
Meta AI has introduced the Llama 3.1 models, which are the most advanced and capable models (opens new window) to date. This blog aims to provide a quick comparison of three variants: Llama 3.1 405B, Llama 3.1 70B, and Llama 3.1 8B. These models offer state-of-the-art performance across various benchmarks and applications.
The Llama 3.1 family includes:
- Llama 3.1 405B (opens new window): The largest open-source model (opens new window) with unparalleled capabilities. When you compare Llama 3.1 405B to the other variants, its superior performance and capabilities stand out, making it a potential game-changer in the AI landscape.
- Llama 3.1 70B (opens new window): A mid-sized model balancing performance and resource efficiency.
- Llama 3.1 8B (opens new window): The smallest variant optimized for specific use cases.
This blog will help readers understand the strengths and applications of each variant, enabling an informed choice for their AI needs.
# Models Overview
# Llama 3.1 405B
The Llama 3.1 405B model is the flagship of the Llama 3.1 series, standing out as the largest and most powerful variant in Meta's collection of AI models. Built on a dense transformer architecture, this model leverages a vast 128K context window, allowing it to handle large volumes of data and maintain contextual awareness over extended inputs. This feature is particularly advantageous for tasks involving long-form content, such as detailed text summarization and complex conversational AI, where maintaining context is crucial.
Llama 3.1 405B is designed with advanced functionalities that enhance its versatility across various applications. Among these are synthetic data generation, which allows the model to create large datasets that can be used to train other models or augment existing datasets, and model distillation, a process where the knowledge from the large 405B model can be transferred to smaller models, making high-level AI capabilities more accessible across different platforms.
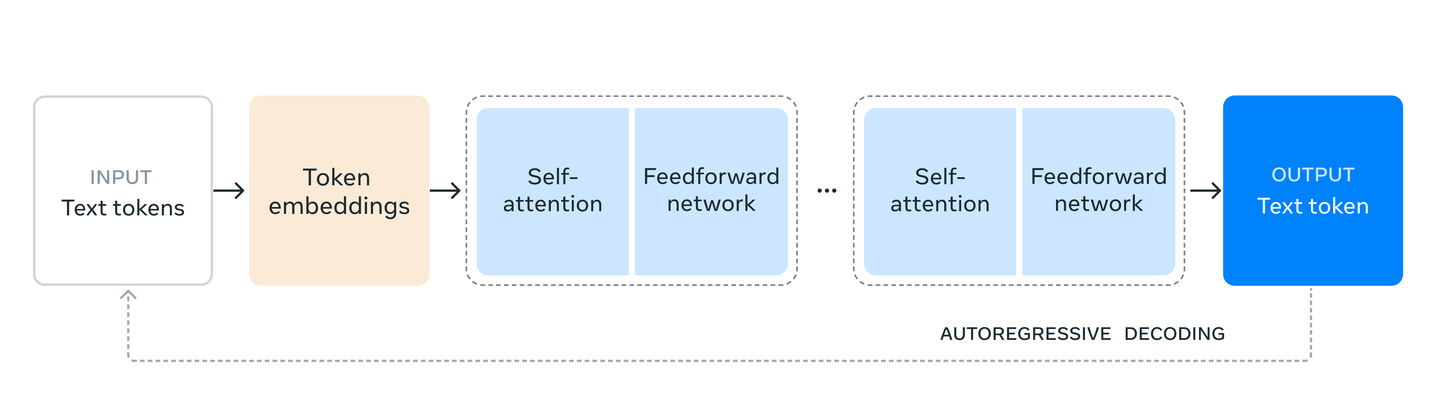
The model’s architecture has been optimized through a multi-phase training process, which includes extensive pre-training on trillions of tokens, followed by rounds of supervised fine-tuning and direct preference optimization. These steps ensure the model's outputs are both accurate and aligned with human preferences, making it a robust tool for a wide array of tasks.

All the models in the Llama 3.1 series supports zero-shot tool use for web search, math and code execution. The model can intelligently determine which tool to use based on the task at hand and can interpret the results from these tools effectively.
