
检索增强生成(RAG)通过将其与外部知识库连接,提高了LLM的性能。它具有许多优点,包括较低的成本/资源、优化特定领域知识上的LLM、数据安全等。在深度学习的背景下,RAG是相对较新的技术[1],但它的使用是巨大的,并且每天都在增加。
随着RAG的使用日益增多,它也在不断改进。随着RAG系统中的限制被发现,研究人员也一直在寻找提高其性能的方法。那么今天,我们将讨论查询改进。
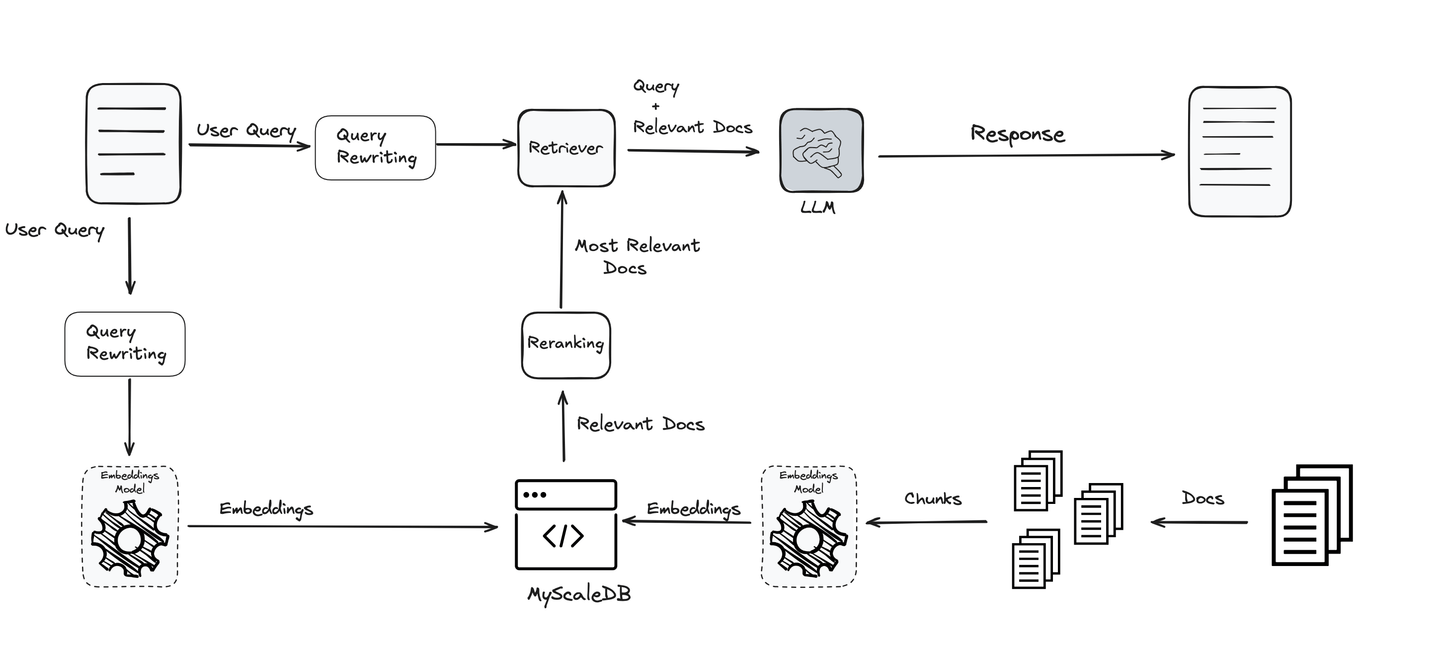
添加查询重写步骤
查询是整个RAG流程中最重要的部分之一。您提出的问题决定了方向,LLM和其他工具会根据此方向为您提供信息。如果查询不清晰或优化不良,即使是最好的系统也可能无法满足要求。因此,改进和优化查询是获得准确和有意义结果的关键。
考虑到这一重要性,使用各种技术来优化和澄清查询,以确保最终用户获得最佳和最相关的结果。这些技术使系统更加高效和可靠,支持RAG流程的每个阶段。
# 查询改写
LLM很难从LLM的角度判断出由(大多数是天真的)用户编写的查询,正如经验所示,这些查询有很大的改进空间。LLM或任何检索系统也可能对特定词语敏感,因此,查询重写可以优化查询以更好地理解。
例子:
为了进一步说明这一点,我们引用[2]中提供的一个例子。原始查询如下:
一个汽车制造工厂正在考虑下一个工厂的新址。在允许建造工厂之前,社区规划者最关心以下哪个问题?
