
In this post, we compare MyScale, an integrated vector database that offers full SQL support, with two traditional databases: PostgreSQL and OpenSearch. Both databases have recently added vector similarity search to their toolboxes.
Note:
We continuously update the benchmark results for MyScale and other vector database products in our open-source project, vector-db-benchmark (opens new window).
The advent of Large Language Models (LLMs) has increased interest in integrating conversational interfaces into various applications, such as search engines, code generators, and data analysis tools. Vector similarity search is a key technology that enables this, playing a vital role in boosting LLMs performance through Retrieval-Augmented Generation (RAG) (opens new window).
There is a wide array of vector database products on the market; some are specialized vector databases explicitly designed for vector indexes, while others are integrated vector databases or general-purpose databases extended to support vector search.
Moreover, integrated vector databases have several distinct advantages specialized vector databases, including:
- They store vectors and structured data in the same database, facilitating more complex filtered searches as well as sql and vector joint queries.
- They utilize powerful and widely used query languages like SQL for structured and vector data analysis.
- They leverage mature tools and integrations of general-purpose databases.
- They reduce additional labor costs for specialized skills and licensing costs of specialized databases.
The three integrated vector databases we are comparing line up as follows:
- MyScale is an integrated vector database developed on top of ClickHouse, combining the capacity for vector similarity search with full SQL support;
- PostgreSQL provides vector search support through its pgvector (opens new window) extension; and
- OpenSearch incorporates neural (vector) search in version 2.9.0 (opens new window).
As described below, our comprehensive benchmark evaluation reveals that MyScale exceeds other products in terms of filtered vector search accuracy, performance, cost-efficiency, and index build time by a long way. Importantly, MyScale is the only product tested that delivers healthy search accuracy and QPS across various filter ratios.
Morever, MyScale also outperforms specialized vector databases, see this post (opens new window) and our open-source benchmark (opens new window) for more details. As shown in the figure below, combination of full-SQL support with high vector search performance makes MyScale a compelling choice for managing your AI/LLM related data, both structured and vectorized:
# Benchmark Setup
We carried out benchmarks on MyScale, OpenSearch, and two Postgres vector search extensions. The specifics are provided below.
| Database | Pod Type | Monthly Cost (USD) | Notes |
|---|---|---|---|
| MyScale (opens new window) | Pod Size: x1 | 120 | Currently free for the development tier (opens new window). |
| Postgres with pgvector (opens new window) | db.r6g.xlarge (opens new window) (4C 32GB) | 329 | Amazon RDS for PostgreSQL |
| Postgres with pgvecto.rs (opens new window) | db.r6g.xlarge (opens new window) (4C 32GB) | 329 | Amazon RDS for PostgreSQL |
| AWS OpenSearch Service (opens new window) | r6g.2xlarge.search (opens new window) (8C 64GB) | 488 | Amazon OpenSearch Service domain |
We utilized 5 million 768-dimensional vectors, generated from the LAION 2B images (opens new window) dataset, for both vector search and filtered vector search tests.
Note:
The complete code, datasets, and results are on our benchmark page (opens new window).
We chose the smallest pod type for each database capable of hosting all the vectors.
As the latest versions of pgvector and pgvector.rs have yet to be widely adopted by any PostgreSQL cloud services, we opted for self-hosting when running our benchmarks. However, we've included the pricing for Amazon RDS for PostgreSQL in the table above for comparison purposes.
Note:
PostgresSQL cloud services like Supabase (opens new window) and TimeScaleDB (opens new window) may cost more for similar hardware configurations.
For OpenSearch, we selected the r6g.2xlarge.search (64GB memory) as we encountered issues when trying to build the vector index on an r6g.xlarge.search (32GB memory) instance. As the summary shows, MyScale remains the most cost-effective integrated vector database.