# Llama 3.1 70B
The Llama 3.1 70B model is designed to strike a fine balance between high performance and resource efficiency. As a mid-sized option in the Llama 3.1 series, it features 70 billion parameters, making it powerful enough for a wide range of tasks while still being more accessible in terms of computational requirements compared to larger models like the 405B.
This model retains the dense transformer architecture and supports advanced features such as tool use training, enabling it to effectively manage tasks like code execution, search, and complex reasoning. It also includes a 128K token context window, making it well-suited for processing extended inputs, such as lengthy documents or comprehensive conversations.
# Use Cases
The Llama 3.1 70B is ideal for environments where maintaining a balance between computational demands and performance is essential. Educational institutions, for example, can utilize this model for research projects that require significant, yet manageable, computational power, making it a suitable choice for academic research, data analysis, and other similar tasks.
Businesses that focus on medium-scale AI applications will also find the Llama 3.1 70B to be an excellent choice due to its efficient performance and cost-effectiveness. It is particularly useful for industries that require scalable AI solutions without the need for extensive infrastructure, such as customer service automation, where its advanced natural language understanding capabilities can enhance user interactions across various languages.
# Llama 3.1 8B
The Llama 3.1 8B model is the smallest and most resource-efficient variant in the Llama 3.1 series, tailored for specific use cases where computational resources are limited, yet reliable performance remains essential. With its 8 billion parameters, this model retains crucial functionalities like tool use training while significantly reducing computational overhead compared to its larger counterparts. It also comes with a contextual window of 128K tokens, allowing it to maintain context over long passages of text, making it ideal for tasks that require processing large amounts of information in a single session.
The Llama 3.1 8B model is perfect for scenarios where a lightweight yet capable AI model is necessary. It excels in use cases such as developing AI solutions for startups, where budget constraints and limited infrastructure are common challenges. Despite its smaller size, Llama 3.1 8B can handle various tasks, including content generation, summarization, and even some aspects of natural language understanding and translation. Its adaptability allows it to be fine-tuned for specific tasks, making it a versatile tool across different industries.
Moreover, this model is particularly advantageous for small to medium-sized businesses needing to integrate AI into their existing workflows without incurring significant costs. Whether it’s for customer service automation, sentiment analysis, or other specific AI-driven applications, Llama 3.1 8B offers a practical solution that balances capability with efficiency.
# Performance Benchmarks of Llama
# Llama 3.1 405B (opens new window) Benchmark Results
The Llama 3.1 405B model showcases outstanding performance across a broad range of industry benchmarks, rivaling even some of the most advanced models like GPT-4. Meta AI conducted extensive testing on over 150 datasets, demonstrating the model's superiority in multilingual tasks, complex reasoning, and advanced tool use. The dense transformer architecture of Llama 3.1 405B enables it to handle large volumes of data with remarkable efficiency, making it particularly strong in tasks like mathematical problem-solving, code generation, and logical reasoning.
In specific benchmarks, the Llama 3.1 405B has shown impressive results:
- Mathematical Reasoning: The model excels in tasks like GSM8K and MATH benchmarks, scoring significantly higher than other models in the series and even outperforming GPT-4 in some tests.
- Tool Use: The 405B model's capabilities in tool use are among the best, with high scores in benchmarks designed to evaluate the integration of external tools like code interpreters and search engines.
