索ではなく、類似性検索の機能を提供することです。このコンセプトは、ChatGPTのリリースに続いて、特に大規模な言語モデル(LLM)のパフォーマンスを向上させるために広く採用されています。
LLMの最大の問題は、微調整に大量のリソース、時間、データが必要であり、それらを最新の状態に保つことが非常に困難であることです。そのため、最近の出来事についてLLMにクエリを投げると、事実に反した回答や無意味な回答、入力プロンプトと関連のない回答が返されることがよくあり、それが「幻覚」を引き起こします。
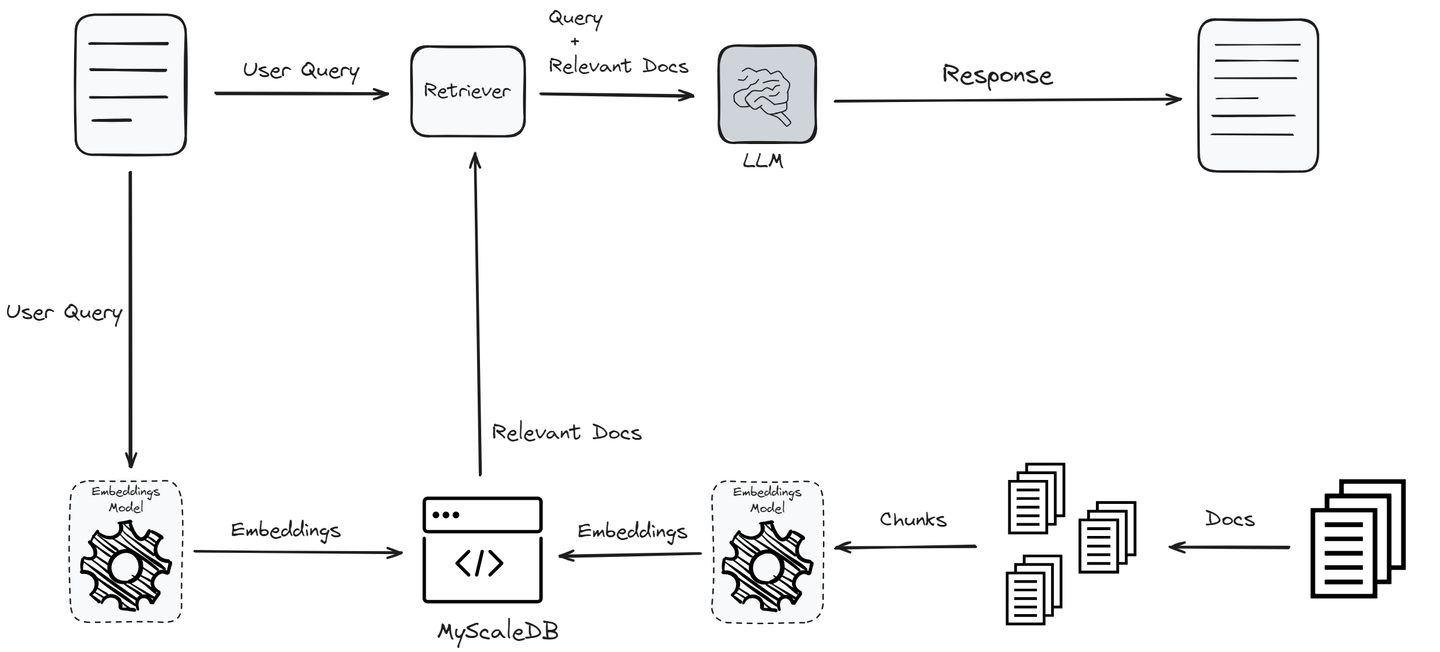
一つの解決策は、検索補完生成(RAG) (opens new window)です。これは、外部の知識ベースから取得した最新の情報をLLMに統合することで、LLMを補完するものです。専門のベクトルデータベースは、ベクトル化されたデータを効率的に処理し、堅牢な意味検索機能を提供するように設計されています。これらのデータベースは、高次元ベクトルの格納と検索に最適化されており、類似性検索を行うために非常に重要です。ベクトルデータベースの速度と効率性は、RAGシステムの重要な要素となっています。
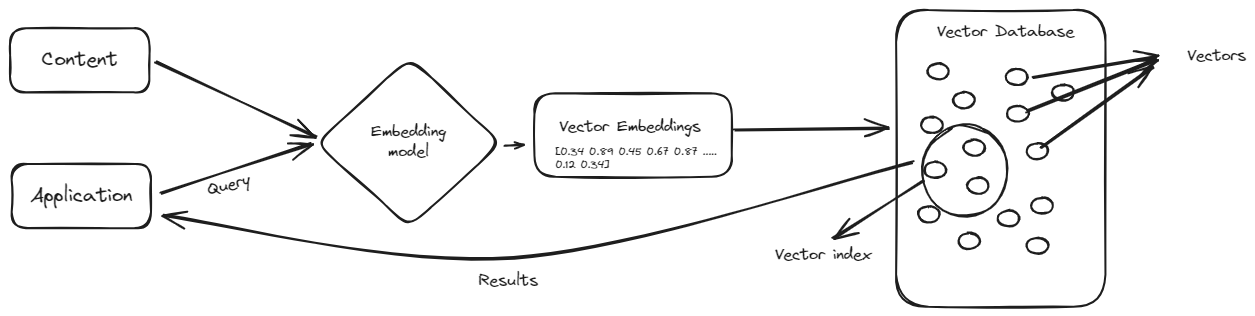
ベクトルデータベースに対する熱狂は、多くの人々が従来のデータベースがベクトルデータベースに置き換えられる可能性があると提案していることを引き起こしました。従来の(SQLまたはNoSQL)データベースにデータを格納する代わりに、自然言語で組み合わせることで、組織のデータセット全体をベクトルデータベースに格納し、取得することができるのでしょうか?
しかし、ベクトルデータベースは従来のデータベースとは異なる動作をします。QdrantのCTOであるAndrey Vasnetsov氏が書いたように (opens new window)、「ベクトルデータベースの大部分は、この意味でのデータベースではありません。それらを検索エンジンと呼ぶ方が正確です。」これは、彼らの主な目的が最適化された検索機能を提供することであり、キーワード検索やSQLクエリのような基本的な機能をサポートするために設計されていないためです。