# Benchmark Results
We've summarized our findings below:
# Vector Search
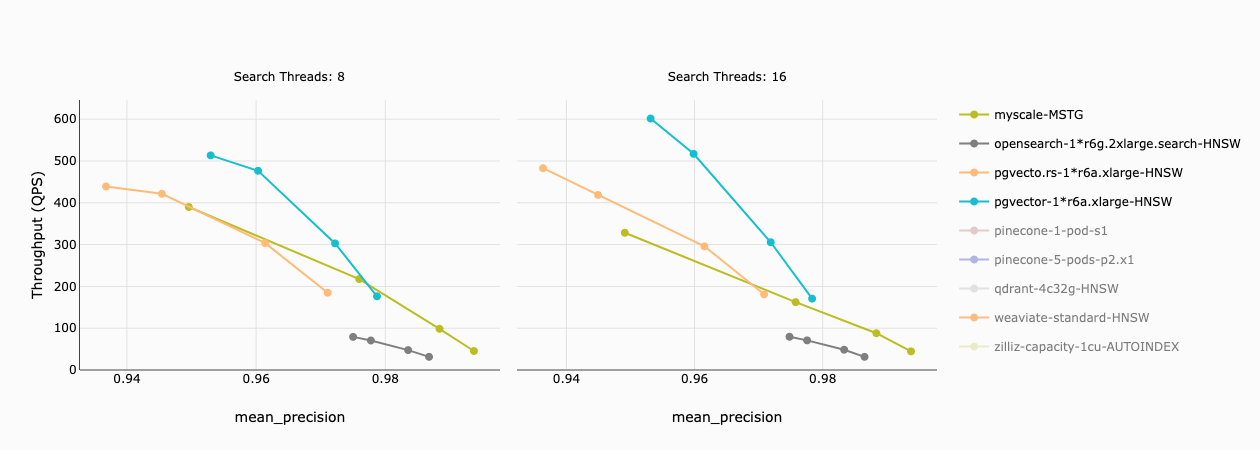
In the graph below, the x-axis represents precision, and the y-axis represents throughput (QPS) for each vector database. We found the following:
- MyScale and the two Postgres extensions have similar throughput at a precision of 97%;
- pgvector and pgvecto.rs can achieve higher throughput at lower precisions but incur significantly higher costs than MyScale; and
- OpenSearch lagged behind the others in speed for all precisions.
# Filtered Vector Search
In real-world scenarios, pure vector search is rarely sufficient. Vectors usually come with metadata, and users often need to apply one or more filters to this metadata.
The following graph describes MyScale's (and other integrated vector databases') throughput on a dataset with a filter ratio of 1%. A filter ratio of 1% implies that 50K vectors (1% x 5M vectors) remain after the filter condition is applied
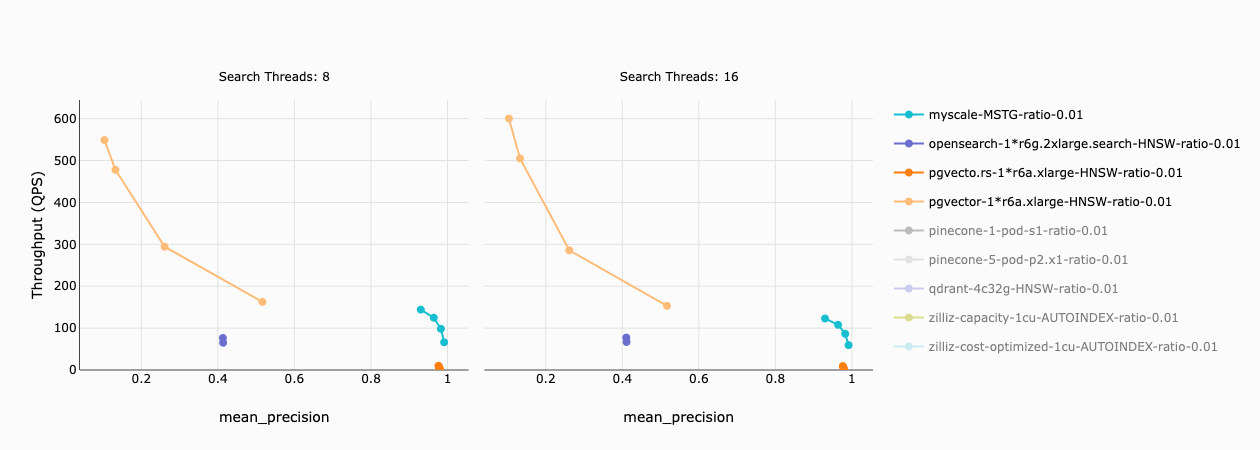
Our findings revealed the following information:
- The precision of pgvector and OpenSearch is low (less than 50%) and almost unusable in practice.
- The throughput of pgvecto.rs is relatively low (less than 10 QPS).
- Only MyScale maintains healthy throughput (66 - 144 QPS) and precision (93% - 99%).
There are two main approaches when implementing filtered vector searches in these databases.