这个查询对LLM来说太复杂,无法准确理解并回答。在使用重写器之后,重写后的查询如下:
在允许建造汽车制造工厂之前,社区规划者最关心什么问题?
它完全有效,并返回了正确的答案。
有许多重写查询的技术。有些用同义词替换它们,有些附加元数据 (opens new window),有些专注于改进语法,有些将查询扩展为更有意义的形式(甚至有些方法生成原始查询的排列组合 (opens new window)),等等。有趣的是,其中一些方法涉及LLM (opens new window)本身。因此,这是一种使用LLM改进另一个(或相同)LLM输入的递归使用LLM的方法。
# 查询规范化
查询规范化是指修复原始查询的语法和拼写等简单方法。类似地,可以使用小写或删除停用词等预处理方法进行查询规范化。
例如,“《卡拉马佐夫兄弟》的作者是谁?”比“谁写了broter karamov”更容易理解,因为您注意到了后者查询中的拼写错误。
在这里,应该注意到LLM是强大的转换模型,通常能够在不进行太多规范化的情况下理解句子。因此,需要在规范化输入和过度规范化之间取得平衡。
# 查询扩展
由于我们通常无法确定查询在大多数情况下是否表现良好,常见的方法是创建查询的多个排列,并为所有排列返回结果。虽然我们也有许多经典的释义方法,但LLM本身在这方面非常擅长,您之前可能已经注意到了。
下面是一个使用LangChain和OpenAI的GPT-4模型的例子(最初取自LangChain (opens new window))。
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain.output_parsers import PydanticToolsParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
class ParaphrasedQuery(BaseModel):
"""您已执行查询扩展以生成问题的释义。"""
paraphrased_query: str = Field(
...,
description="原始问题的独特释义。",
)
system = """您是将用户问题转换为数据库查询的专家。\
您可以访问一个关于构建LLM驱动应用程序的软件库的教程视频数据库。\
执行查询扩展。如果有多种常见的方式来表达用户问题\
或问题中关键词的常见同义词,请确保返回多个版本\
具有不同表达方式的查询。
如果有您不熟悉的首字母缩写词或单词,请不要尝试重述它们。
至少返回3个版本的问题。"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.25)
llm_with_tools = llm.bind_tools([ParaphrasedQuery])
query_analyzer = prompt | llm_with_tools | PydanticToolsParser(tools=[ParaphrasedQuery])
构建了查询扩展器后,我们现在可以使用它。例如:

查询扩展结果
如您所见,它提供了很好的排列(如果需要,我们可以进一步增加排列的数量),这对于输入LLM可能是有帮助的。
# 上下文适应
上下文适应的过程涉及调整查询以更好地适应提问的特定上下文。这通常通过利用强化学习(RL)来实现,根据上下文信息优化查询的措辞。一种方法是使用小型语言模型(LM)作为查询重述器,使用互联网数据等外部来源来丰富查询的上下文。然后,RL组件通过学习有关重述查询在给定上下文中的表现如何的反馈来对此适应进行微调。这种方法已在各种研究中进行了探索,例如[2]和[3]中引用的研究,证明了它在提高查询相关性和性能方面的有效性。
# 查询分解
查询通常包含两个(或更多)不同的查询,这使得LLM很难理解它们。此外,LLM很容易受到无关上下文的影响[4]。例如,在Jessica年龄的经典示例中,引入一个无关的陈述(红色的陈述)可能会使LLM困惑。

来自[4]的查询理解效率低下的示例导致了对查询分解的需求。红色下划线部分的陈述使查询变得不必要复杂,使LLM更难理解。
在这里,更好的解决方案是将查询分解为以下内容:
“Jessica比Claire大六岁。两年后,Claire将年满20岁。” “二十年前,Claire的父亲的年龄是Jessica年龄的3倍” “Jessica现在多大?”