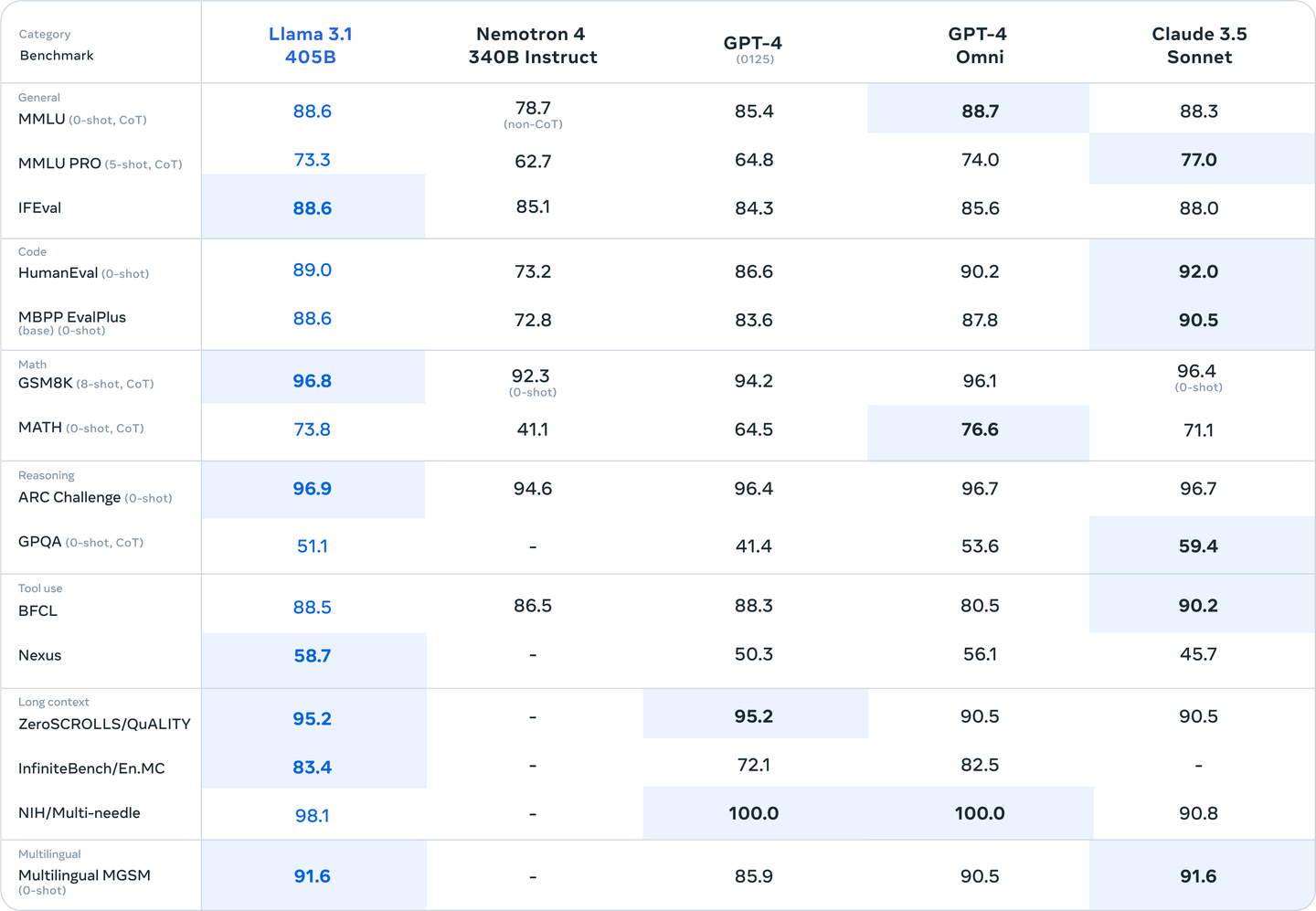
"The compare Llama 3.1 405B variant outperforms many available models on industry benchmarks," according to Meta AI's findings.
# Human-Guided Evaluations
Human evaluations further emphasize the strengths of the Llama 3.1 405B model. In real-world scenarios, experts have found that this model excels in handling intricate problem-solving tasks and large-scale data analysis. The 405B variant consistently provides accurate and detailed responses, making it an invaluable tool for research institutions and industries focused on advanced AI development.