# 専門のベクトルデータベースの制限
ユースケースが増え、アプリケーションのスケーラビリティに焦点が当てられるにつれて、ベクトルデータベースの制限がより明確になりました。開発者はすぐに、ベクトルデータベースではフルテキスト検索エンジンの機能も必要であることに気付きました。たとえば、特定の基準に基づいて検索結果をフィルタリングすることは、ベクトルデータベースでは非常に困難です。これらのデータベースには、多くのタスクにとって重要な正確なフレーズの直接一致がありません。
# 複雑なクエリのサポートが限られている
複雑なクエリには、複数の条件、結合、集計が含まれることが多く、専門のベクトルデータベースではこれらを処理するのが難しいです。これらのデータベースは、メタデータフィルタリングを通じて複雑なクエリの限定的なサポートを提供しています。しかし、ベクトルデータベースではメタデータの保存領域が非常に限られているため、ユーザーは幅広い複雑なクエリを行う能力が制限されます。
対照的に、SQLデータベースは広範なストレージと処理を扱うように設計されており、複数の条件、結合、集計を含む複雑なクエリを効率的に実行することができます。これにより、SQLデータベースは、複雑なデータの取得と操作タスクを処理する際に非常に柔軟で能力があります。
# データ型の制限
専門のベクトルデータベースは、データ型の制限も抱えています。ベクトルと最小限のメタデータの格納に特化しているため、柔軟性が制限されます。ベクトルに焦点を当てることは、整数、文字列、日付などのSQLデータベースが処理できるさまざまなデータ型を扱うことができないことを意味します。これにより、ベクトルデータベースは一般的なデータベースタスクには適していないと言えます。ベクトルデータベースはRAGアプリケーションには適していますが、より広範なユースケースには十分に柔軟ではありません。
