
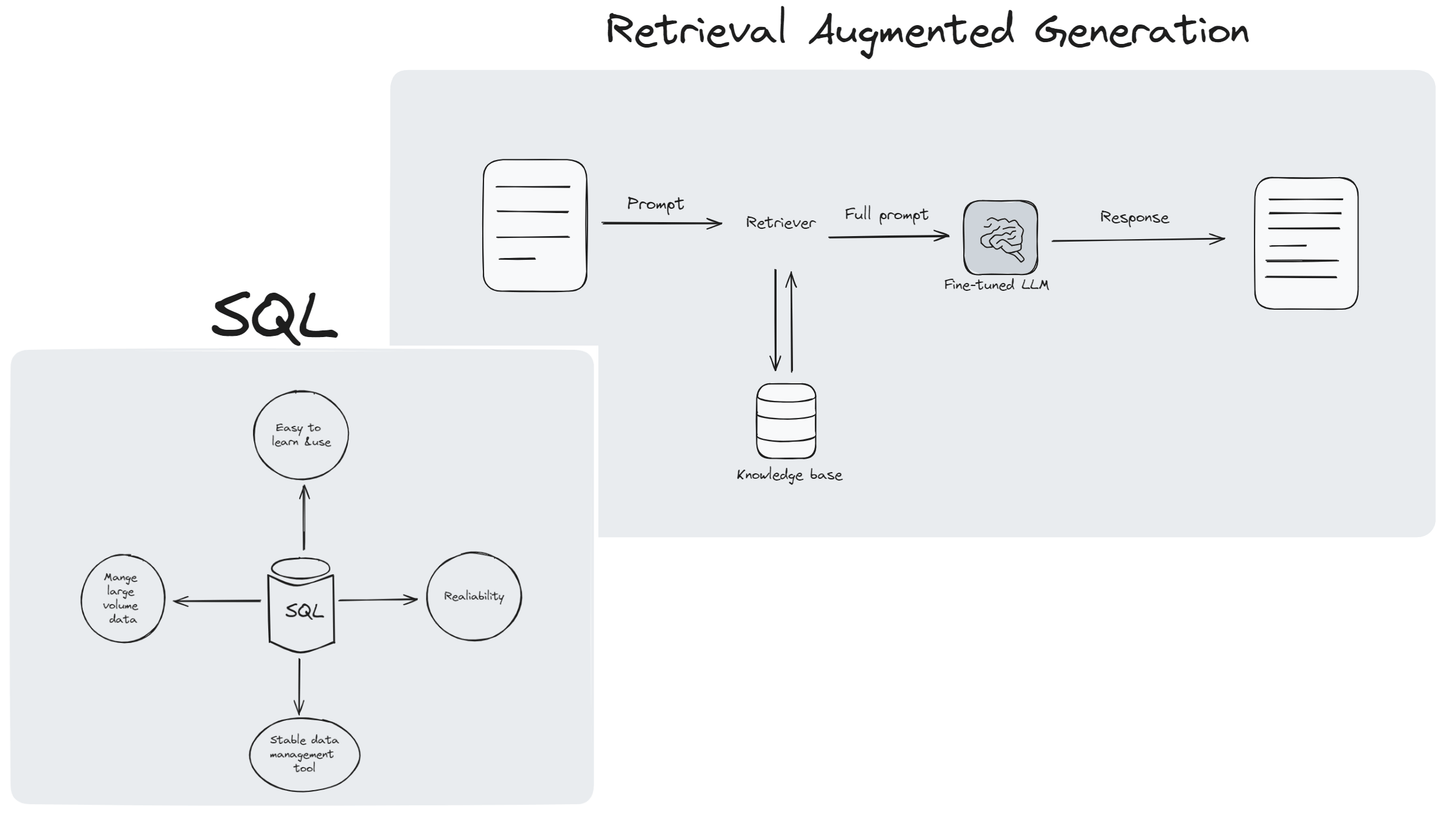
検索補完生成(RAG) (opens new window)は、自然言語処理(NLP)と大規模言語モデル(LLM)の領域で革命的な技術となっています。これは、従来の言語モデルと革新的な検索機構を組み合わせ、言語モデルが広範な知識ベース (opens new window)にアクセスして応答の品質と関連性を向上させることを可能にしています。RAGは、学術研究、顧客サービス、コンテンツ作成など、詳細で最新の情報が必要なシナリオで特に有益です。
RAGは大規模なスケールで使用するとさらに良くなりますが、これにはいくつかの課題もあります。情報が急速に増加するにつれて、RAGは膨大な量の複雑なデータを迅速に整理する必要があります。問題は、システムのサイズを拡張することなく、速度や精度を損なうことなくシステムの効果を向上させることです。RAGは、ベクトルデータとして情報を格納するために特別に設計されたいくつかのベクトルデータベースと共に実装されることが多いです。しかし、これらのデータベースは複雑なクエリの処理に問題を抱えることがあり、複雑な質問の中でシステムの効果を維持することが難しいという課題があります。
# 専門のベクトルデータベースが直面する課題
専門のベクトルデータベースはベクトルデータの処理には適していることは間違いありませんが、それらには独自の問題があります。
- 専門のベクトルデータベースは既存の大規模データシステムと互換性がない
大規模データコレクションに対して多くの企業がSQLデータベースを使用しています。専門のベクトルデータベースへの移行は、データの隔離を引き起こし、他のシステムとの連携が困難になるなど、統合の課題を引き起こす可能性があります。
- 専門のベクトルデータベースは複雑なデータシナリオの処理に苦労する
重要な点として、専門のベクトルデータベースは主に最近傍探索 (opens new window)の実装に特化しています。時間ベースや集計関数 (opens new window)に関連するクエリに直面した場合、問題が発生します。この制限は、このようなクエリが必要なシナリオでは問題を引き起こし、多様なデータ環境での統合と利用をさらに複雑にします。
- 専門のベクトルデータベースは一般の開発者にとって使いやすくありません
また、これらのデータベースは非常に特化しているため、SQLに慣れているデータサイエンティストやエンジニアは学習が難しいと感じるかもしれません。これにより、これらの高度なデータベースの採用が遅れ、利用が制限される可能性があります。さらに、ベクトルデータベースはベクトル化されたデータの処理に優れていますが、多くの業界アプリケーションでまだ主流の構造化および関係データの管理には包括的な機能が不足していることがよくあります。
関連記事: 検索補完生成(RAG)システムの仕組み (opens new window)
# データ管理とストレージにおいてSQLが重要な理由
SQLは長い間、信頼性のあるデータベース管理システムとして知られています。SQLは、効率的なデータのクエリと管理、セキュリティ、およびさまざまな業界での大量のデータの処理能力において優れた性能を発揮します。