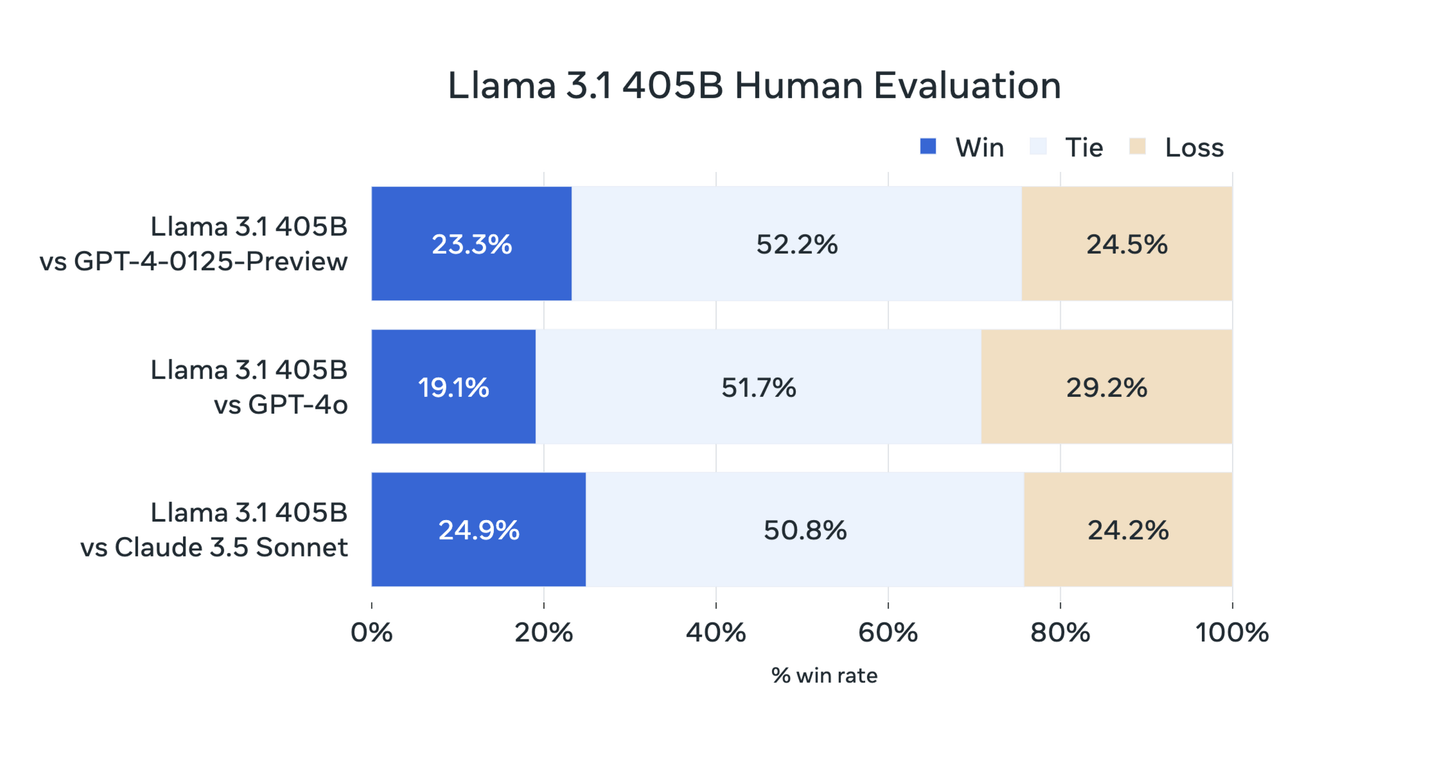
These evaluations reveal that Llama 3.1 405B is particularly well-suited for applications requiring deep reasoning and complex decision-making processes, proving to be a powerful asset in domains such as education, healthcare, and technical fields where precision is critical
# Llama 3.1 70B and 8B Benchmark Results
The Llama 3.1 70B and 8B models are designed to meet the diverse needs of AI applications, with each model offering unique strengths that make them suitable for different scenarios.