# 統合の課題
専門のベクトルデータベースを既存のITインフラストラクチャに統合することは、さまざまな課題を伴います。専門のベクトルデータベースと既存のシステムとの固有の違いにより、互換性の問題が生じることがよくあり、大量のデータ変換やデータの損失や破損の可能性が生じます。レガシーシステムとの相互運用性の確保、データの一貫性と整合性の維持も複雑なタスクです。さらに、統合プロセスには専門のスキルセットが必要であり、組織内で容易に利用できない場合は、高いトレーニングコストと急激な学習曲線が生じます。
さらに、統合には相当な費用がかかります。ソフトウェアのライセンス料、ハードウェアのアップグレード、人員のトレーニング、継続的なメンテナンスなどのコストが発生します。また、既存のアプリケーションをベクトルデータベースとの連携に変更または書き換える必要がある場合がありますが、これは新しいバグやパフォーマンスの問題を引き起こす可能性があるため、コストがかかり、リスクが伴います。専門のベクトルデータベースの継続的なサポートと更新の必要性も、長期的な財務的な負担につながる可能性があります。
# データ処理にはハイブリッドアプローチが必要
専門のベクトルデータベースの基盤は、ベクトルの格納とベクトルの検索であり、主にRAGアプリケーションに適しています。しかし、従来のデータベースもベクトルを処理できる必要があり、ベクトル検索はデータ処理の新しい方法の基盤ではありません。
RAGはベクトルデータベースの利点を活用する人気のあるAI技術です。ベクトルデータベースは、意味検索や高次元データの処理に優れていますが、その特化した機能は組織の運用および機能的なニーズを見落とすことがあります。これにより、多様な運用および機能的な要件を持つ広範なアプリケーションでの使用が制限される場合があります。
同様に、従来のデータベースは、ベクトルの格納とベクトル検索の機能を組み込んで、複雑なデータ型の大規模処理に効率的なソリューションを提供しようとしてきました。たとえば、PostgreSQLやElasticsearchはベクトル検索の機能を導入しています。しかし、そのベクトル検索のパフォーマンスは専門のベクトルデータベース(PineconeやQdrantなど)に比べて劣っています。たとえば、Qdrantは平均レイテンシがわずか45.23msで、精度率が0.9822です。一方、堅牢なOpenSearchはより高いレイテンシ(53.89ms)とわずかに低い精度(0.9823)を記録しています。