# SQLは大量のデータを処理できる
SQLは、大量のデータを効率的にクエリと管理する能力でよく知られています。SQLの強みは、最適化されたクエリエンジンと効率的なデータストレージ構造にあります。SQLデータベースシステムは、通常、高度なインデックス技術とデータパーティショニング戦略を採用しており、大規模な構造化データを扱う場合でも情報の迅速なアクセスと取得を確保します。これにより、ビジネスがスムーズに拡大することができます。
# SQLは信頼性がある
信頼性もSQLの重要な特徴です。データの整合性、堅牢なデータ回復メカニズム、大量のデータと高いレベルの同時トラフィックの処理など、SQLデータベースにはいくつかのキーファクターがあります。SQLデータベースは、インデックス作成、クエリの最適化、キャッシングなどの最適化技術を使用して、効率的なデータの取得と処理を確保し、データベースがサイズと複雑さを増しても信頼性を維持します。
# SQLは高度なデータ処理ツールを提供する
SQLには、データ管理を向上させるための強力なツールと機能があります。開発者は、アプリケーションの独自の要求とパターンに応じてクエリのパフォーマンスを最適化し、向上させる能力を持っています。インデックス作成、パーティショニング、クエリの最適化などの機能により、SQLはデータの取得と処理の効率と速度を大幅に向上させます。これにより、データに依存するアプリケーションが高速に動作し、ユーザーにより良い体験を提供することができます。さらに、SQLには遅延を見つけて修正するための優れたツールもあり、データシステムがさまざまな状況でうまく機能することを保証します。
関連記事: SQLのWHEREとベクトル検索の出会い (opens new window)
# RAGにおいてSQLが重要な理由
検索補完生成(RAG)システムの構築にはいくつかの課題がありますが、SQLはこれらの課題に対処するのに役立ちます。
- SQLは複雑なデータの取得に役立つ
広範で多様なデータセットから関連する情報を取得することは複雑な場合があります。特にテキストドキュメント、画像、マルチメディアなどの非構造化または半構造化データ (opens new window)ソースを扱う場合は、効率的な検索メカニズムを統合することが重要な課題です。SQLのクエリ機能により、これらのデータソースから関連する情報を効率的に取得することができます。特定の基準に合わせてSQLクエリを生成し、高度な検索機能を利用することで、データの取得プロセスを効率化し、多様なデータセットへのアクセスの複雑さに対処することができます。
- SQLは品質の高いデータの取得に役立つ
品質と関連性のあるデータの取得は、正確で意味のある応答を生成するために重要です。ただし、ノイズの多いデータや古いデータ、関連性のない情報は、RAGシステムのパフォーマンスに悪影響を与える可能性があります。効果的にデータをフィルタリングし、ランク付けするためのアルゴリズムを開発することは難しい課題です。SQLは、タイムスタンプ、カテゴリ、または関連性スコアなどのさまざまな基準に基づいてデータをフィルタリングおよびランク付けするためのメカニズムを提供します。さらに、SQLの集計および分析機能により、データの前処理とクリーニングを開発者が行うことができ、生成に使用する前にデータの品質を確保することができます。
