
Since the release of Large Language Models (LLMs) and advanced chat models, various techniques have been used to extract the desired outputs from these AI systems. Some of these methods involve altering the model's behavior to better align with our expectations, while others focus on enhancing how we query the LLMs to extract more precise and relevant information.
Techniques like Retrieval Augmented Generation(RAG) (opens new window), Prompting (opens new window), and fine-tuning (opens new window) are the most widely used ones. On MyScale, we have already discussed techniques like RAG (opens new window) and fine-tuning in detail. In fine-tuning, we have discussed two techniques, fine-tuning using openai (opens new window) and fine-tuning using hugging face (opens new window).
Note:
If you haven't read our RAG and fine-tuning blogs, we highly recommend you to read them first before starting this.
Today's discussion is a little bit different. We're moving from exploration to comparison. We'll look at the pros and cons of each technique. This is important because it will help you to understand when and how to use these techniques effectively. So let's start our comparison and see what makes each method unique.
# Prompt Engineering
Prompting is the most basic way to interact with any Large Language Model. It is like giving instructions. When you use a prompt (opens new window), you're telling the model what kind of information you want it to give you. This is also known as prompt engineering. It's a bit like learning how to ask the right questions to get the best answers. But there's a limit to how much you can get from it. This is because the model can only give back what it already knows from its training (opens new window).
The thing about prompt engineering is that it's pretty straightforward. You don't need to be a tech expert to do it, which is great for most people. But since it depends a lot on the model's original learning, it might not always give you the newest or most specific information you need. It's best when you're working with general topics or when you just need a quick answer without getting into too many details.
# Pros:
- Ease of Use: Prompting is user-friendly and doesn't require advanced technical skills, making it accessible to a broad audience.
- Cost-Effectiveness: Since it utilizes pre-trained models (opens new window), there are minimal computational costs involved compared to fine-tuning.
- Flexibility: Prompts can be quickly adjusted to explore different outputs without the need for retraining the model.
# Cons
- Inconsistency: The quality and relevance of the model's responses can vary significantly based on the phrasing of the prompt.
- Limited Customization: The ability to tailor the model's responses is restricted to the creativity and skill in crafting effective prompts.
- Dependence on Model's Knowledge: The outputs are limited to what the model has learned during its initial training, making it less effective for highly specialized or up-to-date information.
# Fine-tuning
Fine-tuning is when you take the language model and make it learn something new or special. Think of it like updating an app on your phone to get better features. But in this case, the app (the model) needs a lot of new information and time to learn everything properly. It's a bit like going back to school for the model.
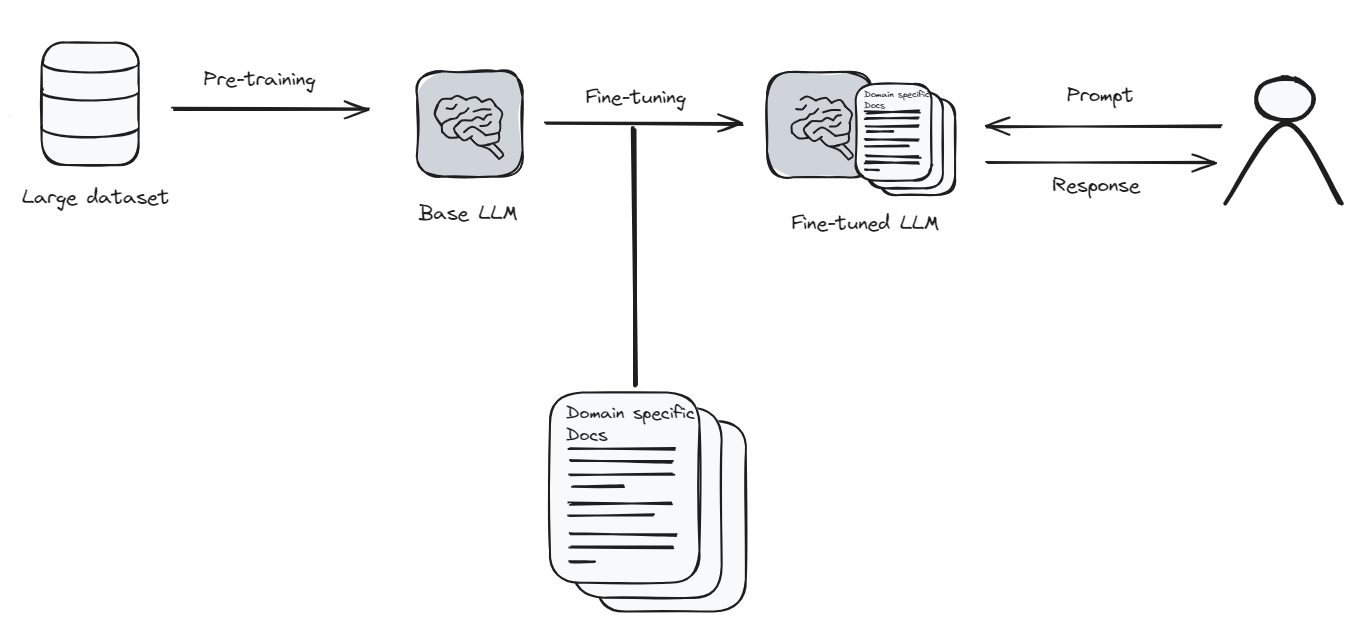
Because fine-tuning needs a lot of computer power and time, it can be expensive. But if you need your language model to understand a specific topic very well, then fine-tuning is worth it. It's like teaching the model to become an expert in what you're interested in. After fine-tuning, the model can give you answers that are more accurate and closer to what you're looking for.