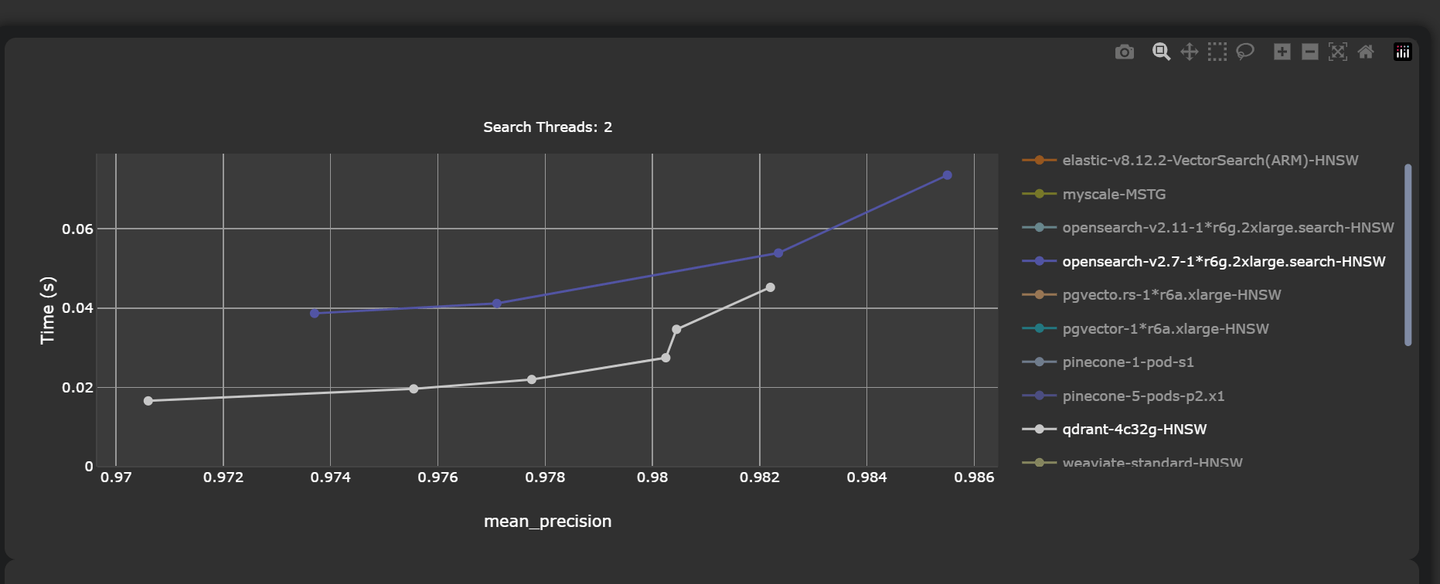
注意:
完全なベンチマークはこちら (opens new window)を参照してください。
専門のベクトルデータベースのアーキテクチャは、高次元ベクトルデータを効率的に処理するために特別に設計されていますが、従来のデータベースは主に関係データの処理に適しており、ベクトル検索の特定のニーズを自然にサポートしていません。
もう一つの選択肢は、現在のデータベースや検索エンジンにベクトル拡張機能を追加することです。このアプローチは、従来のデータベースの強みと柔軟性を現代のベクトル検索の高度な機能と統合することで、ビジネスのニーズを直接サポートします。
ハイブリッドモデルは、ビジネスの多様なデータ処理要件により密接に合致し、データインフラストラクチャを効率化します。これにより、運用コストと複雑さが削減され、組織の包括的なデータ処理ニーズに対応するスケーラブルで効率的なソリューションが実現されます。
# SQLベクトルデータベースがギャップを埋める--MyScaleDBの紹介
SQLは半世紀にわたりスケーラブルなアプリケーションの基盤となっており、ベクトル検索の機能との統合は、従来のデータ処理ニーズと現代のデータ処理ニーズとのギャップを埋めることが期待されています。SQLとベクトルの統合により、データモデリングの柔軟性が向上し、開発が容易になります。これにより、構造化データ、ベクトルデータ、キーワード検索、複数のテーブル間の結合クエリを含む複雑なクエリを処理するシステムが可能になります。
専門のベクトルデータベースは、高次元データを精度と速度で処理する点で優れていますが、ベクトル検索をSQLデータベースに統合することは魅力的な代替手段です。これにより、スケーラビリティのある複雑なデータ型処理に必要な効率と、広く採用されているフレームワーク内で作業する便利さのバランスが取れます。この統合により、専門のベクトルデータベースが直面する遅い反復、効率の悪いクエリ処理、別個のデータベースの管理にかかる高いコストなどの多くの課題が解決されます。SQLベクトルデータベースを採用することで、企業はSQLの確立されたスケーラビリティと信頼性の力を活用しながら、現代のデータ処理の多面的な課題に対応するために必要な高度な機能を得ることができます。