- SQLと他の技術の組み合わせによりデータの解釈が向上する*
データの意味と文脈を理解することは、連続したかつ関連性のある応答を生成するために重要です。ただし、曖昧な情報や主観的な情報を扱う場合、自然言語と文脈の微妙なニュアンスを解釈することは複雑なタスクです。SQL自体は意味理解の機能を持っていませんが、キーワードや文脈情報に基づいてデータを取得し、その後、取得したデータの意味をさらに解釈するためにセマンティック分析アルゴリズムなどの他のNLP技術と組み合わせて使用することができます。
- SQLは拡張性と柔軟性を提供する
データセットがサイズと複雑さを増すにつれて、拡張性はRAGシステムにとって重要な課題となります。システムがパフォーマンスと応答性を維持しながらデータのボリュームを増やすことを確保するためには、効率的なアーキテクチャ設計と最適化戦略が必要です。SQLデータベースは、大量の構造化データを効率的に管理するように設計されています。SQLをRAGシステムと統合することで、AI分野における主要な課題の1つである、パフォーマンスを損なうことなく大規模なデータセットを処理するための検索メカニズムのスケーリングを実現します。さらに、SQLのクエリの柔軟性により、RAGは複雑な情報検索を実行し、生成プロセス中に考慮されるデータの範囲と深さを調整することができます。
- SQLはリアルタイムデータの取得に役立つ
チャットボットやバーチャルアシスタントなどのRAGシステムの多くのアプリケーションでは、リアルタイムの応答が重要です。低遅延の応答時間を実現しながら生成コンテンツの品質を維持することは、特にレイテンシの要件が厳しいシナリオでは課題となります。SQLのクエリキャッシュやインデックスなどの最適化技術により、クエリ処理時間を大幅に短縮することができ、RAGシステムはリアルタイムの応答を提供することができます。
関連記事: SQLベクトルデータベースの詳細 (opens new window)

# RAGに最適なSQLベクトルデータベース:MyScaleDB
急速に拡大するデータボリュームと専門のベクトルデータベースが直面する特定の制限を考慮して、私たちはMyScaleDBを開発しました。**MyScaleDB (opens new window)は、AIアプリケーション向けに特別に設計され、最適化されたクラウドベースのSQLベクトルデータベースです。MyScaleDBは、SQLデータベースであるClickHouse (opens new window)**の上に構築されており、ベクトル類似検索の機能と完全なSQLサポートを組み合わせています。ベクトルデータと構造化データを同じデータベースで管理できるSQLベクトルデータベースです。
専門のベクトルデータベースとは異なり、MyScaleDBはベクトル検索アルゴリズムを構造化データベースとシームレスに統合し、ベクトルと構造化データを同じデータベースで管理することができます。この統合により、コミュニケーションの簡素化、柔軟なメタデータのフィルタリング、SQLとベクトルの結合クエリのサポート、および汎用のデータベースで通常使用される確立されたツールとの互換性などの利点が得られます。