# Post-Filtering
This method is where a vector search is conducted first, followed by removing results that do not match the filter. Unfortunately, there are two significant disadvantages to using this method:
- Firstly, the number of elements in the search is unpredictable, as the filter is applied to an already reduced list of candidates.
- Secondly, if the filter is very restrictive, i.e., it matches only a small percentage of data points relative to the dataset's size, there's a chance that the original vector search does not contain any matches at all.
# Pre-Filtering
The low precisions of pgvector and OpenSearch are attributable to their use of post-filtering. Juxtapositionally, MyScale, and pgvector.rs use a different approach known as pre-filtering. The filter is applied first, and a bitmap is passed to the vector index to perform the vector search.
During our benchmark, the HNSW algorithm used by pgvector.rs performed poorly when the filter ratio was low. Moreover, PostgreSQL's row-based storage is not friendly to the large-scale scanning operation required in pre-filtering, which further exacerbated the suboptimal performance. MyScale, on the other hand, overcomes this issue by combining ClickHouse's fast columnar SQL execution engine (opens new window) and our proprietary MSTG vector index algorithm (opens new window).
# Evaluating Cost-Effectiveness: Pure Vector Search vs. Filtered Vector Search
When selecting a database, one must not only consider raw performance but also the value derived from the investment. Cost-effectiveness, especially at higher precision levels like 95%, becomes a pivotal criterion for businesses running extensive vector searches.
# Pure Vector Search
For a clear insight into cost-effectiveness, we’ve derived the cost-per-performance of each database by examining their monthly cost in relation to the Queries per Second (QPS) they can achieve at approximately 95% precision, providing an indication of the cost per 100 QPS for each database.
As the following results indicate, MyScale offers exceptional cost-efficiency, outpacing its closest competitor by a factor of at least 1.8x.
| Database | Monthly Cost (USD) Per 100 QPS |
|---|---|
| MyScale | 30 |
| pgvector | 54 |
| pgvecto.rs | 79 |
| OpenSearch | 613 |
# Filtered Vector Search with 1% Filter Ratio
However, many real-world scenarios demand more than pure vector searches. Filtering is often applied to datasets, narrowing down results. When we evaluate cost-effectiveness for a filtered vector search with a 1% filter ratio, the landscape changes. Notably, pgvector and OpenSearch could not achieve a precision higher than 50%. This low accuray is unusable in most cases, marking them as N/A in this analysis.
| Database | Monthly Cost (USD) Per 100 QPS |
|---|---|
| MyScale | 96 |
| pgvector | N/A |
| pgvecto.rs | 3290 |
| OpenSearch | N/A |
In conclusion, while MyScale remains the front-runner in pure vector searches, its dominance is even more pronounced in filtered vector searches. Offering top-tier performance at a fraction of the cost, MyScale guarantees businesses optimal returns on their investment. This amalgamation of high precision, cost efficiency, and performance makes MyScale a standout choice for organizations seeking to leverage integrated vector databases effectively.
# Index Build Time
After inserting vectors into a vector database, users must create a vector index before performing vector searches. The time taken to build the index is crucial for fast search results, with the build times for the four different vector databases described in the following table:
| Database | Upload & Build Time |
|---|---|
| MyScale | 32 min |
| Pgvector | 10.9 hours |
| Pgvecto.rs | 80 min |
| OpenSearch | 45 min |
These results show that MyScale is the clear leader with the fastest build time, while pgvector was extremely slow in building the HNSW vector index due to the lack of parallel build support. Fast index building is critical when the application requires inserting and updating a lot of vectors (such as large scale online chat, document editing, etc.), and also reduces resouce contention between index building and vector search.
# Conclusion
After an exhaustive analysis, MyScale consistently surpasses its competitors, showcasing superior performance in filtered vector search and swift index building time. Among all the products tested, MyScale is the only integrated vector database that delivers high search accuracy and QPS across various filter ratios. What distinguishes MyScale from other products as well is its outstanding cost-effectiveness, making it a robust, integrated vector database option and a financially wise choice. For organizations aiming to tap into the capabilities of integrated vector databases, MyScale emerges as a top contender due to its unbeatable combination of performance, precision, and value for money.

# Further Exploration
For a deeper understanding of how MyScale matches up to specialized vector databases in terms of performance, we recommend reading this post (opens new window).
And, for those considering migrating their vector data from PostgreSQL to MyScale, this guide (opens new window) provides invaluable insights and step-by-step instructions.