可能我们甚至可以省略第二个陈述。
# 查询分解中的挑战
查询分解具有一些优点,如更好的清晰度和帮助LLM逐步推理。然而,查询分解也面临一些挑战,例如:
- 过度分解:过度分解查询可能会稀释上下文,导致结果不太相关。
- 结果合并:聚合子查询的结果可能具有挑战性,特别是如果它们是相互矛盾或不完整的。
- 查询依赖性:某些查询依赖于先前步骤的结果,需要迭代过程。
- 成本和延迟:将查询分解为多个部分会增加检索和计算步骤的数量,这可能会导致计算成本增加。
尽管查询分解是有前途的,但正如我们在面临的挑战中看到的那样,它仍有很大的改进空间。如果您对是否使用它有疑问,最好保守一些,特别是为了节省成本。
# 嵌入优化
嵌入通常使用常见的NLP模型(如BERT (opens new window)或Titan (opens new window))生成。这些嵌入对于许多应用程序来说非常好,但通常需要进行优化以获得更好的理解。出于这些原因,还提出了一些基准测试,如大规模文本嵌入基准(Massive Text Embedding Benchmark,MTEB)[5],用于检查嵌入在8个不同任务(如分类、聚类和摘要)中的性能。
“*我们发现没有单一的最佳解决方案,不同的模型在不同的任务中占主导地位。”- MTEB论文
正如MTEB也正确地发现的那样,没有单一的最佳解决方案适用于所有任务:某些模型适用于摘要,某些模型适用于分类等。而且,这也不是在所有数据集上都是通用的,因为对于相同任务,模型在某些数据集上表现更好,而在其他数据集上表现不佳。
# 假设文档嵌入(HyDE)
在2022年,研究人员提出了一种新颖的零样本方法[6]。这种独特的方法基于制作一个虚假文档,然后使用其嵌入在嵌入空间中找到相似的(真实)文档。HyDE正变得越来越受欢迎,作为RAG中查询优化的工具。HyDE的方法可以总结如下:
- 生成假设文档
- 计算其嵌入
- 使用嵌入查询向量数据库
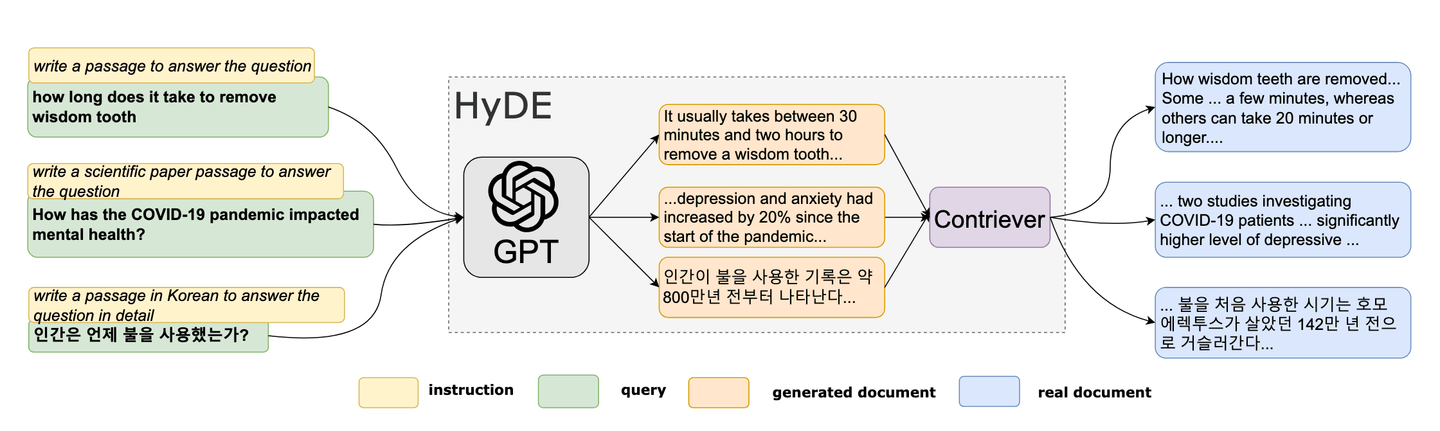
参考:HyDE论文[6]
# 假设文档创建
作为第一步,我们采用查询并使用它来生成假设文档。可以简单地提示LLM“制作一个回答这个问题的文档”,如我们将在示例中看到的那样。
# 嵌入计算
我们可以使用任何模型或服务-MyScale也提供自己的EmbedText()方法-来计算这些嵌入。一旦这些(假设查询)嵌入可用,我们就可以使用它们来查询向量数据库。
一旦我们从假设查询中获得最相似的文本,我们将其与(原始)查询一起传递给LLM进行响应生成。
# HyDE示例
例如,一些嵌入存储在MyScale的DocEmbeddings表中。我们可以使用-比如余弦相似度-查询它们的前10个相似文档,如下所示:
步骤1:假设文档生成
作为第一步,我们采用查询并使用OpenAI的GPT-4(mini)模型生成假设文档(对于大多数任务,GPT4-mini足够好且节省费用)。
from openai import OpenAI
openai_client = OpenAI(api_key='sk-xxxxx')
def Make_HyDoc(query):
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "system", "content": "Make a document that answers the question:"},
{"role": "user", "content": f"{query}"}],
max_tokens=100
)
return response.choices[0].message
现在,我们有了这个函数,因此我们可以使用它来基于我们的查询生成假设文档。
步骤2:嵌入计算
为了计算嵌入,我们将使用MyScale内置的EmbedText()直接计算嵌入。
service_provider = 'OpenAI'
hypoDoc = Make_HyDoc("What was the solution proposed to farmers problem by Levin?")
parameters = {'sampleString': hypoDoc, 'serviceProvider': service_provider}