# Pros:
- Customization: Allows for extensive customization, enabling the model to generate responses tailored to specific domains or styles.
- Improved Accuracy: By training on a specialized dataset, the model can produce more accurate and relevant responses.
- Adaptability: Finetuned models can better handle niche topics or recent information not covered in the original training
# Cons:
- Cost: fine-tuning requires significant computational resources, making it more expensive than prompting.
- Technical Skills: This approach necessitates a deeper understanding of machine learning (opens new window) and language model architectures (opens new window).
- Data Requirements: Effective fine-tuning requires a substantial and well-curated dataset, which can be challenging to compile.
Related Articles: How to build a recommendation system (opens new window)
# Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation, or RAG, mixes the usual language model stuff with something like a knowledge base (opens new window). When the model needs to answer a question, it first looks up and collects relevant information from a knowledge base, and then answers the question based on that information. It's like the model does a quick check of a library of information to make sure it gives you the best answer.
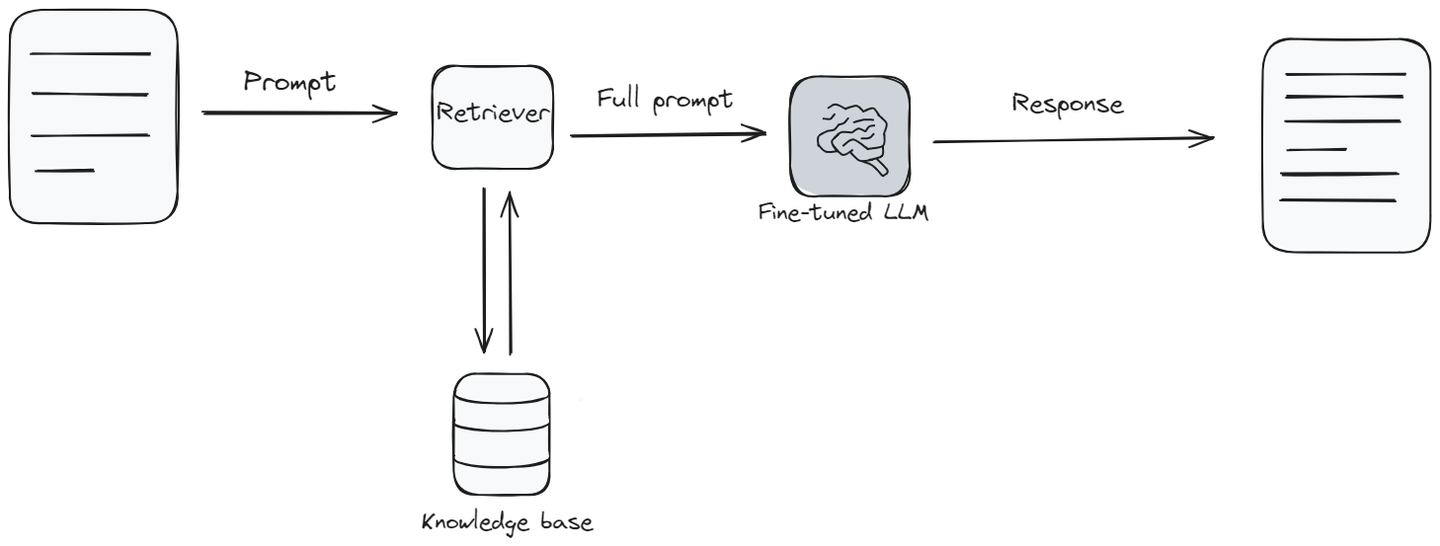
RAG (opens new window) is especially useful in situations where you need the latest information or answers that involve a wider range of topics than what the model learned originally. It’s kind of in the middle when it comes to how hard it is to set up and how much it costs. It's great because it helps the language model give answers that are fresh and have more detail. But, like fine-tuning, it needs extra tools and information to work well.