MyScaleDB (opens new window)は、ClickHouse上に構築されたオープンソースのSQLベクトルデータベースです。GenAIアプリケーションのためにSQLを使用して高次元ベクトルを効率的に格納および管理する能力を備えています。高度なフィルタリングと複雑なSQLベクトルクエリによる包括的なデータの取得を提供し、使用の容易さのためにテキストからSQLへの変換をサポートしています。
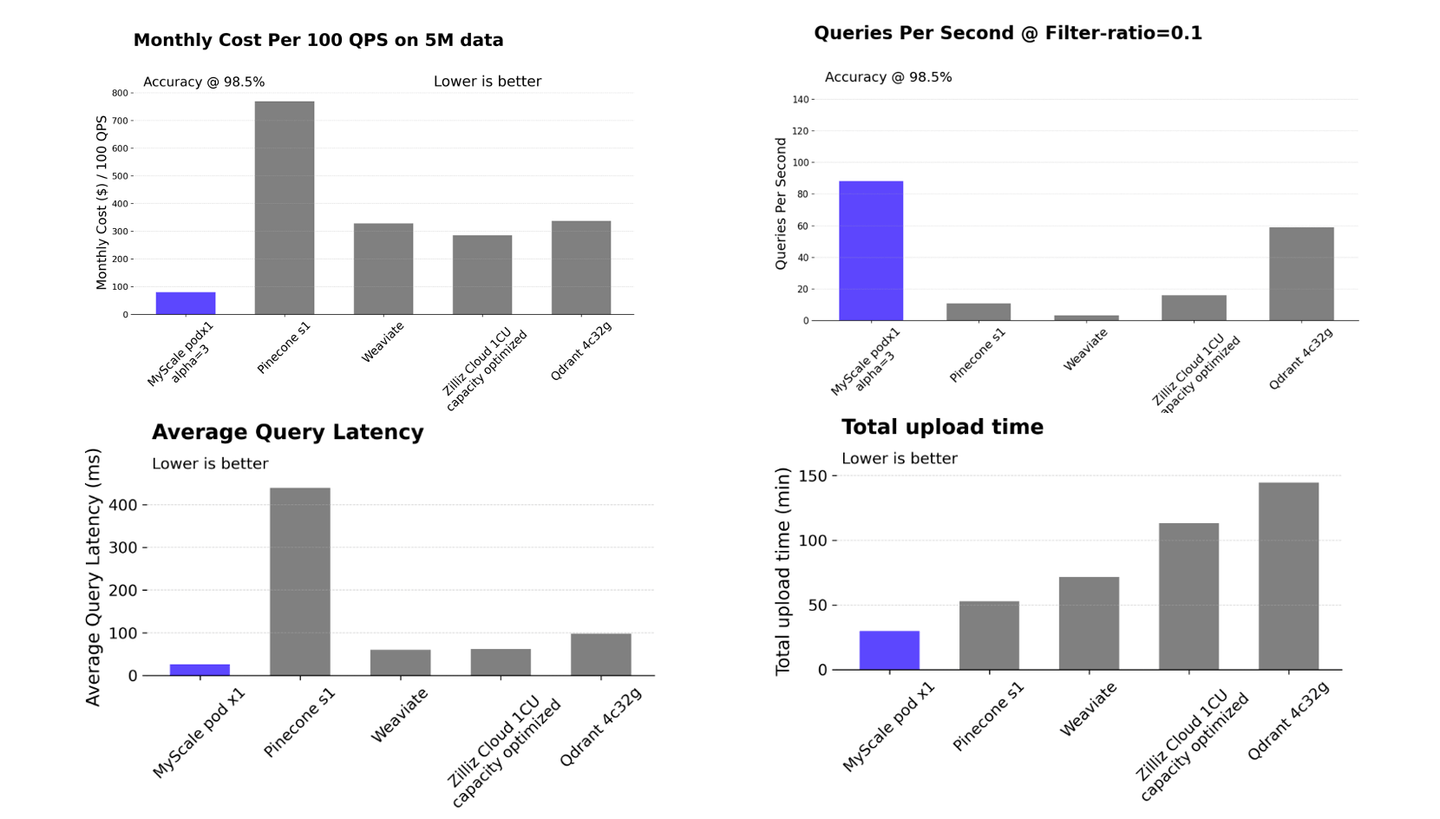
MyScaleDBは、専門のベクトルデータベースよりも高速かつ費用効果が高い (opens new window)です。独自のMSTGインデックスアルゴリズムにより、ベクトルデータの取得を最適化し、システムの効率を向上させています。また、MyScaleDBは、さまざまなフィルタ比率を処理する際のパフォーマンスとスケーラビリティにおいて、ベクトル強化SQL/NoSQLデータベースの中で優れた性能を発揮します。

# 結論
ベクトルの処理のみを行う専門のベクトルデータベースに完全に依存することは、データ管理戦略の柔軟性を制限します。マルチ機能または統合ベクトルデータベースは、より有望な解決策を提供します。MyScaleDBは、ベクトルを効率的に管理するだけでなく、一般的なデータベースとしても機能し、現代のAIアプリケーションの包括的なデータ処理ニーズに対応する柔軟で強力なソリューションとなります。
構造化データとベクトルデータの両方を管理できるデータベースは、今日のAIテクノロジーの世界では重要です。このアプローチにより、複数のシステムを管理する必要がなくなり、スケーラビリティ、柔軟性、費用効率性が確保されます。多目的なデータベースを選択することで、データインフラストラクチャを将来に向けて準備し、現代のアプリケーションの増加する要件に対応することができます。