x = client.query("""
SELECT EmbedText({sampleString:String}, {serviceProvider:String}, '', 'sk-*****', '{"model":"text-embedding-3-small", "batch_size":"50"}')
""", parameters=parameters)
input_embedding = x.result_rows[0][0]
步骤3:使用嵌入查询向量数据库
现在,我们有了input_embedding中的嵌入,我们可以使用简单的SQL查询将其与已存储在表(在此示例中为DocEmbeddings)中的向量进行比较。
SELECT
id,
title,
content,
cosineDistance(embedding, input_embedding) AS similarity
FROM
DocEmbeddings
ORDER BY
similarity ASC
LIMIT
10;
我们可以在Python中运行它并显示为数据帧。
import pandas as pd
query = f"""
SELECT
id,
sentences,
cosineDistance(embeddings, {input_embedding}) AS similarity
FROM
DocEmbeddings
LIMIT
10
"""
df = pd.DataFrame(client.query(query).result_rows)
它返回最相关的文档:

HyDE结果
# 结论
RAG是一种强大且具有成本效益的工具,可以增强LLM的功能,但它也有其局限性。在本博客文章中,我们专注于作为RAG过程的一部分改进查询。我们探讨了各种技术,如重述(通常使用LLM),查询分解,优化嵌入的质量和HyDE。虽然这些方法很有价值,但它们只代表了RAG流程的一个方面。还有其他方法可以增强整个RAG生成过程。在下一篇文章中,我们将深入探讨分块策略,并讨论如何根据用例将数据分块。
# 参考文献
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS. https://arxiv.org/abs/2005.11401
- Ma, X., Gong, Y., He, P., Zhao, H., & Duan, N. (2023). Query Rewriting for Retrieval-Augmented Large Language Models. EMNLP. https://arxiv.org/abs/2305.14283
- Anand, A., V, V., Setty, V., & Anand, A. (2023). Context Aware Query Rewriting for Text Rankers using LLM. ArXiv. https://arxiv.org/abs/2308.16753
- Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H. Chi, Nathanael Schärli, and Denny Zhou. Large language models can be easily distracted by irrelevant context. ICML, 2023.
- Muennighoff, N., Tazi, N., Magne, L., & Reimers, N. (2022). MTEB: Massive Text Embedding Benchmark. ArXiv. https://arxiv.org/abs/2210.07316
- Gao, L., Ma, X., Lin, J., & Callan, J. (2022). Precise Zero-Shot Dense Retrieval without Relevance Labels. ArXiv. https://arxiv.org/abs/2212.10496