# Performance Overview
Llama 3.1 70B delivers a strong balance between performance and resource efficiency, making it highly effective across a wide range of benchmarks. It excels particularly in tasks involving complex reasoning, language understanding, and code generation. The model has demonstrated exceptional performance in multilingual benchmarks as well, reflecting its capacity to handle tasks that require understanding and generating content in multiple languages.
- MMLU (0-shot, CoT): 86.0
- HumanEval (0-shot): 80.5
- GSM8K (8-shot, CoT): 95.1
- ARC Challenge (0-shot): 94.8
These results show that Llama 3.1 70B is well-suited for use in educational research, customer service automation, and other medium-scale AI applications where both power and efficiency are critical.
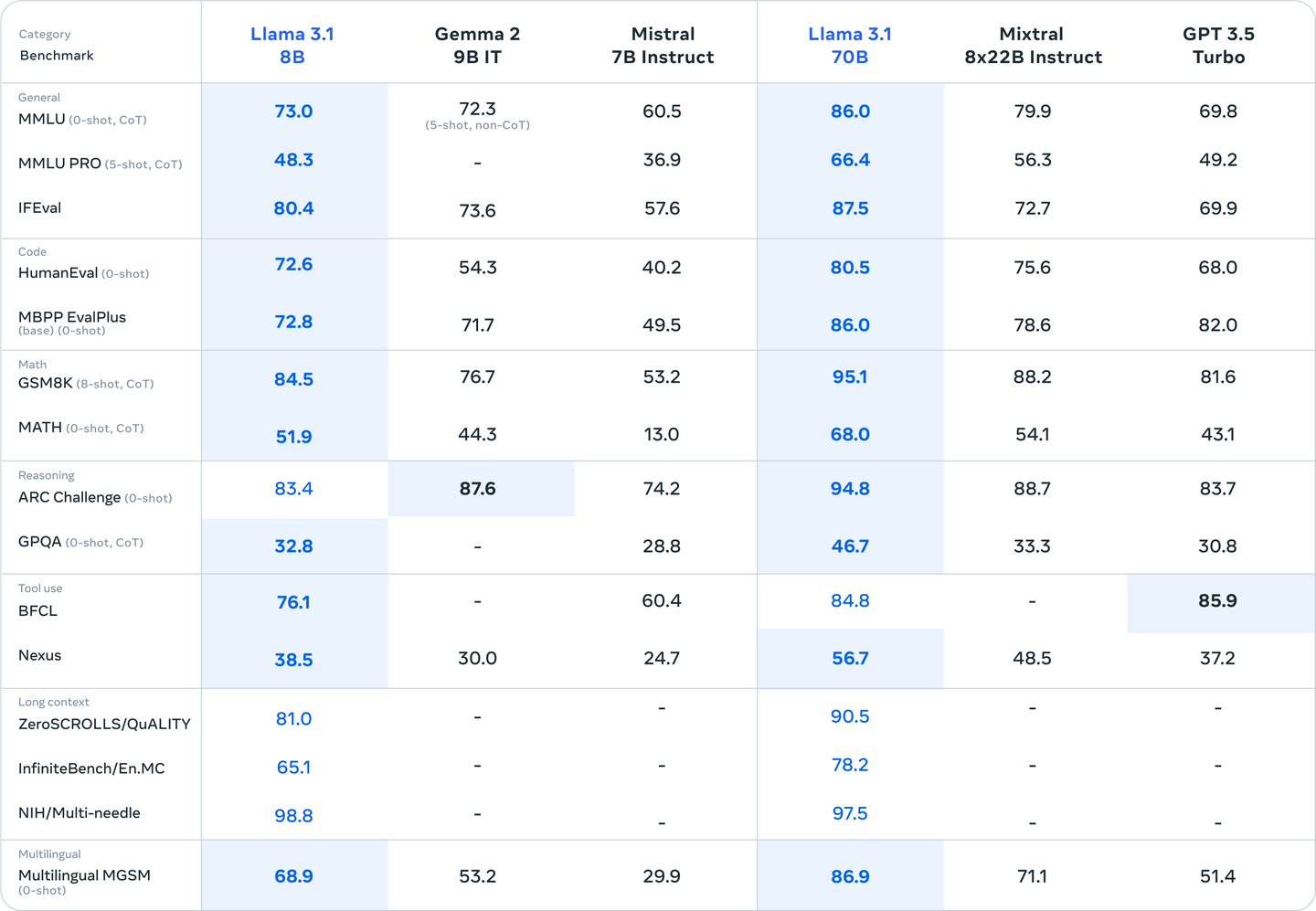
On the other hand, Llama 3.1 8B is optimized for scenarios requiring lower computational overhead without sacrificing too much on performance. Despite being the smallest model in the Llama 3.1 family, it still achieves competitive scores in several important benchmarks:
- MMLU (0-shot, CoT): 73.0
- HumanEval (0-shot): 72.6
- GSM8K (8-shot, CoT): 84.5
- ARC Challenge (0-shot): 83.4
These benchmarks highlight Llama 3.1 8B as an ideal solution for startups, small businesses, or mobile applications where efficiency is a priority but robust performance is still required.