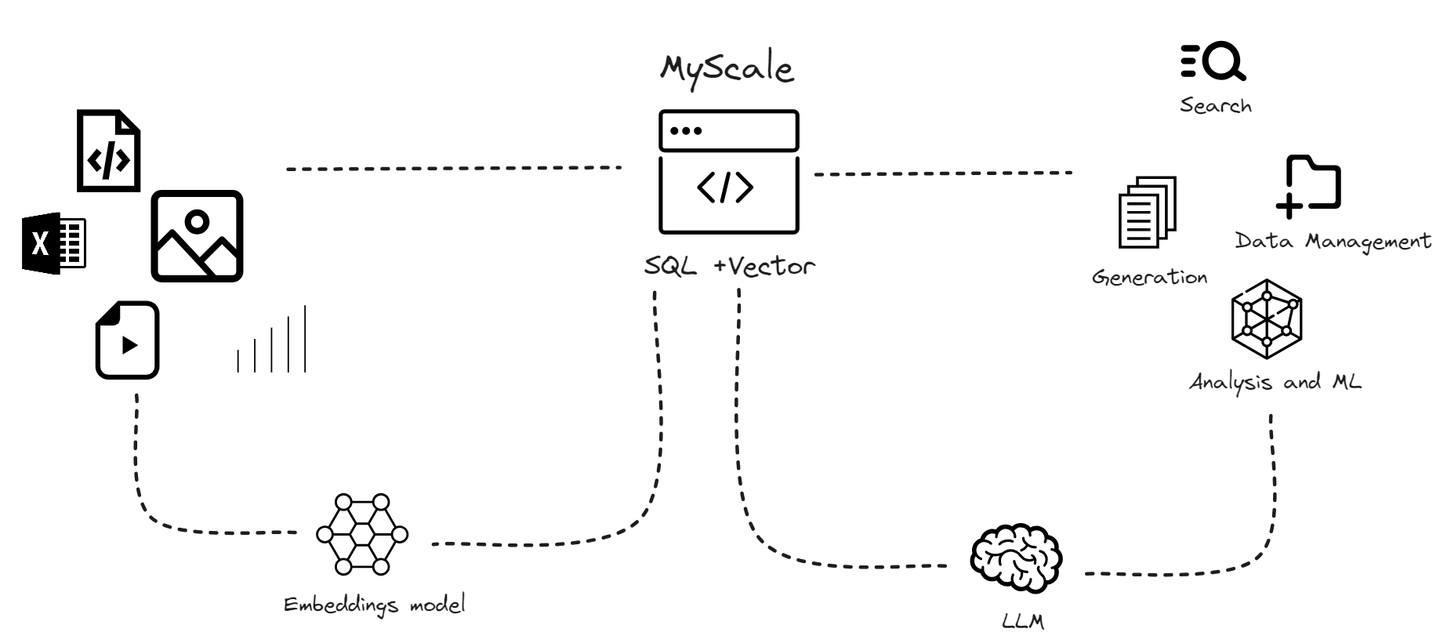
MyScaleDBは、SQLとRAGシステムの統合において優れた性能、互換性、使いやすさを提供します。専門のベクトルデータベースが複雑なクエリや互換性の問題に直面するのに対し、MyScaleDBはRAGシステムの特定のニーズにスムーズに対応するように設計されています。
- まず、MyScaleDBの高度な複雑なSQLクエリのサポートにより、以前は実現不可能だった洗練されたデータの取得操作をRAGシステムが実行できます。この機能により、より関連性が高く文脈に適した応答が可能となり、ユーザーエクスペリエンスが向上します。
- MyScaleDBは、大規模なAIアプリケーション向けに特別に設計されており、高いパフォーマンスとコスト効率を実現しています。完全なSQLサポートを備えたMyScaleDBは、非常に大きなデータセットでも高速性と精度を一貫して維持します。単一のc1x1ポッドは、1000万個の768次元ベクトルをサポートし、s1x1ポッドは500万個のベクトルで150 QPS以上のパフォーマンスを実現します。
- さらに、MyScaleDBは大規模で複雑なデータセットを容易に処理し、従来のベクトルデータベースよりも迅速な応答時間を提供するというパフォーマンスのメリットがあります。
このパフォーマンスの利点により、MyScaleDBは特にスピードが重要なリアルタイムアプリケーションに適しています。MyScaleは、新規ユーザーごとに最大500万個のベクトルの無料ストレージを提供しています。中程度または大規模なアプリケーションのMVPバージョンを簡単に開発することができます。MyScaleDBのホームページ (opens new window)を訪れ、無料アカウントを作成し、2分で無料のポッドを立ち上げることができます。
関連記事: MyScaleの始め方 (opens new window)
# 結論
洗練された知識ベースのアプリケーションの需要が増加するにつれて、SQLと検索補完生成(RAG)システムの統合は重要な開発です。この組み合わせは、専門のベクトルデータベースの拡張性と効率性の問題を解決するだけでなく、SQLの強みと使い慣れた性質を活用し、高度なRAGシステムを開発者にとって使いやすく実用的にします。
MyScaleDBは、この統合の最前線に立っており、優れたパフォーマンス、互換性、使いやすさを提供しています。MyScaleDBを選択することで、開発者や組織はAIアプリケーションの可能性を十分に引き出すことができます。大規模なアプリケーションの構築を計画している場合や、既存の大規模データベース上でアプリケーションを開発する予定がある場合、MyScaleDBは理想的なベクトルデータベースとなるでしょう。
ご意見やご提案がありましたら、Twitter (opens new window)やDiscord (opens new window)でお知らせください。