The cost, speed, and response quality of your RAG system heavily rely on the vector database, making it a very important part of the RAG system. MyScale (opens new window) is such a vector database that not only charges almost half compared to other vector databases but also offers 3x better performance. You can see the benchmark (opens new window) here. Most importantly, you don’t need to learn any external tools or languages to access MyScale, you can access it through simple SQL syntax that makes it a perfect choice for developers.
# Pros:
- Dynamic Information: By leveraging external data sources, RAG can provide up-to-date and highly relevant information.
- Balance: Offers a middle ground between the ease of prompting and the customization of fine-tuning.
- Contextual Relevance: Enhances the model's responses with additional context, leading to more informed and nuanced outputs.
# Cons:
- Complexity: Implementing RAG can be complex, requiring integration between the language model and the retrieval system.
- Resource Intensive: While less resource-intensive than full fine-tuning, RAG still demands considerable computational power.
- Data Dependency: The quality of the output heavily relies on the relevance and accuracy of the retrieved information
# Prompting vs Fine-tuning vs RAG
Let's now look at a side-by-side comparison of Prompting, fine-tuning, and Retrieval Augmented Generation (RAG). This table will help you see the differences and decide which method might be best for what you need.
| Feature | Prompting Engineering | Fine-tuning | Retrieval Augmented Generation (RAG) |
|---|---|---|---|
| Skill Level Required | Low: Requires a basic understanding of how to construct prompts. | Moderate to High: Requires knowledge of machine learning principles and model architectures. | Moderate: Requires understanding of both machine learning and information retrieval systems. |
| Pricing and Resources | Low: Uses existing models, minimal computational costs. | High: Significant computational resources needed for training. | Medium: Requires resources for both retrieval systems and model interaction, but less than fine-tuning. |
| Customization | Low: Limited by the model's pre-trained knowledge and the user's ability to craft effective prompts. | High: Allows for extensive customization to specific domains or styles. | Medium: Customizable through external data sources, though dependent on their quality and relevance. |
| Data Requirements | None: Utilizes pre-trained models without additional data. | High: Requires a large, relevant dataset for effective fine-tuning. | Medium: Needs access to relevant external databases or information sources. |
| Update Frequency | Low: Dependent on retraining of the underlying model. | Variable: Dependent on when the model is retrained with new data. | High: Can incorporate the most recent information. |
| Quality | Variable: Highly dependent on the skill in crafting prompts. | High: Tailored to specific datasets, leading to more relevant and accurate responses. | High: Enhances responses with contextually relevant external information. |
| Use Cases | General inquiries, broad topics, educational purposes. | Specialized applications, industry-specific needs, customized tasks. | Situations requiring up-to-date information, and complex queries involving context. |
| Ease of Implementation | High: Straightforward to implement with existing tools and interfaces. | Low: Requires in-depth setup and training processes. | Medium: Involves integrating language models with retrieval systems. |
The table breaks down the key points of Prompting, fine-tuning, and RAG. It should help you understand which one might work best for different situations. We hope this comparison helps you choose the right tool for your next task.
Related Articles: How does RAG works (opens new window)

# RAG - the Best Choice to Enhance Your AI Application
RAG is a unique approach that combines the power of traditional language models with the precision of external knowledge bases. This method stands out for several reasons, making it particularly advantageous over solely prompting or fine-tuning in specific contexts.
Firstly, RAG ensures that the information provided is both current and relevant by retrieving external data in real time. This is crucial for applications where up-to-date information is important, such as in news-related queries or rapidly evolving fields.
Secondly, RAG offers a balanced approach in terms of customization and resource requirements. Unlike full fine-tuning, which demands extensive computational power, RAG allows for more flexible and resource-efficient operations, making it accessible to a wider range of users and developers.
Lastly, the hybrid nature of RAG bridges the gap between the broad generative capabilities of LLMs and the specific, detailed information available in knowledge bases. This results in outputs that are not only relevant and detailed but also contextually enriched.
An optimized, scalable, and cost-effective vector database solution can greatly enhances the performance and functionality of your RAG applications. That’s why you need MyScale (opens new window), an SQL-based vector database, which provides smooth integrations with major AI frameworks and language model platforms like OpenAI, Langchain, Langchain JS/TS, and LlamaIndex. With MyScale, RAG becomesfaster and more accurate (opens new window), which is great for users looking for the best results.
# Conclusion
In conclusion, whether you opt for prompting engineering, fine-tuning, or RAG will depend on your project's specific requirements, available resources, and desired outcomes. Each method has its unique strengths and limitations. Prompting is accessible and cost-effective but offers less customization. fine-tuning provides detailed customization at a higher cost and complexity. RAG strikes a balance, offering up-to-date and domain-specific information with moderate complexity.
If you are looking for an advanced RAG solution (opens new window) for your AI applicaion, hope MyScale can give you a help. And welcome to discuss any of your thoughts with us in our Discord (opens new window).