# Deployment and Pricing
# Single-Node Fine-Tuning
The Llama 3.1 models, particularly the 405B model, have been optimized to allow for effective single-node fine-tuning, making them highly versatile for a range of specialized applications. This optimization is achieved through advanced techniques such as FP8 quantization and targeted sharding, which significantly reduce the memory footprint and computational requirements. For instance, FP8 quantization compresses the model weights, allowing the 405B model to run on a single high-end GPU node, such as those with H100 or H200 GPUs, without sacrificing performance or accuracy. These optimizations enable researchers and developers to fine-tune the model on a single node with minimal computational overhead, making it feasible to adapt the model for specific tasks even with limited resources
# Low-Latency Inference
The Llama 3.1 series is designed to deliver low-latency inference, crucial for real-time applications like chatbots, virtual assistants, and live data processing. The 405B model, in particular, has been enhanced with TensorRT optimizations, which improve both latency and throughput. These optimizations include FP8 quantization and INT4 Activation-Aware Weight Quantization (AWQ), which significantly reduce the model’s computational load while maintaining high accuracy. As a result, the model can achieve up to 3x lower latency and 1.4x higher throughput compared to baseline performance. These improvements make the Llama 3.1 models exceptionally well-suited for handling high-throughput scenarios while maintaining rapid response times, ensuring smooth and efficient operation even under demanding conditions.
# Pricing Considerations
# Cost
The deployment costs of Llama 3.1 models vary significantly depending on the model variant and the scale of application. The 405B model, with its extensive parameter count and advanced capabilities, incurs higher costs due to its substantial computational resource requirements. This model is best suited for enterprises and large-scale projects where its superior performance can justify the investment. For instance, hosting and inference for the 405B model can cost between $200 to $250 per month, reflecting its high-performance benchmarks in tasks requiring complex reasoning and large-scale data processing.
On the other hand, the 70B and 8B models offer more cost-effective solutions while still delivering robust performance. The 70B model provides a balance between computational efficiency and capability, making it suitable for medium-sized organizations or research institutions. It costs approximately $0.90 per 1 million tokens processed, offering a good trade-off between performance and expense. The 8B model is the most economical, designed for applications with tighter budget constraints, and can potentially be deployed on consumer-grade GPUs with appropriate optimizations, making it ideal for startups or individual developers
# Value Proposition
Despite the higher costs, the 405B model offers unmatched value in terms of performance, particularly in tasks requiring deep reasoning and high precision. It is an invaluable asset for industries focused on advanced AI development, capable of handling complex tasks that smaller models might struggle with.
For those looking for a balance between cost and performance, the 70B and 8B models are more accessible options. They are particularly effective in medium-scale applications where budget constraints exist, but high performance is still required.
Amazon SageMaker provides a flexible and efficient platform for deploying these models, supporting integration with existing workflows, meeting stringent accuracy and latency requirements, and offering fine-grained control over deployment settings. Additionally, Amazon Bedrock offers a range of deployment options across different AWS regions, allowing users to select the most appropriate environment for their specific needs
# Optimizing AI Fine-Tuning with RAG and MyScaleDB
Deploying and fine-tuning large-scale models like the Llama 3.1 series demands vast amounts of data and significant computational power. This level of resource requirement makes it impractical to regularly fine-tune these models for every specific use case, as is often necessary with smaller models. Retrieval-Augmented Generation (RAG) (opens new window) offers a practical alternative by enhancing model outputs with real-time data retrieval, which reduces the need for frequent fine-tuning. However, while RAG helps improve accuracy and relevance, it doesn't necessarily lower the overall computational demands; it just shifts some of the workload to the retrieval process.
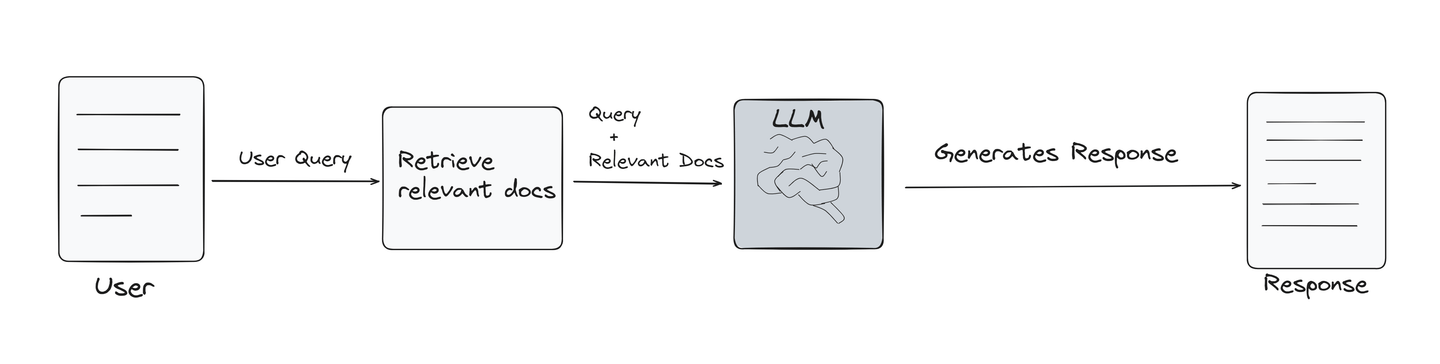
MyScaleDB (opens new window) is key in optimizing RAG systems by combining vector search with traditional SQL databases. This allows developers to manage large-scale vector and structured data efficiently within a single platform. MyScaleDB enables more effective data management for RAG applications, helping to maintain high performance in advanced AI models like Llama 3.1, even though the computational power needed for the entire process remains substantial.
# Conclusion
The Llama 3.1 series, including the 405B, 70B, and 8B variants, showcases Meta AI's commitment to advancing AI technology. Each model offers distinct advantages tailored to different applications.
- The 405B model excels in complex tasks requiring extensive data processing and detailed analysis.
- The 70B model balances performance with resource efficiency.
- The 8B model suits specific use cases demanding lower computational overheads.
Meta AI's advancements in low-latency inference and single-node fine-tuning enhance these models' versatility. Future developments could focus on improving real-time capabilities and optimizing resource usage further.Meta AI has introduced the Llama 3.1 models, which are the most advanced and capable models (opens new window) to date. This blog aims to provide a quick comparison of three variants: Llama 3.1 405B, Llama 3.1 70B, and Llama 3.1 8B. These models offer state-of-the-art performance across various benchmarks and applications.
# See Also
Exploring Limitations of BM25: An Analysis Comparison (opens new window)
Comparing Gemma3 and Llama3: The AI Model Faceoff (opens new window)
Snowflake Arctic vs. Llama3: The Definitive Enterprise AI Battle (opens new window)
5 New Features of Mistral 7B Instruct v0.3 Revealed (opens new window)
Comparing Pinecone and Weaviate: Exploring Functionality (opens new window)